TeachLM: Post-Training LLMs for Education Using Authentic Learning Data (2510.05087v1)
Abstract: The promise of generative AI to revolutionize education is constrained by the pedagogical limits of LLMs. A major issue is the lack of access to high-quality training data that reflect the learning of actual students. Prompt engineering has emerged as a stopgap, but the ability of prompts to encode complex pedagogical strategies in rule-based natural language is inherently limited. To address this gap we introduce TeachLM - an LLM optimized for teaching through parameter-efficient fine-tuning of state-of-the-art models. TeachLM is trained on a dataset comprised of 100,000 hours of one-on-one, longitudinal student-tutor interactions maintained by Polygence, which underwent a rigorous anonymization process to protect privacy. We use parameter-efficient fine-tuning to develop an authentic student model that enables the generation of high-fidelity synthetic student-tutor dialogues. Building on this capability, we propose a novel multi-turn evaluation protocol that leverages synthetic dialogue generation to provide fast, scalable, and reproducible assessments of the dialogical capabilities of LLMs. Our evaluations demonstrate that fine-tuning on authentic learning data significantly improves conversational and pedagogical performance - doubling student talk time, improving questioning style, increasing dialogue turns by 50%, and greater personalization of instruction.
Sponsor

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about building and testing a better AI tutor. The authors created TeachLM, an AI that’s trained to teach more like a good human tutor. Instead of just giving answers, it asks smart questions, adapts to the student, and keeps a real conversation going. They did this by fine-tuning big AI models using a huge collection of real, one-on-one tutoring sessions—over 100,000 hours—from a program called Polygence.
What questions were the researchers asking?
The researchers focused on a few simple but important questions:
- Can an AI tutor be trained to act more like a great human tutor, not just a “helpful assistant” that gives quick answers?
- Does using real tutoring data (with privacy protected) make AI tutoring better than just clever prompting?
- Can we build a realistic “student” AI to practice with the tutor AI, so we can test tutoring skills quickly and fairly?
- How do today’s top AIs compare to human tutors on basic teaching behaviors like asking good questions, listening, and personalizing help?
How did they do it?
Using real tutoring conversations
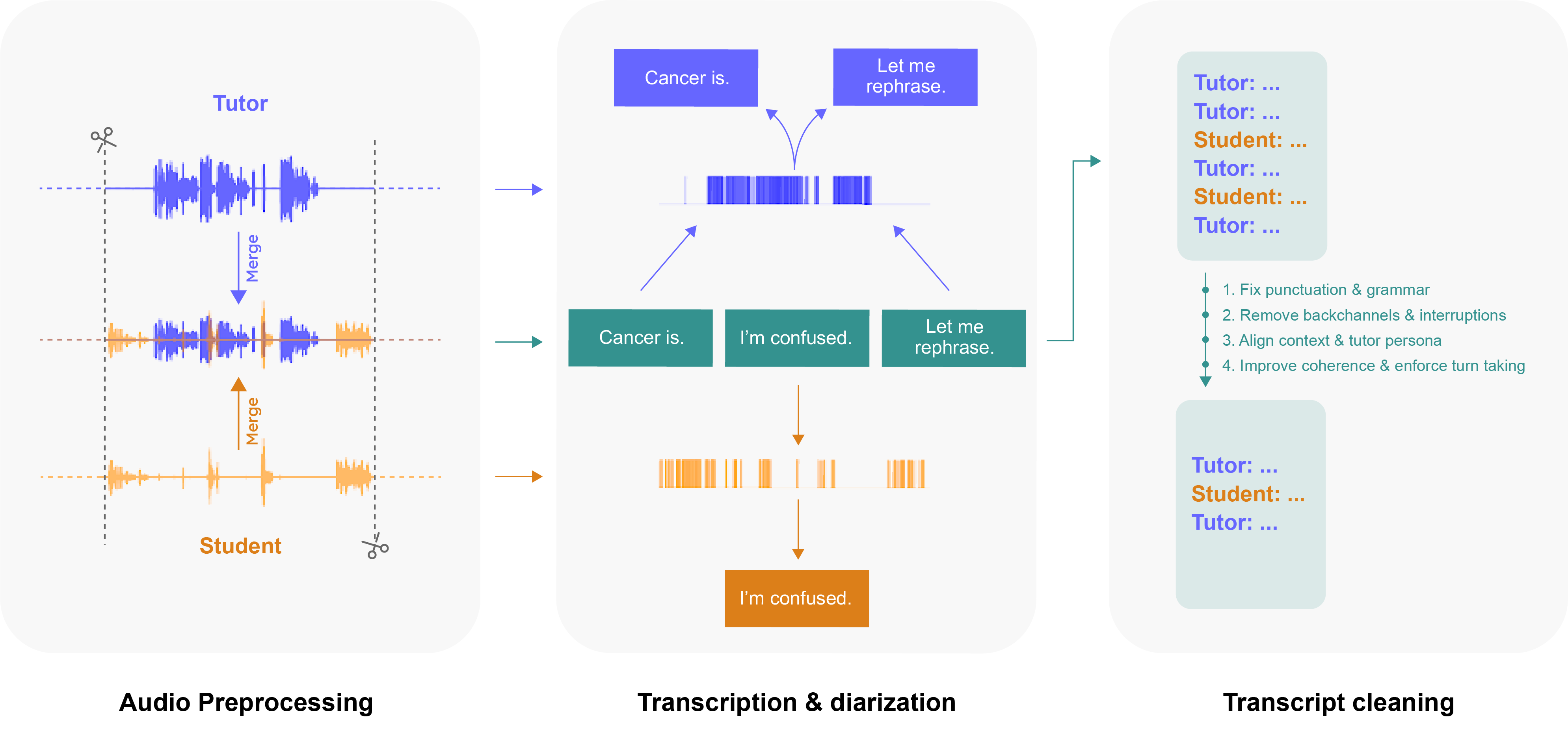
Polygence runs long-term, one-on-one tutoring projects where students work with expert mentors. The team used more than 100,000 hours of these sessions across 150+ subjects (like AI, cancer biology, and creative writing). They:
- Got consent, honored opt-outs, and anonymized personal details to protect privacy.
- Turned audio into clean, readable transcripts using a careful pipeline: transcribe speech, label who’s speaking, fix grammar and formatting, remove filler words, and remove personal info.
Think of it like turning lots of real tutoring “practice games” into a clean playbook the AI can learn from.
Fine-tuning the AI tutor (TeachLM)
They “fine-tuned” an existing powerful AI to teach better. Fine-tuning is like adjusting a radio to get a clearer station—you don’t build a new radio; you tweak it to pick up the signal you want. They used a method called “parameter-efficient fine-tuning,” which means they made small, smart adjustments rather than retraining the whole model. This helps keep costs and complexity down.
Creating a realistic AI “student”
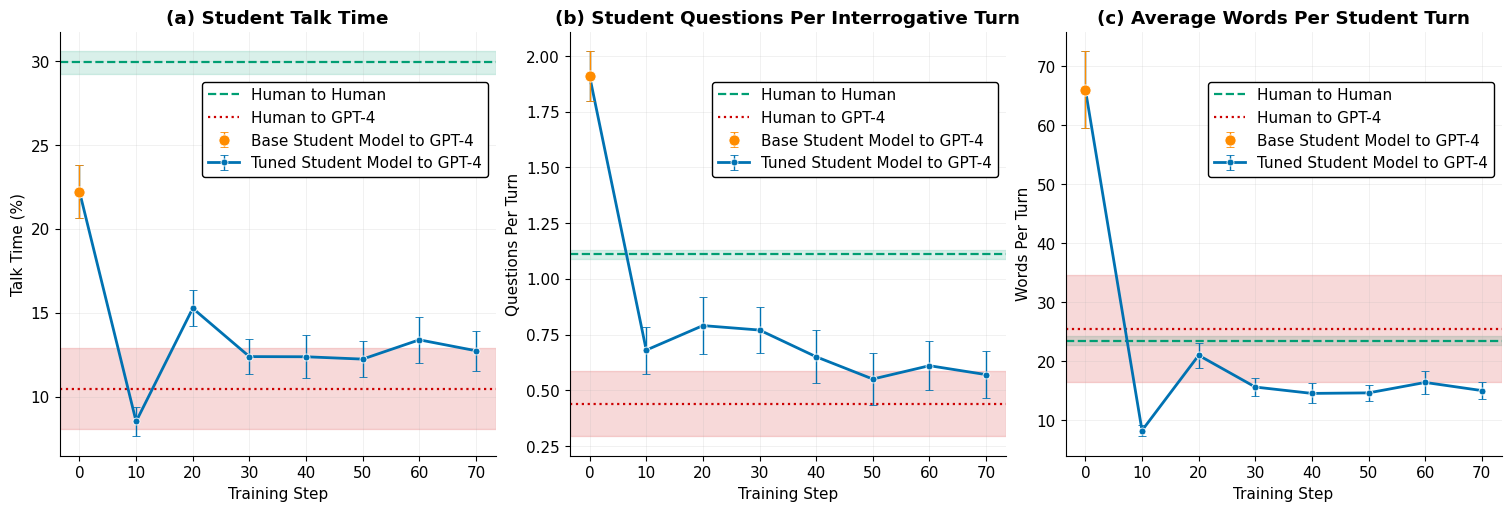
To test tutors properly, you need a believable student. The team trained a student simulator using real student dialogue, so the “student” AI would talk, ask, and behave more like actual learners (not like a robot pretending to be a student). They checked that this student simulator’s conversations looked similar to real human–AI chats (for example, how long turns were, how often questions were asked, and how much the student talked).
A new way to test AI tutors: multi-turn evaluations
Most AI tests are single-turn (one question, one answer). Real tutoring is multi-turn: a back-and-forth conversation. The team made a testing setup where:
- The AI tutor and the AI student hold a full conversation.
- Afterward, another model (a “judge”) scores the dialogue.
- They repeat this many times to get reliable results.
They used simple, common-sense “proxies” (stand-ins) for good teaching. Here are the main ones they measured:
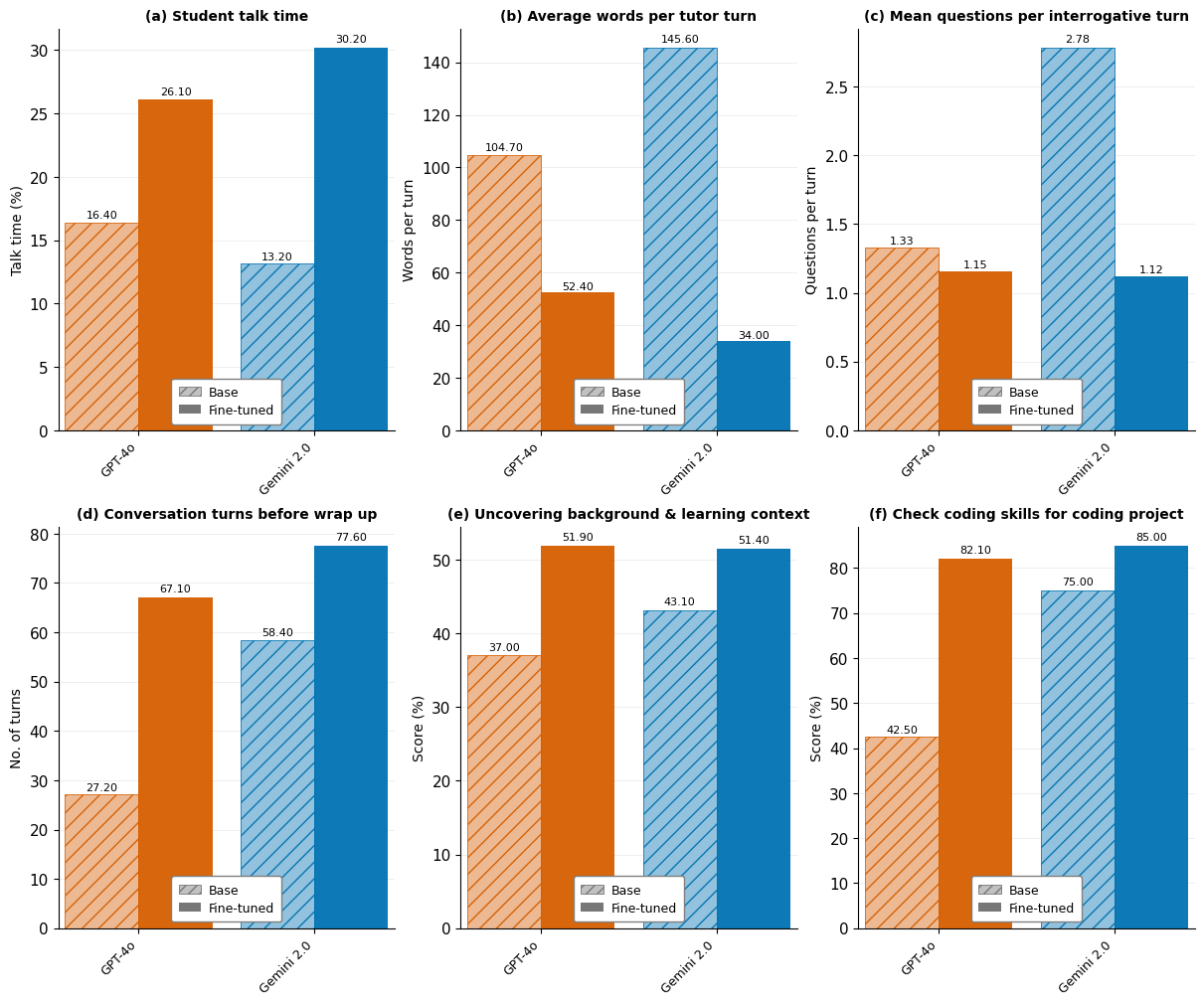
- Student talk time: Does the student get to talk a fair amount, not just the tutor?
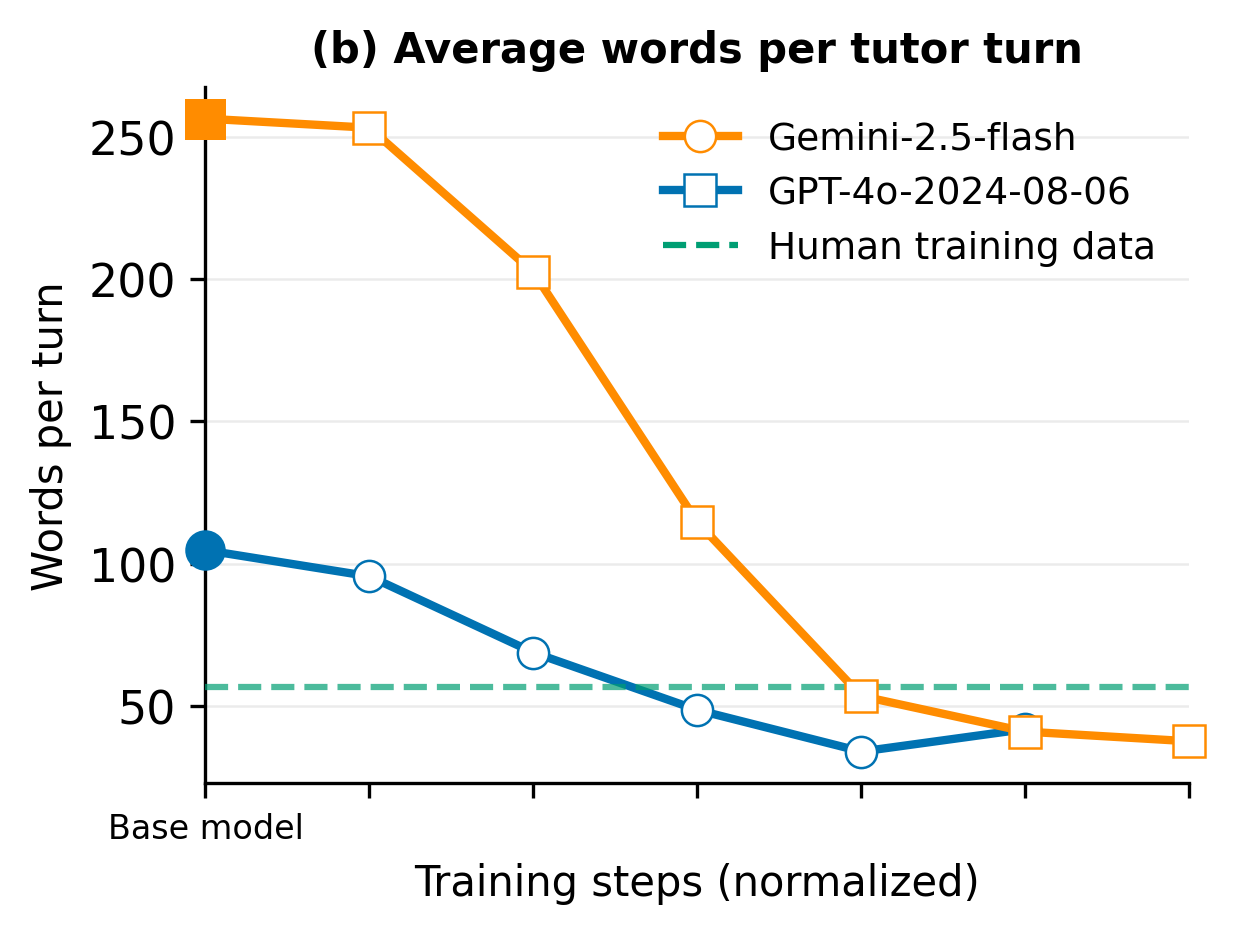
- Words per tutor turn: Does the tutor avoid “walls of text”?
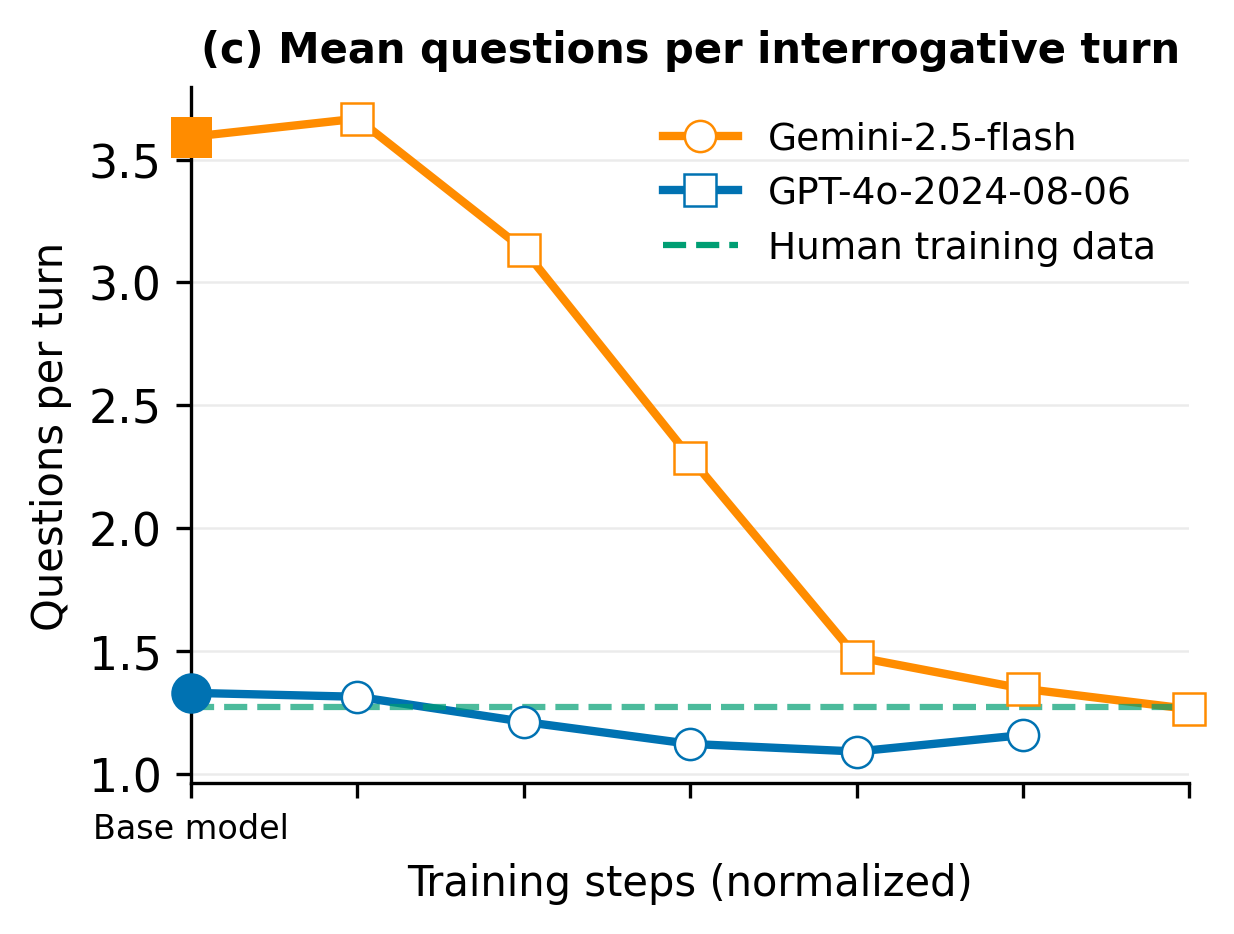
- Questions per turn: Does the tutor ask a few thoughtful questions, not a rapid-fire list?
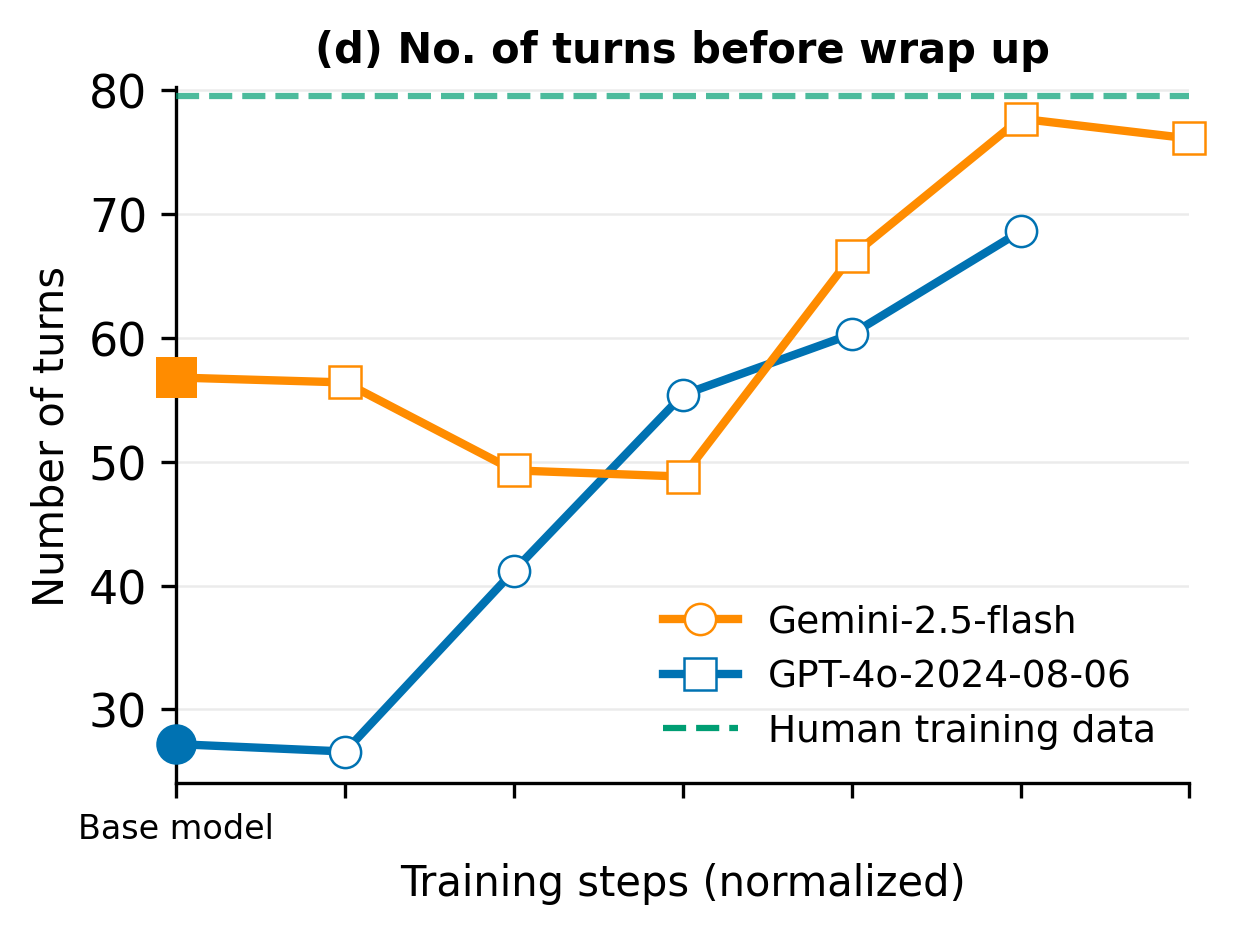
- Number of turns before wrap-up: Does the tutor keep the conversation going long enough to learn and practice?
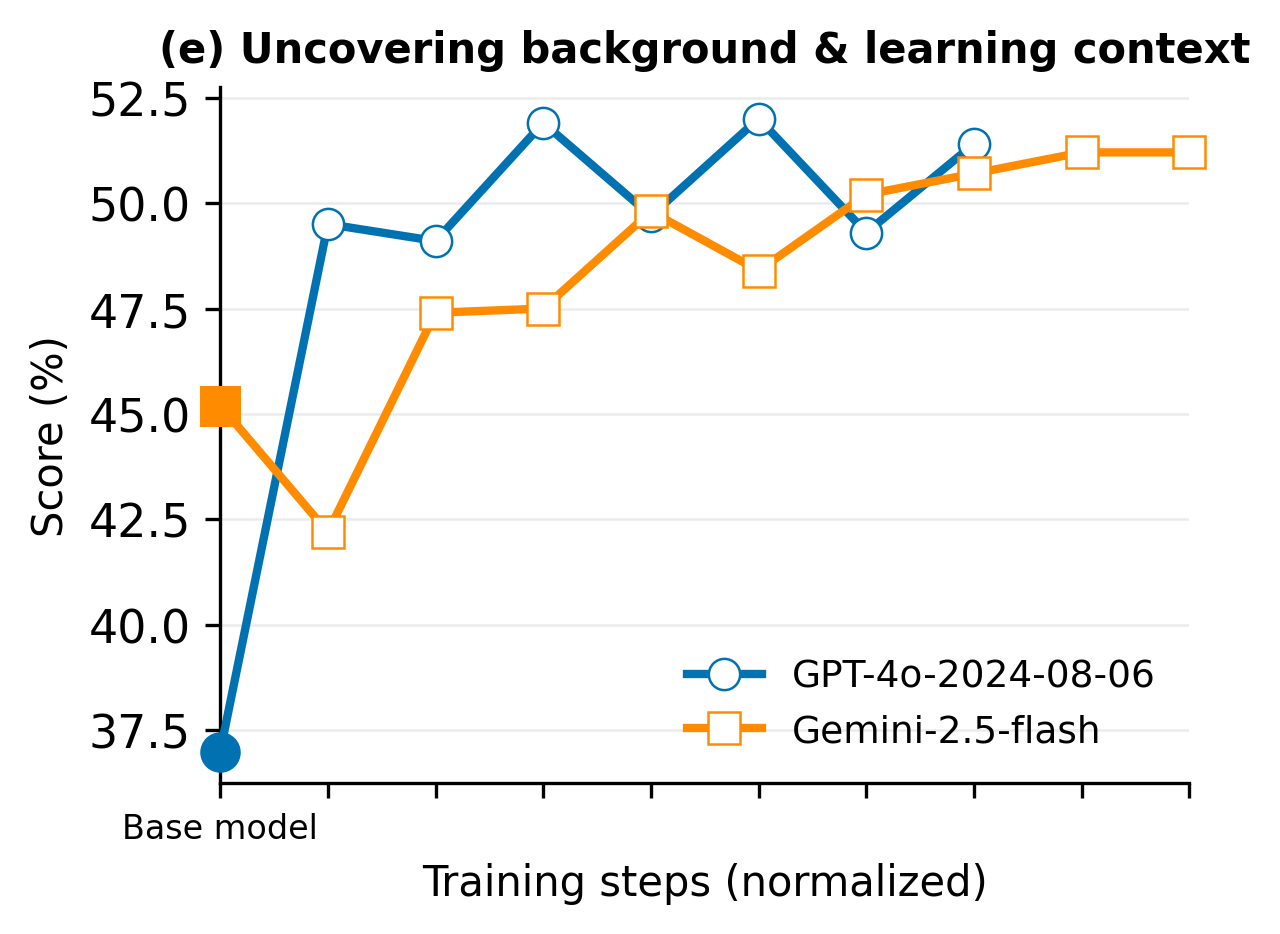
- Uncovering student background: Does the tutor ask about the student’s goals, skills, and needs?
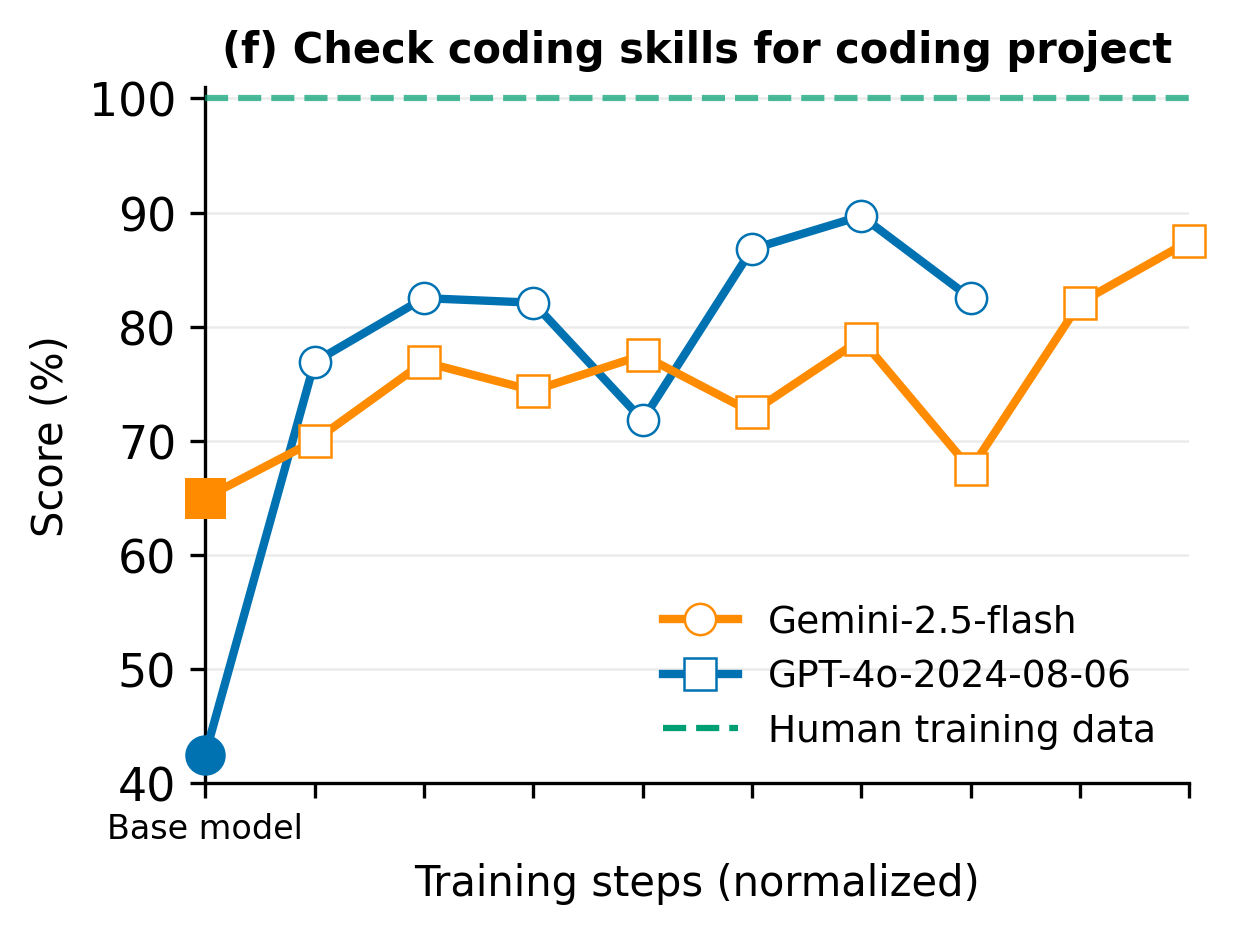
- Checking coding skills (for coding projects): Does the tutor make sure the student’s skills match the task?
What did they find?
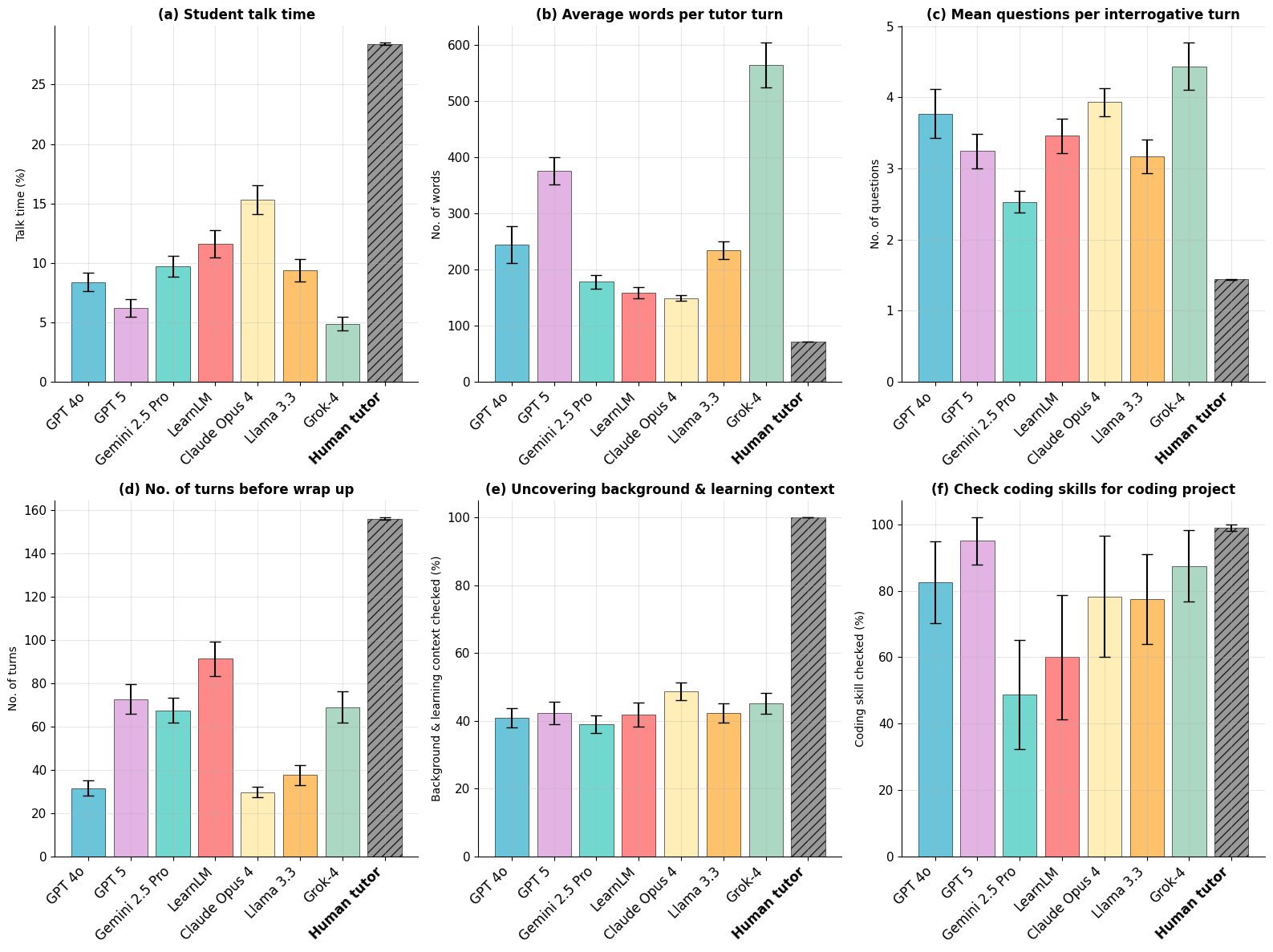
- Off-the-shelf AIs (without special training) don’t tutor like humans. They talk too much, ask too many questions at once, end conversations early, and often fail to learn key things about the student (like goals or skill level).
- Human tutors were better across all the teaching measures.
- The fine-tuned student simulator made AI–AI practice conversations more realistic than using two untrained AIs.
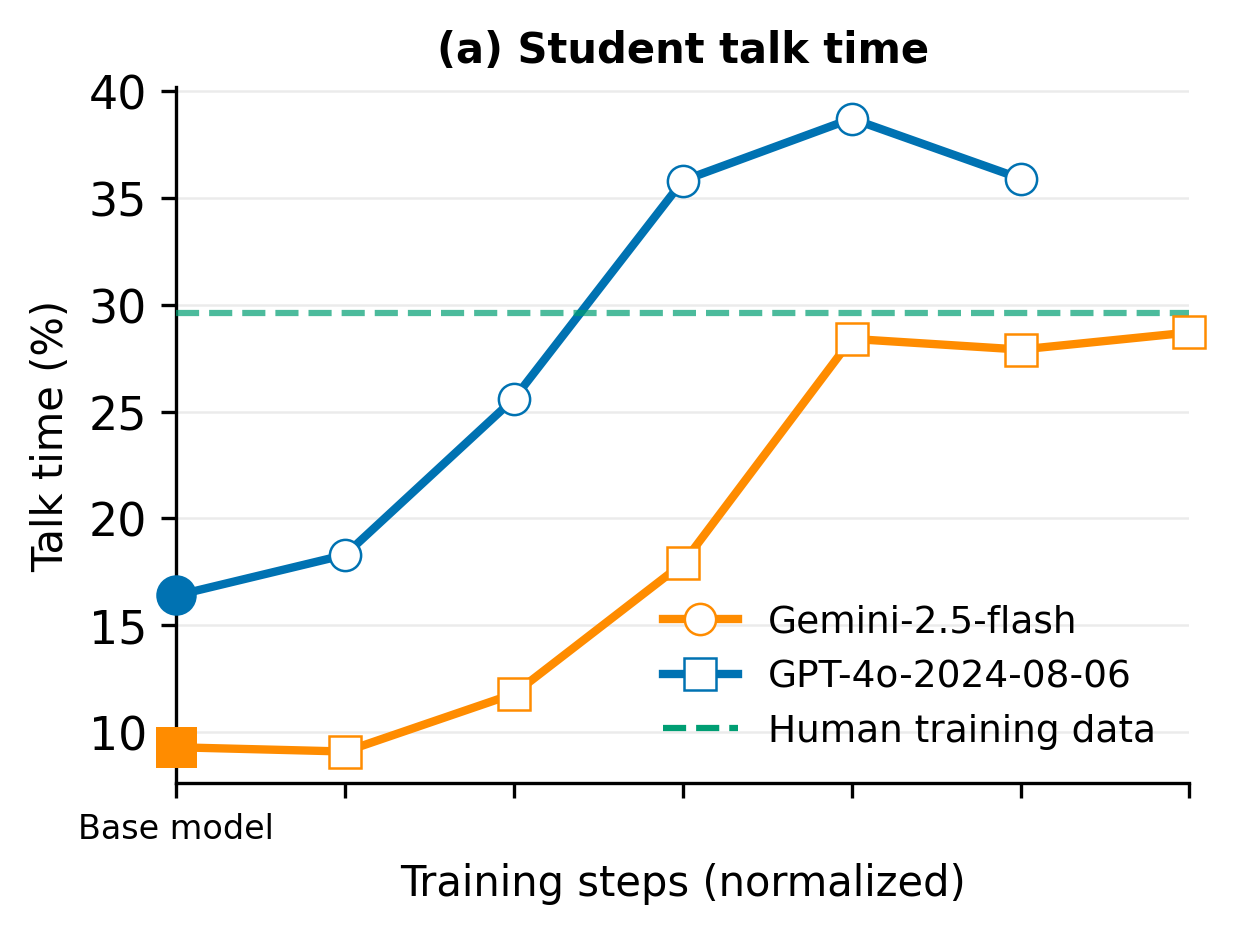
- After fine-tuning on real tutoring data, TeachLM improved a lot:
- Students got about twice as much speaking time.
- Tutors asked better, more human-like questions (not long question lists).
- Conversations lasted about 50% longer, allowing deeper learning.
- The AI was better at personalizing instruction to the student.
In short: using authentic learning data and smart fine-tuning made the AI behave more like a patient, curious coach rather than an answer machine.
Why does this matter?
- For students: A better AI tutor can help you think, not just copy answers. It can ask questions that guide you to understand, practice, and build confidence.
- For teachers: This approach can support teachers by handling routine coaching and giving students more personalized practice, while teachers focus on higher-level guidance.
- For research: The multi-turn testing method is fast, scalable, and repeatable. It gives a fair way to compare AI tutors and track progress over time.
- For privacy and ethics: The project shows it’s possible to use real educational data responsibly, with consent and anonymization.
- For the future: As more high-quality, real learning data becomes available (for example, through initiatives like the National Tutoring Observatory), AI tutors can keep improving. The goal isn’t to replace human tutors but to bring more “one-on-one-style” support to more learners, anywhere, at any time.
Overall, the paper shows a practical path to make AI tutoring more human-like: use real tutoring data, fine-tune carefully, and test in realistic, back-and-forth conversations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- External validity/generalizability: The dataset is drawn from a single platform (Polygence), with US-based, PhD-level tutors and largely project-based, STEM-leaning topics; it is unclear how models trained/evaluated here transfer to other ages (K–6, adult learners), languages, cultures, low-resource settings, non-project coursework, group classrooms, special education, or humanities-focused curricula.
- Demographic and equity considerations: The paper does not report learner demographics, access, or equity analyses (e.g., outcomes across SES, gender, race/ethnicity, disability, language learners), leaving unclear whether the model amplifies or mitigates disparities.
- Data representativeness by subject: Topic distribution is dominated by AI/ML, biomedical, and CS; the extent to which results hold for foundational math, literacy, writing instruction, and other underrepresented subjects is untested.
- Privacy and ethical oversight: The consent/anonymization approach is described but lacks IRB review status, re-identification risk assessment, and formal compliance discussion (e.g., COPPA/FERPA/GDPR) for minors; open question: what technical and governance controls are sufficient for safe, longitudinal educational fine-tuning at scale?
- Impact of transcript “polishing”: The cleaning pipeline removes backchannels, disfluencies, and overlaps and “improves coherence” and “enforces turn-taking,” which can erase authentic instructional signals; ablations are needed to quantify how these edits shift conversational metrics and model learning.
- ASR/diarization fidelity: No quantitative error rates for transcription/diarization are reported; the effect of systematic ASR errors (by accent, gender, age, audio quality) on training/evaluation and on fairness is unknown.
- Student simulator validity: The fine-tuned student model is trained on authentic student turns and then used to evaluate tutors; its fidelity to real learners’ behaviors across unseen students, unseen topics, and new tasks is not established via human-grounded validation.
- Overfitting/memorization in the student model: Using project-specific IDs and possibly overlapping students for training and simulation risks memorization; it remains unclear whether simulations reflect genuine generalization versus recall of training interactions.
- Representativeness of simulated personas: Only 10 fine-tuned student personas are used per evaluation point; the diversity, coverage, and selection bias of these personas (ability levels, motivations, affect, cultural styles) are not characterized.
- Evaluation circularity and judge bias: The pipeline uses LLM judges (e.g., Gemini) to detect wrap-ups and score context elicitation; reliability, calibration, and bias of judge models are not reported, and there is no human adjudication or multi-judge agreement analysis.
- Proxies versus learning outcomes: Chosen metrics (talk time, words per turn, questions per turn, turns to wrap-up, context elicitation, coding-skill check) may be easy to game and are not validated against actual learning gains, retention, transfer, metacognition, or affect; randomized controlled trials with real students are needed.
- Safety and content accuracy: There is no systematic assessment of factual accuracy, misconception repair, hallucinations, harmful guidance, or academic integrity risks; safety-aligned post-training and rigorous safety benchmarks remain open.
- Pedagogical breadth: Key teaching skills—diagnosing misconceptions, stepwise scaffolding, formative assessment quality, metacognitive prompts, culturally responsive pedagogy, motivational/affective support, errorful learning—are not directly evaluated.
- Comparative fairness of model benchmarking: Cross-model comparisons may be confounded by differing default prompts, system instructions, or temperature settings; standardized prompting and ablation of prompt effects are needed for fair comparisons.
- Reproducibility under base model churn: As closed-source base models evolve, maintaining TeachLM’s performance is flagged as costly but unresolved; strategies for continual learning, data/version pinning, and backward-compatible evaluation are not provided.
- TeachLM fine-tuning details: The teacher model’s base architecture, PEFT configuration (e.g., LoRA ranks/layers), data volume, sampling, epochs, hyperparameters, safety tuning, and training objectives are not disclosed—hindering replication and diagnosis of what drives gains.
- Evidence for claimed gains: The abstract claims doubling student talk time, 50% more dialogue turns, improved questioning, and personalization, but detailed effect sizes, confidence intervals, statistical significance, and ablations (e.g., vs prompting or synthetic-only tuning) are not reported for TeachLM.
- Human-in-the-loop evaluation: Beyond LLM judges, there is no human rating of dialogue quality (e.g., rubric-based pedagogy assessments) or inter-rater reliability; a mixed-methods evaluation combining experts, teachers, and students remains to be done.
- Out-of-distribution (OOD) tests: The model is not evaluated on public tutoring datasets or prospective external partners (e.g., National Tutoring Observatory data) to assess OOD robustness.
- Multimodal learning: Although the platform captures documents, code, and other modalities, training/evaluation appears text-only; how to incorporate artifacts (e.g., code repos, drafts, slides) for richer tutoring remains open.
- Conversation termination metric: “Turns to wrap-up” relies on an LLM detector; its sensitivity/specificity and susceptibility to style differences (e.g., summarizing vs coaching) are not validated.
- Context elicitation metric: “Percent of known student info uncovered” uses the original human conversation as a moving ceiling; the construct validity (what info is necessary/sufficient and non-intrusive) and potential to reward excessive probing are unresolved.
- Data and model release: The dataset and model are not open-sourced; without a public evaluation harness or shared data slices, community verification and progress tracking are limited.
- Clustering validity: The K-means/Clio-derived activity taxonomy and the reported 78% overlap with OpenAI student use-cases lack external validation or human coding reliability checks.
- Cost/latency/serving constraints: Inference costs, latency, and throughput for multi-turn tutoring at scale are not analyzed; practical deployment trade-offs versus pedagogical gains are an open question.
- Domain shift over time: Longitudinal changes in student/tutor behavior (e.g., evolving AI literacy) and their impact on retraining schedules and model drift are not studied.
- Ethical design of simulated students: The paper does not address guardrails to prevent simulators from reproducing harmful or biased student behaviors and how that might affect tutor training.
- Blinding and leakage in evaluations: Whether prompts, metadata, or project IDs leak cues to tutors or judges in a way that inflates scores is not examined; rigorous blinding protocols are needed.
- Persona-sensitive pedagogy: How well TeachLM adapts strategies to student profiles (novice vs advanced, anxious vs confident) is claimed qualitatively but lacks quantitative, persona-conditioned evaluation.
- Non-English and multilingual tutoring: The pipeline’s ASR, cleaning, and models are English-centric; extending to multilingual tutoring, code-switching, and translation fidelity remains open.
- Group and classroom interactions: The approach focuses on 1:1 sessions; extending to small-group or whole-class orchestration (turn-taking, equitable participation) is unexplored.
- Instructor modeling fidelity: While student modeling is emphasized, the paper does not quantify how closely TeachLM matches high-performing human tutors’ discourse moves or varies strategy over the course of a project.
- Goodharting risks: The paper notes that proxies can be optimized without improving pedagogy, but it does not propose anti-gaming strategies (e.g., hidden metrics, multi-objective evaluation, adversarial audits).
- Power analysis and sample sizing: The choice of 100 simulated dialogues per evaluation point is heuristic; statistical power, variance across seeds, and sensitivity analyses are not reported.
- Alignment with curriculum and standards: There is no mapping between tutoring behaviors and curricular goals/standards (e.g., NGSS, CCSS), making it hard to situate improvements within formal education constraints.
- Human tutor augmentation: How TeachLM integrates with human teachers (co-tutoring, planning, feedback triage) and impacts workload, satisfaction, or effectiveness is not studied.
- Long-term outcomes: Effects on sustained motivation, self-regulated learning, project completion quality, and downstream academic performance are unknown; longitudinal field trials are needed.
Glossary
- Analysis of Variance (ANOVA): A statistical test used to determine whether there are significant differences between means of three or more groups. "A one-way Analysis of Variance (ANOVA) followed by Tukey's HSD post-hoc tests confirmed that these differences are highly statistically significant."
- anonymization: The process of removing or obfuscating personal identifiers from data to protect privacy. "underwent a rigorous anonymization process to protect privacy."
- ASR: Automatic speech recognition; technology that converts spoken language into text. "mitigating rare but consequential ASR lapses (e.g., dropped segments)."
- backchannels: Brief listener responses (e.g., “yeah,” “uh-huh”) that signal attention but can disrupt transcript clarity. "Removal of backchannels that interrupt flow (e.g.,
yeah'',gotcha'', ``uh-huh'')." - benchmarking: Systematically comparing models or systems using defined metrics or tasks. "We benchmark off-the-shelf LLMs against human tutors across six education-focused evaluations, highlighting systematic differences in conversational and engagement metrics."
- Clio framework: Anthropic’s toolkit for clustering and organizing text data for analysis. "using Anthropic's Clio framework \cite{tamkin2024clio}"
- dialogical capabilities: A model’s ability to conduct effective, multi-turn dialogue. "assessments of the dialogical capabilities of LLMs."
- diarization: The process of segmenting audio to attribute parts to specific speakers. "Speaker activity masks enable accurate diarization, followed by a multi-step cleaning process..."
- diarized transcript: A transcript annotated with speaker labels per utterance. "compile a diarized transcript with one speaker per statement."
- fine-tuned student model: A model trained on student data to simulate authentic learner behavior in dialogues. "a novel multi-turn evaluation protocol that combines a fine-tuned student model and a fine-tuned tutor model to generate a large number of synthetic dialogues."
- first mile problem: The tendency to start explaining before gathering the learner’s context or goals. "the ``first mile problem''âjumping into explanations without first eliciting information about the studentâs academic background or learning goals"
- frontier models: The most capable, cutting-edge LLMs available at a given time. "Post-training frontier models on domain-specific data has recently led to rapid progress toward human-level performance across a range of domains, including coding, law, and science~\cite{wang2025aethercode, deepmind2025geminiICPC, Xie2023DARWIN, hu2025breakingbarriers}."
- fuzzy matching: Approximate string matching to associate similar but not identical text entries. "Assign single-speaker tracks to Tutor or Student via fuzzy matching of Zoom display names to known participants."
- hierarchical K-means clustering: A technique that applies K-means recursively to form multi-level clusters. "obtained via hierarchical K-means clustering."
- interrogative turn: A conversational turn that contains at least one question. "An interrogative turn is defined as a statement that has at least one question and questions are detected via question marks."
- Kura library: An open-source library used for clustering and analysis in this work. "the open-source Kura library \cite{567labs2025kura}"
- longitudinal student–tutor interactions: Extended interactions collected over long periods to capture learning progression. "one-on-one, longitudinal studentâtutor interactions"
- multi-modal exchanges: Interactions that span multiple data types (e.g., audio, text, documents). "Multi-modal exchanges: Each project's dataset encompasses meeting transcripts, shared documents, chat, and other modalities of studentâtutor interaction."
- multi-turn evaluation protocol: An assessment method that evaluates models over extended dialogues rather than single turns. "we propose a novel multi-turn evaluation protocol that leverages synthetic dialogue generation to provide fast, scalable, and reproducible assessments of the dialogical capabilities of LLMs."
- parameter-efficient fine-tuning (PEFT): Techniques that adapt large models by training a small number of additional parameters. "parameter-efficient fine-tuning (PEFT)~\cite{hu2021loralowrankadaptationlarge,schulman2025lora}."
- pedagogical instruction following: Optimizing models to follow teaching-oriented prompts and strategies. "optimizing it for {\it pedagogical instruction following} of teacher- or developer-defined prompts~\cite{modi2024learnlm}."
- post-hoc fine-tuning: Additional training applied to a base model after initial pretraining to target new behaviors. "from {\it post-hoc fine-tuning} of models to optimizing it for {\it pedagogical instruction following}"
- post-training: Adapting a pretrained model to a specific domain or task using additional data and objectives. "Post-training frontier models on domain-specific data has recently led to rapid progress toward human-level performance..."
- prompt engineering: Crafting input prompts to steer a model’s behavior without changing its parameters. "Prompt engineering has emerged as a stopgap, but the ability of prompts to encode complex pedagogical strategies in rule-based natural language is inherently limited."
- RAG-based approaches: Methods that augment generation with retrieved external information during inference. "RAG-based approaches to provide LLMs with high-quality examples."
- reinforcement learning from human feedback (RLHF): Training that uses human preferences as a reward signal to refine model outputs. "reinforcement learning from human feedback (RLHF)~\cite{christiano2017deep, ziegler2019finetuning}."
- speaker activity masks: Time-aligned indicators of who is speaking, used to aid diarization. "Speaker activity masks enable accurate diarization, followed by a multi-step cleaning process"
- squarified hierarchical map: A treemap layout algorithm that produces rectangles with aspect ratios near 1 for readability. "A squarified hierarchical map of the distribution of project topics based on a random sample of Polygence projects."
- stochastic methods: Techniques involving randomness to enable scalable, repeatable approximations or estimates. "These stochastic methods represent fast, scalable and reproducible measures of LLMs multi-turn performance."
- Student’s t-distribution: A probability distribution used to construct confidence intervals when sample sizes are small or variance is unknown. "calculated with the Studentâs t-distribution (light green and light red intervals show the error bars for human-to-human and human-to-GPT-4 conversations respectively)."
- student simulator: An AI model designed to emulate student behavior and responses in tutoring dialogues. "Our student simulator allows us to run multi-turn evaluations at scale on any LLMs."
- student talk time: The proportion of words spoken by the student in a dialogue, used as an engagement metric. "doubling student talk time, improving questioning style, increasing dialogue turns by 50\%, and greater personalization of instruction."
- sycophantic behavior: A model tendency to comply or agree excessively rather than challenge or teach effectively. "sycophantic behaviorâprioritizing compliance over pedagogyâis systematically encoded in model parameters through supervised fine-tuning~\cite{wei2021flanzeroshot} and reinforcement learning from human feedback (RLHF)~\cite{christiano2017deep, ziegler2019finetuning}."
- thinking models: LLM variants optimized for reasoning steps or explicit deliberation. "with only a few thinking models doing better."
- turn-taking: The alternation of speaking turns to maintain conversational flow. "Coherence smoothing and enforced turn-taking by merging consecutive same-speaker utterances."
- tutor persona: The consistent role-specific style and constraints a tutor adheres to in dialogue. "align context and tutor persona"
- Tukey's HSD: A post-hoc statistical test used after ANOVA to identify which group means differ. "A one-way Analysis of Variance (ANOVA) followed by Tukey's HSD post-hoc tests confirmed that these differences are highly statistically significant."
- wall-of-text: Overly long, dense model responses that hinder interaction quality. "âwall-of-textâ responses"
Practical Applications
Overview
The following applications derive from the paper’s core contributions: a privacy-preserving pipeline to curate authentic learning data; parameter-efficient fine-tuning (PEFT) of teacher and student models; a high-fidelity student simulator; and a scalable, reproducible multi-turn evaluation protocol using pedagogical proxies (e.g., student talk time, question style, conversational endurance, and context elicitation). Applications are grouped by immediacy and include sector links, likely tools/products/workflows, and assumptions/dependencies affecting feasibility.
Immediate Applications
The list below covers use cases that can be deployed now or with minimal integration work.
- Pedagogy-aware AI tutor copilot for education platforms
- Sector: Education (K–12, higher ed, tutoring marketplaces, MOOCs)
- What: Deploy TeachLM-style fine-tuned tutoring models that increase student talk time, ask open-ended questions, avoid “wall-of-text” responses, and personalize instruction.
- Tools/products/workflows: TeachLM API; LMS plugins (Canvas, Google Classroom); “Study Assistant” apps; guardrails to withhold direct answers and scaffold “desirable difficulties.”
- Assumptions/dependencies: Access to institutional data for calibration; teacher/admin buy-in; basic privacy and consent workflows; alignment with district policies.
- Multi-turn benchmarking and procurement support for edtech and AI vendors
- Sector: Software/AI, Education
- What: Use the paper’s student simulator + evaluation protocol to compare candidate LLMs on pedagogical proxies (e.g., conversational endurance, context elicitation).
- Tools/products/workflows: Synthetic dialogue test bench; “Pedagogy Metrics Dashboard”; A/B testing harness.
- Assumptions/dependencies: Reliable LLM judge; reproducible runs; legal rights to test third-party models; awareness of LLM-judge bias.
- Tutor quality analytics for human programs
- Sector: Education, Workforce development
- What: Instrument live sessions to track student talk time, question style, turn length, and context coverage; provide actionable coaching feedback to tutors/mentors.
- Tools/products/workflows: Session analytics pipeline; “Tutor QA” reports; coach dashboards; automated alerts when verbosity rises.
- Assumptions/dependencies: Consent to record; diarization/transcription fidelity; tutor acceptance of measurement; data governance.
- Teacher training with authentic student simulators
- Sector: Education (pre-service teacher programs, professional development)
- What: Role-play practice with fine-tuned student personas that faithfully mimic real learners’ talk-time, questioning patterns, and misconceptions across subjects.
- Tools/products/workflows: Simulation platform; configurable student profiles; scenario banks (coding, math, writing, project ideation).
- Assumptions/dependencies: Access to representative data; IRB and ethics review for training use; instructor-designed rubrics.
- Privacy-preserving data curation and anonymization workflow
- Sector: Education, Healthcare, Customer Support
- What: Adopt the paper’s pipeline for consent capture, PII removal, diarization, cleaning, and enterprise security to transform raw audio into training-quality text.
- Tools/products/workflows: Recording consent UX; diarization via dual-track audio masks; PII scrubbing modules; enterprise contracts preventing provider-side training.
- Assumptions/dependencies: Dual-track recording availability; robust anonymization; regulator-compliant storage; auditability.
- Prompt wrappers that approximate better pedagogy when fine-tuning is not possible
- Sector: Education, Software
- What: Lightweight prompt-based “pedagogy-wrapper” for existing LLMs that enforces context elicitation (first-mile), open questions, limits per-turn word count, and avoids premature wrap-up.
- Tools/products/workflows: Reusable prompt instructions; turn-taking controllers; verbosity caps; explicit checks for coding proficiency before project work.
- Assumptions/dependencies: Model cooperation with prompts; monitoring for drift; user-facing disclosures of limitations.
- Coding education plug-in that assesses skill before scaffolding
- Sector: Education (CS education, bootcamps), Software (developer learning)
- What: Automatically check a learner’s coding background and shape project scope and scaffolding accordingly (mirroring human tutor behavior).
- Tools/products/workflows: IDE and LMS add-ons; “Skill probe” module; personalized plan generator.
- Assumptions/dependencies: Accurate self-report or observable signals; detection robustness for novices; integration with course structure.
- Synthetic student–tutor dialogue generation for data augmentation
- Sector: Education AI, Research
- What: Use fine-tuned student models to generate high-fidelity, multi-turn dialogues for training and evaluation where real data is scarce.
- Tools/products/workflows: Dialogue generator; topic/persona configuration; quality filters; deduplication and leakage checks.
- Assumptions/dependencies: Simulator validity checks; prevention of simulator bias; carefully curated prompts to avoid mode collapse.
- Model selection guidance based on observed strengths
- Sector: Edtech, Procurement
- What: Inform procurement by aligning model choices with needs (e.g., Claude for higher student talk time; LearnLM for extending conversations; GPT-5 for coding skill checks).
- Tools/products/workflows: Comparative scorecards; requirement-to-model mapping; contracting playbooks.
- Assumptions/dependencies: Rapid model iteration; periodic re-benchmarking; API availability and pricing.
- Research adoption of the multi-turn evaluation protocol
- Sector: Academia, Edtech R&D
- What: Apply the protocol to replicate and extend findings; run controlled studies of LLM pedagogy across tasks and demographics.
- Tools/products/workflows: Standardized metrics; reproducible pipelines; shared benchmark suites.
- Assumptions/dependencies: Access to student simulators; institutional review for human-in-the-loop validations.
- Daily-life study assistants for self-learners
- Sector: Consumer education
- What: Pedagogy-aware study companions that ask better questions, personalize instruction, and avoid spoon-feeding, suitable for language learning, math, science, and writing.
- Tools/products/workflows: Mobile/web apps; “Don’t just tell—ask” modes; goal-setting and reflection prompts.
- Assumptions/dependencies: User tolerance for “desirable difficulties”; affordability; clear disclosures and opt-outs.
Long-Term Applications
The list below includes uses that require further research, scaling, validation, or infrastructure changes.
- District-scale deployment and rigorous RCTs demonstrating learning gains
- Sector: Education policy and districts
- What: Integrate pedagogy-aware AI tutors into classrooms and homework at scale; run randomized controlled trials measuring achievement, retention, and equity impacts.
- Tools/products/workflows: SIS/LMS integration; teacher co-design; monitoring and guardrails; independent evaluation partners.
- Assumptions/dependencies: Funding; union and community engagement; IRB approvals; device and connectivity access.
- Sector-wide multi-turn pedagogy standards and accreditation
- Sector: Policy, Standards bodies
- What: Codify multi-turn pedagogical benchmarks (talk time, context elicitation, question quality) as certification criteria for educational AI tools.
- Tools/products/workflows: Standards consortium; public benchmarks; audit protocols; model cards with pedagogy metrics.
- Assumptions/dependencies: Broad stakeholder agreement; mechanisms for periodic re-certification; compliance dovetailing with existing procurement rules.
- National data consortia and privacy-preserving fine-tuning (federated/secure enclaves)
- Sector: Education, Policy, Privacy tech
- What: Collaborate with initiatives (e.g., National Tutoring Observatory) to pool anonymized interactions; adopt federated learning or secure enclaves to fine-tune without centralizing PII.
- Tools/products/workflows: Data trusts; governance charters; federated PEFT pipeline; privacy audits.
- Assumptions/dependencies: Legal frameworks; data harmonization; differential privacy; sustainable funding.
- Multimodal, affect-aware tutors that adapt to student cognitive and emotional states
- Sector: Education, Healthcare (patient education)
- What: Incorporate audio/video and affect signals to calibrate difficulty, pacing, and support (e.g., frustration detection).
- Tools/products/workflows: Multimodal capture; consent and opt-in UX; affect models; ethical oversight.
- Assumptions/dependencies: Robust emotion detection; bias and fairness mitigations; strong privacy protections.
- Cross-sector adaptation to patient and customer education
- Sector: Healthcare, Customer Success
- What: Pedagogy-aware LLMs to teach treatment plans, medication adherence, or complex product onboarding—favoring questions and context gathering over dumping instructions.
- Tools/products/workflows: Patient education portals; product coaching chat; compliance logging.
- Assumptions/dependencies: Domain-specific data; clinical governance; liability management; accessibility standards.
- Adaptive curriculum and project orchestration agents
- Sector: Education (project-based learning, competency-based education)
- What: Agents that dynamically scope projects, set milestones, and adjust difficulty based on student context and progress—mirroring Polygence’s longitudinal mentoring.
- Tools/products/workflows: Milestone planners; portfolio trackers; artifact review modules; feedback loops.
- Assumptions/dependencies: Reliable progression signals; integration with assessment systems; teacher oversight.
- Open-source Pedagogy SDK (metrics, simulators, dialogue generator)
- Sector: Research, Open-source community
- What: Package proxies, student simulators, synthetic generation tools, and evaluation harnesses for reproducible pedagogy research and product prototyping.
- Tools/products/workflows: Versioned datasets; APIs; community benchmarks; reproducibility guidelines.
- Assumptions/dependencies: Licensing clarity; maintainers; governance for contributions; safeguards against misuse.
- Adaptive difficulty calibration (“desirable difficulties” engine)
- Sector: Education, Workforce training
- What: LLM policies that withhold answers, sequence hints, and progressively increase challenge to optimize retention and transfer.
- Tools/products/workflows: Difficulty calibrators; hint policies; mastery tracking; reinforcement signals.
- Assumptions/dependencies: Ground-truth outcomes to tune policies; avoidance of frustration or disengagement; ethical guardrails.
- Classroom co-tutor orchestration (group work, peer learning)
- Sector: Education
- What: Agents that facilitate small-group discussions, coach peer feedback, and balance participation, bringing multi-turn pedagogy to collaborative settings.
- Tools/products/workflows: Group discourse analytics; equitable participation prompts; teacher-facing dashboards.
- Assumptions/dependencies: Real-time moderation; fairness constraints; compatibility with classroom routines.
- Internationalization and equity-centered localization
- Sector: Global education
- What: Extend models and benchmarks across languages, dialects, cultures, and access contexts to ensure broad representativeness and equitable outcomes.
- Tools/products/workflows: Multilingual fine-tuning; culturally responsive pedagogy profiles; low-bandwidth deployment modes.
- Assumptions/dependencies: Diverse training data; local partnerships; ongoing bias audits.
- Continuous evaluation and maintenance pipelines for rapidly evolving base models
- Sector: Software/AI Ops
- What: Establish ongoing re-benchmarking, re-tuning, and regression checks as base LLMs change.
- Tools/products/workflows: CI/CD for pedagogy; canary tests; versioned scorecards; rollback mechanisms.
- Assumptions/dependencies: Stable APIs; cost controls; ops staffing; governance over updates.
- Evidence-informed policy frameworks for AI tutoring adoption
- Sector: Policy, Districts, Ministries of Education
- What: Translate evaluation findings into procurement criteria, teacher PD requirements, data safeguards, and student protection policies.
- Tools/products/workflows: Policy blueprints; stakeholder consultations; oversight committees; public transparency reports.
- Assumptions/dependencies: Political will; consensus-building; enforcement capacity; alignment with child safety laws.
Collections
Sign up for free to add this paper to one or more collections.