- The paper introduces a congestion game framework for MoE routing that identifies surge, stabilization, and relaxation phases through effective congestion parameter tracking.
- It employs a multi-type mean-field game extension to handle token heterogeneity, ensuring a unique equilibrium and a 30% improvement in L1 error for held-out predictions.
- Empirical results demonstrate a non-monotonic evolution of γ_eff, highlighting a critical tradeoff between achieving load balance and promoting expert specialization.
Three-Phase Dynamics in Mixture-of-Experts Routing: A Congestion Game Perspective
Overview
This work presents a formal framework rooted in congestion and mean-field game (MFG) theory to analyze the evolution of load balancing during Mixture-of-Experts (MoE) model pretraining. By introducing and empirically tracking an effective congestion coefficient γeff throughout the training trajectory of two open-source models (OLMoE-1B-7B and OpenMoE-8B), the paper uncovers three distinct training phases—surge, stabilization, and relaxation—characterized by specific trends in the tradeoff between expert load balance and expert specialization. The framework is extended with multi-type MFGs to account for token heterogeneity, and the authors carefully articulate both the theoretical significance and the predictive limits of their congestion-based modeling.
Theoretical Model: MoE Routing as a Congestion Game
Mixture-of-Experts architectures route tokens to a subset of M available experts. The routing process can be conceptualized as a finite-state congestion game where:
- Players: Tokens.
- Resources: Experts.
- Payoff structure: Each token's payoff depends on expert quality and a congestion penalty (load imbalance).
- Population regime: With a large number of tokens (N=2,048–$32,768$), mean-field game theory applies.
The per-expert cost function takes the form
ℓ(i,μ)=−qi+γμi,
with qi representing expert quality and γ the congestion coefficient. The resultant equilibrium solution is a temperature-scaled softmax over effective expert qualities, with the “temperature” directly tied to the congestion parameter. The model exhibits a strictly convex Rosenthal potential, guaranteeing uniqueness and interiority of the equilibrium.
Crucially, the static single-type equilibrium does not outperform temperature-scaled softmax in held-out load prediction. Its principal explanatory value lies in revealing the meaning and evolution of the temperature parameter during learning.
Training Dynamics: Discovery of Three Phases
Tracking the fitted γeff parameter across 20 training checkpoints for OLMoE-1B-7B and six for OpenMoE-8B, a highly non-monotonic, three-phase trajectory emerges. This is the central empirical result.
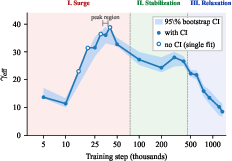
Figure 1: Effective congestion $\gamma_{\mathrm{eff}$ across OLMoE-1B-7B training reveals surge, stabilization, and relaxation phases; the inverted-U trajectory is undetectable via static, post-hoc analysis.
- Surge Phase (Early, Steps 5K–50K): The router rapidly escalates enforcement of load balancing, as evidenced by γeff rising from M0 to a peak in the M1–M2 range. Routing entropy increases, while expert quality spread (M3) sharply decreases due to initial convergence.
- Stabilization Phase (Mid, Steps 100K–400K): M4 plateaus (24–28), indicating a steady-state load balance regime while individual experts continue to specialize internally (with M5 dropping further). The router maintains a high-entropy, near-uniform distribution.
- Relaxation Phase (Late, Steps 500K–1.2M): The learned router increasingly prioritizes assigning tokens to differentiated experts over maintaining strict balance; M6 declines from M7 to M8, while M9 is largely flat.
This trajectory is invariant to methods of expert quality estimation and is replicated across models with different N=2,0480, N=2,0481, and layer patterns, including OpenMoE-8B.
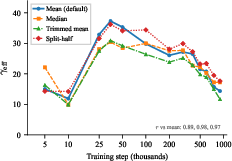
Figure 2: The observed three-phase behavior of N=2,0482 is robust across different quality estimation methods (N=2,0483), excluding proxy artifacts as an explanation.
Analytical Extensions and Empirical Validation
Decomposition of Effective Congestion
N=2,0484 consists of an explicit component N=2,0485 from the routing auxiliary loss, and an implicit component N=2,0486 absorbed by the optimizer during training:
N=2,0487
Empirically, N=2,0488, with convergence ratios frequently N=2,0489–$32,768$0.
Multi-Type MFG for Token Heterogeneity
A $32,768$1-type extension introduces token heterogeneity, where each token type has its own expert quality vector and population share. The coupled equilibrium, strictly convex in its multi-type Rosenthal potential, yields
- Uniqueness and interiority guarantees,
- Improved held-out layerwise predictions (avg. $32,768$2 decrease in $32,768$3 error).
However, independent per-cluster softmax performs even better on well-balanced layers, underlining that the multi-type MFG’s strength is structural (guaranteed uniqueness and coupling), not necessarily predictive for already uniform distributions.
Scope Diagnostics and Limiting Factors
- Anti-concentration threshold $32,768$4 is defined analytically, establishing a “safety margin” for avoiding expert collapse.
- Top-$32,768$5 truncation bounds are derived; the static MFG model only holds significant predictive advantage when $32,768$6 is not too small.
- Continuation spread ($32,768$7) quantifies the error introduced by per-layer myopic independence, correlating with observed fit degradation.
Empirical Results
- The non-monotonicity of $32,768$8 (factor $32,768$9 between peak and final values) is significant and outside the range of sampling noise.
- The explicit auxiliary loss is a small fraction of total balance pressure—the optimizer’s dynamics dominate.
- The three-phase pattern is specific to pretraining; it is absent in later-stage annealing/fine-tuning checkpoints.
- The static equivalence between MFG equilibrium and temperature-scaled softmax is confirmed numerically to within ℓ(i,μ)=−qi+γμi,0 in ℓ(i,μ)=−qi+γμi,1 error.
- Across diverse architectures, the static MFG model is only useful for ℓ(i,μ)=−qi+γμi,2 regimes.
Implications and Future Directions
The three-phase dynamics suggest that early-stage training should be attuned to fostering balance (as indicated by rapidly growing ℓ(i,μ)=−qi+γμi,3), possibly with strong auxiliary loss, while late-stage training could relax balance constraints to allow for expert selectivity. The identification and monitoring of ℓ(i,μ)=−qi+γμi,4 throughout pretraining could serve as a diagnostic for the health of routing dynamics and early warning of expert collapse (as ℓ(i,μ)=−qi+γμi,5 approaches ℓ(i,μ)=−qi+γμi,6).
Theory and empirical results imply MoE optimizers build much more internalized balance than explicit objectives would indicate. This raises open questions for architectural design and balance scheduling:
- Can explicit control or adaptive scheduling of ℓ(i,μ)=−qi+γμi,7 (and thus ℓ(i,μ)=−qi+γμi,8) during training yield better utilization or improved specialization?
- How does token population structure affect routing dynamics and specialization in large-scale, non-uniform data distributions?
- Is the observed three-phase pattern universal across scales and architectures, including production-scale sparse MoE systems?
Conclusion
This work reframes MoE token routing as a mean-field congestion game, exposing the non-monotone, triphasic evolution of the balance-quality tradeoff during pretraining. While static equilibrium analysis reduces to familiar softmax form, tracking the effective congestion parameter reveals a tension in MoE optimization: balance is prioritized early, specialization and quality later. The methodology quantitatively characterizes the dynamics, provides both practical diagnostics and theoretical insights, and motivates new directions for load balancing and training strategy in scalable MoE architectures.