- The paper introduces LAER-MoE, a system-level load balancing strategy using Fully Sharded Expert Parallelism to tackle dynamic routing imbalance.
- It employs a load balancing planner that adaptively re-layouts experts per iteration to diminish All-to-All communication overhead and tail latency.
- Empirical evaluations show up to 1.69x acceleration and robust convergence, confirming the approach's efficacy in large-scale distributed MoE training.
LAER-MoE: Systemic Load Balancing for Efficient Distributed Mixture-of-Experts Training
Introduction and Motivation
Mixture-of-Experts (MoE) models prevail as an effective architecture for scaling LLMs to trillions of parameters by activating only a sparse subset of experts per token. However, distributed MoE training introduces critical system bottlenecks due to dynamic routing imbalance: overloaded experts induce tail latency and inflate communication costs, notably in All-to-All exchanges. The paper "LAER-MoE: Load-Adaptive Expert Re-layout for Efficient Mixture-of-Experts Training" (2602.11686) proposes a system-level remedy, focusing on direct mitigation of expert load imbalance via flexible parameter re-layout, departing from the limited efficacy and convergence penalties of algorithmic balancing.
Analysis of Load Imbalance and System Challenges
The dynamic routing mechanism in MoE layers results in recurring expert overloads across training iterations, producing substantial latency and communication overhead. Empirical profiling during Mixtral-8x7B training exposes severe imbalance, with overloaded experts persisting as the bottleneck in almost every iteration, and All-to-All communication time rising from under 10% to over 40% of iteration time.
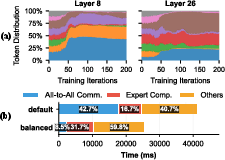
Figure 1: (a) Token distribution during Mixtral 8x7B training reveals significant expert imbalance. (b) Time breakdown shows communication overhead swells under imbalance.
Algorithmic balancing via auxiliary losses improves routing distribution at the expense of slowed convergence, requiring more steps to achieve equivalent model quality.
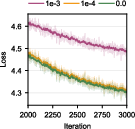
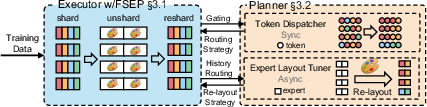
Figure 2: Loss curves for varying auxiliary loss weights, demonstrating increased convergence steps with higher weights.
System-level solutions in prior art (e.g., expert replication in FasterMoE, expert relocation in SmartMoE, FlexMoE) are fundamentally constrained by added re-layout overhead, which penalizes adjustment frequency and restricts timely optimization. Thus, there is a marked need for a paradigm enabling low-overhead, per-iteration re-layout.
Fully Sharded Expert Parallelism (FSEP)
The central innovation is Fully Sharded Expert Parallelism (FSEP), which adapts the principles of FSDP to expert parallelism. FSEP partitions each expert's parameters across all devices; during training, each device reconstructs only the subset of experts needed per iteration through efficient All-to-All communication. This design differs fundamentally from classic expert parallelism (EP), enabling arbitrary expert layout per device in each iteration and decoupling memory bottlenecks from static assignment.
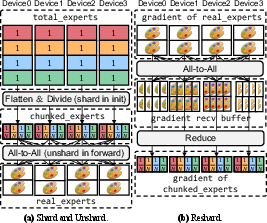
Figure 3: FSEP architecture, with N=4, E=4, C=2: every device stores a shard and reconstructs full experts as needed.
Efficient scheduling fuses re-layout operations with parameter prefetching and gradient synchronization, hiding communication overhead behind computation. FSEP thus achieves balanced throughput with trivial overhead compared to traditional FSDP+EP.
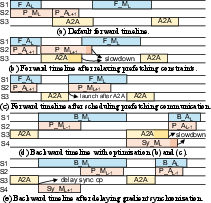
Figure 4: Overlapping communication in FSEP executor to minimize impact on computation.
Quantitative communication analyses reveal that as cluster size increases, FSEP's communication volume approaches that of FSDP+EP, and empirical prefetching overlap is achievable for realistic token counts per device.
Load Balancing Planner: Greedy, Adaptive, Topology-Aware
Exploiting FSEP's flexibility, LAER-MoE integrates a load balancing planner which dynamically monitors token routing and determines optimal expert re-layout and routing strategies for each iteration. The planner decouples expert replication/placement and routing, combining a heuristic greedy expert layout tuner (priority-queue based replica allocation, topology-aware greedy placement) with a lite routing algorithm that minimizes inter-node token transfers and evenly distributes load.
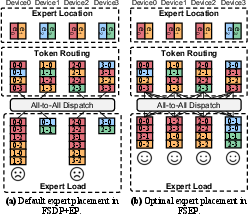
Figure 5: FSEP permits per-iteration expert re-layout, balancing load dynamically compared to fixed layouts.
The overall workflow fuses CPU-side layout tuning and GPU-side token dispatch, with layerwise asynchronous planning that does not impede training immediacy.
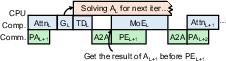
Figure 6: LAER-MoE workflow integrates planner and executor with per-layer layout/routing decisions.
Implementation Details
LAER-MoE builds atop Galvatron, integrating heterogeneous parallel strategies (FSEP for MoE layers, FSDP elsewhere), fine-grained recomputation of expert computations, and custom CUDA kernels for All-to-All communication without excess buffer overhead. Host-to-device and device-to-host transfers are fully asynchronous, ensuring maximal GPU utilization. Triton-based token rearrangement and planner kernels maintain scalability, with multiprocess CPU-side solver for expert layout.
Experimental Results
Evaluation on Mixtral-8x7B, Mixtral-8x22B, and Qwen-8x7B with e8k2 and e16k4 expert configurations demonstrates LAER-MoE achieves up to 1.69x acceleration over SOTA Megatron, and 1.50x over FSDP+EP, with 1.39x speedup vs. FlexMoE. LAER-MoE outperforms baselines consistently across different datasets and model scales, due to dynamic expert layout and load adaptation.
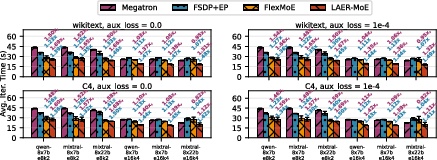
Figure 7: End-to-end performance on various architectures; LAER-MoE achieves maximal speedup by mitigating tail latency.
Convergence studies reveal that low auxiliary loss weights with LAER-MoE attain convergence rates equivalent to Megatron (relative error <1e−3), confirming numerical correctness and removal of convergence penalties associated with algorithmic balancing.
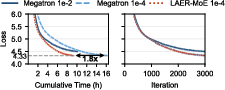
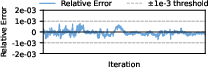
Figure 8: Training loss trajectories; LAER-MoE maintains precise convergence with lighter auxiliary loss.
Case studies breakdown end-to-end iteration times, revealing LAER-MoE reduces All-to-All communication fraction markedly (down to <20%), corresponding to a 2.68x speedup in communication.
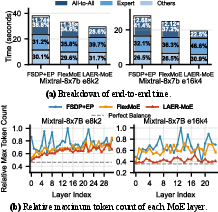
Figure 9: Case study: LAER-MoE achieves near-ideal maximum token count across devices per layer.
Planner performance is negligible (<0.1% of total iteration time) even at large scales, with expert layout solving scalable to 1024 GPUs without bottleneck.
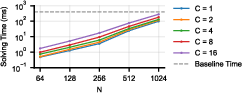
Figure 10: Expert layout solver performance remains sublinear in total iteration cost across cluster scales.
Ablation studies confirm the necessity of both communication optimizations and multi-replica expert layout schemes for achieving maximal speedup.

Figure 11: Ablation study: Combining communication optimization and enhanced layout solver ensures robust efficiency.
Implications and Future Directions
LAER-MoE fundamentally decouples system throughput from algorithmic constraints, enabling optimal load balancing with low auxiliary loss weights, thus facilitating higher model quality and robust training. The paradigm is orthogonal to prior hardware- and algorithm-level optimizations and can be composed with advanced communication schemes and kernel designs for further throughput improvements.
In balanced load scenarios, LAER-MoE matches FSDP+EP efficiency; its scalable communication volume and minimal memory overhead ensure practical deployment in large-scale clusters. Simulations demonstrate efficacy remains stable as cluster scale increases from 8 to 128 GPUs.
Future work should explore more advanced planners, tighter integration with hardware scheduling, and broader adoption with emerging MoE architectures and hybrid parallelisms for multimodal and multimodel training.
Conclusion
LAER-MoE delivers a mathematically robust, system-level solution for dynamic load balancing in distributed MoE training. Its introduction of Fully Sharded Expert Parallelism and adaptive planner achieves up to 1.69× speedups over state-of-the-art, with no loss in numerical precision or convergence quality. This approach advances the scalability and practical efficiency of trillion-parameter MoE deployments.