- The paper introduces expert-choice routing, which deterministically balances expert load and enables adaptive computation for diffusion language models.
- By implementing timestep-adaptive capacity scheduling, the study demonstrates up to 2x speedup in convergence and improved memory utilization.
- Retrofitting pretrained TC models with expert-choice routing leads to faster convergence and enhanced performance on downstream tasks.
Expert-Choice Routing Enables Adaptive Computation in Diffusion LLMs
Introduction and Motivation
Diffusion LLMs (DLMs) have garnered significant attention as scalable, parallelizable alternatives to autoregressive generation for text, leveraging iterative denoising with masked tokens. While the scaling of DLMs relies heavily on Mixture-of-Experts (MoE) architectures to expand parameter count without proportional inference compute overhead, existing DLMs inherited the token-choice (TC) routing paradigm from autoregressive systems. This inheritance introduces notable inefficiencies, especially load imbalance among experts, sub-optimal throughput, and inflexibility in compute allocation across denoising steps.
This work proposes expert-choice (EC) routing as a fundamentally superior routing paradigm for MoE DLMs. Unlike TC, EC enables explicit and deterministic control of expert workload, naturally supporting adaptive computation strategies such as timestep-dependent expert capacity schedules. The architectural argument is buttressed by rigorous empirical evidence of enhanced convergence speed, throughput, and validation performance, both for pretraining and downstream fine-tuning. Furthermore, EC can be retrofitted onto pretrained TC DLMs with only a router replacement, yielding immediate empirical benefits.
Structural Analysis: EC vs. TC Routing
Traditional TC routing allows each token to independently select its top-K experts, leading to emergent load distributions with substantial variance across experts and devices. This imbalance manifests as substantial straggler effects during parallel training, where less-loaded devices idle while waiting for overloaded devices. Mitigation strategies—such as auxiliary load-balancing losses and expert capacity factors—trade throughput for utilization and do not guarantee balance.
In contrast, EC routing inverts the assignment: each expert deterministically selects a fixed number of tokens for processing at each step, ensuring perfect load balance and eliminating dropped token overhead. As illustrated in the comparison schematic, TC introduces idle and overloaded experts for identical overall compute, whereas EC achieves uniform expert utilization and consequently uniform per-GPU memory usage.

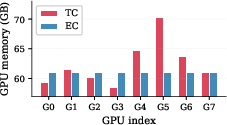
Figure 1: Illustration contrasting TC routing (left, imbalanced) against EC routing (right, balanced) in a 6x3 token-expert score matrix.
Empirical results demonstrate that EC routing achieves a 2× speedup in wall-clock convergence relative to TC baselines at matched FLOPs, with throughput gains between 1.5× and 2.1×, highlighting the system-level efficiency unlocked by deterministic capacity assignment.
Timestep-Adaptive Expert Capacity Scheduling
DLMs’ iterative denoising process introduces inherent heterogeneity in step-wise prediction difficulty, governed by the dynamic masking schedule. Masking ratios decrease as denoising progresses; however, TC routing cannot adaptively allocate computation to steps of varying difficulty due to its uncontrolled, emergent load profile.
By contrast, EC routing exposes per-step expert capacity as a direct control knob, enabling dynamically-varying compute schedules. Several capacity scheduling strategies were systematically evaluated—including linear, cosine, and Gaussian schedules and their reverses—under matched average compute.
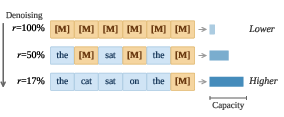
Figure 2: The linear-reverse scheduling strategy: As mask ratio r decreases, more expert capacity is assigned, focusing computation on critical denoising steps.
Empirical pretraining on OpenWebText and Nemotron-CC consistently marks the linear-reverse schedule as optimal: maximizing expert allocation at low mask ratios (late denoising steps) robustly reduces validation perplexity compared to static or high-mask-biased schedules.
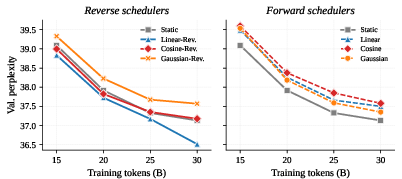
Figure 3: Scheduler performance comparison: Reverse schedulers (left) focusing on low-mask steps consistently outperform forward schedulers (right).
At 8B-A1B scale, dynamic EC routing with the optimal schedule surpasses static EC on perplexity, MMLU, and ARC-Challenge metrics at every checkpoint despite equivalent computational budgets.
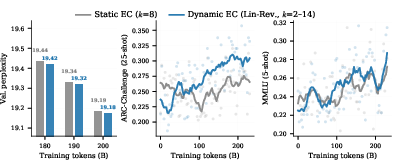
Figure 4: At 8B-A1B scale, dynamic EC achieves lower perplexity and higher MMLU and ARC scores throughout training relative to static EC.
Mechanistic Insights: Mask Ratio and Learning Dynamics
The empirical dominance of low-mask-favoring schedules is theoretically supported by a convergence rate analysis across mask ratio bins. Low-mask steps (few tokens masked) exhibit order-of-magnitude higher learning efficiency; thus, concentrating compute in these regions provides maximal marginal gains.
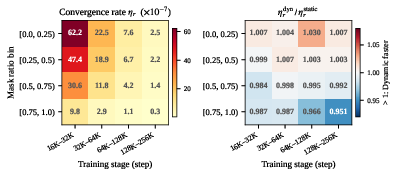
Figure 5: Mechanistic analysis reveals convergence rates ηr for low-mask bins outpace high-mask bins by more than an order of magnitude, and dynamic EC further amplifies learning where it matters most.
This insight demystifies the scheduler efficacy: extra compute at high-mask steps is mostly wasted, while at low-mask steps it substantially drives further loss reduction, justifying the design of adaptive, mask-aware capacity policies.
Retrofitting Pretrained TC DLMs
A salient practical finding is that pretrained TC DLMs can be retrofitted with EC (and dynamic EC) routing by merely updating the router—no re-initialization or architectural changes are required. Fine-tuning experiments on benchmarks including GSM8K, HumanEval, and MedQA show EC-retrofitted models not only converge faster, but also reach equal or improved peak accuracy under reduced decoding times compared to the original TC models.
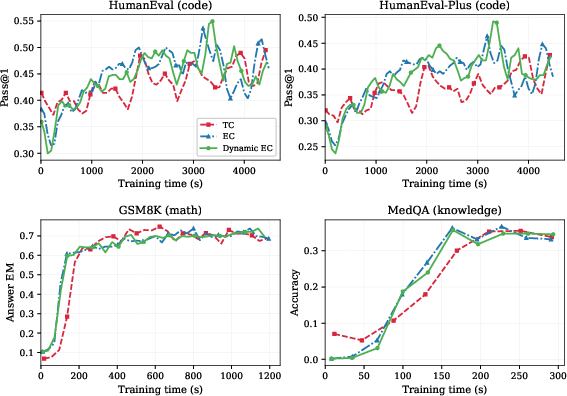
Figure 6: SFT retrofitting of TC DLMs to EC facilitates consistently faster convergence and often improved final accuracy across diverse downstream tasks.
Dynamic EC maximizes these gains, establishing that both during pretraining and transfer/fine-tuning, adaptive expert allocation is universally beneficial.
A potential concern of EC routing is incomplete token coverage by routed experts, especially as capacity varies. Empirical and theoretical analysis demonstrates this issue is negligible in practice: per-layer unrouted token ratios are low, shared experts guarantee full coverage, and the likelihood of a token being missed by all experts across all layers is vanishingly small.
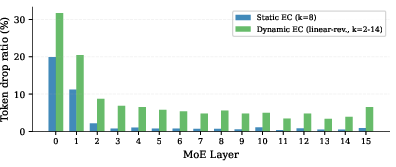
Figure 7: Token drop ratio per MoE layer remains below 1.1\% in static EC and only slightly higher with aggressive dynamic schedules, largely confined to early layers.
Ablations: Isolation of Routing Benefits
Detailed ablations on auxiliary loss strategies and capacity factors for TC confirm that all load-balancing mitigations are insufficient to bridge the inherent throughput and convergence speed gap with EC. The performance advantage is due neither to the presence of auxiliary losses nor to token retention policies, but the structural load balance that EC uniquely enforces.
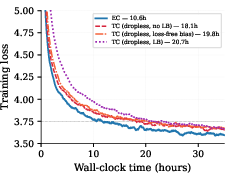
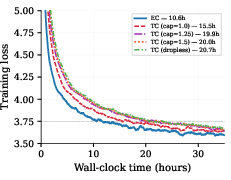
Figure 8: Auxiliary loss ablation: Variants of TC routing with and without auxiliary loss do not eliminate the convergence speed advantage of EC.
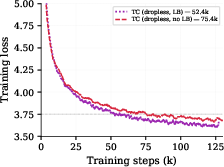
Figure 9: Per-step loss improves with auxiliary loss in TC, but wall-clock efficiency worsens due to system-level inefficiency.
This study extends and unifies previous lines of work across MoE architectures, diffusion-based language modeling, and adaptive computation. Prior studies in vision and language on MoE load balancing, and adaptive inference (e.g., early-exit, depth- or width-adaptive transformers), demonstrated that variance in computation requirements exists both across input tokens and model layers. This work shows that for DLMs, the dominant variation occurs temporally—across denoising steps.
Consequently, future research is well-motivated to explore learned scheduling policies (e.g., policy-gradient optimization, meta-learning for capacity assignment) and combine EC routing with token-level or layer-level adaptive compute mechanisms for maximal efficiency.
Further, the plug-and-play retrofitting mechanism for deployed LLMs offers a low-friction pathway to upgrade production systems for both efficiency and quality. The system-level implications—consistent memory utilization, removal of routing bottlenecks, and predictable compute scaling—are highly salient for hyperscale distributed training and inference.
Conclusion
Expert-choice routing is consistently superior to token-choice routing for MoE Diffusion LLMs, yielding deterministic load balance, higher hardware throughput, and enabling explicit, adaptive compute strategies across denoising steps. Mechanistic analysis confirms that concentrating expert compute at low mask ratios maximizes learning efficiency, and empirical studies validate that both pretraining and transfer learning settings benefit. The findings advocate for treating computation policy in DLMs as a dynamic, adaptable component, not a static architectural constant.
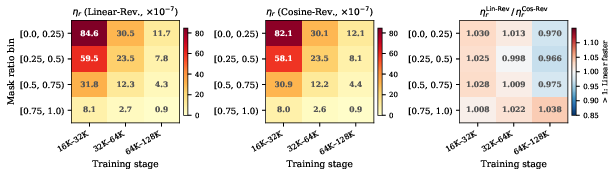
Figure 10: Per-bin convergence rate analysis comparing linear- and cosine-reverse schedules, confirming the robustness of the linear-reverse advantage.
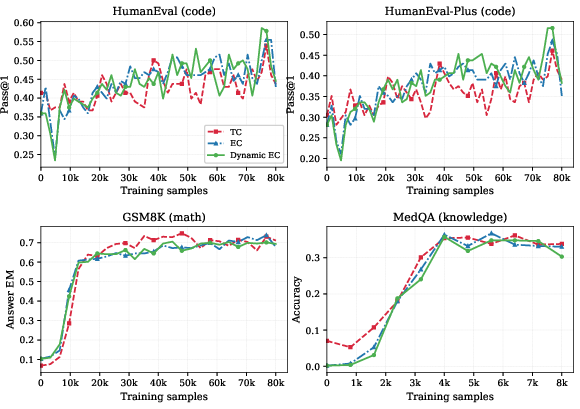
Figure 11: SFT retrofitting results versus sample count reaffirm EC and dynamic EC's consistent speed and performance advantages.
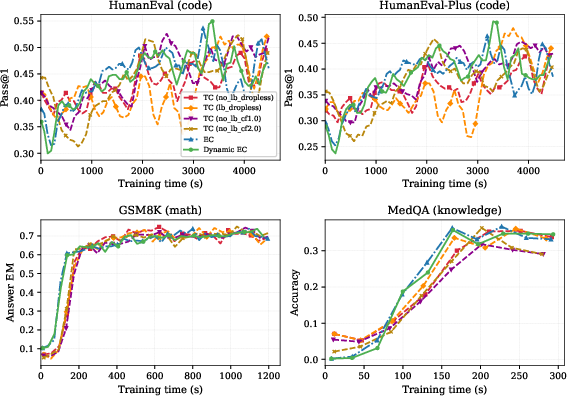
Figure 12: Comprehensive ablation of TC routing strategies confirms that EC and dynamic EC yield superior convergence behavior regardless of TC configuration.
These results suggest a paradigm shift toward adaptive, context- and step-aware expert assignment in large-scale DLMs, with substantial implications for next-generation model architecture, training, and deployment (2604.01622).