- The paper introduces a novel decentralized activation mechanism that replaces centralized routing with expert-internal, thresholded gating.
- It employs a unified dual load-balancing loss to interpolate between token and expert-centric balancing for uniform expert utilization.
- Empirical results demonstrate lower perplexity and enhanced downstream accuracy, with improved hardware efficiency under scalable conditions.
Routing-Free Mixture-of-Experts: Decentralized Sparse Activation for Efficient Scaling
Introduction
The Routing-Free Mixture-of-Experts (RFMoE) architecture represents a departure from classical Mixture-of-Experts (MoE) models by fully removing centralized routing, Softmax, TopK, and rigid load-balancing mechanisms. Instead, expert activation is determined autonomously by the experts themselves, with activation decisions driven by internal confidence scores and thresholding. This approach eliminates the information bottleneck and indirect optimization dynamics associated with centralized routers and provides a more flexible, bottom-up emergence of activation patterns.
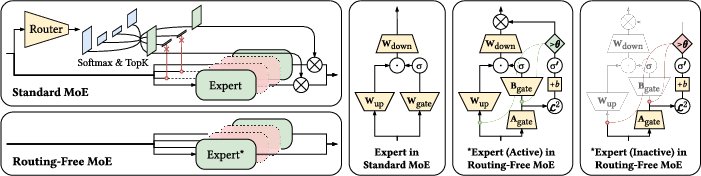
Figure 1: Standard MoE relies on routing to orchestrate expert activations. Routing-Free MoE let each expert purely-independently determine its own activation. Green indicates activated components; red for inactive components; yellow for trainable components.
The design motivation stems from limitations in conventional MoE: routers with small capacity must indirectly learn optimal expert allocation, TopK imposes input-invariant sparsity, and Softmax enforces competitive normalization that erases absolute suitability. Existing balancing strategies—token- or expert-centric—hard-code mutually exclusive constraints, limiting dynamic adaptation. RFMoE addresses these by fully decentralizing activation and devising a unified auxiliary loss framework to softly interpolate between token- and expert-balancing regimes.
Architecture and Training Dynamics
Decentralized Expert Activation
RFMoE adopts an adapted feed-forward network (FFN) for each expert, leveraging a low-rank internal gating mechanism. For input x, each expert computes a norm-based activation Gi(x)=ReLU(∥xAgate,i∥2−bi), where bi is a learnable expert-specific bias. A configurable global threshold θ then determines binary activation: $f_i(\mathbf{x}) = \mathds{1}\{G_i(\mathbf{x}) - \theta \geq 0\}$. This per-expert, per-token, bottom-up gating paradigm obviates the need for any centralized scoring or comparison.
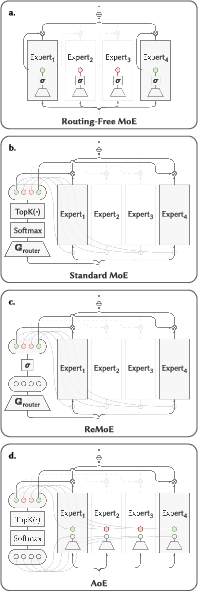
Figure 2: Architectural comparison between (a) Routing-Free MoE and (b) standard MoE: all sparse activation logic is internalized in the former.
Unified Dual Load-Balancing Framework
To reconcile the trade-off between expert- and token-balancing, RFMoE introduces an auxiliary loss,
LLB=μLEB+(1−μ)LTB
where LEB penalizes deviation from uniform expert utilization and LTB penalizes imbalance in activated experts per token. The interpolation parameter μ allows for continuum control between fully token-balanced and fully expert-balanced regimes.
Training employs a dynamic λt coefficient that tracks the empirical activation density towards a designated Gi(x)=ReLU(∥xAgate,i∥2−bi)0, applying strong regularization during warm-up and relaxing as balanced sparsity is achieved. All expert biases Gi(x)=ReLU(∥xAgate,i∥2−bi)1 initialize low to promote early exploration, and regularization intensity is scheduled adaptively.
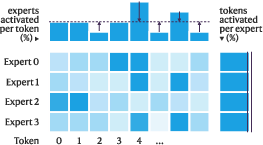
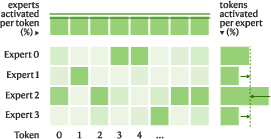
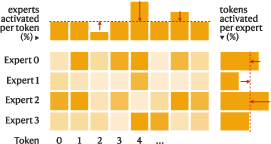
Figure 3: Expert choice (EC) ensures hard expert-balancing and optimizes token-balancing via training; Routing-Free MoE enables simultaneous soft optimization of both.
Emergent Activation Patterns
In contrast to standard MoE's per-layer hard-coded sparsity, RFMoE allows global or per-layer density targets. Notably, relaxing the per-layer constraint allows the network to self-organize its activation density in accordance with layer utility, obviating manually imposed inductive biases.
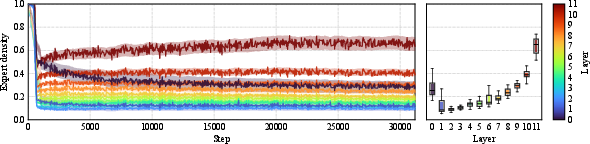
Figure 4: Evolution of expert activation across layers during training; the model self-organizes a structured, layer-differentiated activation pattern under global sparsity supervision.
Empirical Results
Benchmarks are conducted on OpenWebText pretraining at three scales (S/M/L), with evaluation across nine diverse language understanding tasks. RFMoE is compared against standard MoE, AoE, and ReMoE baselines under iso-compute conditions.
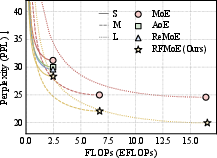
Figure 5: Routing-Free MoE consistently outperforms standard MoE, AoE, and ReMoE in language modeling perplexity under matched FLOP budgets.
Strong Results:
- RFMoE delivers lower validation perplexity at all tested scales, e.g., S: 27.42 vs. 31.22 (MoE); L: 19.97 vs. 24.58 (MoE).
- On downstream benchmarks, RFMoE provides a statistically significant average accuracy gain across 27 evaluation points (Gi(x)=ReLU(∥xAgate,i∥2−bi)2, paired t-test).
- Unlike standard MoE, RFMoE maintains performance gains under scaling, indicating enhanced robustness.
Training stability is improved: RFMoE tolerates larger learning rates without collapse, and the removal of TopK/Softmax mitigates asymmetric expert under-utilization. Ablation studies confirm that both the elimination of the router and the inductive biases (TopK/Softmax) are necessary for maximal improvement—partial ablations only yield intermediate gains.
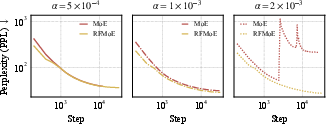
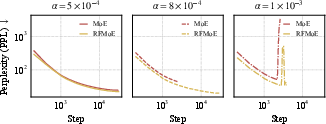
Figure 6: Training curves with different learning rates Gi(x)=ReLU(∥xAgate,i∥2−bi)3 at scale S: RFMoE enables stable convergence at higher Gi(x)=ReLU(∥xAgate,i∥2−bi)4 compared to rapid collapse for standard MoE.
Load-balancing interpolation (Gi(x)=ReLU(∥xAgate,i∥2−bi)5) is shown to be critical: best results are achieved for Gi(x)=ReLU(∥xAgate,i∥2−bi)6, with performance declining if only one balancing dimension is enforced.
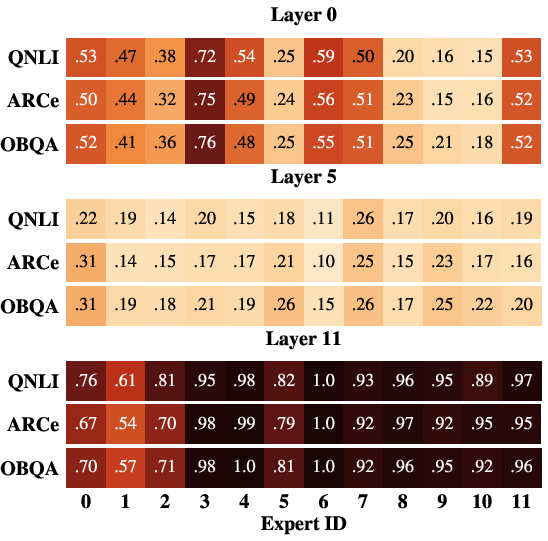


Figure 7: Activation heatmaps under pure token or expert balancing and balanced interpolation, demonstrating uniform expert utilization and domain-robust activation emerging only in the latter.
Practical and Theoretical Implications
From a hardware deployment perspective, RFMoE facilitates efficient expert parallelism. The removal of centralized routing and blocking communication patterns in dispatch/aggregation yields improved throughput, particularly under multi-device deployment and in low-latency autoregressive decode. Analytical and empirical results validate a significant reduction in communication barrier overhead.
RFMoE confers a practical advantage via the global threshold Gi(x)=ReLU(∥xAgate,i∥2−bi)7, which acts as a simple, interpretable control for the computational budget—practitioners can tune efficiency post hoc without retraining, with only marginal impact on average downstream task accuracy until aggressive sparsification.
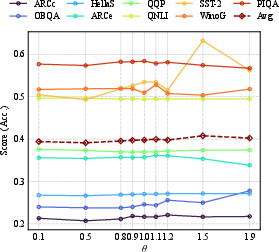
Figure 8: Per-benchmark accuracy across global threshold Gi(x)=ReLU(∥xAgate,i∥2−bi)8 shows that most benchmarks are robust, with best performance near the empirical density target.
Theoretically, the bottom-up self-activation mechanism of RFMoE suggests a shift in MoE scalability paradigms: rather than restricting expert allocation by hand-crafted global constraints, expert specialization and sparsity patterns are endogenously discovered, enabling the model to adapt its capacity distribution to both input- and layer-specific requirements.
Future Directions
RFMoE opens several lines for further exploration:
- Scaling to regimes Gi(x)=ReLU(∥xAgate,i∥2−bi)9 parameters and beyond, to verify persistence of training and inference advantages.
- Integrating auxiliary-loss-free balancing and hierarchical/structured expert pools.
- Investigating transfer to non-language domains (e.g., vision, code).
- Exploring fine-tuning, transfer, or adaptation mechanisms for routing-free architectures.
Potential limitations include unknown behavior in extremely large-scale, multi-lingual, or multi-modal training, as well as the unexplored interplay with quantization and knowledge distillation protocols.
Conclusion
Routing-Free MoE eliminates centralized routers, competitive normalization, and rigid assignment constraints, instead leveraging expert-internal confidence and adaptive dual balancing to achieve state-of-the-art perplexity, downstream task accuracy, and hardware efficiency. This design both clarifies optimization dynamics and paves the way for future MoE scaling and deployment with enhanced flexibility, stability, and interpretability.

