- The paper presents spatio-temporal sparse autoencoders that decompose video features into interpretable, monosemantic components using contrastive losses.
- It demonstrates that enforcing spatial and temporal consistency improves feature robustness, leading to significant gains in text-video retrieval performance.
- The work quantifies trade-offs between reconstruction accuracy and temporal coherence, offering actionable design insights for future video foundation models.
Interpreting Video Representations with Spatio-Temporal Sparse Autoencoders
Introduction
Sparse Autoencoders (SAEs) are an increasingly powerful tool for mechanistic interpretability in deep networks, having demonstrated strong results in decomposing language and static vision features into monosemantic and functionally meaningful components. However, their application to video representations has previously been unaddressed, especially in the context of preserving and leveraging the spatio-temporal structure inherent to video backbones such as DINOv2 and VideoMAE. The work titled "Interpreting Video Representations with Spatio-Temporal Sparse Autoencoders" (2604.03919) provides the first systematic investigation of SAEs for video. This essay will provide a detailed technical analysis of their methodology, empirical findings, and implications for both interpretability and the design of video foundation models.
Spatio-Temporal SAE Design
Standard SAE Pitfalls in Video
Applying standard (TopK) SAEs directly to video backbone activations involves flattening spatial and temporal axes, treating each spatio-temporal patch as independent. The authors demonstrate that while this recovers interpretable, monosemantic features, it catastrophically destroys temporal coherence: feature assignments for semantically persistent concepts (e.g., a pushing hand) become unstable across frames. Specifically, lag-1 autocorrelation of activations is reduced by 36% relative to the raw backbone (e.g., $0.277$ for TopK SAE versus $0.435$ for DINOv2), and the vast majority of SAE features fail to remain active over contiguous frames. Patch-wise hard selection causes this incoherence, a fundamental structural incompatibility with video data.
To resolve this, the authors introduce a set of augmented SAEs with spatio-temporal contrastive losses. Three primary variants are developed:
- Temporal (T-SAE): Encourages consistent activations at the same spatial position across adjacent frames.
- Separate (ST-SAE): Independently applies both horizontal spatial and temporal consistency losses.
- Raster (R-SAE): Serializes the spatio-temporal grid and encourages local consistency in the serialized order, thus unifying spatial and temporal contrast as one objective.
Each variant uses InfoNCE-based losses between positive pairs (semantically-aligned positions across time/space) and negatives (unmatched patches), with tunable weight and temperature. These losses are strictly post-hoc: the underlying video representation is not task-adapted, and all models operate in a fully frozen backbone regime.
In addition, hierarchical grouping is incorporated via Matryoshka BatchTopK: the dictionary is split into high- and low-abstraction units, with reconstruction encouraged from a small (e.g., 20%) subset. This organization further compresses action-relevant semantics and supports interpretability through feature hierarchy.
Empirical Findings: Trade-offs and Efficacy
Interpretability and Feature Typology
The authors provide compelling qualitative evidence that SAEs decompose video backbone features into three classes: scene elements (ubiquitous across templates), object-centric features (irrespective of action), and spatially specific, action-correlated concepts. Importantly, as illustrated below, standard SAEs yield features that "flicker"—appear and disappear erratically across time—whereas Matryoshka-structured SAEs resolve this into temporally robust units.
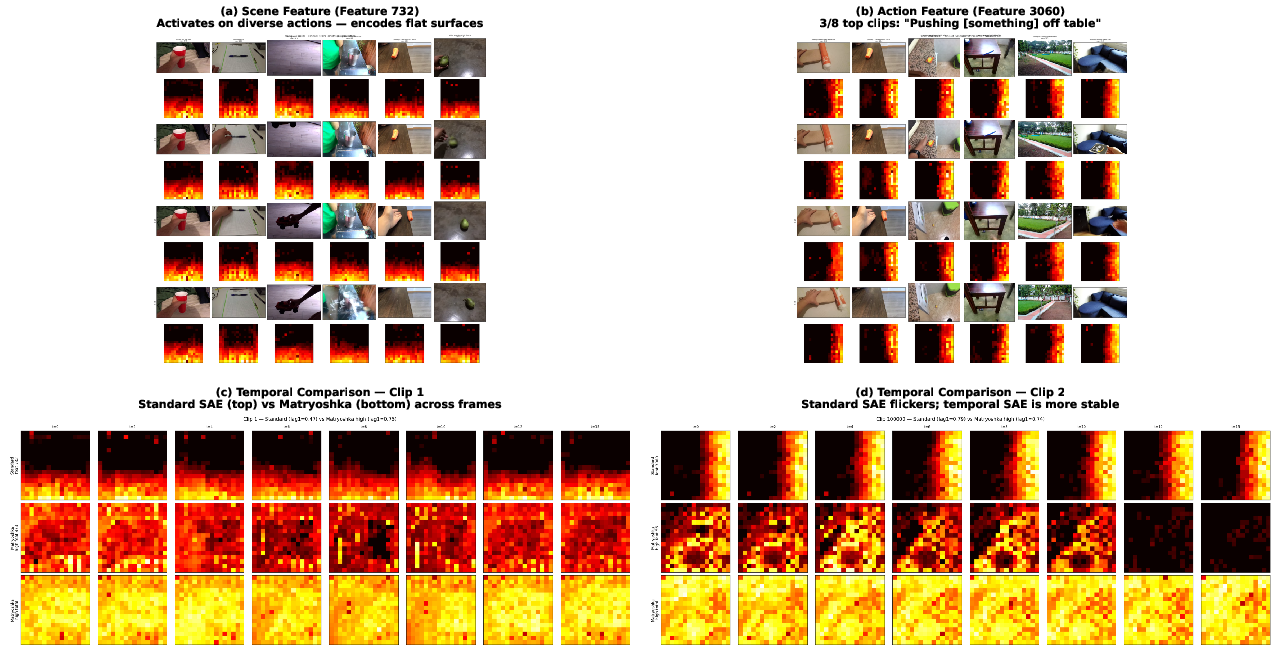
Figure 1: SAE features on DINOv2/SSv2 decompose into scene, object, and action features, with Matryoshka SAE achieving superior temporal coherence over standard SAE.
Quantitative Comparisons and Pareto Frontiers
Via an extensive ablation (over 29 hyperparameter configurations per variant), the authors establish several critical points:
- All SAE variants outperform raw features for downstream probes and retrieval. The best probe gain over baseline is +3.9%, and text-video retrieval (R@1) is improved up to 2.8× for DINOv2 and 1.9× for VideoMAE.
- Temporal coherence and reconstruction are in direct tension, modulated by contrastive loss strength or temperature. The trade-off is Pareto optimal: increasing weight/temperature improves coherence but degrades reconstruction R2.
- Matryoshka variants (especially Temporal+M) are uniformly dominant for balancing interpretability, temporal stability, and downstream discrimination. The lag-1 autocorrelation of Matryoshka SAEs can even exceed the raw backbone ($0.462$ vs $0.435$ in DINOv2).
MonoSemanticity and Metric Alignment Artifact
A key methodological result is that prior metrics for monosemanticity are subject to alignment artifacts: when evaluating VideoMAE versus DINOv2, monosemanticity metrics based on DINOv2 similarity show a 2.7× advantage for VideoMAE. When recomputed with a neutral (CLIP) similarity backbone, this gap vanishes, with both backbones yielding MS ≈0.68. Thus, cross-backbone interpretability comparisons must control for metric alignment.
Causal Feature Intervention
The authors carry out causal ablation by zeroing key SAE features identified by linear probing, demonstrating that predictive information is highly concentrated—especially for Temporal and Matryoshka-enhanced models. For example, ablating the top 10 features in Temporal-SAE reduces probe accuracy by −9.3 pp, in contrast to negligible drops for random ablations, demonstrating that learned sparse features indeed capture actionable and causal structure.
Retrieval and Semantic Alignment
SAE features dramatically improve text-video retrieval, bridging the semantic gap between dense visual features and linguistic templates. This is demonstrated both quantitatively (2.8$0.435$0–1.9$0.435$1 R@1 gains) and visually via qualitative comparisons on SSv2.
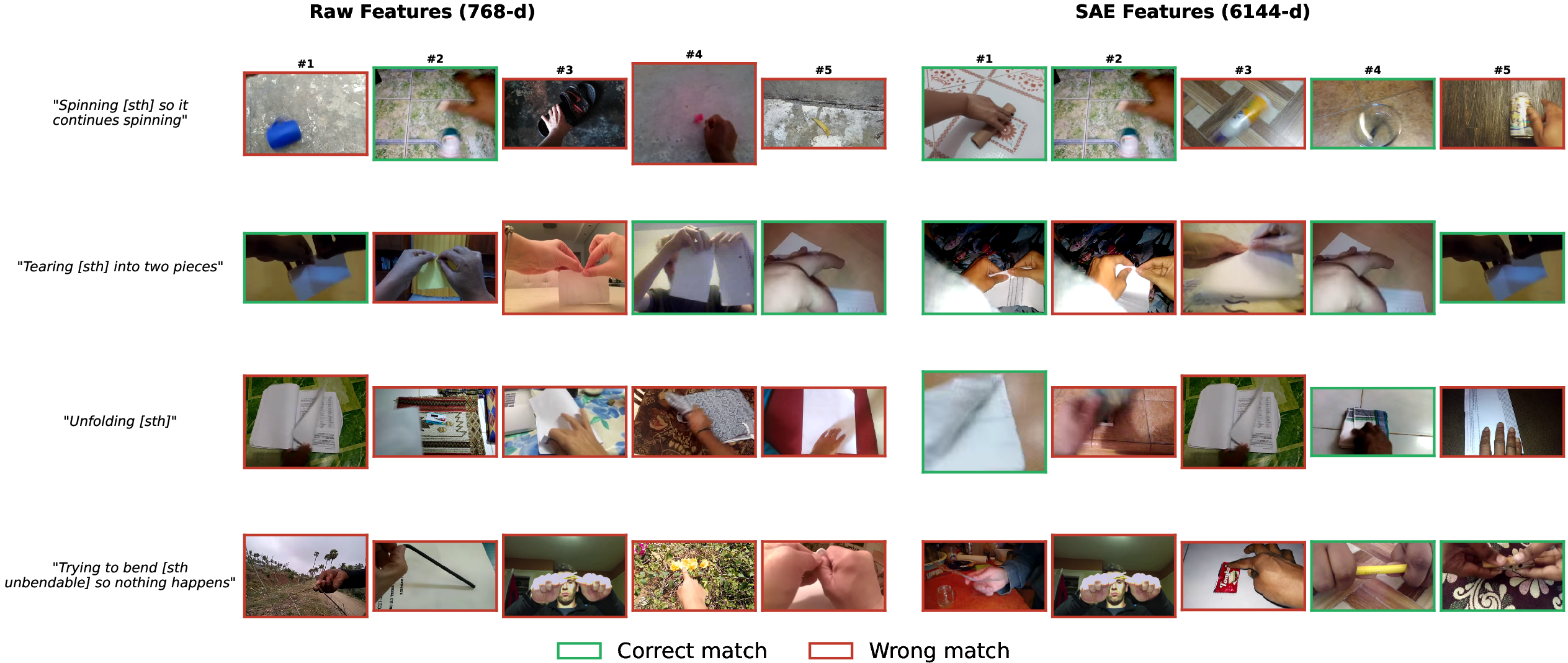
Figure 2: SAE features in text-video retrieval achieve higher precision, retrieving more template-matching clips than raw DINOv2 features.
Auxiliary Analyses
Smoothing and Soft Sparsity
Naïve post-hoc smoothing (e.g., EMA, Temporal Union TopK) can restore temporal coherence numerically, but only at the expense of downstream discrimination. In contrast, learned contrastive objectives retain both coherence and predictive utility. Soft sparsity (e.g., sparsemax/entmax activations with temperature scaling) can approach but not match TopK's discrete capacity or task performance; hard selection remains essential at current scales.
Backbones, Layers, and Dataset Generalization
Contrastive and hierarchical SAEs yield the largest gains for image-native backbones (DINOv2), which lack temporal pretraining. For VideoMAE and at earlier layers, the benefits are reduced as temporal structure is pre-learned. Results generalize to diverse datasets (Kinetics-400), though natural camera motion weakens the utility of fixed spatial-temporal pairing due to lack of explicit correspondence tracking.
Limitations and Recommendations
The method assumes largely static cameras (as in SSv2) due to fixed spatial correspondence between frames. Extension to significant camera motion would require integrating external correspondence mechanisms (e.g., optical flow), which would trade off model-agnosticism. The fixed dictionary size and sparsity level are inherited from prior language/image SAE research; improved or adaptive quantization could yield further improvements.
Theoretical and Practical Implications
This work identifies the contrastive loss strength as a global control axis for the trade-off between reconstruction, interpretability, temporal coherence, and discrimination in post-hoc feature decompositions of video models. This finding is both a design principle and a practical diagnostic when fitting interpretable models to high-dimensional, temporally structured data.
For mechanistic interpretability, the results demonstrate that SAEs, especially with hierarchical grouping, can surface distinct, temporally coherent, and causally significant latent features from video foundation model representations. These results open avenues for model steering, representation auditing, and causal intervention in any context where video understanding is required.
From a model development perspective, the inability of soft sparsity to replicate the task-utility of hard TopK, and the identification of metric alignment artifacts in monoSemanticity scoring, motivate both new evaluation protocols and hybrid soft/hard latent selection schemes.
Future directions include integration with non-rigid correspondence tracking for dynamic camera scenarios, richer hierarchical decompositions, and joint adaptation of contrastive and reconstruction objectives during the backbone pretraining phase. This is expected to further enhance both interpretability and transfer in high-capacity spatio-temporal networks.
Conclusion
"Interpreting Video Representations with Spatio-Temporal Sparse Autoencoders" (2604.03919) provides a rigorous treatment and practical framework for extracting temporally coherent, interpretable features from video backbones. The systematic investigation of contrastive, spatial, and hierarchical objectives shows that the trade-off between fidelity and coherence is not a pathology but a tunable property, subject to a clear Pareto frontier. These methods offer a solid foundation for post-hoc interpretability in both video-only and multimodal settings and suggest a suite of design strategies and evaluation caveats for future video representation research.