- The paper introduces a language-based world model that integrates vision and planning through hierarchical semantic compression and structured abstraction.
- It employs a Tree of Captions and iterative LLM Self-Refine to generate interpretable goal-plan trajectories from raw video data.
- The model achieves state-of-the-art improvements on benchmarks such as VPA, RoboVQA, and WorldPrediction, validated by both quantitative metrics and human evaluations.
Vision Language World Model: Planning with Reasoning from Video
Introduction
The paper "Planning with Reasoning using Vision Language World Model" (VLWM) (2509.02722) presents a novel approach to high-level world modeling for planning and reasoning in real-world environments. VLWM is designed to bridge the gap between perception-driven vision-LLMs (VLMs) and reasoning-oriented LLMs by learning to represent and predict world dynamics directly in language space. This enables interpretable, efficient, and semantically abstract planning from raw video observations, supporting both fast reactive (system-1) and reflective reasoning-based (system-2) planning paradigms.
VLWM is trained on a large corpus of instructional and egocentric videos, leveraging a hierarchical semantic compression pipeline (Tree of Captions) and iterative LLM-based Self-Refine to extract structured goal-plan trajectories. The model learns both an action policy and a dynamics model, facilitating direct plan generation and cost-minimizing plan search via a self-supervised critic. The system achieves state-of-the-art results on multiple benchmarks, including Visual Planning for Assistance (VPA), RoboVQA, and WorldPrediction, and demonstrates superior plan quality in human preference evaluations.
VLWM Architecture and Abstraction Pipeline
VLWM is a JEPA-style world model that predicts abstract representations of future world states, rather than generating raw sensory observations. The core innovation is the use of natural language as the abstraction interface for world modeling, enabling semantic and temporal abstraction, interpretability, and computational efficiency.
VLWM's training pipeline consists of two main stages:
- Semantic Compression via Tree of Captions: Raw video is compressed into a hierarchical tree of detailed captions, generated from local video segments using state-of-the-art video encoders and captioning models. Hierarchical agglomerative clustering is used to segment the video into monosemantic units, preserving both fine-grained and long-horizon information.
- Structured Plan Extraction via LLM Self-Refine: The Tree of Captions is processed by an LLM (Llama-4 Maverick) using iterative Self-Refine to extract structured representations: goal description, goal interpretation (initial and final states), action descriptions, and world state changes. This process ensures high-quality, task-relevant abstractions suitable for world modeling and planning.
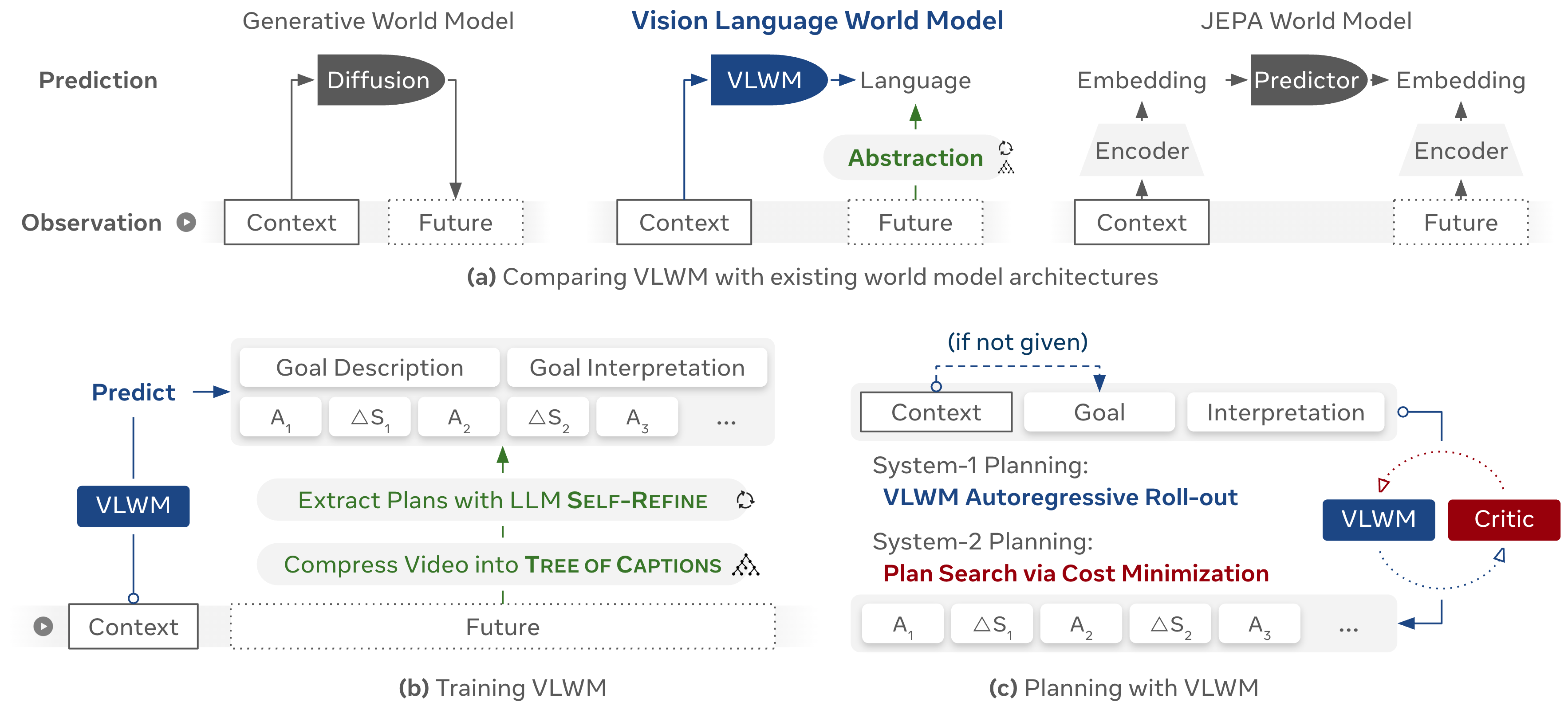
Figure 1: VLWM overview: JEPA-style world model predicting structured textual representations of future world states from video context, supporting both system-1 and system-2 planning.
The model is trained to predict these abstractions autoregressively, enabling direct plan generation (system-1) and facilitating internal simulation of candidate plans for cost-based reasoning (system-2).
System-1 and System-2 Planning Paradigms
VLWM supports two distinct planning modes:
- System-1 (Reactive Planning): Plans are generated via direct text completion, using the learned action policy. This mode is computationally efficient and suitable for short-horizon, in-domain tasks, but lacks foresight and the ability to revise suboptimal decisions.
- System-2 (Reflective Planning with Reasoning): Multiple candidate action sequences are generated and simulated via VLWM roll-outs. A self-supervised critic model evaluates the semantic distance between the predicted future states and the desired goal state, assigning costs to each candidate. The planner selects the lowest-cost plan, enabling internal trial-and-error reasoning and optimal plan selection.
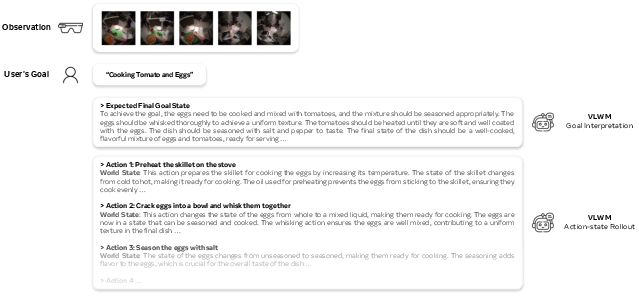
Figure 2: Example VLWM action-state trajectory: system-1 generates a plan via one roll-out, system-2 searches over multiple actions by inferring new world states and minimizing a cost function.
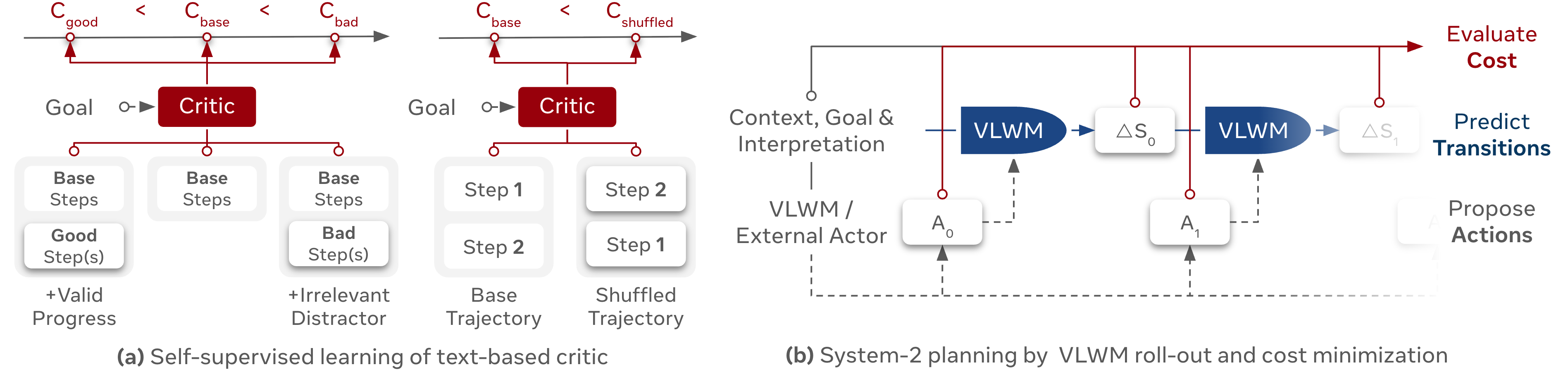
Figure 3: System-2 planning: critic assigns costs to candidate plans based on semantic progress toward the goal; planner selects the lowest-cost trajectory.
The critic is trained in a self-supervised manner using ranking losses over valid, distractor, and shuffled trajectories, leveraging both VLWM progress data and external preference/similarity datasets.
Training and Data Generation
VLWM is trained on 180k videos (over 800 days of duration) from diverse sources (COIN, CrossTask, YouCook2, HowTo100M, Ego4D, EgoExo4D, EPIC-KITCHENS-100), generating 21M nodes of unique captions and 2.2M goal-plan trajectories. The critic model is trained on paired data from vision-language world modeling, preference modeling, and semantic similarity datasets, using a ranking loss with cost centering regularization.
VLWM is initialized from PerceptionLM-8B and trained with a batch size of 128, 11.5k token context length, and 32-frame visual context inputs. The critic is initialized from Llama-3.2-1B and trained for one epoch with a batch size of 128 and 1536 token context length.
Experimental Results
Visual Planning for Assistance (VPA)
VLWM sets a new state-of-the-art on the VPA benchmark, outperforming existing planners (DDN, LTA, VLaMP, VidAssist) and frequency-based heuristics across all metrics (SR, mAcc, mIoU) and evaluation horizons. VLWM achieves absolute gains of +3.2% in SR, +3.9% in mAcc, and +2.9 points in mIoU over prior best results.
Human Preference Evaluation: PlannerArena
PlannerArena is a human evaluation framework inspired by ChatbotArena, where annotators select preferred plans from anonymous model outputs. VLWM System-2 achieves the highest Elo score (1261), outperforming Llama-4-Maverick (1099), VLWM System-1 (992), Qwen2.5VL (974), ground truth plans (952), and PerceptionLM (721). Notably, ground truth plans are often less preferred than VLWM-generated plans, highlighting limitations of current procedural planning datasets.

Figure 4: PlannerArena annotation interface and results: VLWM System-2 achieves highest Elo and win rates across datasets.
RoboVQA and WorldPrediction
VLWM achieves 74.2 BLEU-1 on RoboVQA, outperforming all baselines, including specialized robotic LLMs. On WorldPrediction procedural planning, VLWM-critic-1B establishes a new state-of-the-art with 45.4% accuracy, demonstrating robust generalization and semantic cost modeling.
Critic Model Evaluation
VLWM-critic-1B outperforms Qwen3-Embedding and Qwen3-Reranker baselines on goal achievement detection (98.4% on VLWM-Instruct, 92.7% on VLWM-Ego, 72.9% on OGP-Robot). Ablation studies show that removing goal interpretation or world state descriptions significantly reduces performance, especially on OOD data, confirming the importance of explicit semantic representations.
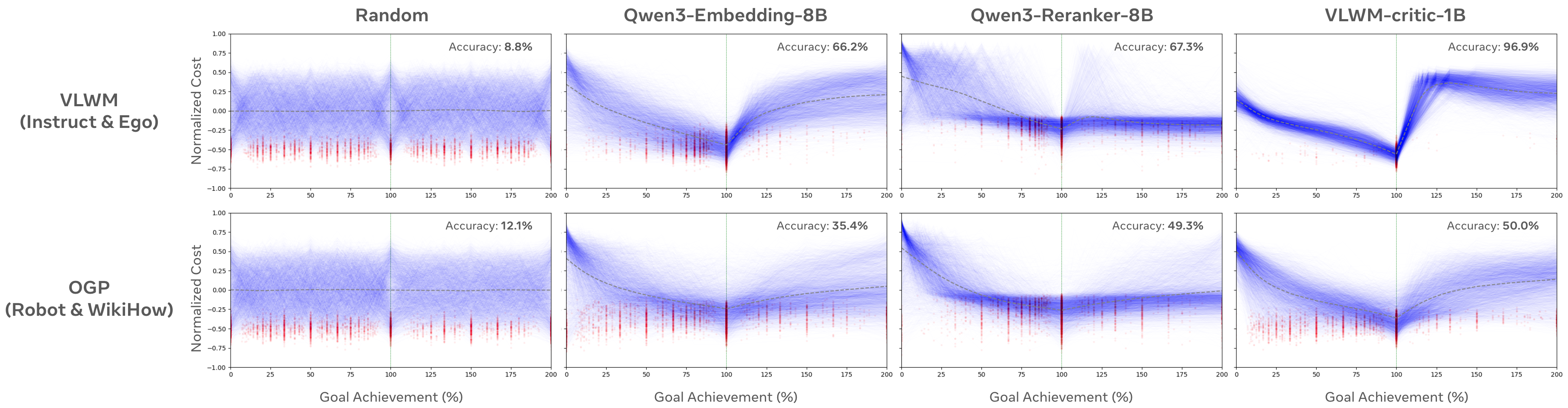
Figure 5: Cost curves from critic models: VLWM-critic-1B accurately detects goal achievement, while baselines show noisy or suboptimal behavior.
Implementation Considerations
VLWM's abstraction pipeline enables efficient training and inference by compressing high-volume video data into structured textual representations. The use of language as the world state interface facilitates interpretability, integration with LLM engineering ecosystems, and seamless incorporation of prior knowledge. System-2 planning allows for scalable internal search and reasoning, supporting long-horizon and complex tasks.
Resource requirements include large-scale video datasets, high-capacity video encoders and captioning models, and LLMs with extended context length. Training VLWM and the critic requires multi-node GPU clusters (e.g., 8×H100 GPUs per node). Deployment strategies should consider the trade-off between system-1 efficiency and system-2 optimality, as well as the integration of external actors or constraints in the planning loop.
Implications and Future Directions
VLWM demonstrates that language-based world models can serve as a powerful interface for bridging perception, reasoning, and planning, advancing AI assistants beyond imitation toward reflective agents capable of robust, long-horizon decision making. The explicit modeling of semantic cost and internal trial-and-error reasoning enables superior plan quality and generalization, as validated by both benchmark and human preference evaluations.
Future developments may include:
- Scaling VLWM to broader domains (e.g., web navigation, multi-agent systems, real-time robotics)
- Integrating multimodal chain-of-thought reasoning and external tool use
- Enhancing critic generalization via richer preference and similarity datasets
- Exploring hierarchical planning and meta-reasoning over abstract world models
- Open-sourcing models and data to facilitate reproducibility and community benchmarking
Conclusion
VLWM introduces a principled framework for high-level world modeling and planning from video, leveraging semantic compression and language-based abstraction to enable interpretable, efficient, and reflective reasoning. Its dual-mode design supports both fast reactive and optimal reflective planning, achieving state-of-the-art results across multiple benchmarks and human evaluations. The approach establishes language-based world models as a viable and powerful paradigm for advancing embodied AI planning and reasoning.

