- The paper proposes a dual-branch MAE framework that integrates video and image modalities using both intra-modal and cross-modal contrastive learning.
- It employs high masking ratios (90–95% for video, 75–90% for image) and semantic distillation to capture nuanced spatiotemporal and contextual features.
- Empirical results show state-of-the-art performance on benchmarks like SSv2, K400, UCF101, and HMDB51, highlighting its efficacy for action recognition.
CrossVideoMAE: Self-Supervised Image-Video Representation Learning with Masked Autoencoders
Motivation and Context
CrossVideoMAE addresses a critical limitation in video-based Masked Autoencoders (MAEs): the inability to fully capture nuanced semantic attributes and spatiotemporal correspondences necessary for robust action recognition. Existing MAEs tend to focus on generic spatial-temporal patterns, often missing contextually rich and continuous action-specific features. The proposed framework leverages both video sequences and sampled static frames, integrating mutual spatiotemporal information and semantic knowledge in a feature-invariant space. This joint intra-modal and cross-modal contrastive learning paradigm is designed to enforce invariance to augmentations and facilitate effective semantic knowledge distillation, thereby enhancing the quality of learned representations for downstream tasks.
Methodology
Architecture Overview
CrossVideoMAE employs a dual-branch architecture: a video branch and an image branch, both based on ViT-B/16. The video branch utilizes SpatioTemporalMAE for intra-modal pre-training, while the image branch leverages a pre-trained MAE for cross-modal semantic distillation. Both branches operate with high masking ratios (90–95% for video, 75–90% for image), which is shown to be optimal for representation learning.
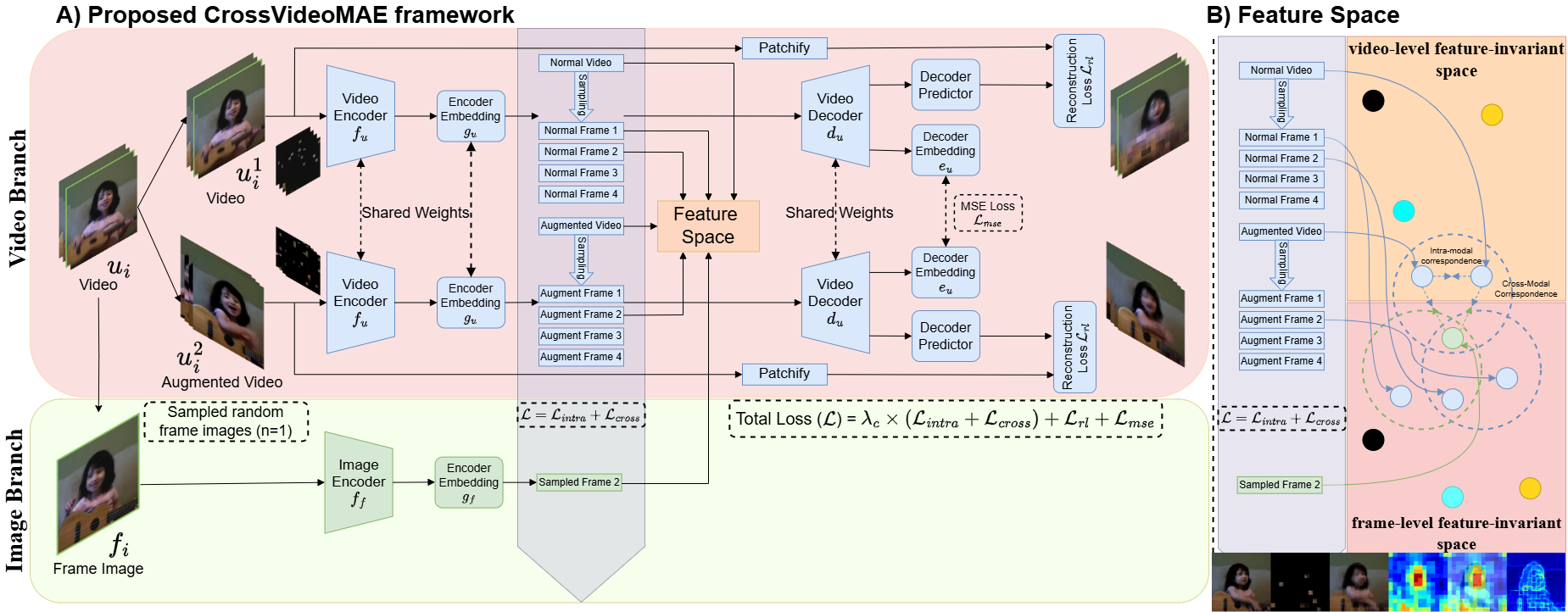
Figure 1: The CrossVideoMAE framework with video and image branches, illustrating intra-modal and cross-modal contrastive learning objectives at both video and frame levels.
The model is pre-trained jointly across video and image domains using a combination of intra-modal and cross-modal contrastive learning objectives at both the video and frame levels. For downstream tasks, only the video branch encoder is retained.
Intra-Modal Contrastive Learning
Intra-modal contrastive learning is applied at both video and frame levels to enforce view-invariant representations. For each video, two views (raw and augmented) are generated via spatiotemporal and spatial augmentations. The encoder projects these views into a feature-invariant space, and the NT-Xent loss is used to maximize similarity between positive pairs and minimize similarity with negatives within the batch. Frame-level embeddings are sampled from video-level embeddings to capture temporal variations.
Cross-Modal Contrastive Learning
Cross-modal contrastive learning aligns feature embeddings between video sequences and their corresponding sampled frames. The image encoder projects sampled frames into the invariant space, and the model maximizes cosine similarity between video and frame-level features. This strategy compels the model to learn from more challenging positive and negative samples, enhancing representation capability beyond intra-modal alignment.
Reconstruction and MSE Losses
Reconstruction and MSE losses are employed to ensure fidelity in the decoded outputs and to improve the feature embedding of visible tokens. The MSE loss is computed between the decoder outputs of original and augmented videos, while the reconstruction loss is the mean squared error between the predicted and target representations for both views.
Joint Objective
The overall pre-training objective is a weighted sum of intra-modal and cross-modal contrastive losses, reconstruction loss, and MSE loss:
L=λc×(Lintra+Lcross)+Lrl+Lmse
Implementation Details
- Backbone: ViT-B/16, shared weights, ~87M parameters.
- Input: 16 frames per video, 224×224 resolution, patch size 2×3×16×16, yielding 1568 tokens.
- Masking: Random masking, optimal at 90–95% for video, 75–90% for image.
- Augmentations: Random resizing, cropping, horizontal flipping, random erasing, mixup, cutmix.
- Optimization: AdamW, batch size 32, 8 GPUs, decoder depth 4.
- Test-Time Adaptation (TTA): 20 gradient updates per batch during inference, reducing GPU memory and pre-training time.
Empirical Results
CrossVideoMAE achieves state-of-the-art performance on UCF101, HMDB51, Kinetics-400 (K400), and Something-Something V2 (SSv2) datasets. Notably, it outperforms previous methods in both full fine-tuning and linear evaluation settings, with the most significant gains on SSv2 due to effective semantic alignment from sampled frames.
- SSv2 Acc@1: 73.7% (best in class)
- K400 Acc@1: 83.2% (best in class)
- UCF101 Acc@1: 97.6% (best in class)
- HMDB51 Acc@1: 78.4% (best in class)
Ablation studies confirm that joint intra-modal and cross-modal contrastive learning, high masking ratios, and random masking strategies are critical for optimal performance. Increasing decoder depth up to four blocks improves accuracy, with diminishing returns beyond that.

Figure 2: Self-attention maps visualization of CrossVideoMAE, demonstrating effective learning of spatiotemporal and semantic representations across original, masked, and reconstructed frames.
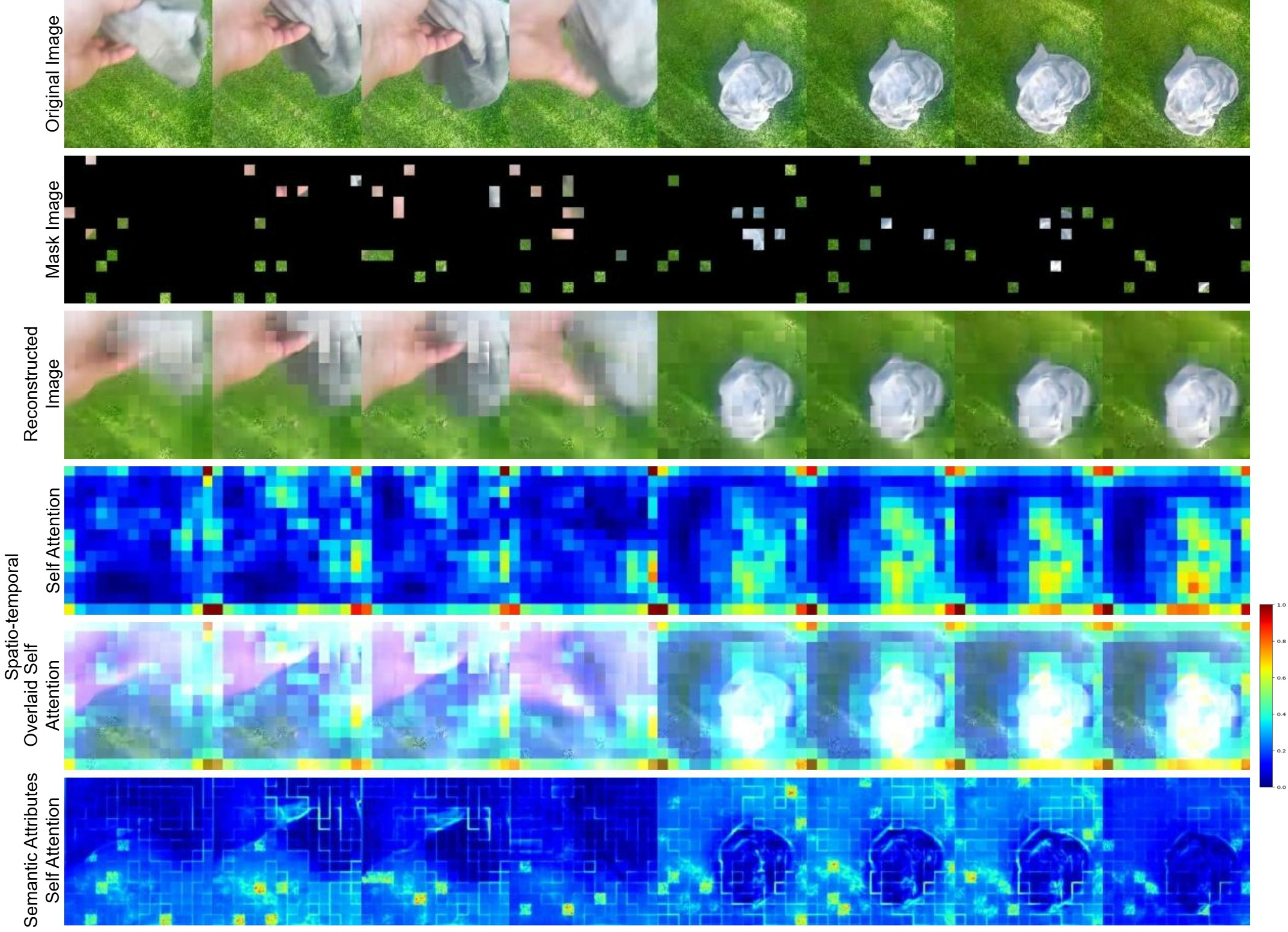
Figure 3: Example self-attention maps on K400, highlighting the model's focus on action-relevant regions.
Figure 4: Example self-attention maps on SSv2, showing robust semantic attribute extraction under high masking ratios.
Qualitative Analysis
Self-attention map visualizations reveal that CrossVideoMAE consistently attends to semantically relevant regions, such as hands and objects involved in actions, even under aggressive masking. The model demonstrates strong invariance to augmentations and effective semantic knowledge transfer from sampled frames to videos.
Practical Implications and Future Directions
CrossVideoMAE's architecture and training paradigm enable efficient, label-free video representation learning with reduced computational resources. The framework is highly transferable to downstream tasks such as action recognition, video retrieval, and potentially video captioning. The reliance on sampled frames for semantic distillation suggests future work could explore automated frame selection strategies or extend the approach to other modalities (e.g., audio, text).
The demonstrated gains in representation quality and resource efficiency position CrossVideoMAE as a robust foundation for scalable video understanding systems. Further research may investigate its integration with multimodal transformers, domain adaptation, and real-time inference in resource-constrained environments.
Conclusion
CrossVideoMAE introduces a principled approach to self-supervised image-video representation learning, leveraging joint intra-modal and cross-modal contrastive objectives, high masking ratios, and semantic knowledge distillation from sampled frames. The method achieves superior performance across multiple benchmarks, validating its effectiveness for spatiotemporal and semantic representation learning. The framework's design and empirical results suggest promising avenues for future research in efficient, scalable video understanding.

