- The paper demonstrates that explicit memory actions (commit, expand, fold) enable efficient context compression with minimal information loss.
- It employs dual-form reasoning entities to archive summaries and retrieve detailed steps, supporting robust long-horizon inference.
- Experimental results reveal notable reductions in token usage and inference time while maintaining or improving accuracy.
LightThinker++: Explicit Memory Management for Efficient and Robust LLM Reasoning
Motivation and Background
Current LLM-based reasoning demonstrates substantial progress on complex problems, primarily via long-form Chain-of-Thought (CoT) and o1-like iterative prompting protocols. However, these successes incur significant computational and memory overhead, especially as solution traces lengthen. The quadratic scaling of self-attention and the linear KV-cache growth in Transformer architectures impose practical constraints, frequently making large-scale or long-horizon reasoning infeasible in both research and deployment settings. Prevailing methods for mitigating this overhead—prompt engineering with shorter outputs, output-pruned distillation, and KV-cache token selection—exhibit intrinsic trade-offs: static or rule-based approaches risk dropping salient logical information, while token-by-token dynamic techniques add substantial inference latency and can ossify reasoning flexibility.
LightThinker++ addresses these bottlenecks by introducing a reasoning-time, model-driven compression and memory management framework that enables LLMs to strategically compress intermediate thoughts, dynamically regulate context granularity, and flexibly retrieve critical details as demanded by downstream logical dependencies. This paradigm is motivated by cognitive economy principles: high-level reasoning relies on preserving only signal-critical content, archiving atomic steps when feasible, and expanding upon previously folded details only when logical bottlenecks or error correction necessitate backtracking.
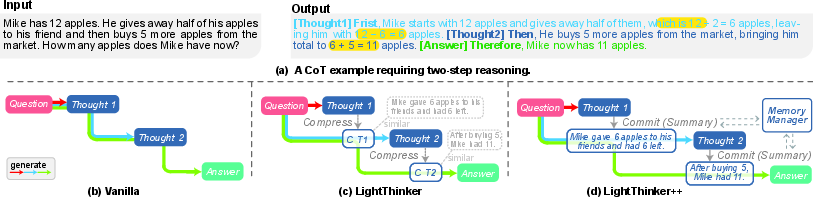
Figure 1: Visualization of compressed reasoning paradigms, contrasting baseline and LightThinker(++) thought manipulation, token compression, and explicit summary management.
The LightThinker Family: Implicit Compression and Explicit Management
Implicit Compression
LightThinker introduces implicit, representation-level compression by training LLMs to condense each multi-token thought into a parameterizable set of gist tokens, using specialized attention masks to enforce information bottlenecks and force semantically faithful abstraction. This approach draws from the Information Bottleneck principle, regulating token growth while preserving minimal subsequent reasoning fidelity by distilling salient reasoning content and discarding verbose or redundant detail.
Thought-level segmentation (tied to explicit logical or newline boundaries) empirically outperforms token-level segmentation (fixed-size intervals), as semantically aligned compression captures more critical anchors and avoids blurring inter-step dependencies.
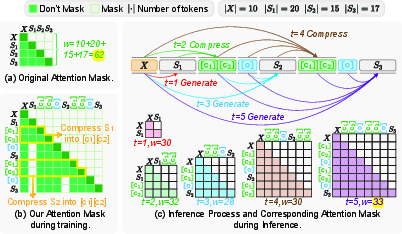
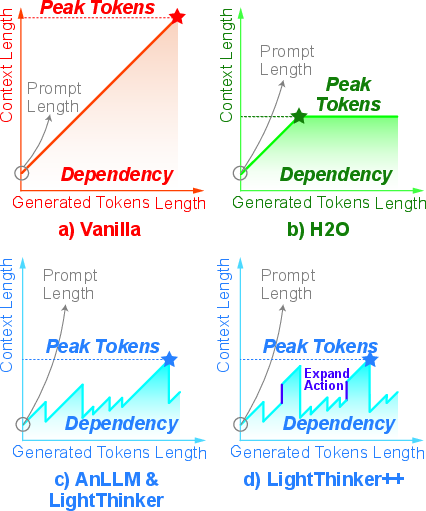
Figure 2: Overview of LightThinker’s step-wise compression pipeline and attention controls for training and inference.
However, LightThinker’s fixed-capacity, lossy compression is fundamentally non-reversible. For complex reasoning, high-density information segments—e.g., algebraic constraints, variable bindings, key constants—can be destroyed, breaking subsequent logical chains and making error recovery impossible.
Explicit Memory Management: LightThinker++
LightThinker++ extends the architecture with a set of explicit memory actions—commit, expand, fold—enabling the LLM to actively instantiate, archive, and recover atomic reasoning steps. Each step is represented as a dual-form reasoning entity Ik=(Rk,Zk), with Rk capturing the full step trace and Zk its distilled summary. Model-driven policies dynamically toggle historical reasoning segments between “archived” (summary-only) and “active” (full trace available) states.
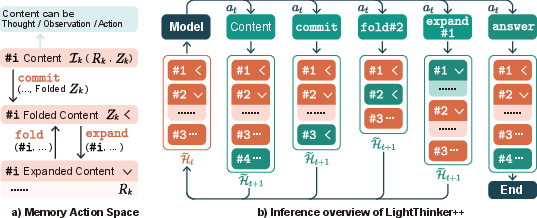
Figure 3: Schematic of LightThinker++ memory primitives, dual-form entities, and stateful context masking for stepwise archival and recovery.
Commit actions instantiate and archive summaries, expand recovers detailed evidence (subject to dependency constraints and symmetry, i.e., fold is only permitted after expand for the same entity), and fold reverts views to the summarized state, regularizing the active memory footprint.
Notably, LightThinker++’s training pipeline employs a synthetic expert trajectory generation process, enforcing environmental context constraints (simulating memory-limited environments) and pruning non-monotonic or redundant management sequences. This ensures that compressed trajectories remain functionally sufficient and causally well-grounded in logical progression.
Experimental Results: Standard Reasoning Efficiency and Robustness
LightThinker and LightThinker++ were evaluated on multiple code and reasoning-heavy open benchmarks (GSM8K, MMLU, GPQA, BBH) with both Qwen2.5-7B and Llama3.1-8B backbones. Metrics included accuracy (Acc), inference time, peak and total token dependence (Dep).
On the Qwen2.5-7B backbone, LightThinker achieves:
- Peak token usage reduction by 70%
- Inference time savings of 26%
- Only 1% accuracy loss versus vanilla baselines
LightThinker++ further delivers:
- Comparable or superior accuracy (+2.42% on average in Budget mode)
- 69.9% reduction in peak memory tokens in Throughput mode, with stable accuracy
- 45% and 33.7% reductions in peak and Dep, respectively, in Budget mode
These results are robust under increased batch scaling and persist in the presence of tight generation or context-length budgets; compressed-context models maintain or improve logical pass rates despite operating with a fraction of the original token context.
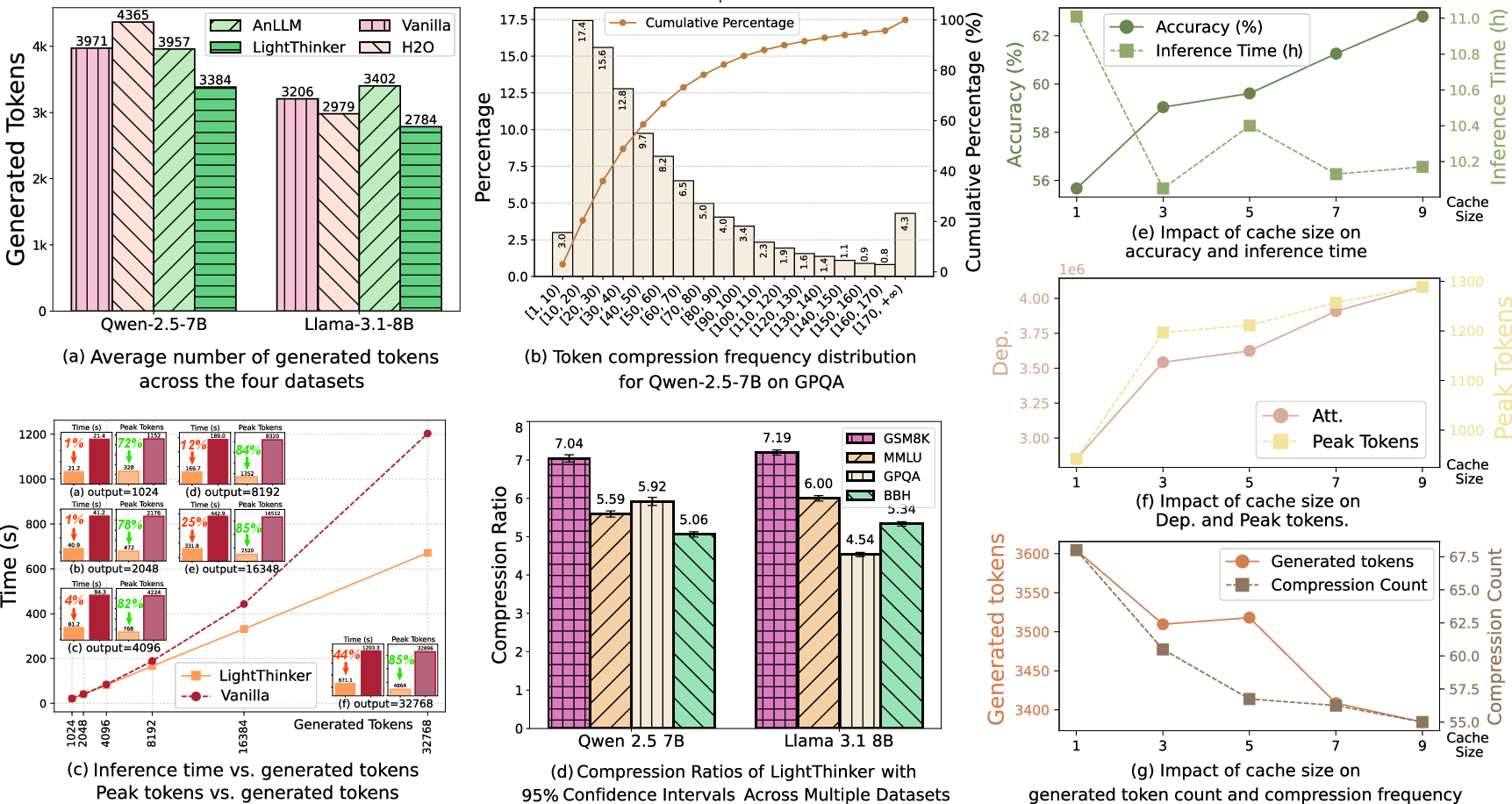
Figure 4: Efficiency analysis highlighting token reduction, compression ratio distribution, and cache size ablation results for LightThinker and baselines.
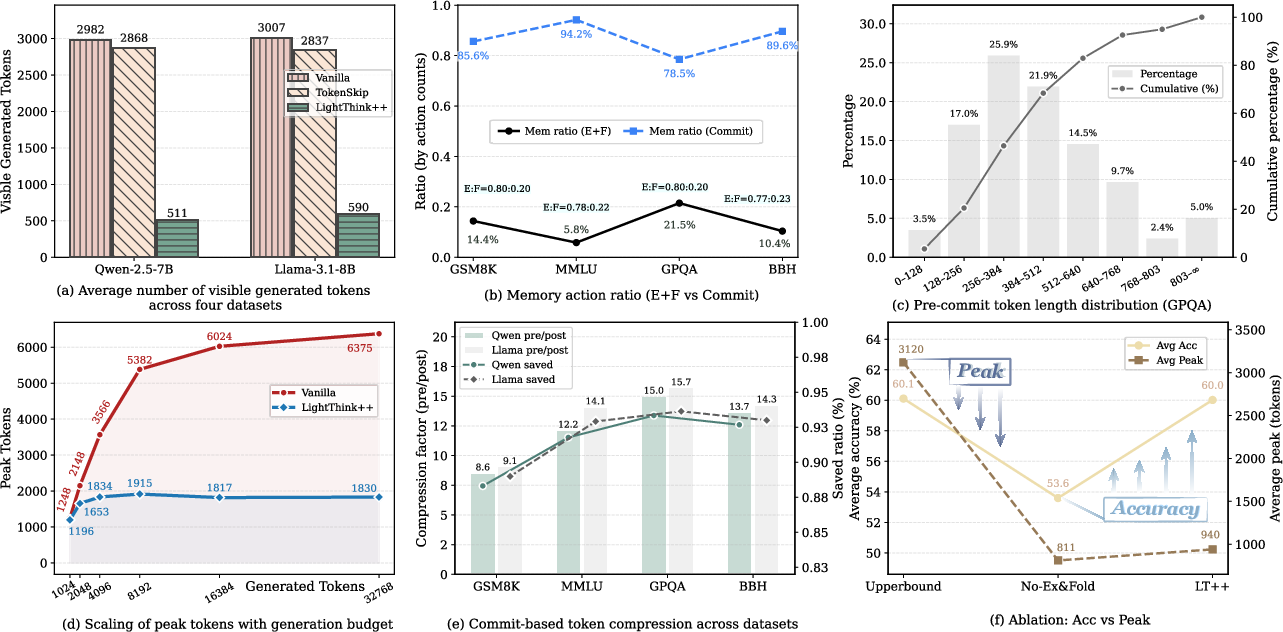
Figure 5: Ablation and action analysis for LightThinker++: context reduction, operation mix (commit/expand/fold), pre-commit segment length statistics, and scaling with inference budget.
Case Analysis
Failure cases in GSM8K can be traced to excessive lossy compression, which discards necessary numerical anchors, resulting in solution inconsistencies. Recovery is only possible with explicit memory management; LightThinker++ models successfully utilize expand actions to revisit, validate, and restore previously omitted information, directly leveraging the new behavioral primitives.

Figure 6: Partial inference trace revealing logical failure routes under aggressive compression with vanilla LightThinker.
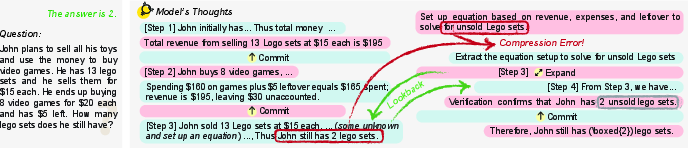
Figure 7: Successful case utilizing expand-finalize-fold for robust recovery of missing details during multi-step arithmetic reasoning.
Long-Horizon Agentic Reasoning
LightThinker++ is applied to web-based, multi-hop research and planning environments (e.g., xBench-DeepSearch, BrowseComp-EN/ZH). In this regime, context windows rapidly inflate to 100k+ tokens under standard agents, causing reasoning collapse due to accumulated noise and attention inefficiency. Explicit context folding and expansion keep memory usage stable—at 30k–40k tokens—even beyond 80 dialogue rounds, decoupling reasoning horizon from physical context constraints.
LightThinker++ achieves:
- Pass@1 improvements between 5.7–8.8% over vanilla agents
- 2.0–3.1x improvements on hard, low-success instances (hard01) versus baselines
- Significant performance gains under fixed search/visit action budgets, reducing necessary environment interactions by 1.6–2.5x
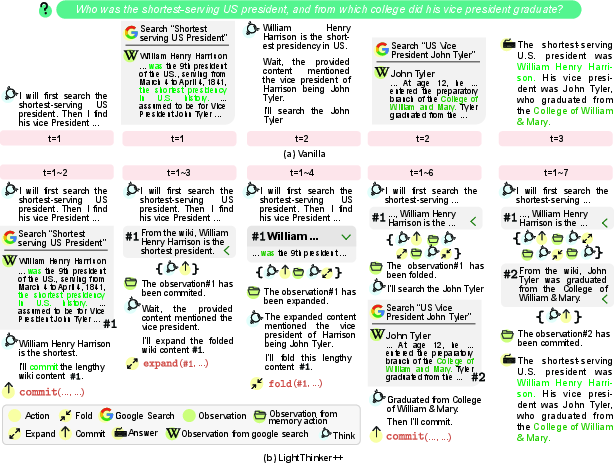
Figure 8: Schematic of stateful agentic reasoning and explicit context archiving for DeepResearch tasks.
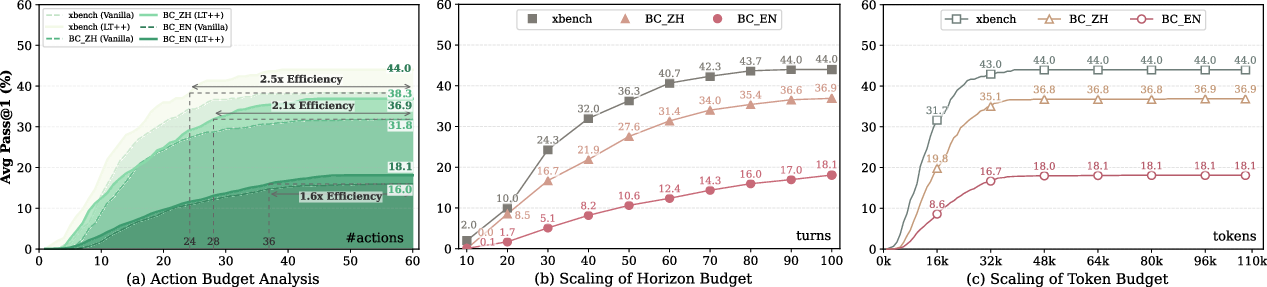
Figure 9: Trajectories of active context growth versus vanilla; LightThinker++ suppresses contextual explosion and achieves stable mean/peak usage over extended horizons.
Implications and Future Directions
LightThinker++ demonstrates that explicit memory management—grounded in direct model-driven behavioral primitives—outperforms fixed bottleneck (implicit) compression in high-density, long-horizon LLM reasoning and agentic tasks. This decoupling of reasoning coverage from unconditional context growth critically advances the deployment of LLMs in settings that require deep, persistent inference spanning thousands of tokens and rounds.
The dual-form entity design, stepwise archival/recovery mechanisms, and action-oriented training signals open new avenues for generalizable context engineering, interpretable self-regularization, and domain-agnostic reasoning architectures. The approach aligns with, but provides greater sample efficiency and controllability than, recent RL-driven memory selection and context folding pipelines [mem1, memagent, agentfold, context-folding].
Future research can extend adaptive compression capacities, refine summary/detail alternation criteria, and further unify behavioral and continuous-latent reasoning frameworks for continual learning and cross-task transfer.
Conclusion
LightThinker++ provides a formal paradigm for memory-efficient, high-fidelity LLM reasoning via a model-internal suite of explicit memory management operations. Extensive empirical evidence shows that such mechanisms significantly compress context, boost efficiency, and improve logical robustness for both standard reasoning and long-horizon agentic tasks. These results establish explicit behavioral memory management as a critical axis for next-generation large-scale reasoning architectures.
(2604.03679)