- The paper introduces a discrete diffusion language model that employs a two-stage curriculum training to balance code generation quality and speed.
- It integrates constrained-order training with on-policy learning to optimize generation trajectories and enable block-wise parallel inference.
- The model achieves 2146 tokens/sec on H20 GPUs and demonstrates competitive accuracy in code generation and editing across multiple benchmarks.
Seed Diffusion: Large-Scale Diffusion Language Modeling for High-Speed Inference
Introduction and Motivation
Seed Diffusion introduces a large-scale discrete diffusion LLM (DLM) tailored for code generation, with a focus on achieving high inference speed while maintaining competitive generation quality. The work addresses two persistent challenges in discrete DLMs for language: (1) the inefficiency of random token-order modeling, which conflicts with the sequential nature of natural language, and (2) inference latency due to iterative denoising steps, which undermines the parallelism advantage of non-autoregressive (NAR) models. The model is benchmarked against state-of-the-art autoregressive and diffusion-based code models, demonstrating a strong speed-quality trade-off.
Model Architecture and Training Strategies
Seed Diffusion Preview employs a standard dense Transformer architecture, omitting complex reasoning modules to establish a robust baseline for code-focused diffusion modeling. The training pipeline is derived from the Seed Coder project, utilizing exclusively code and code-related data.
Two-Stage Curriculum (TSC) for Diffusion Training
The training procedure is divided into two stages:
- Mask-Based Forward Process (80% of training): Tokens in the input sequence are independently masked according to a monotonically increasing noise schedule γt. This process is analytically tractable and yields a low-variance ELBO objective.
- Edit-Based Forward Process (20% of training): Augments the mask-based process with token-level edit operations (insertions, deletions, substitutions), controlled by a scheduler based on Levenshtein distance. This mitigates overconfidence in unmasked tokens and improves calibration, especially for code-editing tasks.
The overall objective combines the ELBO from the mask-based process with a denoised loss from the edit-based process, ensuring the model learns to reconstruct and self-correct across a spectrum of corruption levels.
Constrained-Order Diffusion Training
Standard mask-based diffusion models implicitly learn any-order autoregressive decompositions, which can be detrimental for language modeling. Seed Diffusion introduces a constrained-order training phase, where optimal generation trajectories are distilled from the pre-trained model using ELBO maximization. The model is then fine-tuned on these high-quality trajectories, reducing the learning burden of redundant or unnatural generation orders.
On-Policy Diffusion Learning
To unlock parallel decoding efficiency, Seed Diffusion adopts an on-policy learning paradigm. The reverse process is optimized to minimize trajectory length, with a model-based verifier ensuring convergence to valid samples. Training is stabilized using a surrogate loss proportional to the expected Levenshtein distance between trajectory states. This approach is analogous to mode filtering in NAR text generation, promoting efficient block-wise sampling.
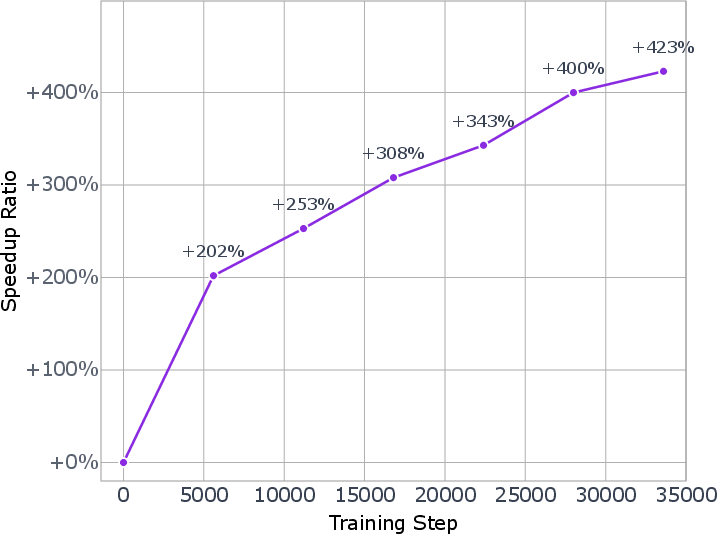
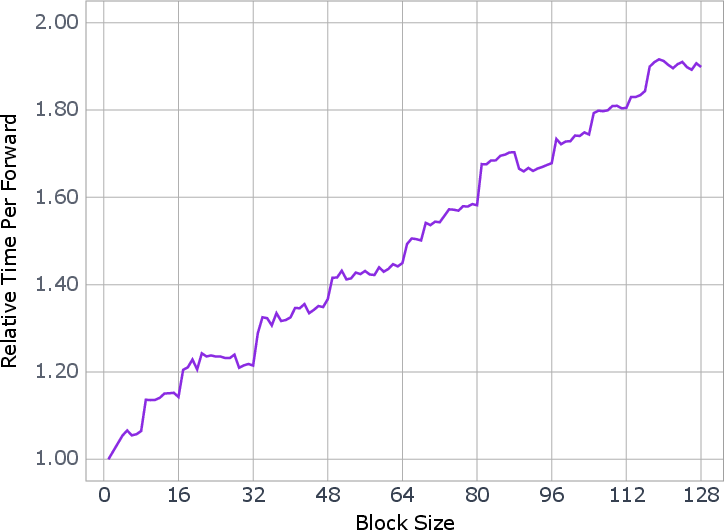
Figure 1: The changes of speedup ratio estimated by sampling with a certain block size b during the on-policy training.
Inference and System Optimization
Inference is performed using a block-level parallel diffusion sampling scheme, maintaining causal ordering between blocks. The reverse process generates tokens in blocks, amortizing the computational cost of parallel steps. System-level optimizations are implemented to accelerate block-wise sampling, with empirical analysis guiding the selection of optimal block sizes for latency and throughput trade-offs.
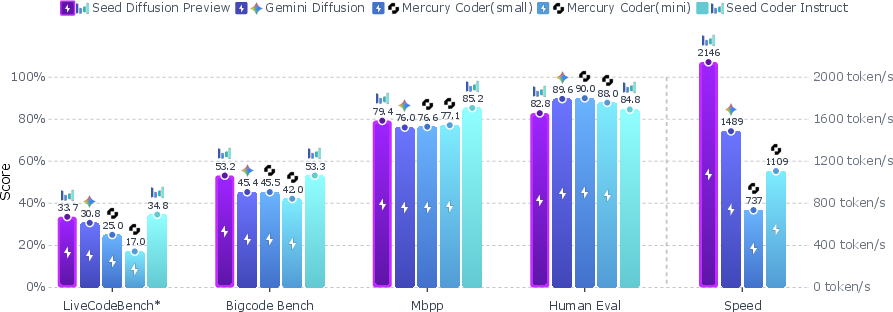
Figure 2: Seed Diffusion's inference speed is measured over H20 GPUs across eight open code benchmarks, highlighting its position on the speed-quality Pareto frontier.
Experimental Results
Seed Diffusion Preview is evaluated on a comprehensive suite of code generation and editing benchmarks, including HumanEval, MBPP, BigCodeBench, LiveCodeBench, MBXP, NaturalCodeBench, Aider, and CanItEdit. The model achieves:
- Inference speed of 2146 tokens/sec on H20 GPUs, substantially outperforming autoregressive and prior diffusion baselines under comparable hardware and protocol constraints.
- Competitive code generation accuracy across multiple programming languages and tasks, with performance on par with or exceeding similarly-sized autoregressive models.
- Superior code-editing capabilities, attributed to the edit-based corruption and calibration strategies.
The results establish Seed Diffusion as a strong candidate for high-throughput code generation and editing, with discrete diffusion models demonstrating practical viability for real-world deployment.
Theoretical and Practical Implications
Seed Diffusion advances the understanding of discrete diffusion modeling in language domains, particularly for code. The work demonstrates that:
- Random-order modeling is suboptimal for language, and constrained-order training is necessary for competitive performance.
- Edit-based corruption is essential for calibration and self-correction, especially in code-editing scenarios.
- Block-wise parallel inference, combined with on-policy learning, enables substantial speedup without sacrificing quality.
These findings challenge the conventional wisdom regarding the quality-speed trade-off in NAR models and suggest that discrete diffusion can be scaled and adapted for complex reasoning tasks.
Future Directions
The authors posit that high-speed inference is only the initial benefit of discrete diffusion models. Future research should explore:
- Scaling properties of discrete DLMs for larger model sizes and more diverse domains.
- Alternative token-order modeling paradigms, moving beyond left-to-right and random-order assumptions.
- Applications to complex reasoning and multi-step tasks, leveraging the flexibility of diffusion-based generation.
Further investigation into hybrid architectures, advanced corruption processes, and system-level optimizations will be critical for realizing the full potential of discrete diffusion in language modeling.
Conclusion
Seed Diffusion Preview demonstrates that large-scale discrete diffusion LLMs can achieve high inference speed and competitive generation quality for code tasks. The combination of two-stage curriculum training, constrained-order modeling, and block-wise parallel inference establishes a new baseline for practical deployment of diffusion-based LLMs. The work provides a foundation for future research into scalable, efficient, and flexible generative modeling in discrete domains.

