- The paper introduces D3PM, a discrete diffusion model that iteratively refines noisy inputs via denoising, providing an alternative to autoregressive methods.
- It contrasts D3PM's parallel generation approach with sequential autoregressive models by comparing evaluation metrics such as perplexity and Bits Per Token.
- The research highlights challenges in training stability and learning dynamics, suggesting future work to optimize diffusion models for robust language generation.
Discrete Diffusion Models for Language Generation (2507.07050)
Introduction to Discrete Diffusion Models
The emergence of discrete diffusion models presents an alternative approach to language generation by leveraging denoising processes on noisy inputs. These models have been explored as viable competitors to the established autoregressive (AR) models like GPT-2, primarily characterized by sequential token prediction. Diffusion models such as the Discrete Denoising Diffusion Probabilistic Model (D3PM) sidestep some inherent limitations of AR models, primarily exposure bias and inefficiencies in parallel computation during inference. The D3PM model operates by iteratively refining a corrupted input through a process that is inherently parallel, allowing the entire sequence to be generated simultaneously during inference.
Model Architectures and Mechanisms
Autoregressive Models
Autoregressive models are defined by their sequential generation process. They predict each token based on prior tokens, achieving high-quality text generation in applications requiring coherence and context awareness. These models employ a probability chain rule where each output token depends on previously generated tokens.
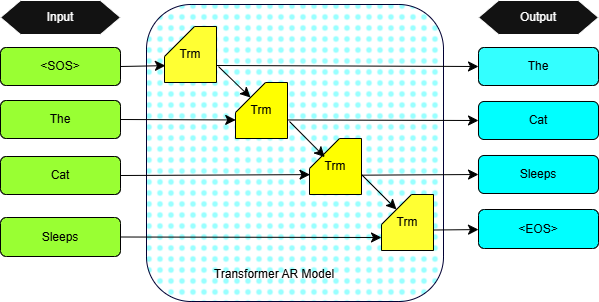
Figure 1: Illustration of the token-by-token generation process in an autoregressive model. This Trm represent the Transformer block.
The Transformer architecture underpins these models, with stacked layers of multi-head self-attention and feedforward networks enabling rich context utilization across long input sequences.
Discrete Diffusion Models
D3PM, a variant of diffusion models, operates by first adding structured noise to clean data sequences in a forward process and then reconstructing the original data from noisy inputs in a backward diffusion step.
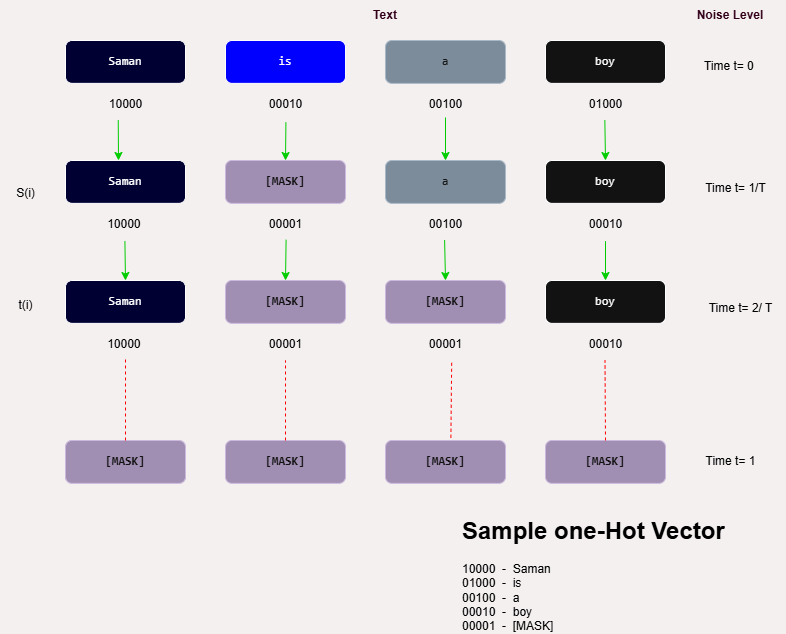
Figure 2: Illustration of the D3PM forward process.
For a sequence to undergo denoising, a sequence of masking steps is applied in reverse order. Each denoising step corresponds to a learned approximation of applying an inverse transform to recover the clean sequence. This approach contrasts with the AR model's stepwise prediction, favoring parallelism in generative tasks.

Figure 3: Using a trained D3PM absorbing model for LM1B to (top) generate new sentences and (bottom) reconstruct corrupted examples.
The evaluation utilized datasets like WikiText-103, applying metrics such as Bits Per Token (BPT), Negative Log-Likelihood (NLL), and Perplexity (PPL) to quantify model performance. These metrics provide insight into both generative efficiency and the probabilistic confidence of predictions.
AR models, despite their slower inference speeds, achieved superior performance in terms of perplexity and text fluency, attributed to their sequential prediction capability. Conversely, D3PM models showed potential in tasks requiring structured text completion but at the cost of higher BPT and PPL values.
Learning Dynamics and Efficiency
Figure 4: Sample spectrum from the WikiText-103 dataset.
The training loss convergence of D3PM indicates potential instability across different seed values, highlighting challenges in learning dynamics and initialization sensitivities that need addressing for robust performance realization.
Comparative Analysis and Implications
Key distinctions between D3PM and AR models lie in their operational mechanics. AR models excel in applications requiring context-driven text generation and high fidelity, such as conversational AI and long-form content generation. In contrast, diffusion-based models provide flexibility for tasks where the input consists of fragmented or noisy data, effectively leveraging parallelism.
Conclusion
This research underscores the divergent strengths of D3PM and AR models. While AR models demonstrate superior fluency and quality in traditional language generation tasks, D3PM offers benefits for scenarios requiring controlled text generation from incomplete inputs. Future work may focus on optimizing the stability and learning dynamics of diffusion models, potentially broadening their applicability in AI-driven language processing. Through further refinements, diffusion models could evolve into formidable alternatives, complementing the strengths of AR paradigms in suitable contexts.

