Encoder-Decoder Diffusion Language Models for Efficient Training and Inference
Abstract: Discrete diffusion models enable parallel token sampling for faster inference than autoregressive approaches. However, prior diffusion models use a decoder-only architecture, which requires sampling algorithms that invoke the full network at every denoising step and incur high computational cost. Our key insight is that discrete diffusion models perform two types of computation: 1) representing clean tokens and 2) denoising corrupted tokens, which enables us to use separate modules for each task. We propose an encoder-decoder architecture to accelerate discrete diffusion inference, which relies on an encoder to represent clean tokens and a lightweight decoder to iteratively refine a noised sequence. We also show that this architecture enables faster training of block diffusion models, which partition sequences into blocks for better quality and are commonly used in diffusion LLM inference. We introduce a framework for Efficient Encoder-Decoder Diffusion (E2D2), consisting of an architecture with specialized training and sampling algorithms, and we show that E2D2 achieves superior trade-offs between generation quality and inference throughput on summarization, translation, and mathematical reasoning tasks. We provide the code, model weights, and blog post on the project page: https://m-arriola.com/e2d2
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
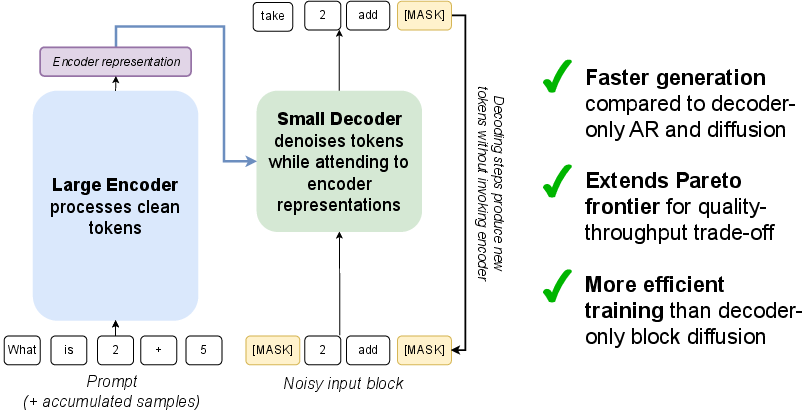
This paper introduces a new way to build and run “diffusion” LLMs so they can generate text faster and train more efficiently. The authors call their method Efficient Encoder-Decoder Diffusion (E2D2). It splits the model into two parts:
- an encoder that understands already clean (correct) words,
- and a small decoder that fixes the “noisy” or masked words step by step.
By separating these jobs, the model uses less compute per step and can generate text more quickly without hurting quality.
What questions did the researchers want to answer?
The team focused on three simple questions:
- Can we make diffusion LLMs run faster when generating text?
- Can we train these models more efficiently (with less computation) without losing quality?
- Does this new design still work well on real tasks like summarization, translation, and math word problems?
How does it work? Key ideas and methods in everyday terms
First, some quick explanations of terms in simple language:
- Tokens: Think of tokens as the building blocks of text—like words or pieces of words.
- Diffusion model: Imagine starting with a sentence where many words are covered by [MASK] boxes. A diffusion model uncovers those words step by step, making better guesses each time—like cleaning a blurry picture gradually.
- Encoder: Like a careful reader who builds a smart summary of the clean words and the prompt, so the model knows the context well.
- Decoder: Like a fixer who looks at the encoder’s summary and improves the masked parts, one round at a time.
- KV cache: A memory that remembers what the model already saw so it doesn’t have to re-read everything every time, which speeds up generation.
- Blocks: Instead of filling in the whole sentence at once, the model works on small chunks (blocks) of the sentence in order, which helps both speed and quality.
What most diffusion models do today:
- They use one big “decoder-only” network.
- They must run the full network at every denoising step, which is expensive.
What E2D2 changes:
- It splits the work. The encoder reads and represents clean tokens (like the prompt and any tokens already finalized). The lightweight decoder focuses on fixing the noisy tokens.
- During generation, the decoder runs many quick denoising steps without calling the encoder each time. Then, when enough new tokens are ready, the encoder is called to update its understanding.
- This design also makes training faster, especially for “block diffusion,” where the model fills in the sentence block by block from left to right. E2D2 processes clean blocks with the encoder and noisy blocks with the decoder, cutting training cost roughly in half compared to a decoder-only version of the same size.
Two practical design choices:
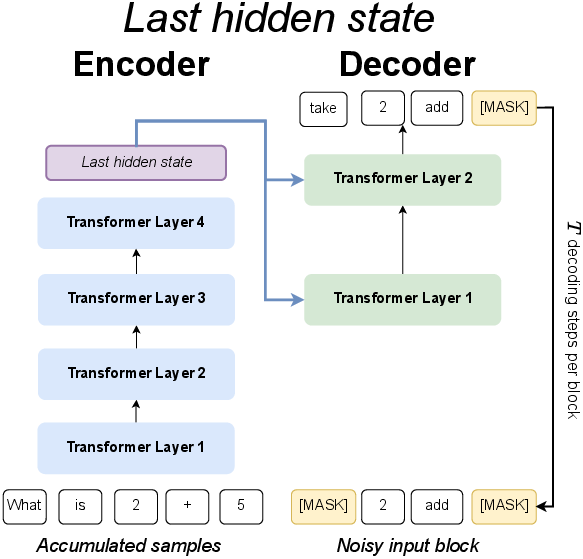
- “Last hidden state” version: The decoder attends to the encoder’s final layer features—simple and strong when training from scratch.
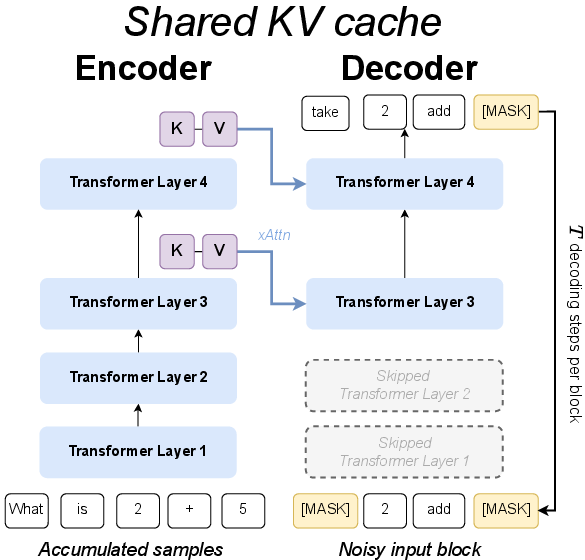
- “Shared KV cache” version: The decoder reuses the encoder’s internal memory per layer—very stable when fine-tuning from a pretrained model.
How they sample (generate text):
- The encoder reads the prompt and builds context.
- The decoder repeatedly improves a small block of masked tokens using that context.
- After some steps, the newly cleaned block is added to the context, and the encoder updates its representation.
- Repeat until the whole output is generated.
How they train:
- They run the encoder on the clean sequence and the decoder on the noisy sequence at the same time with custom attention masks, so each part only looks where it should. This “vectorized” setup means they only need one pass per batch and it’s much more efficient.
What did they find?
Across several tasks, E2D2 was faster and often better than standard diffusion baselines:
- Summarization (CNN/DailyMail):
- E2D2 generated faster than other diffusion models and even beat a similar-size autoregressive (AR) baseline in quality, while being about 75% faster than that AR baseline in decoding speed.
- Translation (WMT14 German→English):
- E2D2 achieved higher quality (BLEU score) than comparable diffusion models and the highest decoding speed among tested setups.
- Math reasoning (GSM8K):
- E2D2 reached much higher accuracy than diffusion baselines (pass@1 47.9% vs. 33.2% for a strong baseline) and decoded faster.
- Language modeling (OpenWebText):
- E2D2 matched or approached the best diffusion model’s perplexity (a measure of how well a model predicts text) while training about 40% faster.
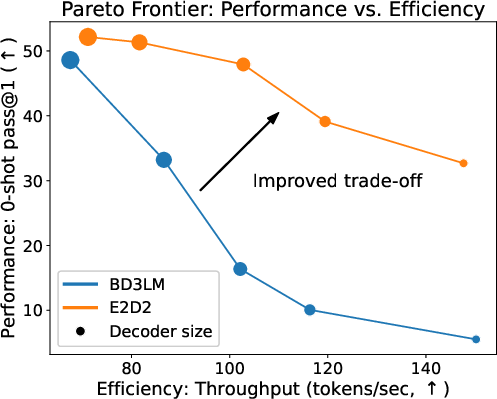
They also mapped the “Pareto frontier,” which shows the trade-off between speed and accuracy for different model sizes. E2D2 consistently offered better trade-offs: for a given speed, it achieved higher accuracy; or for a given accuracy, it decoded faster.
Other practical insights:
- Smaller blocks speed up generation but can reduce quality; larger blocks do the opposite. E2D2 lets you pick the balance that suits your needs.
- Fewer diffusion steps per block increase speed; E2D2 keeps better quality than baselines even with fewer steps.
- The “last hidden state” version is best when training from scratch on larger datasets; the “shared KV cache” version is best for fine-tuning smaller datasets from a strong pretrained model.
Why is this important?
- Faster text generation: E2D2 reduces the number of heavy network calls needed during sampling, making diffusion models more practical for real-world use.
- Cheaper training: Splitting clean and noisy processing cuts training cost (roughly 2× less than a common baseline), saving time and compute.
- Strong performance: The model keeps or improves quality on summarization, translation, math reasoning, and language modeling.
- Flexible deployment: By changing block size and decoder depth, you can aim for maximum speed, maximum quality, or a balance between the two.
Simple takeaway
E2D2 shows that diffusion LLMs don’t have to be slow. By letting an encoder handle the “understanding” and a small decoder handle the “fixing,” the model generates text faster and trains more efficiently—without giving up quality. This makes diffusion-based text models more practical and competitive for tasks like summarizing articles, translating languages, and solving math problems.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and open questions left by the paper that future work can directly address.
- Scaling behavior at large model sizes: The paper evaluates E2D2 mostly on small and mid-scale models (170M, and a 1.7B fine-tune for GSM8K) but does not quantify training stability, memory footprint, throughput, and quality at 7–8B+ scales where recent diffusion LMs have excelled. Action: Train and profile E2D2 at multi‑billion parameter scale with long contexts and report wall‑clock speed, memory, convergence, and failure modes.
- Long-context generalization: Experiments use context lengths up to 1024 tokens; the performance, KV cache behavior, and memory growth of E2D2 at 8k–32k tokens are untested. Action: Evaluate throughput, latency, and quality for long inputs with realistic KV cache sizes and attention patterns.
- Empirical validation of E2D2 for standard masked diffusion (MDLM): While an MDLM variant is described, results focus on block diffusion; no empirical comparisons for E2D2‑MDLM are reported. Action: Benchmark E2D2‑MDLM against MDLM and BD3LM across tasks and sequence lengths.
- Encoder invocation scheduling: The paper uses predetermined encoder update intervals (e.g., after denoising a block) but does not study adaptive schedules that trigger encoder calls based on uncertainty or token change magnitude. Action: Design policies that learn or adapt the frequency of encoder updates to maximize quality-per‑FLOP.
- Optimal allocation of encoder vs. decoder capacity: The trade-off between encoder depth/width and decoder depth/width is not systematically explored beyond a few settings. Action: Conduct controlled sweeps to find Pareto‑optimal allocations under fixed total parameters and FLOPs.
- Dynamic or learned block boundaries: E2D2 trains and decodes with fixed block sizes; the impact of learning block boundaries or using content‑adaptive blocks remains unknown. Action: Investigate models that predict block segmentation online, balancing KV cache efficiency and likelihood tightness.
- Joint optimization of block size S and diffusion steps T: Ablations vary S and T independently; there is no principled method to choose them per task or per sequence. Action: Develop criteria or meta‑learning strategies to select or schedule S and T dynamically during training and inference.
- Adaptive denoising budgets per block: All blocks use the same number of diffusion steps; blocks with low uncertainty may need fewer steps. Action: Introduce per‑block early‑stopping criteria or confidence‑based step allocation to reduce inference cost.
- Fused attention kernel portability and correctness: The fused cross+self attention design is presented without benchmarking across hardware stacks (A100/H100, AMD, TPU) or assessing numerical stability vs. standard separate cross‑attention. Action: Provide portability benchmarks, numerical analyses, and ablations comparing fused vs. unfused attention across toolchains.
- Decoder attention sharing with encoder features: The fused attention forces the decoder to “split” attention between its own states and encoder outputs; the impact on gradient flow, representation interference, and optimization is not analyzed. Action: Evaluate gating, reweighting, or router mechanisms to modulate encoder vs. decoder attention and measure downstream effects.
- KV caching details and memory overhead: The paper sketches KV caching for block decoding and mentions decoder KV accumulation “not depicted,” but does not quantify the memory impact of maintaining encoder and decoder caches (especially in the “shared KV cache” variant) nor eviction policies. Action: Profile memory usage, propose cache compression/eviction, and measure throughput vs. cache size trade‑offs.
- Weight tying and layer mapping in the “shared KV cache” variant: The choice to copy decoder layers from the top of the encoder and tie weights is heuristic; there is no study of alternative mappings (e.g., every k‑th layer, mixing low/high layers) nor the effect on fine‑tuning stability. Action: Systematically test layer mapping strategies and weight‑tying policies for different initializations.
- Initialization from pretrained AR LLMs: Although one GSM8K fine‑tune is shown, broader guidance on initializing E2D2 from AR checkpoints (mask annealing schedules, attention mask transitions, cross‑attention alignment) is lacking. Action: Develop robust initialization protocols and compare against training from scratch across datasets.
- Inference latency and serving considerations: Results report tokens/sec but not end‑to‑end latency per sample, tail latency under batching, or throughput under multi‑request serving. Action: Benchmark real-world serving profiles and design batching/scheduling strategies optimized for E2D2’s periodic encoder calls.
- Energy efficiency and cost: FLOPs analyses are presented, but energy, cost per generated token, and carbon metrics are not reported. Action: Measure energy consumption and cost across architectures and hardware to substantiate “efficiency” claims.
- Exact or tighter likelihood estimation for diffusion LMs: Perplexities are upper bounds; the tightness of the bound varies with block size and parameterization but is not quantified. Action: Derive tighter bounds or unbiased estimators for log‑likelihood and relate them to S and T choices.
- Guidance and control mechanisms: The paper mentions discrete guidance in related work but does not integrate classifier or sequence‑level guidance into E2D2. Action: Add guidance for controlling style, faithfulness, or task constraints and measure its speed/quality impact.
- Robustness, calibration, and uncertainty: There is no evaluation of calibration, error bars, or uncertainty in denoising predictions, especially for reasoning tasks. Action: Quantify calibration, implement uncertainty‑aware sampling, and test robustness under perturbations.
- Faithfulness and human evaluation: Summarization is evaluated with ROUGE; hallucination and factuality are not assessed, and translation uses BLEU without COMET or human judgments. Action: Incorporate human evaluations and modern metrics (COMET, factuality scores) to validate quality improvements.
- Cross‑lingual, code, and multimodal generalization: E2D2 is tested on English summarization, de‑en translation, and math; performance on other languages, code generation, music/biology (where diffusion has seen success) is unexamined. Action: Extend experiments to multilingual, code, and multimodal settings.
- Noise schedule design: The training samples t uniformly and adopts a standard schedule, but does not explore schedule learning or block‑specific schedules. Action: Optimize or learn noise schedules (per layer, per block) to improve quality vs. speed.
- Training stability and failure modes: The paper qualitatively notes stability benefits of the “shared KV cache” variant on small datasets but provides no quantitative analysis of instabilities (e.g., exposure bias analogs, mode collapse) across settings. Action: Track gradients, loss landscapes, and divergence cases, and propose regularizers or curriculum.
- Integration with speculative/accept‑reject decoding: E2D2’s lightweight decoder resembles draft models but does not explore accept‑reject schemes to further cut encoder invocations. Action: Combine E2D2 with speculative decoding, evaluate acceptance rates, and measure end‑to‑end improvements.
- Theoretical analysis of block diffusion tightness vs. performance: The paper cites that larger blocks loosen the bound and harm quality but does not model the trade‑off formally. Action: Provide theoretical and empirical curves linking block size, bound tightness, and error rates.
- Position alignment and masking correctness: The vectorized training relies on complex attention masks; formal guarantees of masking correctness and absence of information leakage are not provided. Action: Validate masks with provable properties and automated tests across diverse sequence layouts.
- Serving‑side cache reuse across prompts/sessions: There is no discussion of whether encoder caches can be reused across related prompts or tasks to amortize cost. Action: Explore cache reuse and pre‑encoding strategies for frequent contexts.
- Compatibility with standard toolchains: Fused attention and custom masks may not integrate cleanly with common inference/training stacks (e.g., TensorRT‑LLM, vLLM, PyTorch 2.x). Action: Release portable kernels, measure integration overhead, and provide reference implementations.
- Security and safety: The paper does not assess bias, toxicity, or safety under E2D2’s denoising regime. Action: Evaluate safety benchmarks and explore guidance or filtering compatible with diffusion inference.
- Comprehensive comparison to large diffusion LMs: No head‑to‑head comparisons with LLaDA, Dream7B, or other 7–8B diffusion LMs at similar scales are provided. Action: Run matched‑scale comparisons to situate E2D2’s quality/throughput against state‑of‑the‑art diffusion decoders.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s E2D2 architecture, training, and sampling algorithms, along with the released code and weights.
- High-throughput summarization and translation services (software, media, finance, government)
- What: Replace autoregressive or decoder-only diffusion backends with E2D2 to cut inference latency and cost for document summarization, meeting/earnings-call summarization, and multilingual translation.
- Tools/products/workflows: E2D2-powered inference server; batch processing pipelines; “Pareto tuner” to pick decoder depth, block size S, and diffusion steps T for target quality/throughput.
- Assumptions/dependencies: Access to GPUs/TPUs; integration with existing serving stacks; domain-specific fine-tuning as needed; licensing for pretrained bases (e.g., Qwen3).
- Enterprise document processing and compliance (legal, finance, public sector)
- What: Use E2D2 for large-scale ETL pipelines to summarize, translate, and triage documents faster (KV caching + block diffusion supports streaming and chunked processing).
- Tools/products/workflows: KV cache manager for encoder-decoder diffusion; block-wise streaming summarizer.
- Assumptions/dependencies: Reliable chunking strategy (block size) and validation on enterprise datasets; auditability and controllability requirements.
- Real-time customer support assistants (contact centers)
- What: Lower latency response generation with iterative lightweight decoder steps and periodic encoder updates, improving user experience and concurrency.
- Tools/products/workflows: E2D2-based response generator; latency-aware scheduler that optimizes T and S per request.
- Assumptions/dependencies: Domain fine-tuning; guardrails; GPU scheduling that prioritizes decoder steps.
- On-device or edge summarization/translation (mobile, embedded)
- What: Deploy small E2D2 decoders on-device to iteratively denoise, invoking a heavier encoder less frequently (periodic context updates), enabling offline or low-connectivity operation.
- Tools/products/workflows: Quantized lightweight decoder; occasional server-side encoder refresh; fused attention kernel optimized for mobile GPUs/NPUs.
- Assumptions/dependencies: Efficient kernel support on edge hardware; memory constraints; quality-vs-throughput trade-offs with larger S.
- Math reasoning tutors and study aids (education)
- What: Use fine-tuned E2D2 models for step-by-step reasoning in homework assistance, benefiting from improved throughput and accuracy over decoder-only diffusion baselines.
- Tools/products/workflows: E2D2-powered reasoning tutor; curriculum-aware fine-tuning pipeline; dynamic block sizing based on problem length.
- Assumptions/dependencies: High-quality math datasets; pedagogy alignment; evaluation for faithfulness and error correction.
- Faster academic experimentation with diffusion LMs (academia)
- What: Halve training FLOPs for block diffusion, enabling more rapid prototyping and scaling studies; adopt the “shared KV cache” design to stabilize fine-tuning from AR checkpoints.
- Tools/products/workflows: E2D2 training harness; fused attention kernel; block mask generators; hyperparameter sweeps for S and T.
- Assumptions/dependencies: Adoption in PyTorch/JAX ecosystems; reproducibility on open benchmarks; availability of pretrained AR backbones.
- Cost and energy reduction in LLM serving (energy, infrastructure)
- What: Replace decoder-only diffusion or AR models with E2D2 to cut inference compute and energy per token, increasing throughput per GPU.
- Tools/products/workflows: Energy dashboards; throughput/quality Pareto mapping to select N_enc/N_dec; autoscaling policies tuned to decoder-only bursts.
- Assumptions/dependencies: Accurate measurement pipelines; workload profiles conducive to block diffusion; alignment with sustainability KPIs.
- Multilingual communication tools (consumer apps)
- What: Real-time chat translation with lower latency; bidirectional attention and block-wise decoding support efficient context updates.
- Tools/products/workflows: E2D2-backed messaging plugin; streaming decoder loop with periodic encoder refresh; QoS tuning of T per network conditions.
- Assumptions/dependencies: Language coverage; fairness and bias audits; privacy guarantees.
- Developer tooling and frameworks support (software)
- What: Integrate E2D2 modules into transformer libraries; add fused cross/self-attention kernels; expose KV caching APIs compatible with encoder-decoder diffusion.
- Tools/products/workflows: “E2D2 runtime” plugin; KV cache sharing utilities; block diffusion masks; inference schedulers.
- Assumptions/dependencies: Framework compatibility (e.g., PyTorch, Triton kernels); CI for fused kernels; community adoption.
- Biological sequence design and music generation (life sciences, creative industries)
- What: Apply E2D2 to discrete sequence tasks cited in the literature (proteins, music), gaining faster sampling while maintaining quality.
- Tools/products/workflows: Domain tokenization pipelines; block-wise generative loops; evaluation harnesses.
- Assumptions/dependencies: Domain-specific datasets; tokenizer fit; safety and IP constraints.
Long-Term Applications
These applications require additional research, scaling, integration, or validation but are well supported by the paper’s methods and insights.
- Large-scale general-purpose E2D2 LLMs (software)
- What: Train 7–8B+ E2D2 models to match AR quality with lower inference cost and better throughput, building on encouraging early diffusion LMs.
- Tools/products/workflows: Multi-node training with block diffusion; hardware-aware fused kernels; robust KV caching across long contexts.
- Assumptions/dependencies: Massive pretraining corpora; stable optimization at scale; rigorous evaluation on safety, reliability, and hallucination.
- Hybrid AR–diffusion inference (software, research)
- What: Combine E2D2’s parallel denoising bursts with AR token verification or tool use, dynamically allocating compute between encoder and decoder based on uncertainty.
- Tools/products/workflows: Gating mechanisms; uncertainty estimators; mixed-attention scheduling.
- Assumptions/dependencies: New algorithms for agreement/acceptance, robust error detection, and tool orchestration.
- Speculative decoding for diffusion (software, research)
- What: Adapt speculative decoding ideas to E2D2 by using ultra-light decoders for proposals and periodic encoder validations, potentially further reducing latency.
- Tools/products/workflows: Proposal decoders; accept/reject samplers; latency-aware schedulers.
- Assumptions/dependencies: Acceptance criteria for diffusion steps; calibration of proposal networks; theoretical guarantees.
- Retrieval-augmented E2D2 (software, education, enterprise)
- What: Periodically refresh encoder representations with retrieved documents while performing lightweight decoder denoising in between, yielding efficient, context-rich generation.
- Tools/products/workflows: Retrieval pipeline integration; encoder refresh cadence controller; cache-aware memory manager.
- Assumptions/dependencies: Scalable retrieval infra; context window management; evaluation for factuality.
- Privacy-preserving clinical summarization and translation (healthcare)
- What: On-prem E2D2 deployments for EMR summarization and patient communication, benefiting from reduced energy and latency while maintaining HIPAA compliance.
- Tools/products/workflows: Secure inference servers; audit trails; domain fine-tuned clinical models; periodic encoder updates on local hardware.
- Assumptions/dependencies: Clinical dataset availability; regulatory approvals; robust evaluation on safety and bias.
- Real-time language interfaces for robotics (robotics)
- What: Use low-latency E2D2 generation for instruction following and dialogue with robots, exploiting efficient KV caching and block-wise updates in closed-loop control.
- Tools/products/workflows: Language-action middleware; timing-aware decoders; safety filters.
- Assumptions/dependencies: Hard-real-time constraints; integration with perception/action stacks; safety validation.
- Sustainable AI policy and procurement (policy, public sector)
- What: Encourage adoption of compute-efficient architectures like E2D2 in public services to lower carbon footprints of AI deployments; include efficiency metrics in procurement.
- Tools/products/workflows: Benchmarking frameworks for energy-per-token; procurement guidelines referencing block diffusion and KV caching benefits.
- Assumptions/dependencies: Standardized measurement; consensus on efficiency metrics; stakeholder engagement.
- Cross-domain discrete sequence generation (bio, music, code)
- What: Extend E2D2 to more domains (e.g., code generation with reasoning, protein design with constraints), leveraging faster training and inference for iterative design loops.
- Tools/products/workflows: Domain-specific tokenizers and evaluation metrics; iterative refinement UIs; constraint-aware sampling.
- Assumptions/dependencies: High-quality labeled data; domain safety protocols; specialized evaluation suites.
- Hardware-optimized E2D2 libraries (energy, hardware ecosystem)
- What: Co-design fused attention kernels and KV cache sharing for next-gen accelerators, making encoder-decoder diffusion a first-class hardware target.
- Tools/products/workflows: Vendor-supported libraries; kernel autogen; memory schedulers for 2L attention masks.
- Assumptions/dependencies: Collaboration with hardware vendors; stable APIs; broad developer adoption.
- Quality–throughput governance and automation (enterprise MLOps)
- What: Automate selection of decoder size, block size S, and steps T using live metrics to meet SLAs; integrate Pareto frontier mapping into deployment tooling.
- Tools/products/workflows: Auto-tuners; canary deployments; adaptive schedulers.
- Assumptions/dependencies: Reliable online metrics; safe reconfiguration; rollback and observability.
Glossary
- Absorbing state: A special terminal state in a diffusion process where once entered, the system remains (e.g., all tokens masked). "masking (absorbing state) diffusion"
- Autoregressive (AR): A modeling approach that generates tokens sequentially, each conditioned on previous outputs. "autoregressive (AR) models"
- Block autoregressive decoding: Decoding strategy that generates tokens in contiguous blocks from left to right, autoregressively across blocks. "rely on block autoregressive decoding at inference"
- Block diffusion LLMs (BD3LM): A diffusion parameterization that models tokens within blocks via diffusion while sequencing blocks autoregressively. "Block diffusion LLMs (BD3LM \cite{arriola2025block}) improve sample quality"
- Block-causal mask: An attention mask that allows each block to attend to itself and previous blocks, enforcing blockwise causality. "a block-causal mask $M_{\text{Enc} \in \{ 0, 1\}^{L \times L}$"
- Categorical distribution: A discrete probability distribution over a finite set of categories. "where represents a categorical distribution"
- Cross-attention: Attention mechanism where the decoder attends to encoder outputs to condition predictions on encoded context. "conditioned on the encoder output via cross-attention"
- Decoder-only architecture: A transformer design using only a decoder stack (no encoder), typical in many LLMs. "prior diffusion models use a decoder-only architecture"
- Denoising network: The parameterized model in diffusion that predicts cleaner data from corrupted inputs. "train a denoising network to remove noise"
- Discrete denoising diffusion probabilistic models (D3PM): Diffusion models operating over discrete variables with defined forward corruption and learned reverse denoising. "Discrete denoising diffusion probabilistic models (D3PM \cite{austin2021structured})"
- Discrete diffusion models: Diffusion-based generative models over token sequences that iteratively denoise discrete variables. "Discrete diffusion models enable parallel token sampling for faster inference than autoregressive approaches."
- Encoder-decoder architecture: A transformer design that encodes inputs and decodes outputs, with decoder attending to encoder representations. "we propose an encoder-decoder transformer architecture"
- FLOPs: A measure of computational cost counting floating-point operations. "Forward-pass training FLOPs comparison."
- Fused attention kernel: An implementation that combines self- and cross-attention into a single kernel call to reduce overhead. "enables a fused attention kernel that reduces memory access and kernel launch overhead."
- Gaussian diffusion: Classical diffusion over continuous variables where noise is Gaussian. "originally proposed as an extension of Gaussian diffusion"
- Key-value (KV) cache: Stored key and value tensors from attention layers to avoid recomputation across decoding steps. "key-value (KV) caching which significantly accelerates inference"
- Kernel fusion: Optimization that merges multiple GPU kernel launches into one to reduce memory traffic and latency. "efficient implementation of the decoder's attention module using kernel fusion."
- Latent variables: Hidden variables corrupted by the forward process that the model denoises during sampling. "latent variables , for "
- Likelihood: The probability of observed data under a model, often optimized via log-likelihood. "The likelihood of this model is defined as"
- Logits: Pre-softmax outputs of a model used to define categorical distributions over tokens. "The decoder outputs logits that are conditioned on the encoder output via cross-attention"
- MDLM (masked diffusion LLM): A full-sequence masked diffusion formulation for language modeling. "standard full-sequence masked diffusion model (MDLM \cite{sahoo2024simple})"
- Noise schedule: A function controlling how much corruption is applied at each diffusion time step. "is a noise schedule decreasing in "
- One-hot vector: A vector with a single 1 indicating a category and 0 elsewhere, used to represent discrete tokens. "define corruption processes over discrete one-hot vectors ."
- Pareto frontier: The curve of optimal trade-offs between competing objectives (e.g., quality vs. speed). "We also map the Pareto frontier of the quality-throughput trade-off"
- Perplexity (PPL): A standard language modeling metric measuring how well a model predicts a sample. "We compute perplexity (PPL) on the validation set of this corpus"
- Posterior (true posterior): The distribution of cleaner variables given corrupted ones and original data under the forward process. "the true posterior is known"
- Reverse process: The learned denoising trajectory that maps noisy variables back toward clean data. "In the reverse process within each block "
- Sequence-to-sequence modeling: Tasks mapping input sequences to output sequences, often using encoder-decoder transformers. "encoder-decoder architecture, commonly used in sequence-to-sequence modeling"
- Shared KV cache: A design where the decoder reuses the encoder’s cached keys/values to stabilize and speed cross-attention. "The 'shared KV cache' variant"
- Throughput: The rate of token generation or processing per second during inference. "inference throughput"
- Vectorized implementation: Batched computation across positions/blocks to process many elements in a single pass. "Vectorized Implementation~"
- Weight-tying: Reusing the same parameters across modules to reduce memory and potentially aid training. "We reduce the memory footprint of the model by weight-tying the encoder and decoder parameters."
Collections
Sign up for free to add this paper to one or more collections.

