Diffusion Language Models are Super Data Learners
Abstract: Under strictly controlled pre-training settings, we observe a Crossover: when unique data is limited, diffusion LLMs (DLMs) consistently surpass autoregressive (AR) models by training for more epochs. The crossover shifts later with more or higher-quality data, earlier with larger models, and persists across dense and sparse architectures. We attribute the gains to three compounding factors: (1) any-order modeling, (2) super-dense compute from iterative bidirectional denoising, and (3) built-in Monte Carlo augmentation; input or parameter noise improves AR under data constraint but cannot close the gap. At scale, a 1.7B DLM trained with a ~1.5T-token compute budget on 10B unique Python tokens overtakes an AR coder trained with strictly matched settings. In addition, a 1B-parameter DLM achieves > 56% accuracy on HellaSwag and > 33% on MMLU using only 1B tokens, without any special tricks, just by repeating standard pre-training data. We also show that rising validation cross-entropy does not imply degraded downstream performance in this regime.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper compares two ways of training LLMs—autoregressive models (AR) and diffusion LLMs (DLMs)—to answer a simple question: when you don’t have much unique training data, which kind of model learns more? The main claim is that DLMs are “super data learners.” If you repeat the same data many times, DLMs keep getting better and eventually beat AR models of the same size.
Key Objectives
The authors set out to:
- Find out which model type learns more from each unique token when data is limited but compute is available.
- Measure when the “crossover” happens (the point where DLMs overtake AR), and how it shifts with:
- The amount of unique data
- Data quality
- Model size
- Model sparsity (dense vs. mixture-of-experts)
- Test whether adding noise to AR models (like masking inputs or using dropout) can close the gap with DLMs.
- Check if a higher validation loss (often called “overfitting”) actually hurts performance on real tasks.
- Scale up to a practical case: training code models on 10 billion tokens of Python to see if the crossover still appears.
Methods and Approach
Think of the two model types like different ways to solve a word puzzle:
- Autoregressive (AR) models
- They read and predict text left to right, one token at a time. Imagine typing a sentence and guessing the next word each time, using only what came before.
- Training uses “teacher forcing,” which means the model sees the real previous words and learns to predict the next one at every position.
- This is very efficient and fast, but it strictly follows the left-to-right rule.
- Diffusion LLMs (DLMs)
- They use a “mask-and-fill” strategy. Picture taking a sentence, covering some words with blanks, and training the model to fill in the blanks using all visible context on both sides.
- The model repeats this “add noise, then denoise” process many times, revealing different words step-by-step. Because it can look both left and right, it can learn in any order, not just left-to-right.
- This approach naturally creates many variations of the same sentence by masking different sets of words—like generating lots of practice quizzes from the same textbook page.
In experiments, the authors:
- Trained AR and DLM models under closely matched settings (same size, same data, same total compute).
- Varied how much unique data they had, the data quality, model size (1B–8B parameters), and whether the model was dense or sparse (Mixture-of-Experts).
- Evaluated on multiple-choice benchmarks (HellaSwag, MMLU) and coding benchmarks (HumanEval, MBPP).
- Tested “noise” tricks on AR models, like masking some input tokens or using dropout, to see if this mimics the benefits DLMs get from their masking-based training.
Simple analogies for technical ideas:
- Any-order modeling: DLMs can learn relationships no matter where the word appears—like solving a crossword where clues connect in all directions.
- “Super-dense compute”: DLMs spend more computational effort per example by repeatedly refining predictions, similar to doing multiple passes of careful review on the same homework.
- Monte Carlo augmentation: DLMs automatically make many noisy versions of the same data and learn from all of them, like practicing with dozens of slightly different worksheets made from the same chapter.
Main Findings and Why They Matter
Key results from the paper:
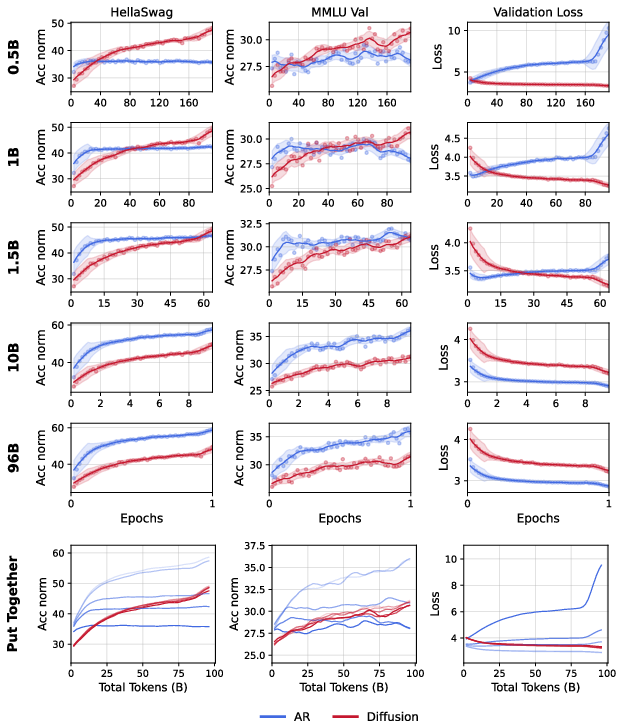
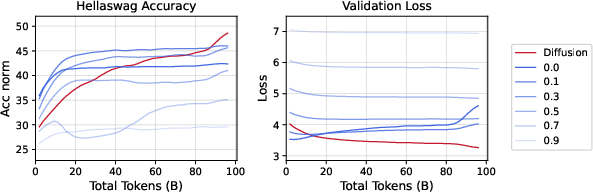
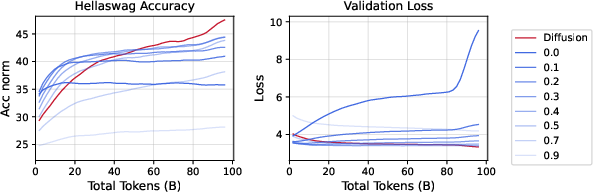
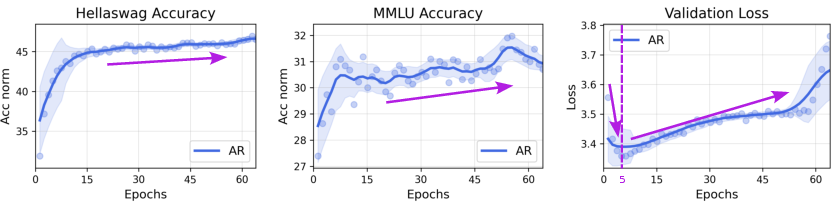
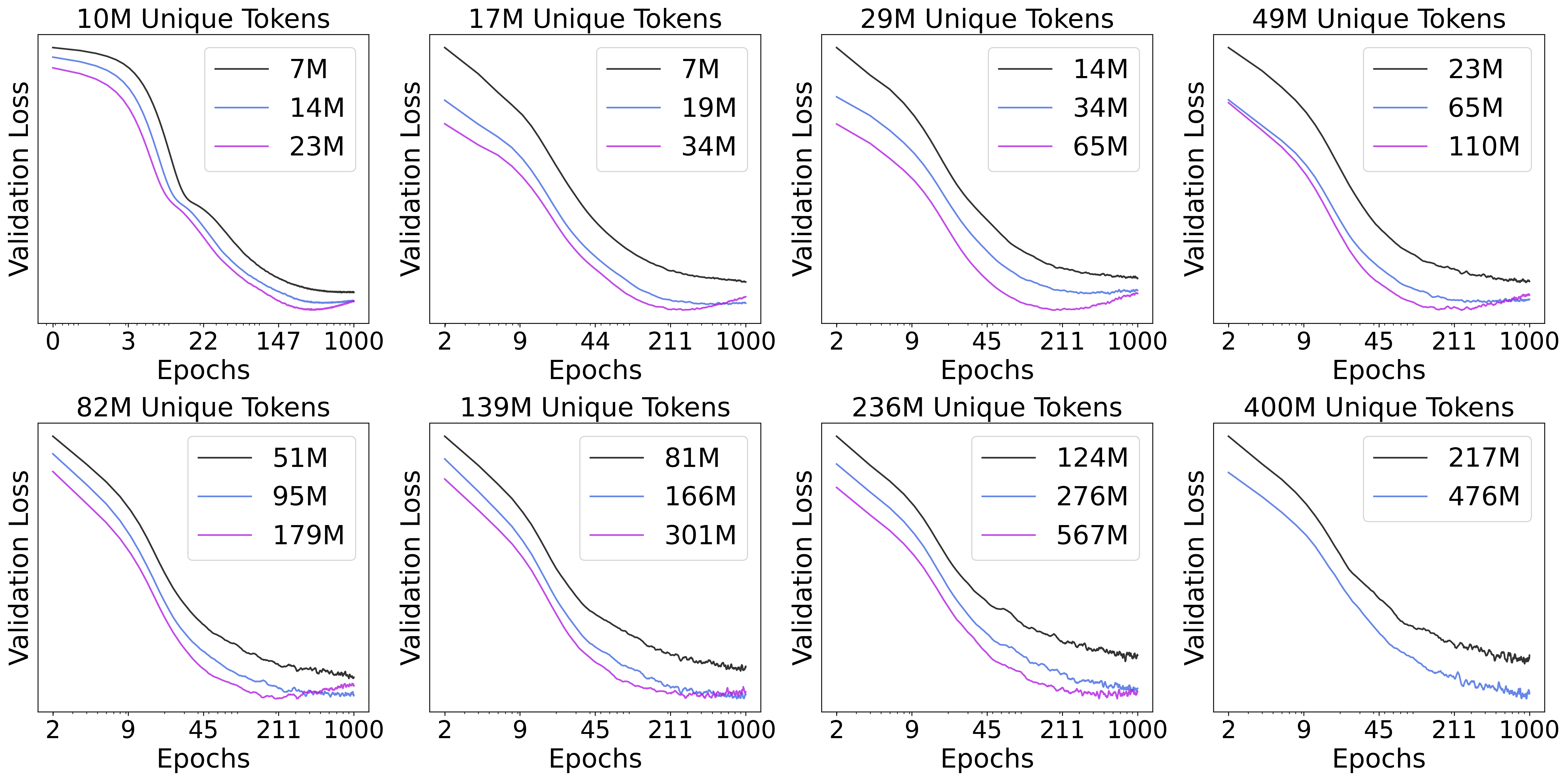
- The crossover effect: When unique data is limited and you train for more epochs, DLMs consistently overtake AR models of the same size.
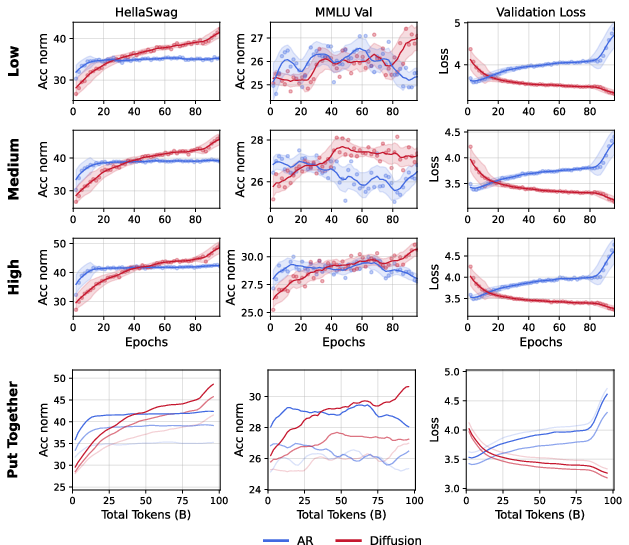
- More unique data or higher data quality pushes the crossover later.
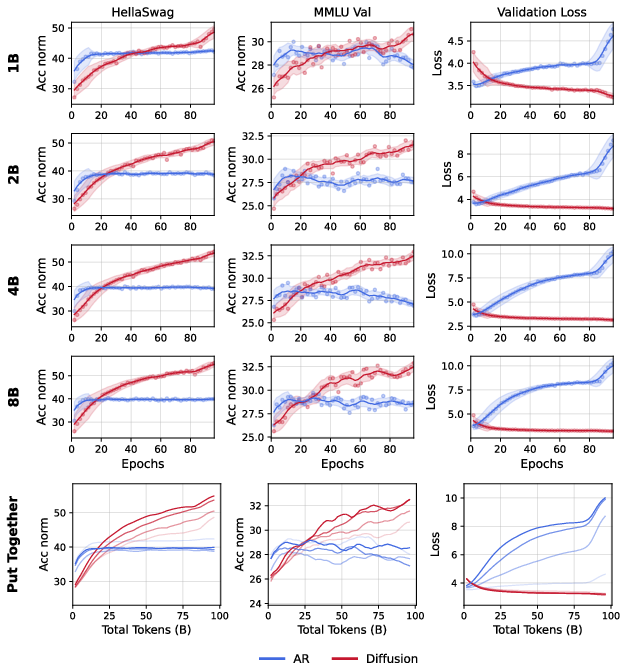
- Larger models make the crossover happen earlier.
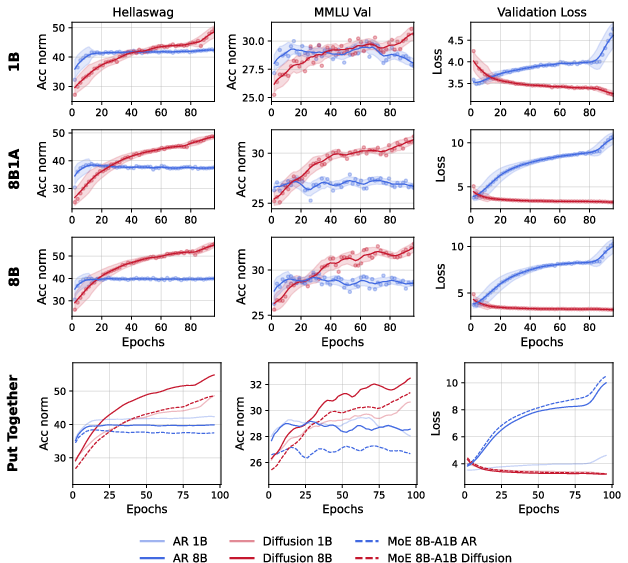
- The pattern holds for both dense and sparse (MoE) architectures.
- Data efficiency: DLMs learn more from each unique token—often over 3× more—by turning the same data into many useful training cases (thanks to masking and denoising).
- Noise helps AR, but not enough: Adding input masking or dropout to AR models does improve them under data scarcity, but DLMs still win.
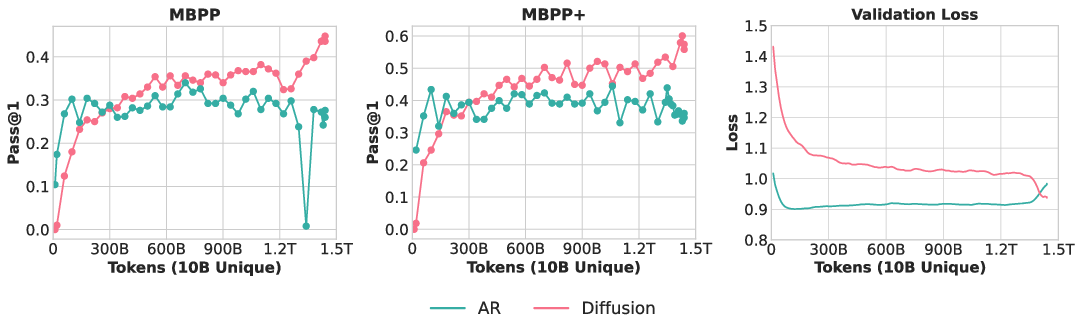
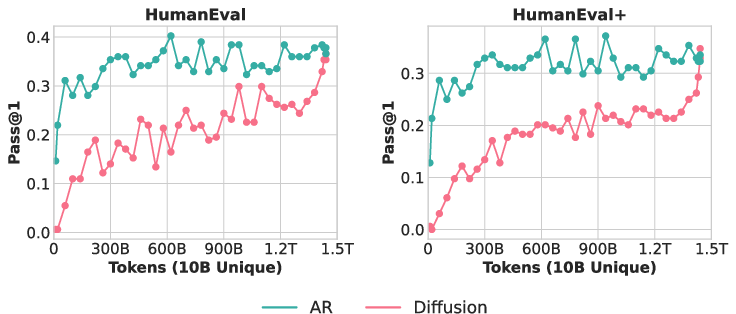
- Scaling to code: A 1.7B-parameter DLM trained on about 10B unique Python tokens with a 1.5 trillion token compute budget beat a matched AR coder. The DLM reached parity with strong AR code models trained on far more unique tokens.
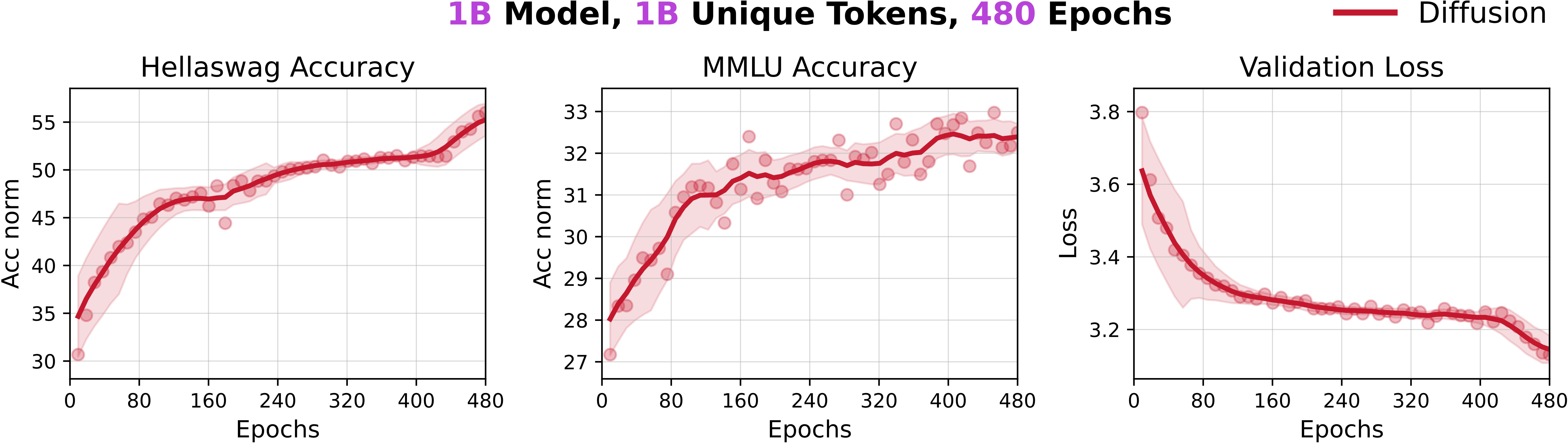
- Strong performance with repeated data: A 1B-parameter DLM got over 56% on HellaSwag and over 33% on MMLU using only 1B unique tokens—by repeating standard pre-training data many times.
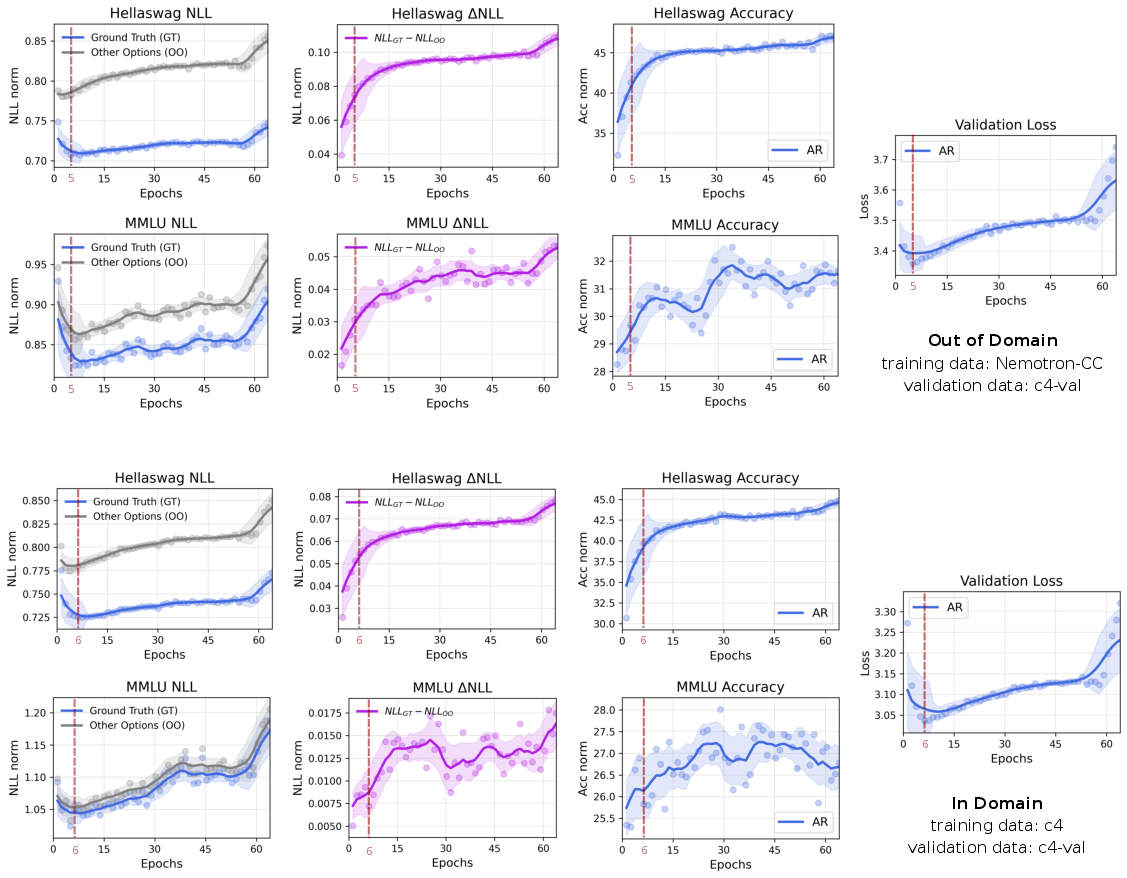
- Validation loss vs. real performance: Even when validation loss rises (which looks like overfitting), downstream accuracy on real tasks can keep improving. In other words, a higher loss doesn’t always mean the model got worse at solving problems.
- DLMs can overfit too, but later: If you train long enough on very small unique datasets, DLMs eventually overfit; however, they extract much more value before they saturate.
Why this matters:
- As high-quality data becomes scarce but compute keeps getting cheaper, DLMs may be the better choice to maximize what we can learn from limited data.
Implications and Potential Impact
What this research suggests for the future:
- In a “data-bound” world, DLMs are promising: If the main limit is how much unique, high-quality data we can get—and not the amount of compute—DLMs can deliver more capability per token.
- Trade-offs: DLMs need more computation to train and to generate text, although much of it can be parallelized. AR can still be the better option when data is plentiful and you want maximum efficiency.
- Practical deployment: DLM tooling is less mature than AR today, and careful choices (like masking schedules and sampling steps) matter. There are also risks of memorization when reusing data many times, so stronger safety checks are needed.
- Broad applications: Any-order modeling and iterative refinement may boost tasks that need back-and-forth reasoning—like coding and math—where looking both left and right helps.
- Methodological lesson: Don’t rely only on validation loss curves. Evaluate on actual tasks to understand true model progress.
In short, the paper argues that diffusion LLMs are built to squeeze more learning out of the same data. If acquiring great data is the hardest part, DLMs might be the smarter bet—even if they take more compute to reach their full potential.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Hyperparameter and pipeline fairness: Diffusion runs reused AR-optimized hyperparameters; a systematic, diffusion-first tuning study (optimizer, LR schedules, normalization, masking schedules, denoiser targets) is needed to rule out under-optimization bias.
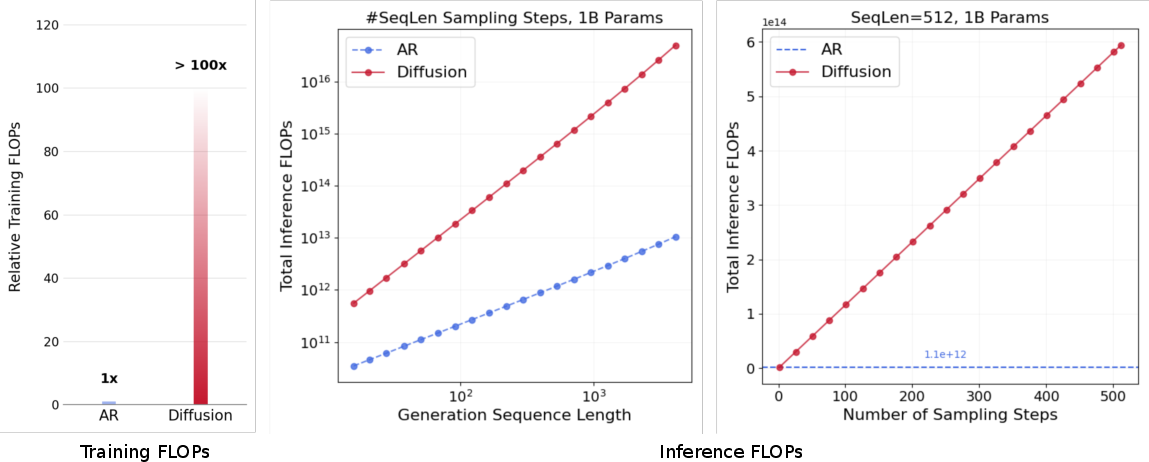
- Compute accounting: Training/inference FLOPs and wall-clock throughput are only approximated (e.g., “>100×”); provide rigorous, reproducible measurements (FLOPs, MFU, latency, memory) across hardware and sequence lengths, including energy and cost per unit improvement.
- Factor isolation: The paper ablates noisy augmentation but does not isolate “any-order modeling” or “super-density”; design controlled experiments that keep FLOPs constant while varying order constraints (e.g., blockwise AR, prefixLM, encoder–decoder denoising) to quantify each factor’s causal contribution.
- Baseline coverage: Compare DLMs against strong denoising baselines (T5-style span corruption, BART, encoder–decoder masked objectives) and discrete diffusion variants (absorbing vs replacement kernels, time-conditioned denoisers) under matched regimes.
- Evaluation protocol sensitivity: Crossover timing shifts with shot settings (0-shot vs 3-shot in code); run a systematic study varying prompt formats, few-shot exemplars, decoding temperatures, pass@k, and stop criteria to disentangle training dynamics from evaluation artifacts.
- Benchmark breadth: Results are limited to English web text and Python; extend to multilingual corpora, low-resource languages, math, scientific writing, dialogue, summarization, translation, and long-form reasoning to test generality.
- Long-context performance: Quantify DLM behavior with very long contexts (e.g., >32k tokens) versus AR with KV cache; measure quality, latency, memory, and stability as steps × context scale.
- Streaming and tool-use: Assess DLMs on streaming generation, tool-use, and interactive multi-turn tasks where causal generation and KV cache are advantageous; define metrics when perplexity is inapplicable.
- Multi-token decoding trade-offs: Substantiate claims of “bleeding fast” multi-token generation with head-to-head wall-clock latency–quality trade-off curves versus AR under continuous batching.
- Masking schedule design: Systematically ablate masking schedules, denoising weights w(t), timestep discretization, and corruption patterns; produce guidelines for schedule selection by task/domain.
- Adaptive test-time compute: Explore dynamic or input-adaptive denoising step schedules and early exit policies to reduce inference FLOPs while preserving quality.
- MoE fairness and scaling: The AR MoE underperforms under data constraints; check if routing/load-balancing differences (token-choice vs alternative routing, auxiliary/z losses) or optimization instability drive the gap; extend MoE experiments beyond 8B total with varied expert counts and capacities.
- Larger model scales: Validate crossovers at frontier scales (>10B–70B+ parameters) under matched data and compute; test whether the “earlier crossover with larger models” persists.
- Post-training alignment: Evaluate whether DLM advantages survive instruction tuning, preference optimization (RLHF/DPO), and tool integration; compare alignment stability and sample quality after SFT/RL.
- AR augmentation parity: Test stronger AR data augmentation (span masking, denoising autoencoding, stochastic depth, scheduled dropout, model rewriting pipelines) to evaluate how close AR can get when given diffusion-like augmentation.
- Theoretical characterization: Provide sample complexity or information-theoretic analyses explaining why any-order modeling + Monte Carlo augmentation increases data efficiency; derive scaling laws predicting crossover points as functions of unique tokens, epochs, and parameters.
- Validation loss vs downstream metrics: Extend the NLL–accuracy decoupling analysis beyond multiple-choice to generative tasks (code, long-form) with formal correlation studies, calibration metrics, and error taxonomy.
- Memorization and safety: Heavy data reuse raises contamination and privacy risks; run membership inference, canary leakage, and duplication audits to quantify memorization under super-dense training.
- Data quality methodology: Clarify and release the procedure for defining low/medium/high quality tiers; quantify quality metrics, filtering criteria, and their impact on crossover timing; ensure decontamination of eval sets.
- Tokenization effects: Ablate tokenization choices (BPE vs SentencePiece, byte-level, special mask token design) for text and code; measure their interaction with diffusion corruption and denoising.
- Curriculum and repeat scheduling: Study how epoch order, annealing token usage, and curriculum pacing affect overfitting onset and downstream gains; develop repetition-aware schedulers.
- Reproducibility: Release training code, configs, seeds, data filtering scripts, and models to enable replication of crossovers; include multiple seeds/error bars to quantify variance.
- Hardware and systems optimization: Investigate practical parallelization strategies (pipeline/tensor/data parallel, fused kernels) for DLM inference; quantify how newer GPU architectures change the AR–DLM latency gap.
- Memory footprint and stability: Measure activation/parameter memory under iterative bidirectional refinement; evaluate gradient checkpointing and stability at high step counts.
- Hybrid paradigms: Develop and benchmark hybrids (e.g., block diffusion, bidirectional refinement with causal windows) that interpolate between AR efficiency and DLM data potential; report when hybrids outperform either extreme.
- Domain-specific data-bound regimes: Validate crossovers in truly scarce domains (robotics logs, clinical notes, biological sequences) with careful decontamination and domain-specific metrics.
- Decoding quality beyond accuracy: For code and long-form generation, evaluate robustness (test coverage, runtime errors), style consistency, and faithfulness, not just pass@k or accuracy.
- Uncertainty and calibration: Compare confidence calibration (ECE/Brier) between AR and DLMs under repetition; test whether DLMs’ rising absolute NLL harms or helps calibration.
- Retrieval augmentation: Examine whether DLMs’ bidirectional denoising synergizes with retrieval (RAG) during training/inference, and whether this shifts crossover timing.
- Carbon footprint and cost–benefit: Quantify energy use and monetary cost per unit of downstream gain for DLM vs AR across regimes to inform practical deployment decisions.
Practical Applications
Practical Applications of “Diffusion LLMs are Super Data Learners”
Below are actionable, real-world applications that follow from the paper’s findings, methods, and innovations. They are grouped into Immediate and Long-Term categories and linked to sectors, with assumptions and dependencies noted.
Immediate Applications
- DLM-first model selection for data-scarce domains
- Use DLMs when unique high-quality tokens are limited but compute is available; expect higher accuracy per unique token than equally sized AR models.
- Sectors: healthcare (clinical notes), legal, finance (compliance text), robotics (logs), low-resource languages, enterprise verticals with proprietary corpora.
- Tools/workflows: internal model selection rubric that pivots to DLMs for data-bound regimes; procurement templates emphasizing data efficiency rather than MFU.
- Assumptions/dependencies: access to sufficient training compute; serving stack that tolerates higher inference FLOPs; basic DLM training codebase.
- Diffusion coders for niche languages and constrained codebases
- Train 1–3B DLM code assistants on limited unique code (e.g., 5–10B tokens) with repeated epochs to reach parity/superiority over matched AR coders.
- Sectors: software engineering, DevOps, embedded/legacy languages, scientific computing.
- Tools/products: vertical code copilots, unit-test generator, patch/diff refiner, whole-function multi-token completion.
- Assumptions/dependencies: strict deduplication to mitigate memorization; integration with IDEs; parallel inference to limit latency.
- Data reuse with principled noise schedules (Monte Carlo augmentation)
- Replace ad-hoc data repetition with DLM-native corruption schedules to expand effective dataset variants without manual augmentation pipelines.
- Sectors: all model pretraining/foundational model labs; enterprise model teams.
- Tools/workflows: training pipelines that couple dataset repeat factors with masking schedules; hyperparameter presets for α(t) schedules and step counts.
- Assumptions/dependencies: monitoring for contamination/memorization; compute budget headroom.
- Any-order editing assistants and document “refinement” tools
- Deploy DLM-powered bi-directional, iterative writers that can revise earlier context and generate multi-token edits for faster drafting.
- Sectors: productivity software, publishing, customer support KB maintenance.
- Products: paragraph-level rewrite, table/citation fill-in, “hole-punch” drafting where masked regions are iteratively completed.
- Assumptions/dependencies: UX designed for batch updates (less streaming); content safety filters.
- Validation/evaluation practice updates (don’t equate rising val loss with worse downstream)
- Adopt delta-NLL or pairwise logit-gap dashboards and benchmark-first early stopping; avoid over-reliance on perplexity when repeating data.
- Sectors: academia, industry R&D, ML platform tooling.
- Tools/workflows: eval pipelines that track ΔNLL on MC tasks; dashboards separating likelihood calibration from discriminative accuracy.
- Assumptions/dependencies: curated validation sets; logging infra for per-option likelihoods.
- Lightweight gains for AR when DLM isn’t feasible: input masking or dropout
- Inject modest input masking (~10%) or parameter dropout to AR pretraining under data scarcity for measurable improvements.
- Sectors: teams locked into AR stacks; edge models with limited retraining scope.
- Tools/workflows: optional noisy-augmentation toggles in AR training recipes.
- Assumptions/dependencies: tuning to avoid collapse at high noise; still won’t close the DLM gap.
- Data/compute planning for the “data-bound era”
- Redesign scaling strategies to prioritize FLOPs over unique tokens when data is the bottleneck; explicitly budget for super-dense training.
- Sectors: strategy and infra teams in AI orgs; cloud providers; cost modellers.
- Tools/workflows: capacity planning that targets token-repeat epochs; ROI models for FLOPs-per-unique-token.
- Assumptions/dependencies: access to affordable compute; carbon/energy accounting.
- DLMs for structured imputation and any-order completion
- Use DLMs to fill sparse fields in semi-structured artifacts (tables, forms, medical templates) by masking and denoising arbitrary spans.
- Sectors: healthcare (EHR templating), operations, CRM, back-office.
- Products: form completion assistants, report assembly tools.
- Assumptions/dependencies: compliance guardrails; evaluation on domain fidelity.
- Small-data vertical copilots for enterprises
- Build internal copilots from limited proprietary text by repeating and corrupting corpora (108–109 tokens) rather than waiting for more data.
- Sectors: insurance, manufacturing (maintenance logs), telecom (ticket notes), energy (incident reports).
- Products: troubleshooting assistants, SOP authoring, change-log analysis.
- Assumptions/dependencies: governance for repeated exposure to sensitive text; access controls; audit trails.
- MoE decisions under data constraints
- Prefer dense DLMs over sparse AR when unique data is small; if using MoE, target DLM MoE with sufficient activated FLOPs.
- Sectors: platform model teams; inference infra.
- Tools/workflows: sparsity sweeps that compare FLOPs-matched and parameter-matched settings with DLMs.
- Assumptions/dependencies: routing stability; batch sizes to keep MFU acceptable.
- Benchmarking and protocol hygiene for generative tasks
- Standardize 0-shot vs 3-shot settings to interpret crossovers; track crossover timing sensitivities to protocol choices (e.g., MBPP vs HumanEval).
- Sectors: evaluation bodies, open-source benchmarks, model vendors.
- Tools/workflows: metadata-rich eval runs; early-vs-late training probes.
- Assumptions/dependencies: community agreement on reporting formats.
- Risk and safety auditing upgrades for high-epoch training
- Add stronger memorization testing and decontamination checks when repeating data many epochs; red-team for leakage.
- Sectors: policy/compliance, safety teams, healthcare/finance regulators.
- Tools/workflows: membership inference probes, k-NSP decontamination; privacy budgets tied to epoch counts.
- Assumptions/dependencies: reliable dedup; secure data handling.
Long-Term Applications
- Industrial-grade DLM serving stacks with parallel decoding
- Build runtime kernels and schedulers optimized for iterative, bidirectional refinement and multi-token updates to achieve practical latency.
- Sectors: cloud inference providers, accelerator vendors, model-serving platforms.
- Tools/products: specialized CUDA kernels, block-wise attention for DLM, step-adaptive schedulers.
- Assumptions/dependencies: hardware support; compiler/runtime maturity.
- Hybrid AR–Diffusion systems (e.g., block diffusion)
- Combine AR’s streaming efficiency with diffusion’s data potential via blockwise any-order denoising conditioned on clean prefixes.
- Sectors: consumer chat, real-time assistants, coding IDEs.
- Products: hybrid decoders toggling modes by context; latency–quality trade-off controllers.
- Assumptions/dependencies: training objectives that interoperate; robust schedules; new decoding policies.
- DLMs for privacy-preserving domains where unique data cannot scale
- Train hospital- or bank-specific foundation models with repeated, noise-augmented corpora while enforcing strict privacy audits.
- Sectors: healthcare, finance, government.
- Products: domain-tuned copilots, claim/appeals assistants, case summarizers.
- Assumptions/dependencies: certified privacy toolchains; reproducible memorization audits; regulator buy-in.
- Low-resource language and dialect modeling at practical quality
- Deliver capable LMs for languages with small corpora by leaning on DLM training with aggressive repetition and masking schedules.
- Sectors: education, localization, public-sector services.
- Products: translation and tutoring assistants in underserved languages.
- Assumptions/dependencies: curated seed corpora; culturally aligned evaluation sets; community partnerships.
- Scientific and biomedical sequence modeling with any-order dependencies
- Apply DLMs to DNA/protein or symbolic math where non-causal dependencies are strong; perform masked denoising for structure-aware completion.
- Sectors: biotech, pharma, math/physics automation.
- Products: sequence repair/synthesis suggestions, proof-step fill-in assistants.
- Assumptions/dependencies: domain tokenization; structure-aware masking; high compute.
- Retrieval-augmented diffusion generation (RAG-D)
- Couple DLMs with retrieval to further reduce unique data needs; iteratively denoise with retrieved spans as unmasked anchors.
- Sectors: enterprise search, legal discovery, technical support.
- Products: citation-grounded drafting, traceable answers with multi-token insertion.
- Assumptions/dependencies: retrieval–denoising interfaces; context-window management.
- Compute–carbon policy and standards for super-dense training
- Develop reporting norms and incentives for energy-efficient FLOPs scaling in data-bound regimes; carbon budgets for high-epoch training.
- Sectors: policy/regulators, sustainability offices, cloud providers.
- Products: standardized energy disclosures, green credits for parallel-friendly kernels.
- Assumptions/dependencies: reliable metering; accepted benchmarks of “data efficiency.”
- New evaluation paradigms beyond perplexity
- Institutionalize ΔNLL/relative likelihood metrics, calibration-aware scoring, and data-repetition-aware overfitting diagnostics.
- Sectors: academic ML, standards bodies, benchmark hosts.
- Tools/products: open-source eval suites instrumented for option-wise log-likelihoods and calibration curves.
- Assumptions/dependencies: broad community adoption.
- Safety-by-design for repeated exposure regimes
- Build frameworks to control memorization risk as a function of epochs and masking; automated checks in training loops.
- Sectors: safety engineering, compliance.
- Products: “epoch budgets,” automated canary insertion and detection, memorization dashboards.
- Assumptions/dependencies: robust detection methods; shared test suites.
- DLM-optimized hardware and compilers
- Architect accelerators that favor bidirectional attention and iterative passes; exploit parallelizable steps in diffusion decoding.
- Sectors: semiconductor, systems research.
- Products: DLM-friendly tensor cores, scheduling primitives.
- Assumptions/dependencies: stable software abstractions; market demand.
- Curriculum scheduling for masking and step counts
- Research curricula that adapt masking ratios/step counts over epochs to maximize learning throughput under fixed compute.
- Sectors: foundational model labs, AutoML.
- Tools/products: automated schedule search, closed-loop training controllers.
- Assumptions/dependencies: reliable proxies for downstream gains; reproducibility.
- Regulatory guidance for choosing modeling paradigms
- Issue advisories indicating when DLMs vs AR are preferable in public-sector deployments given data scarcity, privacy, and energy goals.
- Sectors: government IT, public services, procurement.
- Products: model selection frameworks, compliance checklists.
- Assumptions/dependencies: evidence synthesis across domains; stakeholder consultation.
- Multi-modal diffusion LMs for rich editing and insertion
- Extend masked denoising to text+code+tables+images with any-order completion for document/process automation.
- Sectors: office suites, analytics, RPA.
- Products: cross-modal “fill the gaps” agents; report assembly from heterogeneous inputs.
- Assumptions/dependencies: multi-modal tokenizers; alignment and safety for mixed content.
Notes on Assumptions and Dependencies Across Applications
- Compute availability: DLMs trade compute for data potential; expect higher training and (parallelizable) inference FLOPs than AR. Budgeting and hardware support are critical.
- Serving maturity: DLM inference stacks (kernels, schedulers, decoding policies) are less mature than AR KV-cached pipelines; latency targets may require engineering.
- Data governance: repeated training heightens memorization risk; stronger deduplication, contamination audits, and privacy testing are needed.
- Evaluation nuance: rising validation cross-entropy may not imply worse downstream performance; rely on task-specific metrics and relative likelihoods.
- Domain fit: any-order modeling and span denoising shine where non-causal dependencies or structured gaps exist (code, forms, tables, sequences).
- Scalability: Sparse vs dense design should consider effective FLOPs per example under data scarcity; dense DLMs benefit consistently from scale in this regime.
Glossary
- Absorbing discrete diffusion: A discrete diffusion formulation where masked tokens are absorbed into a special state during corruption. "masked diffusion—also known as absorbing discrete diffusion, which relies on an absorbing transition kernel—has emerged as the most effective formulation"
- Absorbing transition kernel: The transition rule in absorbing discrete diffusion that sends tokens to an absorbing mask state. "masked diffusion—also known as absorbing discrete diffusion, which relies on an absorbing transition kernel—has emerged as the most effective formulation"
- Annealing tokens: A subset of tokens used to gradually adjust training difficulty or distribution in code datasets. "consisting of 9B unique Python tokens and 1B annealing tokens, ensuring a strictly non-repetitive training corpus"
- Any-order modeling: Modeling sequences without a fixed causal order, allowing predictions conditioned on arbitrary visible tokens. "Their bidirectional attention and diffusion objective enable any-order modeling, allowing data to be modeled in arbitrary directions during both training and inference"
- Autoregressive (AR) LLM: A model that factorizes the joint token distribution left-to-right using the chain rule. "Autoregressive (AR) language modeling is the mainstream modeling scheme in state-of-the-art LLMs"
- Auxiliary loss: An additional training loss used to guide MoE routing or regularize the model. "All mixture-of-expert models in this work use token-choice routing with 1e-2 auxiliary loss and 1e-3 z loss"
- Bidirectional attention: Attention mechanism that allows tokens to attend to both left and right context, not just the prefix. "Their bidirectional attention and diffusion objective enable any-order modeling"
- Block diffusion: A hybrid approach that diffuses or generates in blocks instead of token-by-token. "a natural strategy is interpolation, as exemplified by block diffusion methods"
- Causal factorization: Decomposition of sequence likelihood into conditionals over prefixes using the chain rule. "Autoregressive (AR) LLMs have been the default recipe for modern LLMs: causal factorization, teacher forcing delivering high signal-to-FLOPs training"
- Causal mask: A triangular attention mask that restricts each position to attend only to the prefix. "a triangular (causal) mask limits each position’s receptive field to the prefix x_{<i}"
- Compute-bound settings: Training regimes limited by available compute rather than unique data. "Under compute-bound settings with abundant unique data, AR recovers its edge by fitting the data more rapidly"
- Continuous batching: An inference technique that batches streaming requests to maximize hardware utilization. "At inference, token-by-token generation naturally facilitates throughput optimization techniques such as continuous batching"
- Cross-entropy: A likelihood-based loss function used to train probabilistic models. "rising validation cross-entropy (``overfitting'') does not necessarily imply degraded downstream accuracy"
- Crossover: The point in training where DLMs surpass AR models under limited unique data. "we observe a Crossover: when unique data is limited, diffusion LLMs (DLMs) consistently surpass autoregressive (AR) models"
- Data-bound regimes: Training regimes constrained primarily by limited unique data rather than compute. "but in data-bound regimes, which is our focus and, increasingly, the practical reality, DLM is the final winner"
- Diffusion LLM (DLM): A LLM trained via a noising–denoising (diffusion) objective over discrete tokens. "diffusion LLMs (DLMs) consistently surpass autoregressive (AR) models by training for more epochs"
- Diffusion schedule: The function controlling the probability that tokens remain clean or are masked at each noise level. "define a monotone diffusion schedule α_t∈[0,1] with α_0=1 and α_1=0, where α_t is the probability that a token is clean (unmasked) at noise level t"
- Dropout: A regularization technique that randomly zeros neuron outputs to inject parameter noise. "zeroing out a random set of neuron outputs, a.k.a., dropout"
- Exposure bias: A mismatch between training (teacher-forced) and inference (sequential) conditioning leading to errors compounding at generation time. "While AR models are inherently one-directional and can suffer exposure bias from teacher forcing"
- FLOPs: Floating-point operations, a measure of computational cost for training/inference. "DLMs use substantially more FLOPs at train and test time (temporal refinement with bidirectional attention)"
- HellaSwag: A commonsense reasoning benchmark for evaluating LLM multiple-choice performance. "achieves > 56% accuracy on HellaSwag"
- HumanEval: A code generation benchmark evaluating functional correctness of generated programs. "we evaluate both models on HumanEval and HumanEval+, and find that the crossover occurs at a different point compared to MBPP and MBPP+"
- HumanEval+: An extended version of HumanEval with additional tasks or variations. "we evaluate both models on HumanEval and HumanEval+, and find that the crossover occurs at a different point"
- KV-caching: A technique that caches key–value pairs from attention layers to speed up autoregressive decoding. "inference proceeds sequentially with KV-caching for efficiency"
- Mask token: The special token used to indicate masked positions in discrete diffusion. "Let K be the vocabulary size, L the sequence length, and m the mask token"
- Masked diffusion: A discrete diffusion process that corrupts sequences by masking tokens and then denoises them. "Among their variants, masked diffusion—also known as absorbing discrete diffusion, which relies on an absorbing transition kernel—has emerged as the most effective formulation"
- MBPP: A code generation benchmark (Mostly Basic Programming Problems) with a multi-shot evaluation protocol. "MBPP and MBPP+ adopt a 3-shot setting"
- MBPP+: An augmented version of the MBPP code benchmark. "MBPP and MBPP+ adopt a 3-shot setting"
- Mixture-of-Experts (MoE): A sparse model architecture that routes tokens to different expert subnetworks. "we train Mixture-of-Experts (MoEs) for both AR and diffusion models"
- Model FLOPs Utilization (MFU): A metric indicating how effectively a model uses available FLOPs during inference. "a high Model FLOPs Utilization (MFU) during batched inference"
- Monte Carlo augmentation: Implicit augmentation via randomized corruptions sampled during diffusion training. "built-in Monte Carlo augmentation"
- MMLU: A broad knowledge test (Massive Multitask Language Understanding) for LLMs. "and > 33% on MMLU"
- Negative Log-Likelihood (NLL): The negative of the log probability assigned to the correct target; equals cross-entropy for discrete outputs. "Cross-Entropy loss (Negative Log-Likelihood, NLL)"
- Nemotron-CC: A curated web-text corpus used for pretraining experiments. "Cross-over experiments were trained on a subset of the Nemotron-CC corpus"
- Perplexity: An exponentiated average negative log-likelihood metric; lower is better. "perplexity is not directly comparable"
- Pre-layer RMSNorm: A normalization technique applying Root Mean Square normalization before each layer. "pre-layer RMSNorm"
- qk normalization: A normalization applied to query–key projections to stabilize attention. "and qk normalization"
- RoPE (Rotary Position Embeddings): A positional encoding method that rotates token embeddings to encode position. "rotary position embeddings (RoPE)"
- RefinedCode: A code dataset used for training the coder models. "the coders are trained on a subset of the RefinedCode"
- Signal-to-FLOPs ratio: The amount of useful gradient signal per unit of compute during training. "teacher forcing delivering high signal-to-FLOPs training"
- SwiGLU: An activation function variant combining Swish and GLU for better performance. "SwiGLU activations"
- Super-density: The practice of spending substantially more parallelizable FLOPs per task via iterative refinement. "We term these diffusion-based dense models 'super-dense' architectures"
- Teacher forcing: A training method where models learn next-token prediction using ground-truth previous tokens. "Training uses teacher forcing—shifting the sequence so that all next-token conditionals are learned in parallel"
- Token-choice routing: An MoE routing strategy that selects experts based on token-level decisions. "All mixture-of-expert models in this work use token-choice routing with 1e-2 auxiliary loss and 1e-3 z loss"
- Variational bound: A lower bound on log-likelihood optimized by diffusion training objectives. "Masked diffusion maximizes a variational bound on log p_θ(x_0)"
- Warmup–stable–decay (WSD): A learning rate schedule with warmup, plateau, and decay phases. "a warmup-stable-decay (WSD) learning rate schedule peaking at 2e-4 with 1000 warmup steps, followed by a 10% exponential decay to 2e-5"
- z loss: A regularization term (often used with MoE or classification) penalizing logit scale or confidence. "token-choice routing with 1e-2 auxiliary loss and 1e-3 z loss"
Collections
Sign up for free to add this paper to one or more collections.