- The paper demonstrates that iterative image replication unveils significant failures in common NR-IQA metrics, revealing counterintuitive quality improvements despite severe degradation.
- It introduces the Banana100 dataset with 28,000 images from 100 iterative edits using Nano Banana Pro, providing a rigorous benchmark for evaluating image quality degradation.
- The research highlights the potential of large-VLM-based metrics in detecting nuanced artifacts while emphasizing the need for robust quality assessment in long-horizon, multi-turn image editing.
Breaking NR-IQA Metrics via Iterative Image Replication: A Professional Appraisal of "Banana100"
Background and Motivation
Recent advancements in image-text-to-image (IT2T) models and multi-modal agentic systems have enabled complex, multi-step image editing workflows, providing unprecedented creative flexibility and automation. Despite the impressive performance of models such as Nano Banana Pro in single-turn editing scenarios, this paper exposes a critical vulnerability—iterative degradation in long-horizon editing—which manifests as rapid artifact accumulation and failure in instruction following. The research further scrutinizes the robustness of contemporary No-Reference Image Quality Assessment (NR-IQA) metrics in detecting such degradations, revealing pervasive evaluator failures and underscoring risks for both model training and inference in deployed agentic systems.
Dataset Construction and Scope
The authors introduce the Banana100 dataset, comprising 28,000 images generated through 100 iterative editing steps on 13 high-quality, diverse AI-generated initial images (both photorealistic and anime-style) using Nano Banana Pro. These images span a range of challenging visual features, including regular grid structures, varied textures, color gradients, and occlusions. The dataset primarily emphasizes exact replication prompts to isolate degradation effects, but also includes object addition, roundtrip transformations (e.g., decolorization-colorization), and edits under varied model hyperparameters (seed, temperature, resolution).
This comprehensive approach enables controlled assessment of degradation irrespective of confounders such as semantic content changes, and reinforces the generalizability of the findings across differing image types, edit scenarios, and even across alternative image-editing models, such as Nano Banana 2 Fast, FLUX.2 [dev], and Qwen Image Edit.
Qualitative Failure Modes in Multi-Turn Editing
Through multi-step edits, the paper identifies multiple, consistent failure modes:
- Sub-Object Level: Rapid color simplification and loss of fine detail, particularly in visually complex regions like anime character eyes.
- Object Level: Instruction-following lapses manifest as counting errors, replacement instead of addition, and spatial degradation, with reasoning outputs often hallucinating success.
- Image Level: Persistent background noise, aspect ratio drift owing to model output constraints, failed attempts to denoise or reconstruct, and inability to preserve global transformations (mirroring, rotation, monochrome conversion).
These failures persist across prompt variations, hyperparameter sweeps, and editing paradigms, emphasizing the inherent fragility of current IT2T model architectures in maintaining both appearance and semantic fidelity under iterative refinement.
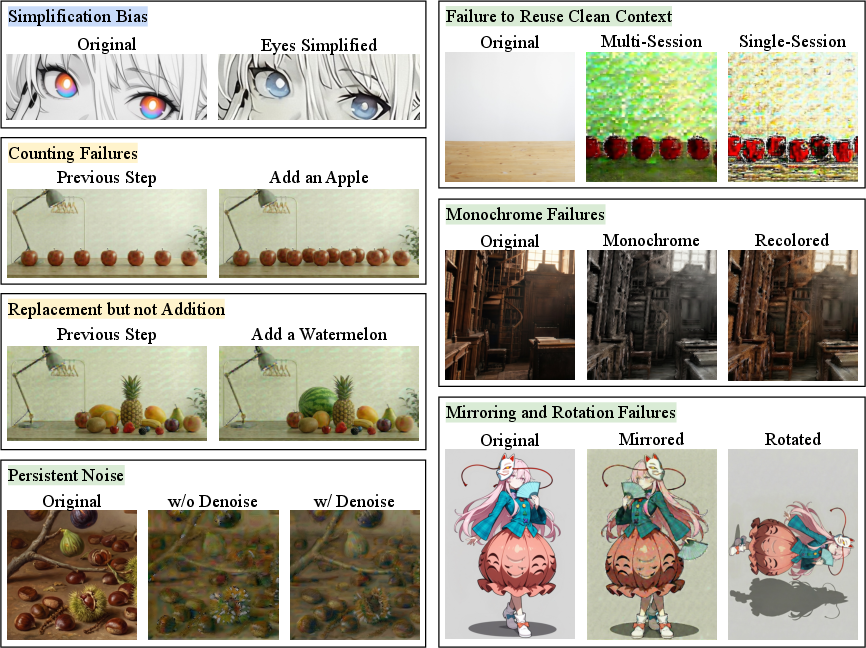
Figure 1: Instruction-following failures are categorized into sub-object, object, and image levels, with visual artifacts emerging consistently across edits.
Quantitative Failure of NR-IQA Metrics
The core quantitative contribution is the systematic evaluation of 21 popular NR-IQA metrics (e.g., BRISQUE, NIQE, CLIPIQA, PI, PIQE) across Banana100’s replicate runs. Contrary to intuition and human judgment, all metrics (save for two recent large-VLM-based methods) fail to assign lower quality scores to degraded images; many actually report improved scores after severe noise induction. For instance, BRISQUE scores drop (improve) in contradiction to visually obvious image corruption after multiple editing steps.
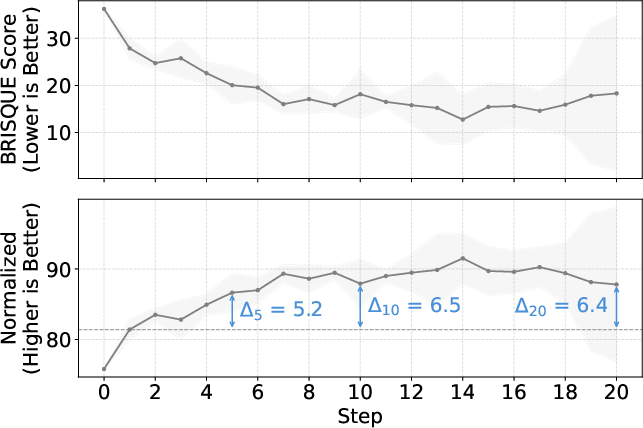
Figure 2: Normalized BRISQUE scores demonstrate counterintuitive improvement with step count despite visible quality loss.
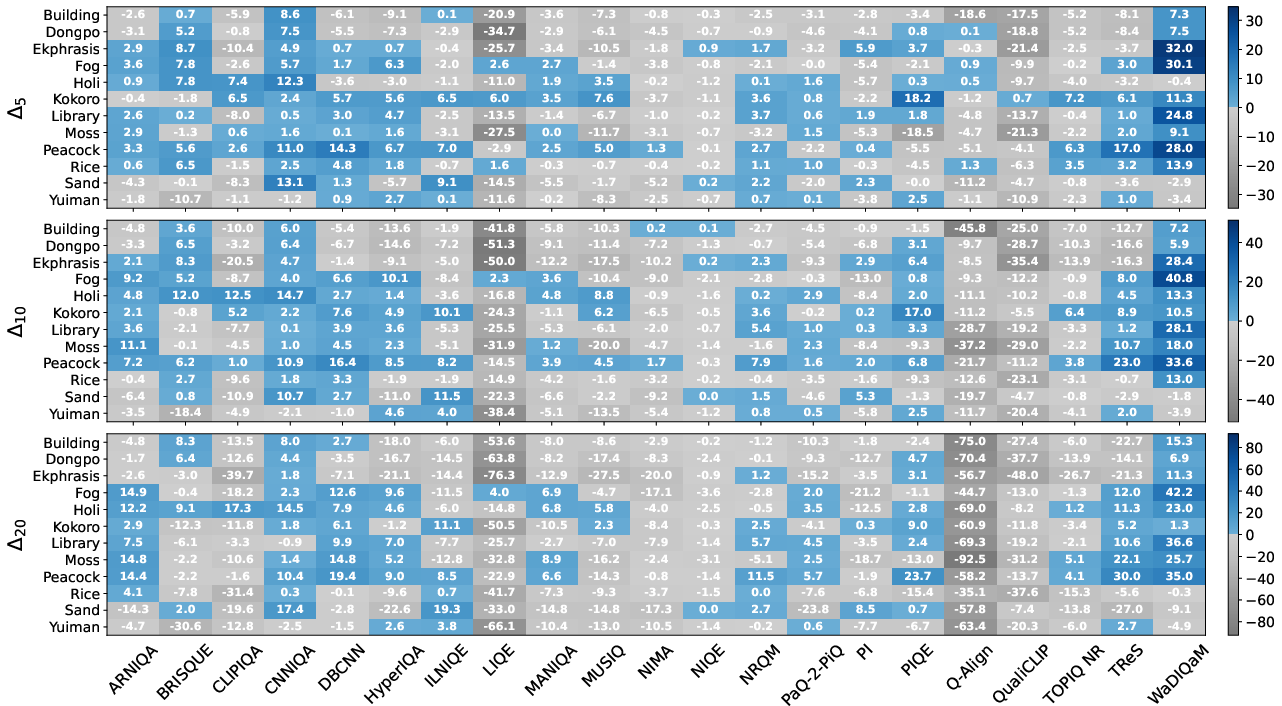
Figure 3: Heatmap quantifies widespread NR-IQA failures, with blue cells marking instances where degraded images receive higher normalized quality scores.

Figure 4: Aggregated failures across metrics and images show no single NR-IQA consistently identifies all degradation cases.
This disparity is attributed to the training regime of NR-IQA metrics, which typically focus on heuristic distortions rather than model-induced, iterative artifacts. The fragility of metrics like BRISQUE and NIQE poses risk of undetected data pollution, jeopardizing future model training (potentially accelerating model collapse [shumailov2024ai, yoon2024model]) and propagating instability in deployed agentic pipelines.
Successes and Limitations of Large-VLM-Based NR-IQA Metrics
Notably, RALI [zhao2025reasoning] and VisualQuality-R1 [wu2025visualqualityr], both based on recent large vision-LLMs, robustly detect iterative degradation across Banana100. However, these metrics reveal vulnerabilities in cases of semantic content changes (e.g., object addition prompts), pointing to a trade-off between robustness to low-level artifacts and adaptation to semantic information.
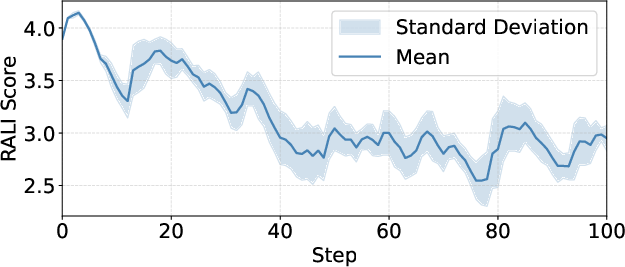
Figure 5: RALI scores fluctuate undesirably with semantic changes, highlighting its sensitivity and lack of robustness in complex editing scenarios.
Model-Agnostic Noise Patterns
Experiments across Nano Banana 2 Fast, FLUX.2 [dev], and Qwen Image Edit confirm that noise accumulation and NR-IQA failures generalize across architectures and implementation modalities, though the specifics of noise manifestation vary: contour-following wrinkles, scatter points, or texture simplification.
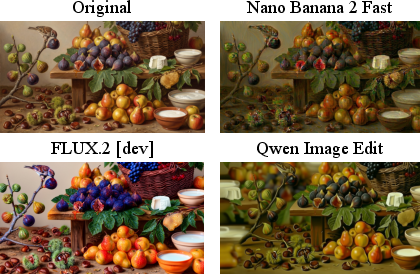
Figure 6: Distinct noise types are generated by different models during replication, indicating qualitative variability but quantitative commonality in degradation.
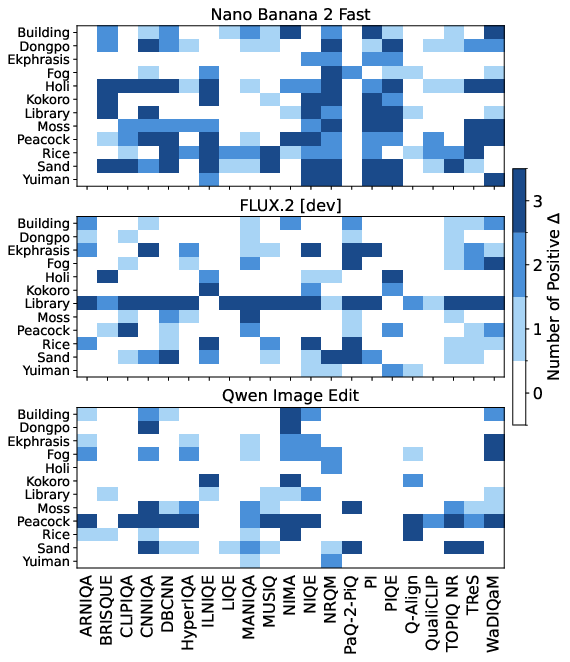
Figure 7: NR-IQA metrics fail to consistently identify degradation across models, further validating the metric vulnerability.
Implications and Prospective Developments
The findings have direct practical and theoretical consequences:
- Quality Control and Dataset Curation: The inability of NR-IQA metrics to detect iterative degradation threatens the integrity of synthetic datasets, potentially resulting in irreversible noise accumulation and performance decay across generations of models.
- Multi-modal Agentic System Safety: Since agentic systems increasingly rely on automated evaluators (often using flawed NR-IQA metrics), their long-horizon editing stability is at risk.
- Metric Development: The demonstrated success of large-VLM-based approaches motivates further research into vision-language reasoning for IQA, enabling more robust, generalizable evaluators capable of detecting nuanced, model-induced artifacts.
- Model Architecture and Training: Addressing iterative noise buildup necessitates architectural refinement and development of strategies for artifact mitigation, such as robust high-frequency feature preservation [liao2025freqedit], reasoning-guided edit tracking, and explicit artifact-aware loss functions.
The release of Banana100 offers a valuable benchmark for both image generator and metric development, challenging future research to eradicate silent quality decay and improve evaluative rigor.
Conclusion
This paper rigorously demonstrates the fragility of popular NR-IQA metrics and IT2T models in iterative editing scenarios. By providing the Banana100 dataset and exposing the dual failures of generators and evaluators, it catalyzes the need for robust, degradation-aware image editing workflows and quality assessment metrics. The implications span data curation, model safety, and the future trajectory of AI image editing and evaluation research, demanding advancements in both generator robustness and metric reliability (2604.03400).

