- The paper introduces MultiBanana, a novel benchmark that rigorously evaluates multi-reference text-to-image generation by addressing compositionality, cross-domain mismatches, rare concepts, and multilingual prompts.
- The paper details a sophisticated dataset construction pipeline that integrates high-quality real and synthetic images with dual-validated editing instructions to ensure balanced task representation.
- The paper conducts comprehensive experiments showing that both closed and open-source models struggle with increased reference complexity, highlighting areas for future research.
MultiBanana: Benchmarking Multi-Reference Text-to-Image Generation
Motivation and Benchmark Architecture
MultiBanana establishes a rigorous and diversified evaluation paradigm for multi-reference text-to-image generation, targeting the limitations of prevailing datasets which predominantly focus on single-reference or narrowly defined multi-reference tasks. Existing benchmarks, such as MagicBrush, EditBench, EmuEdit, and DreamOmni2, fail to systematically probe compositionality, domain gaps, rare concepts, and multilingual generalization in complex multi-reference scenarios (2511.22989). MultiBanana extends beyond basic task definitions (e.g., "what to edit" or "number of references") and instead operationalizes benchmarks across orthogonal axes: number of references (up to 8), cross-domain and scale mismatches, rare concept inclusion, and multilingual textual conditioning.
The dataset construction pipeline integrates high-quality real and synthetic images, filters for relevance and safety, conducts hierarchical categorization, and generates validated editing instructions via Gemini and human reviewers. This protocol enables MultiBanana to capture intrinsic difficulty, compositional relationships, and diversity required for state-of-the-art evaluation.
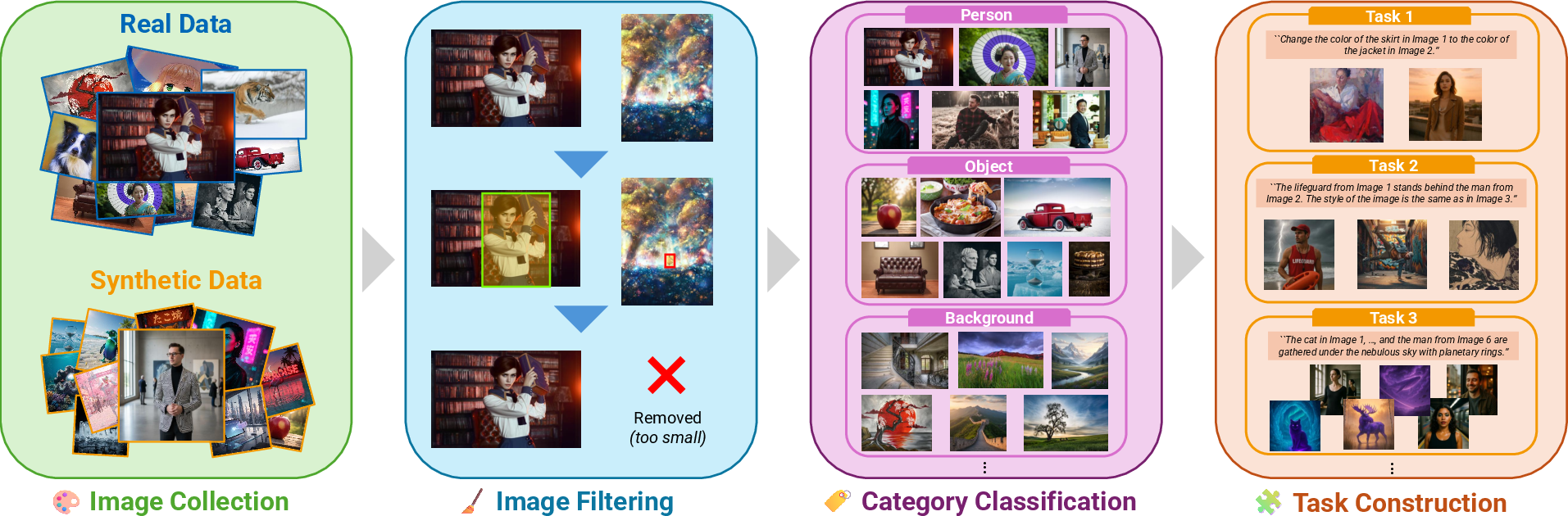
Figure 1: MultiBanana benchmark formation pipeline: staged data collection, filtering, hierarchical classification, and dual (human+Gemini) instruction generation/validation.
Dataset Composition and Diversity
To overcome the categorical and attribute imbalance common in LAION-5B and similar corpora, MultiBanana augments real imagery with synthetic data generated by Nano Banana and ChatGPT-Image-1. This targets increased coverage for person, object, animal, and textual categories, correcting the landscape/background bias found in the base real dataset. The final collection is more balanced, supporting nuanced evaluation across compositional and relational editing tasks.
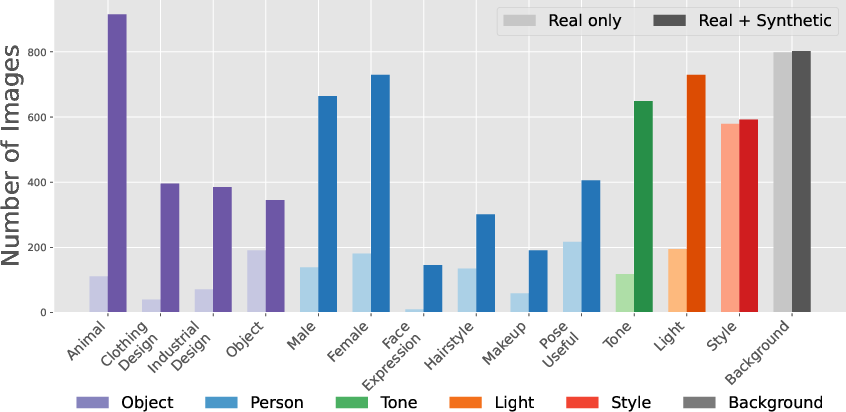

Figure 2: Real vs. synthetic data statistics, with enrichment in subject-centric categories and representative synthesized images per class.
The reference images and editing tasks are distributed across major attribute classes and subcategories, guaranteeing that even in multi-reference configurations (3-8 inputs), each task type—objects, backgrounds, local/global transformations—contains sufficient samples (>70 per type), exceeding previous benchmarks by an order of magnitude.
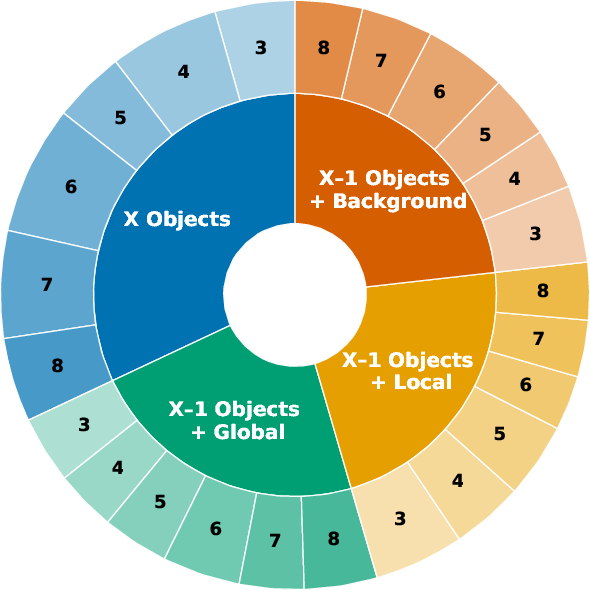
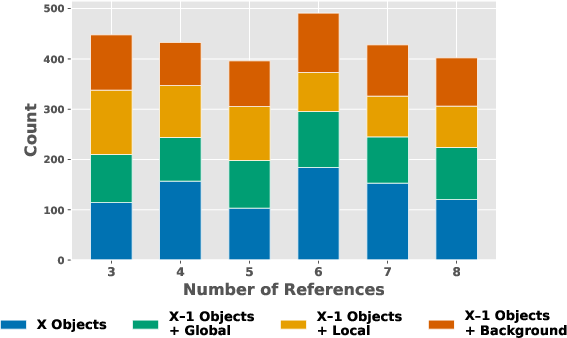
Figure 3: Balanced task breakdown, editing set distribution by reference count, and prompt diversity word cloud.
Task Taxonomy and Evaluation Criteria
MultiBanana operationalizes three core task settings:
- Single-reference editing: Classic instruction-following image editing, preserving semantic/visual identity.
- Two-reference compositional editing (11 types): Includes subject addition/replacement, background change, pose/hair/makeup/style modification, color/material/tone transfer, and text correction.
- Multi-reference generation (3–8 inputs; 48 types): Requires compositional reasoning, integrating consistency, diversity, and relational structure among heterogeneous references.
Diversity axes under evaluation include cross-domain (e.g., photo/anime), scale/viewpoint mismatches, rare concept references, and multilingual rendering. These explicit difficulty combinations—cross-domain, rare concept, scale/view, multilingual—are represented at substantial scale (e.g., 28% cross-domain, 20% rare concept).
Experimental Protocol
MultiBanana employs both closed-source models (Nano Banana, GPT-Image-1) and leading open-source models (Qwen-Image-Edit-2509, DreamOmni2, OmniGen2) for evaluation. All model outputs are rated on five independent criteria:
- Instruction Alignment
- Reference Consistency
- Background-Subject Match
- Physical Realism
- Visual Quality
Scoring uses VLM judgers (Gemini-2.5 and GPT-5), revealing robust inter-rater reliability.
Quantitative Results and Analysis
Performance in MultiBanana exposes significant gaps not visible in saturated editing and multi-reference benchmarks. Closed-source models demonstrate superior instruction adherence and reference integration but suffer compounded compositional failures as reference count increases—visual overcrowding and inconsistencies. Open-source models, while maintaining background and realism quality, generally ignore multiple subjects in high-ref contexts and show degraded alignment and consistency scores. Critically, background replacement remains the hardest for all models.

Figure 4: Score decrement trends across evaluation criteria when increasing the number of reference images (open/closed-source models).

Figure 5: Failure cases in cross-domain/scale/rare/multilingual reference scenarios and open-source multi-reference collapse.
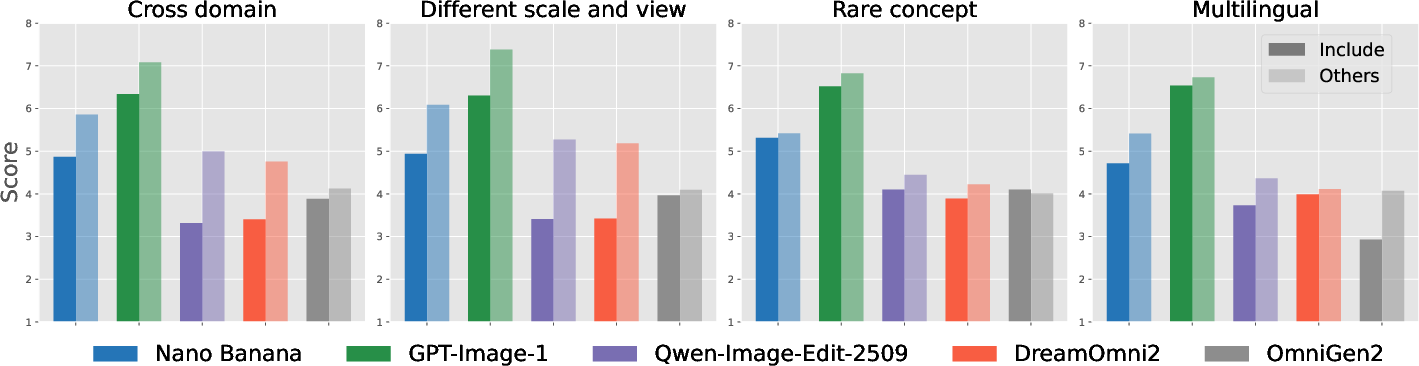
Figure 6: Results for difficult reference compositions—cross-domain, scale/view mismatch, rare concept, multilingual are salient model bottlenecks.
Agentic inference—Iterative Prompt Refinement (IPR), Context-Aware Feedback Generation (CAFG), Selective Reference Adaptation (SRA)—provides marginal improvements (particularly for GPT-Image-1) but can induce information loss and prompt drift in Gemini-driven pipelines, revealing additional challenges in multi-step prompt adaptation for context-rich compositional scenes.
Qualitative and Difficulty Analysis
MultiBanana tasks incorporating cross-domain or scale/viewpoint diversity consistently reduce reference consistency and physical realism, as models either forcibly unify styles (domain collapse) or fail to match detail/pose. Rare concepts induce scale distortions and realism violations; multilingual rendering exposes persistent weaknesses outside English.
Implications and Future Directions
MultiBanana advances the frontier of benchmark-driven evaluation in multi-reference text-to-image synthesis. By explicitly targeting compositionality, relational reasoning, cross-domain and multilingual generalization, and large-n reference integration, the benchmark reveals strengths and unaddressed weaknesses in both closed and open model families—especially critical failure modes as reference count and task complexity scale. Results suggest that agentic iterative planning provides limited mitigation, indicating unmet algorithmic needs for hierarchical scene composition, adaptive reference weighting, and language-to-image transfers beyond monolingual contexts.
Empirical saturation in prior benchmarks (ImgEdit, DreamOmni2) underscores MultiBanana's necessity—state-of-the-art models score near the ceiling in legacy datasets yet struggle on this new benchmark's diversity and difficulty axes.
Conclusion
MultiBanana provides a comprehensive and challenging foundation for evaluation and further research in multi-reference-driven text-to-image generation. It exposes nuanced failure modes—prompt/subject omission, compositional collapse, and weak cross-domain or multi-language fidelity—while supporting agentic protocol investigation. This dataset will drive progress in scalable compositionality, reference integration, and instruction alignment for multimodal generative systems.
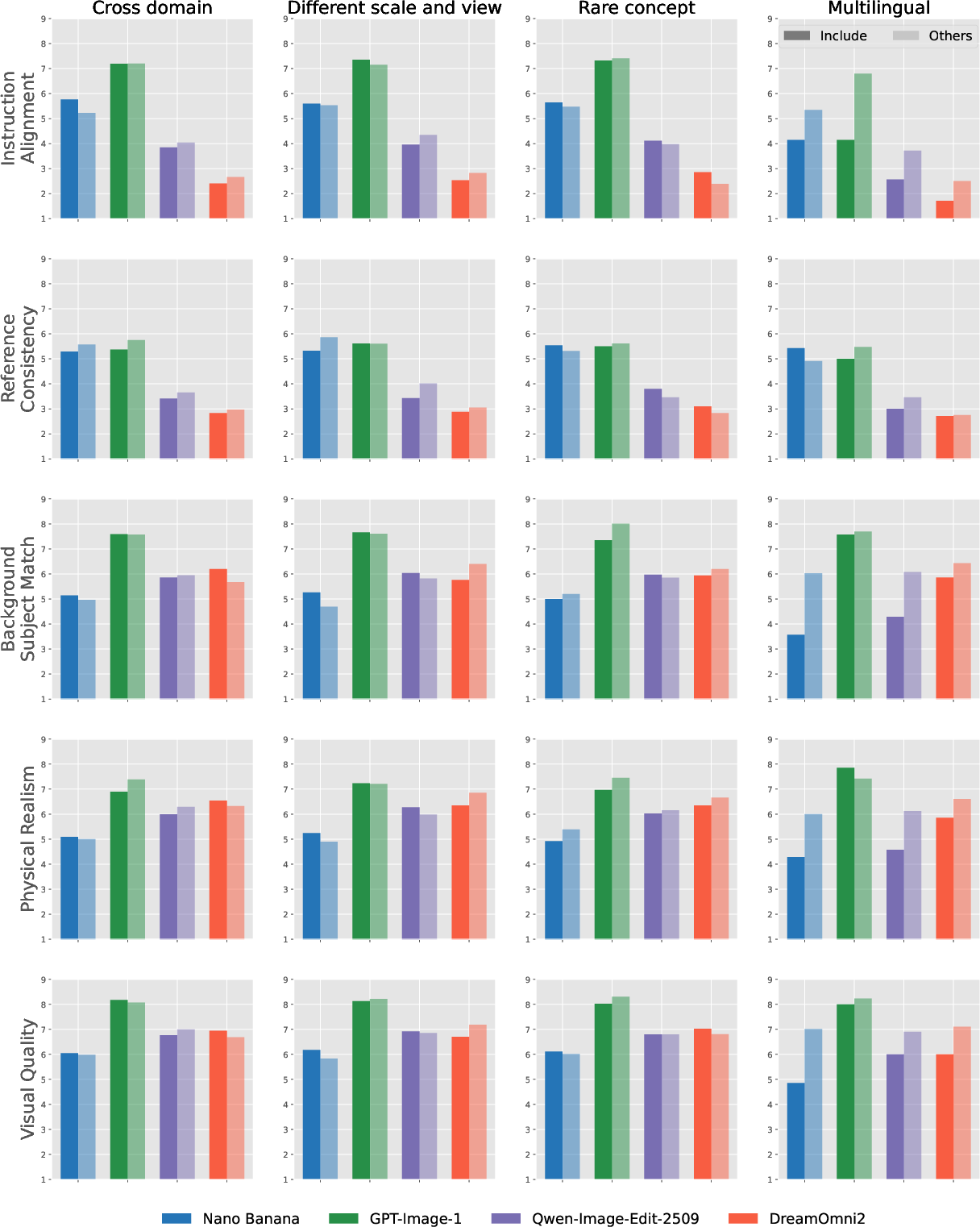
Figure 7: Overall scores for difficult reference combinations, highlighting systematic challenges by category and model.