- The paper introduces a novel compilation pipeline that profiles skill capabilities and transforms static prompts into efficient code artifacts.
- It employs an AOT compiler and adaptive JIT optimizer to achieve up to 50× latency reductions and a 15.3% improvement in task completion rates.
- The system enhances reliability by preempting environment mismatches and exploiting latent concurrency through explicit dependency and parallelism extraction.
SkVM: Compiling Skills for Efficient Execution Across Heterogeneous LLM Agents
Introduction and Motivation
The proliferation of skill-based composition in LLM agents has led to an ever-expanding ecosystem of reusable, natural language "skills" designed to augment agents' capabilities across tasks from data analysis to office automation. Despite the promise of modularity and portability, present approaches treat skills as static context appended to agent prompts, yielding inconsistent performance across models and harnesses. Analytical evidence, as demonstrated through largescale ecosystem studies, reveals that over 15% of skills introduce performance degradation and up to 87% provide no improvement for certain tasks or models, exposing intrinsic flaws in skill portability and execution efficiency.
The authors attribute this to fundamental mismatches along three axes: (1) skill assumption vs. model capability (model mismatch), (2) skill assumption vs. agent harness affordances (harness mismatch), and (3) skill assumption vs. user execution environment (environment mismatch). These misalignments are manifested by large and uneven skill distributions (Figure 1), environment dependency failures (Figure 2), and highly variant task scores across model/harness pairs (Figure 3). The observed landscape calls for systematic, cross-layer solutions that draw on the lessons of classical software compilation and runtime systems.
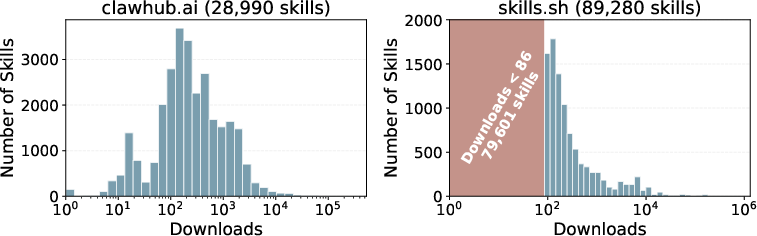
Figure 1: Skill download distribution follows a long-tailed pattern, with a small fraction of skills experiencing majority usage.
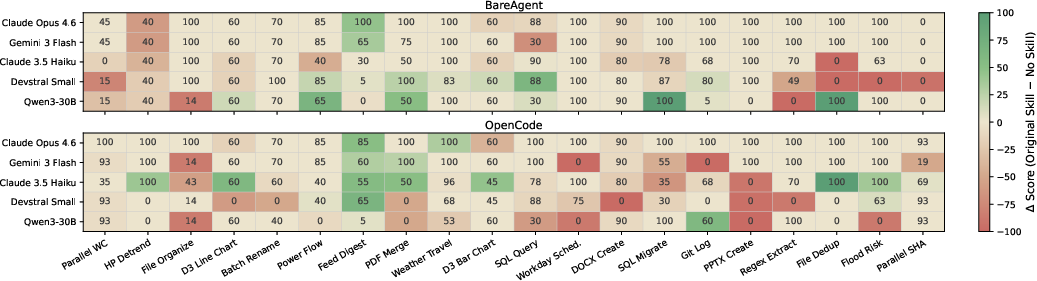
Figure 3: Heatmap elucidates the significant effect of both model identity and harness choice on skill effectiveness across tasks.
SkVM System Architecture
SkVM addresses these cross-axis mismatches by conceptualizing skills as code units and LLMs/harnesses as heterogeneous execution backends, motivating an explicit compile-time/runtime separation inspired by programming language theory. Its architecture comprises an AOT (Ahead-Of-Time) compiler and an adaptive JIT (Just-In-Time) runtime optimizer (Figure 4). Skills undergo a three-stage compilation:
- Capability-Based Compilation: Skill requirements are decomposed into a set of 26 primitive capabilities, each stratified by proficiency level. The compiler extracts the capability demands from the skill and profiles the target (model+harness) via microbenchmarks to assess proficiency, selecting appropriate compensation or substitution transforms to close the identified gap (Figure 5).
- Environment Binding: Explicit extraction and configuration of tool/package dependencies, generating environment binding scripts to preempt runtime resolution errors.
- Concurrency Extraction: Skill workflows are analyzed for latent data-level (DLP), instruction-level (ILP), and thread-level parallelism (TLP), which are surfaced via workflow DAGs and mapped to concurrency primitives supported by the harness (Figure 6).
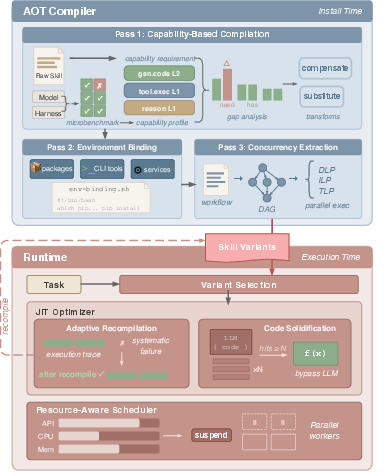
Figure 4: Architectural overview of SkVM featuring AOT skill compilation and runtime optimization.
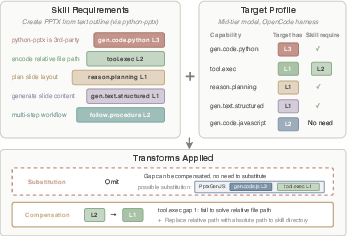
Figure 5: An exemplar capability-based compilation illustrating extraction, profiling, and transform based on capability gap.
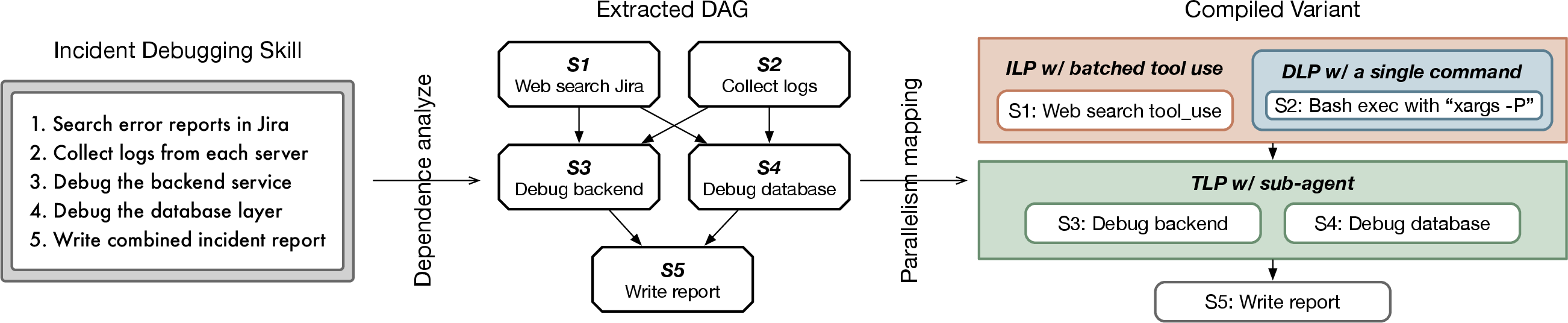
Figure 6: Workflow DAGs and concurrency extraction reveal latent parallelism within skill procedural structure.
JIT Optimization and Runtime Adaptivity
At runtime, SkVM utilizes two major complementary optimizations.
Code Solidification: The system identifies code fragments in skills with stable structure (parameterized templates). Through multi-phase monitoring (AOT prediction, runtime validation, template promotion), repeated LLM inference is supplanted by directly executable code, yielding substantial speedups (Figure 7, Figure 8).
Adaptive Recompilation: The runtime tracks execution outcomes and failure traces, enabling skill recompilation on persistent, systematic failures—iterating toward improved alignment with the underlying model's actual behaviors.
Resource-Aware Scheduling: Parallel execution opportunities extracted during compilation are dynamically throttled, suspended, or prioritized based on observed system and API resource constraints.

Figure 7: The code solidification pipeline showing identification, validation, and promotion of code segments to bypass the LLM.

Figure 8: Drastic reduction in LLM inference latency post-solidification; safety mechanisms avoid template promotion when predictions misalign.
Empirical Evaluation
Comprehensive experiments are conducted across eight diverse LLMs (ranging from small to SOTA), three agent harnesses, and 118 benchmark tasks.
Task Completion and Regression: SkVM-optimized skills consistently yield higher task completion rates than baseline or skill-creator enhanced variants, averaging 15.3% improvement. Particularly, weaker models benefit more dramatically from SkVM, as compilation refines primitive capability alignment. Regression rates are also reduced from 15% (baseline) to 4.5% (SkVM) (Figure 9, Figure 10).
Token and Latency Efficiency: On most model/harness pairs, SkVM achieves both improved task success rates and up to 40% reduction in token consumption. When coupled with code solidification and parallelization strategies, SkVM demonstrates 3.2× speedups via TLP and up to 50× latency reduction for repeatable code paths (Figure 11, Figure 12, Figure 13).
Environment Binding and Profiling Overhead: SkVM preempts environment-related failures and redundant agent loops via explicit dependency binding, restoring correctness, minimizing wasted tokens, and matching the completeness of properly provisioned environments (Figure 14). The cost and duration of initial capability profiling is negligible compared to runtime efficiency gains (Figure 15).
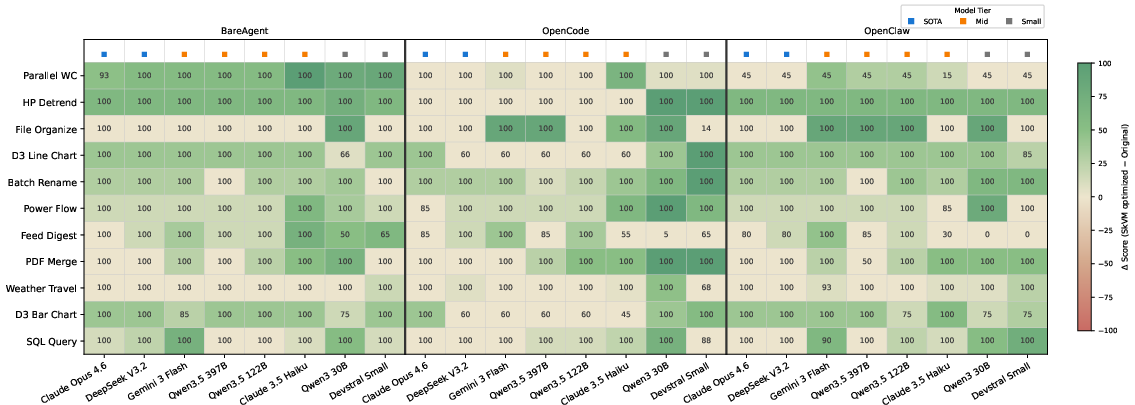
Figure 9: Task completion rate improvements with SkVM, visualized as gains over baseline and highlighted per-task.
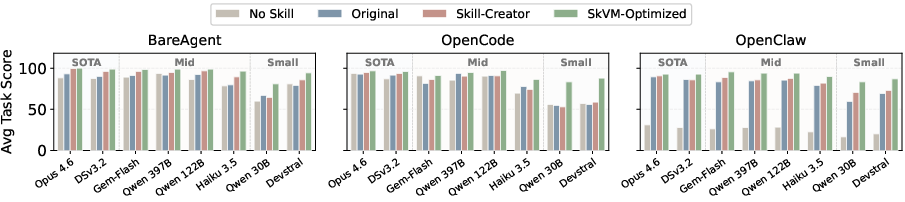
Figure 10: Average task scores by skill variant; SkVM-Optimized yields the highest across all model–harness combinations.
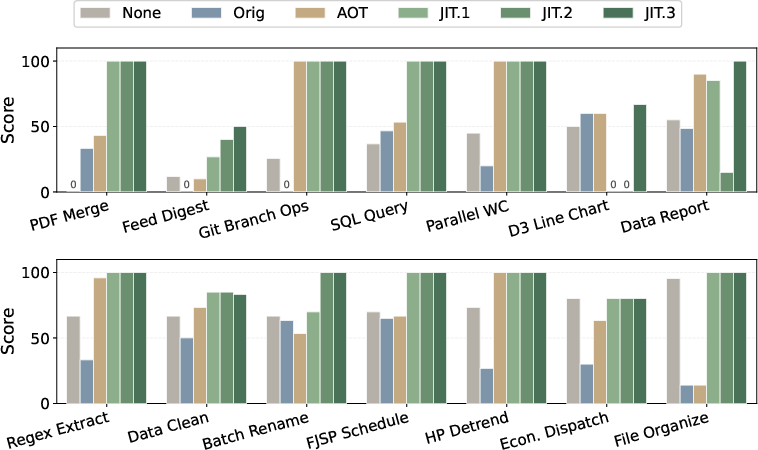
Figure 12: Staged breakdown reveals the cumulative effects of AOT and iterative JIT rounds across skill categories.
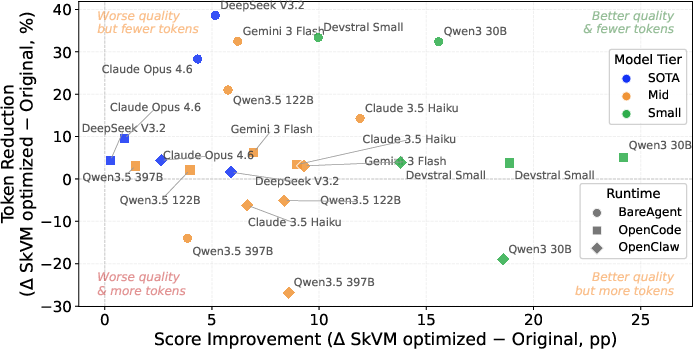
Figure 11: Most model–harness pairs attain both higher score and lower token count post-optimization.
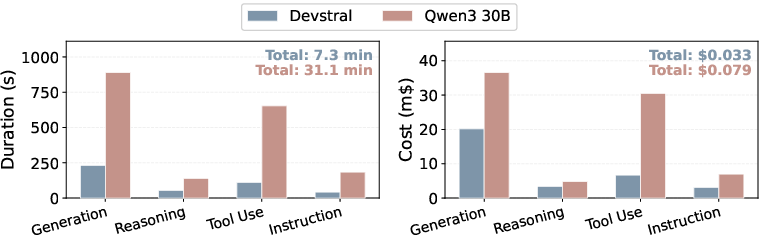
Figure 15: Capability profiling incurs moderate, one-time overhead in both duration and financial terms.
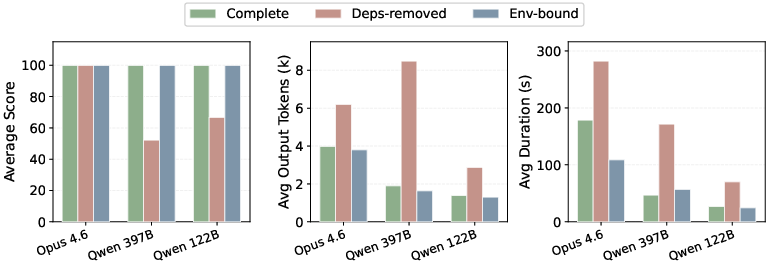
Figure 14: Environment binding restores correctness, efficiency, and speed to levels seen in fully provisioned settings.
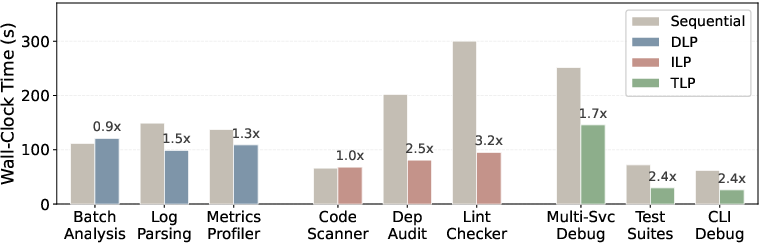
Figure 13: Quantitative speedup of DLP, ILP, and TLP parallelization across selected tasks.
Discussion and Implications
SkVM's approach clarifies the importance of treating skills as compilable artifacts rather than static prompts, enabling a rigorous cross-stack optimization process. Several points merit reflection:
- Non-determinism and Safety: While natural language skills introduce nondeterminism absent from traditional programs, SkVM manages this via layered compilation, validation gates, and rollback mechanisms, maintaining operational reliability.
- Scalability and Evolvability: The iterative capability profiling and skill transformation framework is designed to accommodate expanding primitive capability sets as the ecosystem grows.
- Amortized Overhead: Compilation and profiling costs are amortized over frequent skill re-use. Additionally, compiled skills can be shared across users, further diminishing per-use costs.
Future directions may include refinement of capability abstractions, automated derivation of new transforms, and tighter harness integration for fine-grained scheduling. As LLMs and agent frameworks continue to diversify, the explicit compilation and runtime optimization paradigm established by SkVM is likely to become foundational for robust, portable agent ecosystems.
Conclusion
SkVM introduces a principled compiler-runtime system for transforming fragile, static skills into portable, high-efficiency code artifacts consumable by heterogeneous LLM agents. By bridging capability, environment, and concurrency mismatches through a classical yet deeply modern compilation pipeline, SkVM sets a template for systematic skill portability and efficiency. The empirical gains in completion, efficiency, and predictability across models and platforms substantiate the benefits of this approach, positioning skill compilation as a critical methodological advance for scalable, robust agent development.
Reference: "SkVM: Compiling Skills for Efficient Execution Everywhere" (2604.03088)