SkillOrchestra: Learning to Route Agents via Skill Transfer
Abstract: Compound AI systems promise capabilities beyond those of individual models, yet their success depends critically on effective orchestration. Existing routing approaches face two limitations: (1) input-level routers make coarse query-level decisions that ignore evolving task requirements; (2) RL-trained orchestrators are expensive to adapt and often suffer from routing collapse, repeatedly invoking one strong but costly option in multi-turn scenarios. We introduce SkillOrchestra, a framework for skill-aware orchestration. Instead of directly learning a routing policy end-to-end, SkillOrchestra learns fine-grained skills from execution experience and models agent-specific competence and cost under those skills. At deployment, the orchestrator infers the skill demands of the current interaction and selects agents that best satisfy them under an explicit performance-cost trade-off. Extensive experiments across ten benchmarks demonstrate that SkillOrchestra outperforms SoTA RL-based orchestrators by up to 22.5% with 700x and 300x learning cost reduction compared to Router-R1 and ToolOrchestra, respectively. These results show that explicit skill modeling enables scalable, interpretable, and sample-efficient orchestration, offering a principled alternative to data-intensive RL-based approaches. The code is available at: https://github.com/jiayuww/SkillOrchestra.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SkillOrchestra, a new way to run complex AI systems that use many models and tools together. Instead of relying on one big model to do everything, SkillOrchestra acts like a smart conductor that chooses the right “musician” (AI agent) for each part of a task based on the specific skills needed and the cost. The goal is to make AI systems more accurate, cheaper, and easier to manage.
What questions does it try to answer?
To make the idea clear, here are the main questions the paper explores:
- How can we choose the best AI model or tool at each step of a multi-step task, instead of making one big decision at the start?
- Can we avoid the common problem where a router keeps picking the strongest (but most expensive) model over and over, even when a lighter model would do just fine?
- Is there a way to plan AI decisions using “skills” (like searching the web, solving math, or writing code) so that choices are more reliable, cheaper, and reusable?
- Can we build a reusable “Skill Handbook” that helps different orchestrator models make better decisions without retraining?
How did they do it?
Think of an AI system like a sports team or an orchestra:
- Different players (or musicians) have different strengths.
- The coach (or conductor) shouldn’t just pick the star player every time—it should choose the person with the right skill for the moment.
- Also, you need to keep track of how good each player is at specific skills, what it costs to use them, and when each skill matters.
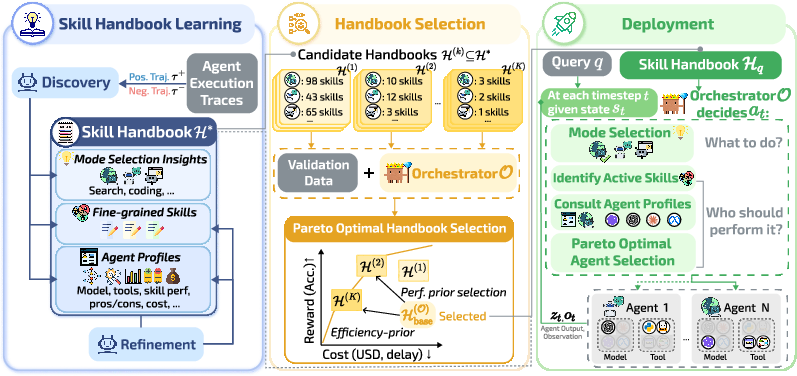
SkillOrchestra works in three simple steps:
1) Build a Skill Handbook
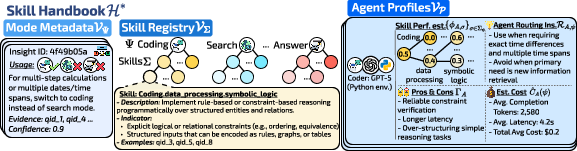
The Skill Handbook is a reusable guide that contains three parts:
- Mode-level insights: Tips on when to use a mode like “Search,” “Code,” or “Answer.”
- Skills: Fine-grained abilities (for example, “symbolic logic,” “data processing,” “high-precision math,” “multi-hop fact linking”).
- Agent profiles: For each agent (a model plus its allowed tools), estimates of how likely it is to succeed on each skill and how much it costs (like tokens or time).
How it’s built (in everyday terms):
- The system runs sample tasks using different agents.
- When one attempt succeeds and another fails, it asks: “What skill was missing?” Then it records that skill in the handbook.
- Over time, it keeps refining the skill list—splitting vague skills into clearer ones or merging duplicates—so the handbook stays clean and useful.
- It also tracks how different agents perform on each skill and how expensive they are to use.
2) Pick the right handbook version for your orchestrator
Not all orchestrators (the “conductor” model) are equally smart or detailed. A very fine-grained skill list might confuse a smaller orchestrator. So SkillOrchestra selects the best level of skill detail for the target orchestrator using validation, aiming for the best accuracy at the lowest cost (this is called choosing a point on the “Pareto frontier,” where you can’t get better accuracy without paying more cost, or vice versa).
3) Use the handbook during a task
When solving a multi-step problem:
- The orchestrator first chooses the mode (e.g., Search vs. Code) based on the handbook’s guidance.
- Then it identifies which skill is needed right now.
- Finally, it picks the agent that’s best for that skill and balances performance vs. cost.
In short: at each step, the system asks “what skill do we need?” and “who’s best at that skill for a reasonable price?”
Helpful analogies for key terms
- Orchestration: The conductor deciding who plays next and what they play.
- Agent: A model plus tools (like a coder model with Python access or a general model with web search).
- Mode: The type of action (Search, Code, Answer)—like switching from strings to percussion in an orchestra.
- Skill: A specific ability needed right now (like “multi-hop reasoning” or “precision arithmetic”).
- Reinforcement learning (RL): Teaching by trial-and-error with rewards for good outcomes.
- Routing collapse: When the router keeps picking the same powerful model every time, even when it’s wasteful.
- Pareto frontier: The set of “best trade-offs” where improving accuracy would raise cost, and lowering cost would reduce accuracy.
What did they find, and why is it important?
Here are the main results, explained simply:
- Better accuracy at lower cost:
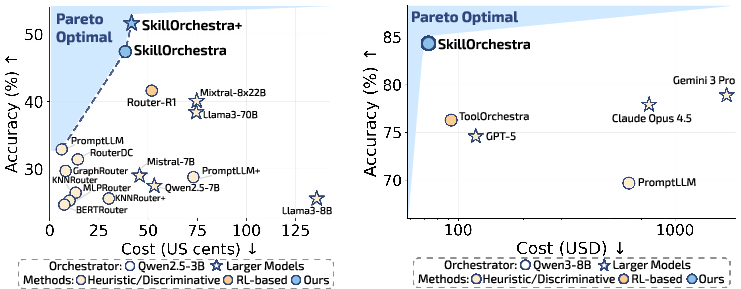
- SkillOrchestra beat strong RL-based systems by up to 22.5 percentage points in accuracy on tough benchmarks.
- It also ran cheaper, often cutting total cost by around 2× in math tasks and significantly reducing costs in QA and full agent orchestration scenarios.
- Avoids routing collapse:
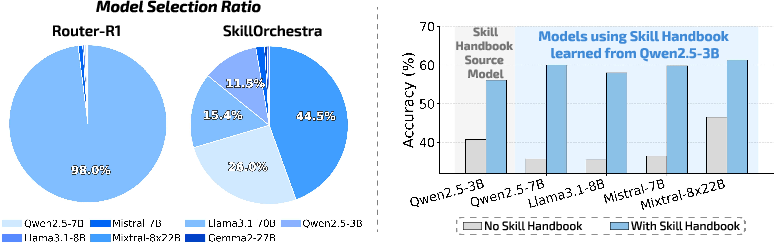
- RL routers tended to call one massive model almost all the time (over 98% of the time in tests), which is very expensive and wastes specialized models.
- SkillOrchestra spread calls across models based on the skills needed, using big models only when necessary and relying on lighter models for simpler steps.
- Much cheaper to train:
- Compared to RL systems like Router-R1 and ToolOrchestra, SkillOrchestra reduced learning (training) costs by roughly 700× and 300×, respectively, because it learns a reusable handbook from execution traces instead of doing heavy end-to-end RL.
- Transfers across orchestrators:
- The same Skill Handbook worked with different orchestrator backbones (small or large models) without retraining and consistently improved performance, especially with stronger orchestrators.
- Works beyond model selection:
- SkillOrchestra also boosts full agent orchestration (multiple modes and tools: Search, Code, Answer). It reached the highest accuracy while keeping costs lowest among strong baselines, including RL-tuned systems and proprietary models.
- More skills aren’t always better:
- The best results came from discovering skills, refining them (splitting/merging), and selecting the right granularity for the orchestrator. Too fine-grained can confuse weaker orchestrators; too coarse can reduce precision.
Why this matters: It shows that organizing AI decisions around skills—rather than blindly “training the router harder”—can be more accurate, more stable, cheaper, and easier to reuse.
What’s the bigger impact?
If adopted widely, SkillOrchestra could:
- Make complex AI systems smarter and cheaper by choosing the right agent at the right time.
- Reduce wasteful spending on big models when smaller ones would do.
- Provide interpretable, reusable orchestration knowledge (the Skill Handbook) that can be shared, updated, and transferred as model pools change.
- Cut down on data-hungry RL training, making deployment faster and more practical.
- Help future AI systems handle complex, multi-step tasks (like research and scientific discovery) in a more reliable, skill-aware way.
In short: SkillOrchestra is like giving AI a playbook of skills and a coach who knows which player to send in. It leads to smarter choices, lower costs, and better teamwork among models and tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces SkillOrchestra and reports promising results, but several aspects remain missing, uncertain, or unexplored. Future work could address the following gaps:
- Skill discovery reliability and reproducibility: The LLM-based “discoverer/reflector” that defines and refines skills is heuristic and underspecified. How stable are discovered skills across runs, LLMs, seeds, and datasets, and how much human oversight is required to ensure consistent taxonomies?
- Determining active skills at runtime: The method states that the orchestrator “identifies a set of relevant skills” and uses “indicators” and nearest-neighbor retrieval, but provides no concrete algorithm or evaluation of detection accuracy. What is the precision/recall of skill activation, and how sensitive is routing to misidentified skills?
- Skill granularity selection mechanisms: Pareto validation is used to pick skill granularity, yet the procedure risks overfitting to the validation set and choices. How robust is this selection across domains, budgets, and orchestrator capacities, and can it adapt online as conditions change?
- Agent competence modeling assumptions: Success probabilities are estimated independently per skill with Beta-Bernoulli updates. This ignores correlations between skills, context dependencies, and non-stationarity (e.g., model updates, prompt changes). Can competence be modeled with hierarchical, contextual, or drift-aware methods with uncertainty calibration?
- Exploration vs. exploitation and uncertainty use: Routing uses posterior means but no explicit treatment of uncertainty for decision-making. How should the system balance exploration of under-observed agents/skills and robust exploitation, especially in cold-start or shifting environments?
- Mode selection learning and termination: The paper avoids RL but does not specify how mode policies are learned, updated, or when to stop (e.g., when to switch from search to code or to terminate). What learning signals or algorithms (supervised, bandit, imitation) are used for mode transitions and horizon control?
- Skill compositionality and interactions: The aggregator uses a weighted average over skills, assuming additivity. How to handle interactions (synergy/conflict
Glossary
- Agent instantiation: Formal definition of how an agent is constructed from a model and a subset of tools. "An agent is defined as a pair A = (m, \mathcal{T}_A), \quad m \in \mathcal{M}, \; \mathcal{T}_A \subseteq \mathcal{T},"
- Agent orchestration: Coordinating multiple models and tools across modes to accomplish a task. "We next evaluate whether SkillOrchestra extends beyond model routing to full agent orchestration, where the system must coordinate multiple operational modes and tools beyond model selection."
- Agent profile: A summary of an agent’s competence and cost characteristics conditioned on skills and modes. "An agent profile summarizes an agent’s mode-conditioned competence, cost, and routing characteristics for skill-aware orchestration."
- Agentic task environment: A setting where agents perform multi-step reasoning in response to a query. "We consider an agentic task environment where a user instruction initiates a multi-step reasoning process."
- Beta distribution: A probabilistic model used to estimate success probabilities for agent-skill pairs. "we model success probability as "
- Cascade strategies: Heuristic routing methods that escalate queries based on difficulty or budget. "Early approaches rely on heuristic or cascade strategies~\citep{chen2024frugalgpt} that escalate queries based on predicted difficulty or budget constraints"
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning from LLMs. "CoT~\citep{wei2022chain}"
- Competence-aware agent routing: Selecting agents based on estimated skill competence and cost under the current mode. "Competence-Aware Agent Routing. Conditioned on the selected mode , the orchestrator identifies a set of relevant skills "
- End-to-end: Training or optimizing a routing policy directly as a single process. "enables data-efficient, transferable, and more balanced orchestration without end-to-end RL training."
- Execution trace: The outputs produced by an agent’s operation at a turn (e.g., search results, code). "The selected agent produces an execution trace (e.g., search results or generated code),"
- Foundation models: Large pretrained models serving as backbones for agents. "A set of candidate foundation models ,"
- GRPO: A reinforcement learning algorithm used to finetune orchestrators. "Prior work typically instantiates this optimization via RL such as GRPO~\citep{shao2024deepseekmath}"
- GraphRouter: A graph-based model routing approach. "GraphRouter~\citep{feng2025graphrouter}"
- KNN Router: A similarity-based routing method using nearest neighbors. "KNN Router~\citep{hu2024routerbench}"
- Latency: Time delay used as part of execution cost modeling. "the estimated execution cost (e.g., latency, token usage) under mode "
- Mode policy: The policy that selects the operational mode at each turn. "The mode policy $\pi_{\text{mode}$ selects the current operational mode based on the interaction state "
- Mode–skill index: A mapping from modes to associated skills used to constrain routing. "Mode--skill index . The graph structure induces a mapping "
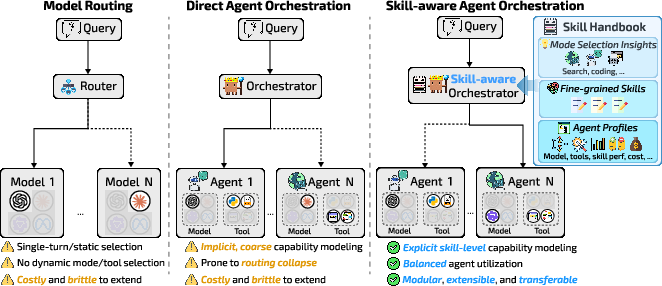
- Model routing: Selecting a model from a pool to answer a query, often in single-shot settings. "A common form of orchestration is model routing, where a controller selects a model from a model pool"
- Multi-hop QA: Question answering tasks requiring reasoning across multiple pieces of information. "Multi-hop QA: HotpotQA~\citep{yang2018hotpotqa}, 2WikiMultiHopQA~\citep{ho-etal-2020-constructing}, Musique~\citep{trivedi-etal-2022-musique}, and Bamboogle~\citep{press-etal-2023-measuring}"
- Multi-turn interactions: Dialogues or workflows involving multiple sequential turns. "This assumption breaks down in multi-turn interactions, where different states require distinct capabilities."
- Operational modes: Abstract action types (e.g., search, code) defining allowed tools and operations. "Operational Modes (). A set of abstract action modes defined at the capability level."
- Orchestrator: The controller that plans and allocates resources across agents and modes. "The Orchestrator (): A central controller responsible for high-level planning and resource allocation."
- Orchestrator-specific subset: A tailored selection of handbook content matched to an orchestrator’s capacity. "we therefore select an orchestrator-specific subset for orchestrator via Pareto-optimal validation"
- Pareto frontier: The set of solutions that optimally trade off performance and cost. "SkillOrchestra and SkillOrchestra+ lie on the Pareto frontier, achieving higher accuracy at lower cost than all baselines."
- Pareto-optimal validation: Validation procedure to choose handbook subsets that optimize accuracy–cost trade-offs. "we therefore select an orchestrator-specific subset ... via Pareto-optimal validation"
- Policy factorization: Decomposing the overall policy into mode selection and routing components. "We factorize the policy as $\pi(a_t \mid s_t) = \pi_{\text{mode}(\psi_t \mid s_t)\cdot \pi_{\text{route}(A_t \mid s_t, \psi_t),$"
- Posterior mean: The mean of the posterior distribution used to aggregate competence estimates. "aggregating the posterior means over the active skill set"
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm used to train routing policies. "Router-R1~\citep{zhang2025routerr}, a strong PPO-trained~\citep{schulman2017proximal} multi-turn router"
- RAG (Retrieval-Augmented Generation): A method that augments generation with retrieved information. "RAG as in~\citet{zhang2025routerr}"
- Reinforcement learning (RL): Framework for learning sequential decision policies via rewards. "Recent RL-based orchestration methods~\citep{zhang2025routerr,toolorchestra} address this by learning sequential routing policies with LLMs."
- Routing collapse: Degeneration of a routing policy to repeatedly select a single option despite alternatives. "routing collapse: the degeneration of the orchestration policy into repeatedly selecting a single option at one or more decision levels"
- Semantic alignment: Matching the current state’s semantics to agent profiles during routing. "optionally incorporating semantic alignment between the current state and the agent profile"
- Skill Handbook: A reusable knowledge base of skills, mode insights, and agent profiles guiding orchestration. "we learn a Skill Handbook , a reusable experience base that captures (i) mode-level execution insights ... (ii) fine-grained skills ... (iii) agent profiles ..."
- Skill-aware orchestration: Orchestration paradigm that reasons over explicit skills rather than direct policy optimization. "we introduce SkillOrchestra, a framework for skill-aware orchestration."
- Skill registry: The catalog of discovered skills organized within the handbook. "The handbook maintains a registry of skills (Definition~\ref{def:skill}),"
- State-conditioned: Decisions that depend on the current interaction state rather than just input-level features. "First, it enables state-conditioned, fine-grained orchestration, allowing different models to specialize across capabilities."
- Success probability: The probability an agent succeeds on a given skill, modeled probabilistically. "we model success probability as "
- Trajectory: The sequence of states, actions, traces, and observations over turns. "This interaction induces a trajectory ."
- Trajectory-level rewards: Rewards computed over entire execution trajectories to optimize accuracy–cost. "optimizing performance-cost trade-offs via trajectory-level rewards."
- Tradeoff hyperparameter: A scalar λ weighting performance against cost in the objective. " is a tradeoff hyperparameter."
- Tool pool: The set of executable tools available to agents within the environment. "Tool Pool (). A set of executable tools $\mathcal{T} = { t_1, \dots, t_{K_T} },"
Practical Applications
Immediate Applications
The following applications can be deployed with current technology and workflows using the paper’s SkillOrchestra framework, Skill Handbook, and Pareto-optimal selection strategy.
- Cost-aware LLM gateways for enterprise model routing (Software, Finance)
- Use case: Deploy SkillOrchestra to dynamically route queries across a pool of LLMs, balancing accuracy and per-token cost to avoid routing collapse (e.g., always choosing the largest model).
- Tools/products/workflows: “Skill Handbook Builder” from production logs; routing SDK for LangChain/LangGraph/AutoGen; dashboards showing Pareto trade-offs; policy controls to enforce budgets.
- Assumptions/dependencies: Access to multiple models with cost telemetry; collection of execution traces; reliable success/failure signals per task.
- Multi-turn customer support assistants with balanced model/tool use (Industry: Customer Service, CRM)
- Use case: Route among modes like retrieve (RAG/CRM search), analyze (sentiment/classification), and answer, invoking higher-cost models only when skill demands warrant it.
- Tools/products/workflows: CRM connectors, knowledge base search, ticketing systems; skill-grounded orchestration policies; audit trails via skill descriptions.
- Assumptions/dependencies: Accurate mapping of support intents to skills; secure integrations with customer data; tool availability (search, summarization).
- Software engineering copilots with competence-aware escalations (Software)
- Use case: In IDEs/CI, select coding, debugging, or test-generation modes; route to specialized coding LLMs or run test suites, escalating to a stronger model only on complex skills (e.g., symbolic logic or refactoring).
- Tools/products/workflows: Orchestration in VS Code/JetBrains; Python/containers for execution; competence estimates per coding subskill.
- Assumptions/dependencies: Code execution sandbox; skill registry aligned to code tasks; access to code-specialist models.
- Data analytics assistants that orchestrate SQL, visualization, and narrative synthesis (Software, Enterprise Analytics)
- Use case: Decompose tasks into query building, data cleaning, visualization, and summarization; route to DB tools and appropriate models with explicit cost-performance trade-offs.
- Tools/products/workflows: DB connectors, BI tools; mode/skill-aware routing; governance for data access.
- Assumptions/dependencies: Stable mapping from analytics tasks to skills; role-based access control; telemetry on query success.
- Content moderation and review pipelines with selective deep reasoning (Media/Trust & Safety)
- Use case: Apply fast classifiers for clear cases; invoke high-precision reasoning models only for borderline content (e.g., nuanced policy violations).
- Tools/products/workflows: Moderation APIs, policy skill registry; agent profiles capturing false-positive/false-negative tendencies.
- Assumptions/dependencies: Label definitions and skills aligned with policy; legal/compliance review of routing logic.
- Legal document analysis with mode-aware agent orchestration (LegalTech)
- Use case: Flow through retrieve clauses, structure extraction, risk assessment, and synthesis steps; choose agents based on competence in specific skills (e.g., clause similarity, obligation extraction).
- Tools/products/workflows: Document search, clause extraction tools; orchestration of summarization vs. analysis models; audit-ready skill definitions.
- Assumptions/dependencies: Reliable ground truth or heuristics for success; confidentiality controls; stable skill ontology for legal tasks.
- Scientific and literature research assistants (Academia, Pharma R&D)
- Use case: Multi-step research tasks: search → screening → synthesis → hypothesis refinement; route to coding (e.g., simple simulations), structured extraction, and summarization agents based on skill demands.
- Tools/products/workflows: PubMed/semantic search APIs; Python notebooks; skill registry for evidence grading.
- Assumptions/dependencies: Integration with scholarly databases; evaluation metrics per skill; responsible use of external tools and data.
- Education tutoring agents with domain-specific skill routing (Education)
- Use case: Distinguish between math reasoning, code execution (checking solutions), and reading comprehension; route to specialized agents per skill with cost controls for student usage.
- Tools/products/workflows: Classroom LMS integration; sandboxed code runners; math/domain skill profiles.
- Assumptions/dependencies: Accurate skill detection at student query level; fairness and accessibility considerations.
- Incident response copilots for DevOps (Software/IT Ops)
- Use case: Triage logs, retrieve runbooks, propose commands, and execute diagnostics; use cheaper models for routine checks and escalate when symbolic reasoning or complex coding is required.
- Tools/products/workflows: Log ingestion, runbook search; shell/infra APIs; Pareto validation to tune granularity for the orchestrator.
- Assumptions/dependencies: Safe command execution; robust detection of active skills; token cost visibility across tools.
- Governance and auditing of AI orchestration decisions (Policy, Risk & Compliance)
- Use case: Replace opaque RL routers with interpretable, skill-grounded handbooks; enable auditors to trace why modes and agents were selected under explicit trade-offs.
- Tools/products/workflows: Handbook versioning; compliance dashboards; policy constraints on routing (e.g., data locality).
- Assumptions/dependencies: Stable skill definitions; logs of mode/agent choices; data privacy and model vendor compliance.
- Procurement optimization for model/tool vendors (Finance, Public Sector)
- Use case: Use Pareto-optimal handbook selection to evaluate model pools; quantify performance-cost trade-offs before buying seats/tokens; enforce budget allocations via routing policies.
- Tools/products/workflows: Benchmarking harness; cost simulators; agent profile management.
- Assumptions/dependencies: Comparable metrics across vendors; reliable pricing and latency data; representative validation set.
- Personal productivity assistants with multi-mode orchestration (Daily Life)
- Use case: Plan tasks involving search, spreadsheet formulas, email drafting; invoke code execution for automation; select models by skill and price constraints to fit personal budgets.
- Tools/products/workflows: Calendar/email APIs; spreadsheet/automation tools; skill-aware routing on-device or via cloud.
- Assumptions/dependencies: Access to personal data with consent; small orchestrator capacity may require coarser skill granularity.
Long-Term Applications
These applications build on the paper’s innovations but require further research, scaling, standardization, or development to achieve robust deployment.
- Cross-domain skill registries and marketplaces (Software, Ecosystem)
- Vision: Standardized, shareable Skill Handbooks across organizations and frameworks; interoperable skill ontologies to plug-and-play agent pools.
- Dependencies: Community standards for skill schemas; security/privacy for shared traces; tooling for merging/splitting skills across domains.
- Safety-critical orchestration in healthcare workflows (Healthcare)
- Vision: Clinical documentation, coding (ICD/SNOMED), evidence retrieval, and synthesis with audited, skill-grounded routing; selective escalation to certified agents.
- Dependencies: Regulatory approval; rigorous validation datasets; robust uncertainty handling; HIPAA-compliant data flows.
- Autonomous scientific discovery agents (Academia, Pharma R&D)
- Vision: Orchestrate experiment design, simulation coding, data analysis, and literature reasoning; reuse handbooks across labs and domains.
- Dependencies: High-quality traces; domain-specific toolchains; advanced skill refinement for novel tasks; reproducibility infrastructure.
- Real-time robotics orchestration (Robotics)
- Vision: Route among perception, planning, control, and language explanation modes; balance compute, latency, and accuracy under skill demands.
- Dependencies: Hard real-time constraints; edge deployment; agent profiles with latency/energy costs; safety and verification.
- Grid and energy operations assistants (Energy)
- Vision: Skill-aware routing for forecasting, anomaly detection, optimization, and policy reporting; selective deep reasoning for contingencies.
- Dependencies: Integration with SCADA; domain-specific skill definitions; robust evaluation of success states; cybersecurity measures.
- Financial research and compliance copilots (Finance)
- Vision: Orchestrate data ingestion, risk modeling, backtesting, and narrative reporting; competence-aware routing for quantitative vs. textual tasks.
- Dependencies: Data governance; auditability; skill granularity tuned to model capacity; model/tool validation in regulated contexts.
- Dynamic price-aware procurement and model switching (Policy, Enterprise)
- Vision: Real-time orchestration that adapts to changing API pricing/latency/service levels; automatic Pareto re-selection of handbooks.
- Dependencies: Reliable provider telemetry; SLAs for routing changes; governance policies for dynamic switching.
- Automated skill refinement with meta-learning (Software/ML)
- Vision: Replace LLM reflectors with meta-learning agents that split/merge skills from outcomes; continuous learning pipelines.
- Dependencies: Stable training signals; avoidance of over-fragmentation; generalization guarantees; data-efficient updates.
- On-device and edge skill-aware orchestration (IoT, Mobile)
- Vision: Lightweight orchestrators with coarser skill granularity operating offline/low-latency; selective cloud escalation for hard skills.
- Dependencies: Efficient local models/tools; privacy-preserving traces; adaptive handbook selection for limited capacity.
- OS-level agent orchestration services (Platform)
- Vision: Native skill-aware routing integrated into operating systems/frameworks (e.g., “Agent OS”), standardizing modes and tool access across apps.
- Dependencies: Platform APIs; standardization of operational modes; security/capability isolation; developer tooling.
- Education platforms with individualized skill routing (Education)
- Vision: Longitudinal student models informing skill detection and routing; personalized budgets; transparent learning pathways.
- Dependencies: Reliable student skill assessment; fairness/ethics; integration with curricula; teacher oversight.
- Public-sector digital service orchestration (Policy, Government)
- Vision: Triage and process citizen requests with interpretable skill-based routing; enforce budget, fairness, and transparency mandates.
- Dependencies: Policy frameworks; audit infrastructure; multilingual skill definitions; robust failure handling.
Notes on Assumptions and Dependencies
Across applications, feasibility depends on:
- Access to multi-model pools and external tools; telemetry on cost (tokens/latency).
- Collection of execution traces to learn and refine the Skill Handbook; reliable success/failure labeling per skill/mode.
- Orchestrator capacity alignment with handbook granularity via Pareto-optimal selection; weaker orchestrators benefit from coarser skills.
- Data privacy, security, and regulatory compliance when routing across vendors/tools; audit trails enabled by skill-level explanations.
- Robustness of LLM-based skill discovery and refinement; potential need for domain experts or meta-learning to validate skills.
- Domain-specific evaluation metrics and governance to prevent harmful or biased routing decisions.
Collections
Sign up for free to add this paper to one or more collections.

