- The paper proposes a synthetic data generation pipeline that produces over 50,000 pixel-perfect geometry diagrams with precise spatial ground-truth masks.
- It adapts state-of-the-art vision-language models using LoRA adapters to reformulate segmentation as polygon-token sequences with buffered IoU evaluation.
- The study demonstrates significant improvements in segmentation accuracy, laying the foundation for integrated visual grounding in automated geometry education.
Procedural Generation and Visual Grounding for Artificial General Teachers in Geometry
Overview
This paper, "Toward an Artificial General Teacher: Procedural Geometry Data Generation and Visual Grounding with Vision-LLMs" (2604.02893), delineates a methodology to formalize the pedagogical act of visual "pointing" traditionally performed by human geometry teachers. By casting the task as Referring Image Segmentation (RIS)—generating pixel-level masks highlighting diagram elements described in natural language—the authors introduce a synthetic data engine and adapt state-of-the-art vision-LLMs (VLMs) for precise schematic visual grounding in mathematics education.
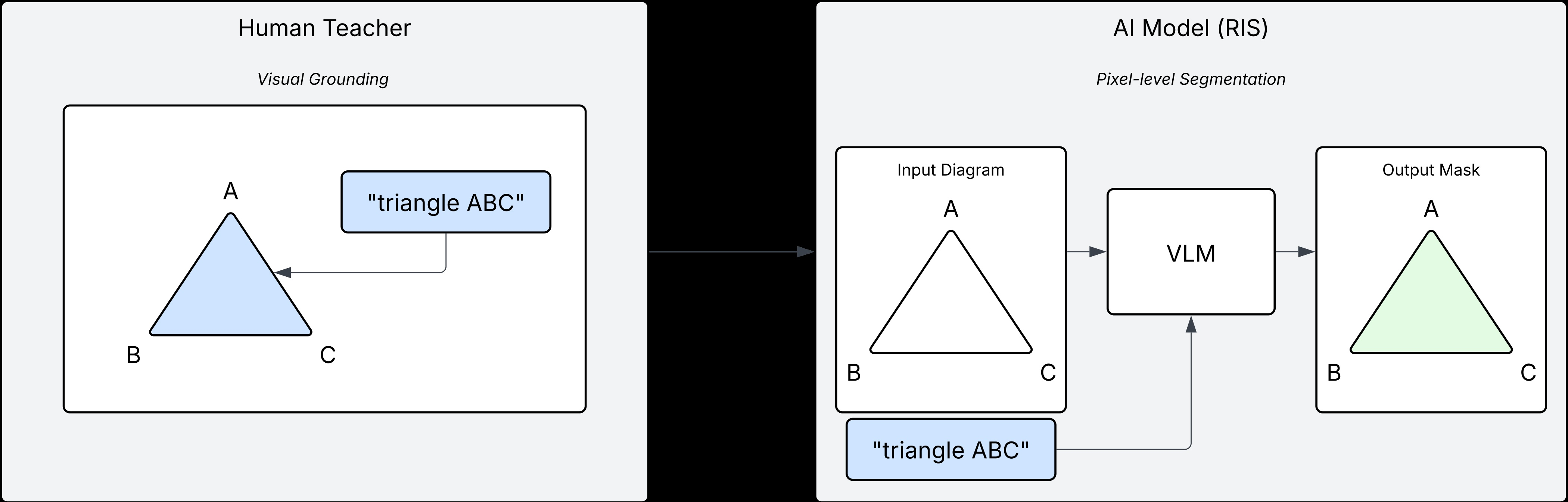
Figure 1: A comparison illustrating how the Artificial General Teacher formalizes human pedagogical pointing as a Referring Image Segmentation task to generate pixel-level visual explanations.
Synthetic Data Generation Pipeline
Central to this approach is a highly automated, three-stage data generation pipeline, yielding over 50,000 pixel-perfect geometry diagrams with no manual annotation. Unlike prior datasets tailored purely for symbolic reasoning, this framework establishes a scalable mechanism for constructing diverse schematic data with exact spatial ground-truths.
The pipeline consists of:
- Constraint-Based Geometry Construction: Each geometric shape satisfies mathematically explicit constraints (e.g., parallelism, equal length), avoiding the inefficiency of random sampling and rejection prevalent in previous procedural generators.
- Deterministic Vector Rendering with LaTeX/TikZ: Geometric coordinates are injected into TeX templates, benefiting from infinite resolution, precise reproducibility, and perfect alignment between diagrams and masks.
- Automated Mask Extraction via Rasterization: Target elements are selectively rendered in color, context is suppressed, and masks are extracted through channel arithmetic, ensuring zero misalignment and complete transparency during training and evaluation.
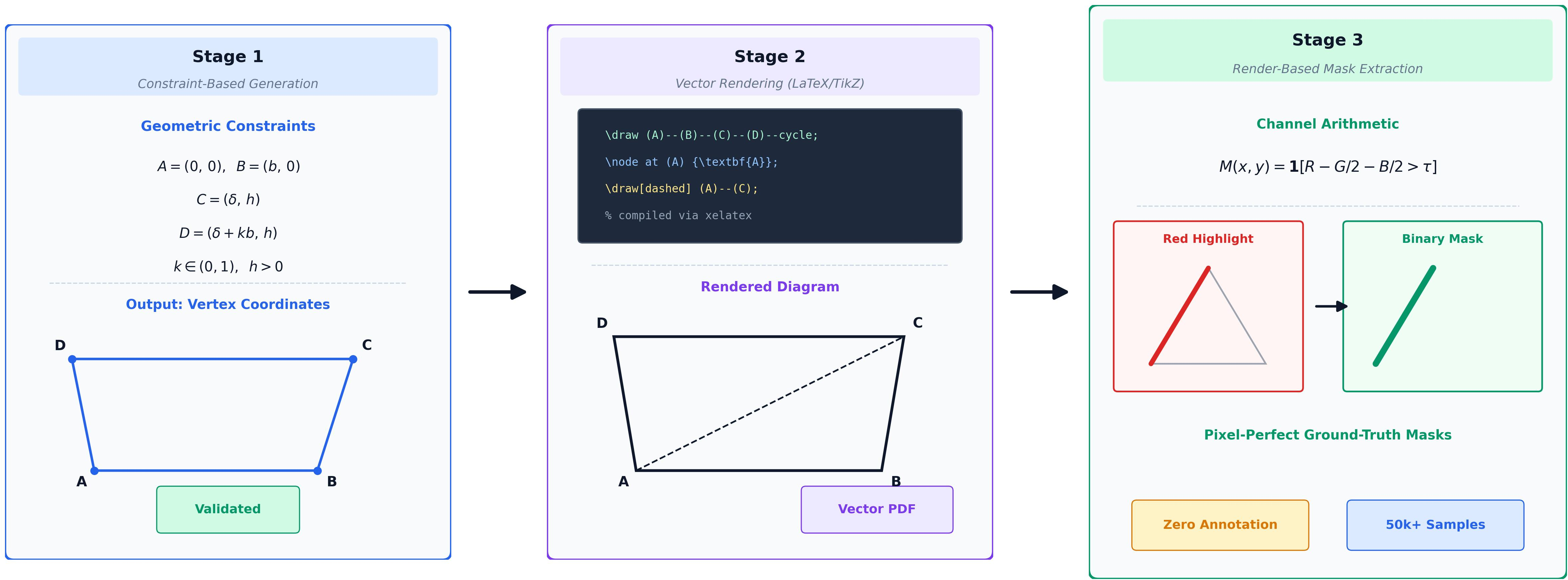
Figure 2: The automated three-stage data generation pipeline that leverages analytical constraint solving and vector graphics rendering to produce synthetic diagrams with pixel-perfect ground-truth masks.
The procedural pipeline supports various geometric primitives such as parallelograms, rectangles, trapezoids, squares, and polygons with incircles, ensuring comprehensive coverage. Rigorous convexity and non-collinearity validation ensures geometric admissibility without post-hoc correction.
A hierarchical template-based natural language generation system produces diverse referring expressions (e.g., "The triangle with vertices B, D, and E", "The segment connecting F and G") to robustify grounding against phrase memorization.
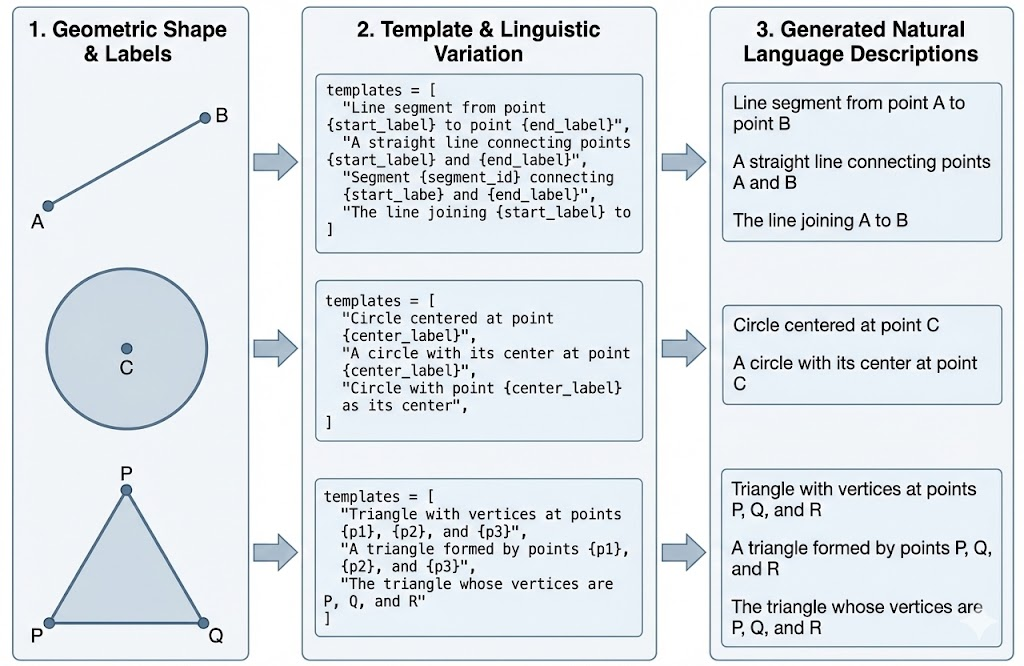
Figure 3: A hierarchical template system that generates linguistically diverse referring expressions from geometric labels to ensure the model learns robust visual grounding rather than memorizing specific phrases.
Resolution stochasticity is introduced, simulating both low-fidelity and high-fidelity renderings to maximize real-world robustness.
Vision-LLM Adaptation for Schematic Visual Grounding
The RIS task in the geometric domain exhibits a magnitude of domain shift relative to benchmarks such as RefCOCO(+/g). Pretrained models, including LAVT and Florence-2, fail (<1% IoU, <5% Buffered IoU) due to the absence of visually salient cues present in photographic imagery. The authors hypothesize that language-centric architectures—especially those with LLM backbones—are better suited for parsing geometric descriptions that rely on topological semantics rather than appearance.
The following VLMs were selected for adaptation:
- Florence-2: Lightweight with strong text-grounding and efficient fine-tuning behavior.
- Qwen-VL: LLM-centric, capable of multi-stage reasoning and explicit spatial computation via language understanding.
The authors employ parameter-efficient LoRA adapters, minimizing computational overhead while preserving domain adaptability, and reformulate the segmentation output as polygon-based coordinate token sequences—aligning supervision with the natural autoregressive sequence modeling of VLMs.
Buffered IoU (BIoU) is introduced as an evaluation metric, explicitly tolerating limited spatial deviation (buffered polygons), providing a fairer assessment for thin elements than classical IoU.
Experimental Results
Fine-tuning transforms zero-shot failure into highly accurate segmentation:
| Model |
IoU |
BIoU |
| LAVT (RefCOCO, zero-shot) |
<1% |
3% |
| Florence-2 (zero-shot) |
<1% |
3% |
| Qwen-VL (zero-shot) |
3% |
5% |
| Florence-2 (fine-tuned) |
49% |
85% |
| Qwen-VL (fine-tuned) |
10% |
42% |
Florence-2 fine-tuned achieves 49% IoU and 85% BIoU, outperforming competitors by large margins. Standard metrics understate model accuracy on thin elements, while BIoU better captures practical localization. Mixed-resolution training further increases low-DPI segmentation accuracy by 24% without harming high-resolution performance, demonstrating effective domain generalization.
Qualitative results validate precise segmentation of lines, polygons, and circles under varied diagrammatic complexity and linguistic query forms.
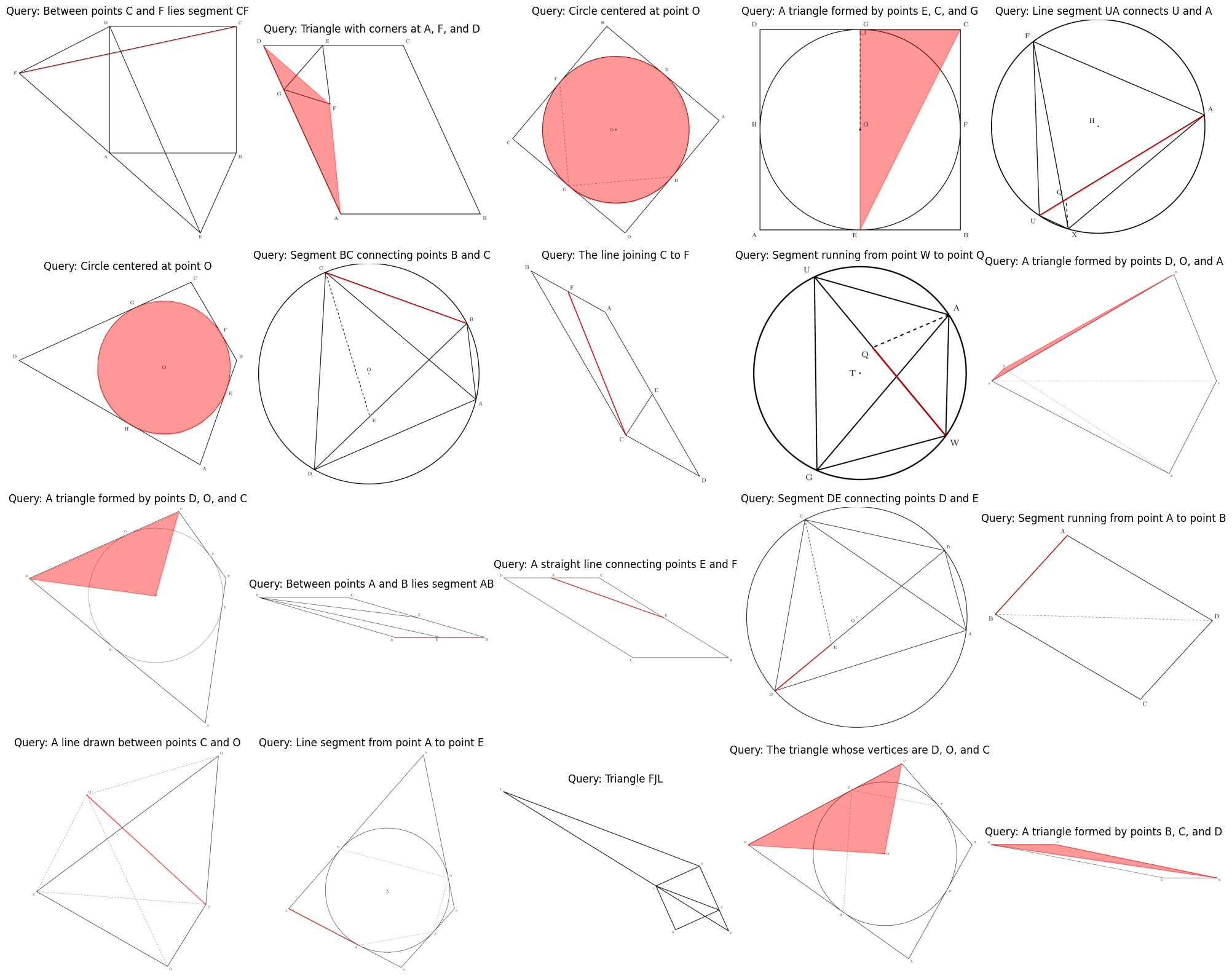
Figure 4: Qualitative visual grounding results demonstrating precise segmentation of lines, triangles, and circles across diverse geometric queries and diagrammatic complexities.
Toward the Artificial General Teacher Pipeline
The AGT system is conceptualized as an integrated workflow:
- Geometry concept understanding and constraint solving
- Analytical problem solving (numeric answer and procedural steps)
- Generation of step-by-step natural language explanations
- Visual grounding of key elements via RIS, closing the pedagogical loop by multimodal signal integration
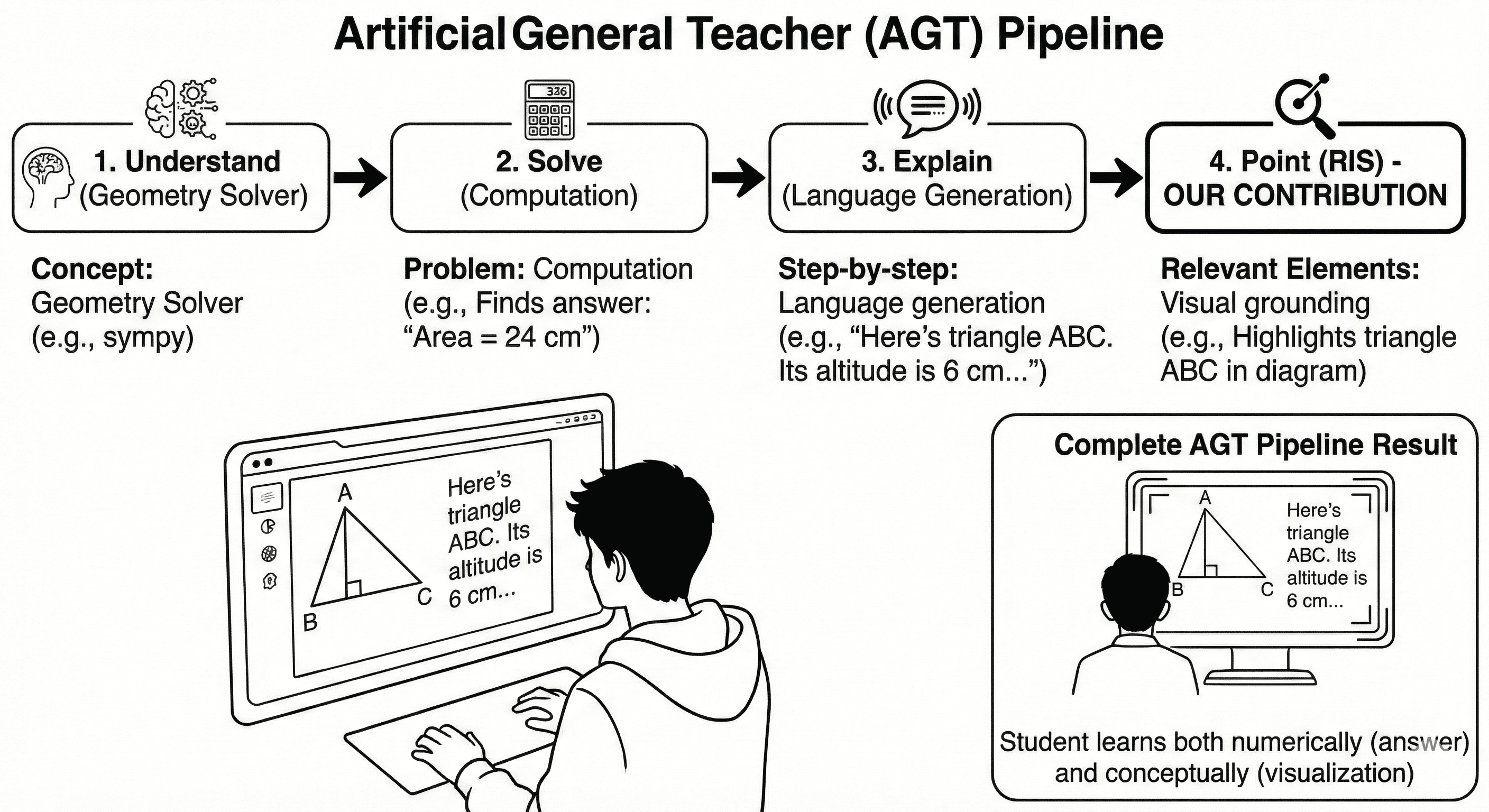
Figure 5: The Artificial General Teacher (AGT) Pipeline, illustrating the multimodal integration of solver, computation, explanation, and visual grounding.
This approach delivers significant pedagogical benefits, reducing cognitive search overhead and reinforcing concept acquisition via visual-linguistic alignment.
Limitations and Future Directions
Primary current limitations include exclusive reliance on synthetic data, restriction to 2D explicit elements, and limited shape variety. Notably, implicit geometric constructs (e.g., altitudes, angle bisectors, circumcircles) require symbolic reasoning and are currently out of scope.
Future research priorities are:
- Sim2real transfer to handwritten and photographic diagrams via domain-mixed fine-tuning
- Extension to 3D geometric rendering and reasoning for higher-dimensional education
- Integration with geometric solvers to infer implicit constructions
- Advanced multi-polygon and topologically-constrained mask prediction
- Additional spatial loss (e.g., Hausdorff distance) for token-to-shape consistency
The modular pipeline supports extensibility toward richer STEM diagram domains (e.g., physics) and conversational tutoring agents capable of dynamic multimodal pedagogy.
Conclusion
This work demonstrates a procedural data and training framework that enables vision-LLMs to achieve high-fidelity referring image segmentation on schematic geometry. Through analytical shape generation, vector-based rendering and masking, and advanced sequence-level supervision, the authors realize a core component of artificial general teachers—visual grounding—heretofore inaccessible to models trained only on natural images. Future developments will rely on synthesizing geometric reasoning, real-world robustness, and richer pedagogical interactivity, opening the path toward comprehensive automated STEM education systems.