- The paper introduces a unified formal language that enables precise symbolic parsing for both 2D and 3D geometric diagrams.
- It presents the GDP-29K dataset with nearly 30K annotated diagrams, enhancing robustness in geometric perception.
- The dual training approach of supervised fine-tuning and reinforcement learning achieves state-of-the-art accuracy in geometric reasoning.
A Unified Framework for Geometric Diagram Parsing: From Plane to Solid Geometry
Motivation and Problem Statement
Robust geometric reasoning remains a persistent challenge for Multimodal LLMs (MLLMs), primarily due to a fine-grained perception bottleneck. While advances in visual LLMs have yielded impressive results on general mathematical and reasoning benchmarks, a pronounced gap exists when models are tasked with the precise symbolic understanding of geometric diagrams—a critical prerequisite for downstream geometry problem solving. The main limiting factor is the inability of current MLLMs, even at state-of-the-art (SOTA) scale, to accurately parse geometric primitives and the rich semantic structures they encode, particularly in solid (3D) geometry.
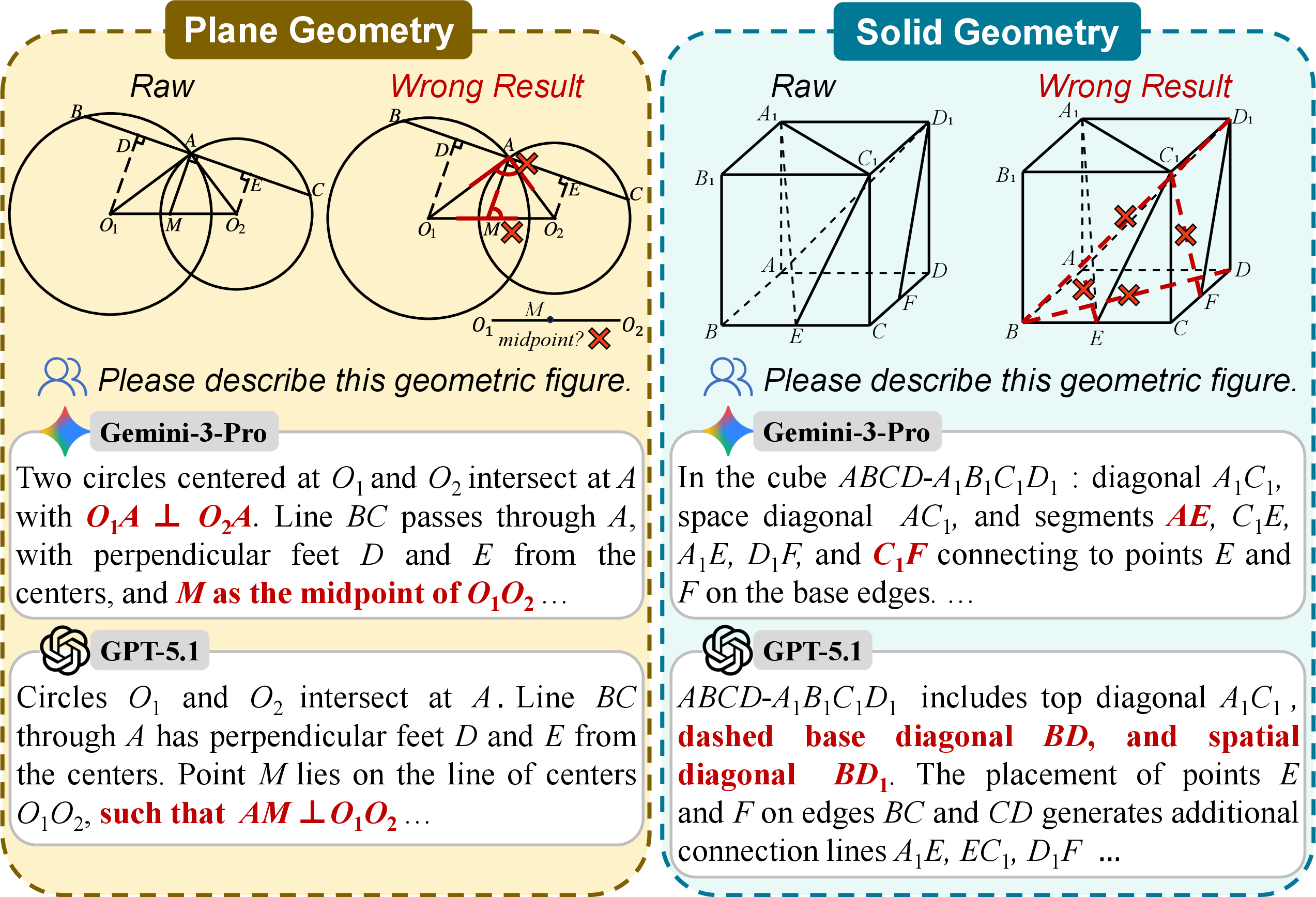
Figure 1: Hallucinations in geometric parsing by SOTA MLLMs. Gemini-3-Pro and GPT-5.1 struggle to correctly parse slightly complex plane geometry and simple solid geometry.
This paper introduces a unified approach to geometric diagram parsing, formalizing both plane and solid geometry within a single expressive language, and provides the large-scale GDP-29K dataset to fuel the development of robust symbolic geometric perception systems.
The cornerstone of this work is the introduction of an extensible, unified formal language capable of capturing the full breadth of both plane (2D) and solid (3D) geometric structures, including:
- Explicit definition of primitives (points, lines, circles, planes, solids)
- Encapsulation of semantic relations (e.g., perpendicularity, parallelism, metric constraints)
- Modular templates that enable both compactness and high expressiveness, facilitating hierarchical decomposition of complex solids into interpretable components
This language systematically extends previous 2D-focused formalisms to cover intricate 3D constructions, including polyhedral objects (cubes, prisms, pyramids, frustums) and solids of revolution (cylinders, cones, spheres), ensuring seamless compatibility with legacy datasets and reasoning systems while enabling holistic spatial compositionality.
The GDP-29K Dataset: Structural Coverage and Diversity
GDP-29K is a large-scale dataset purpose-built for diagram parsing tasks. It comprises 19,965 plane and 8,917 solid geometry diagrams, each paired with formal, fully verified annotations.
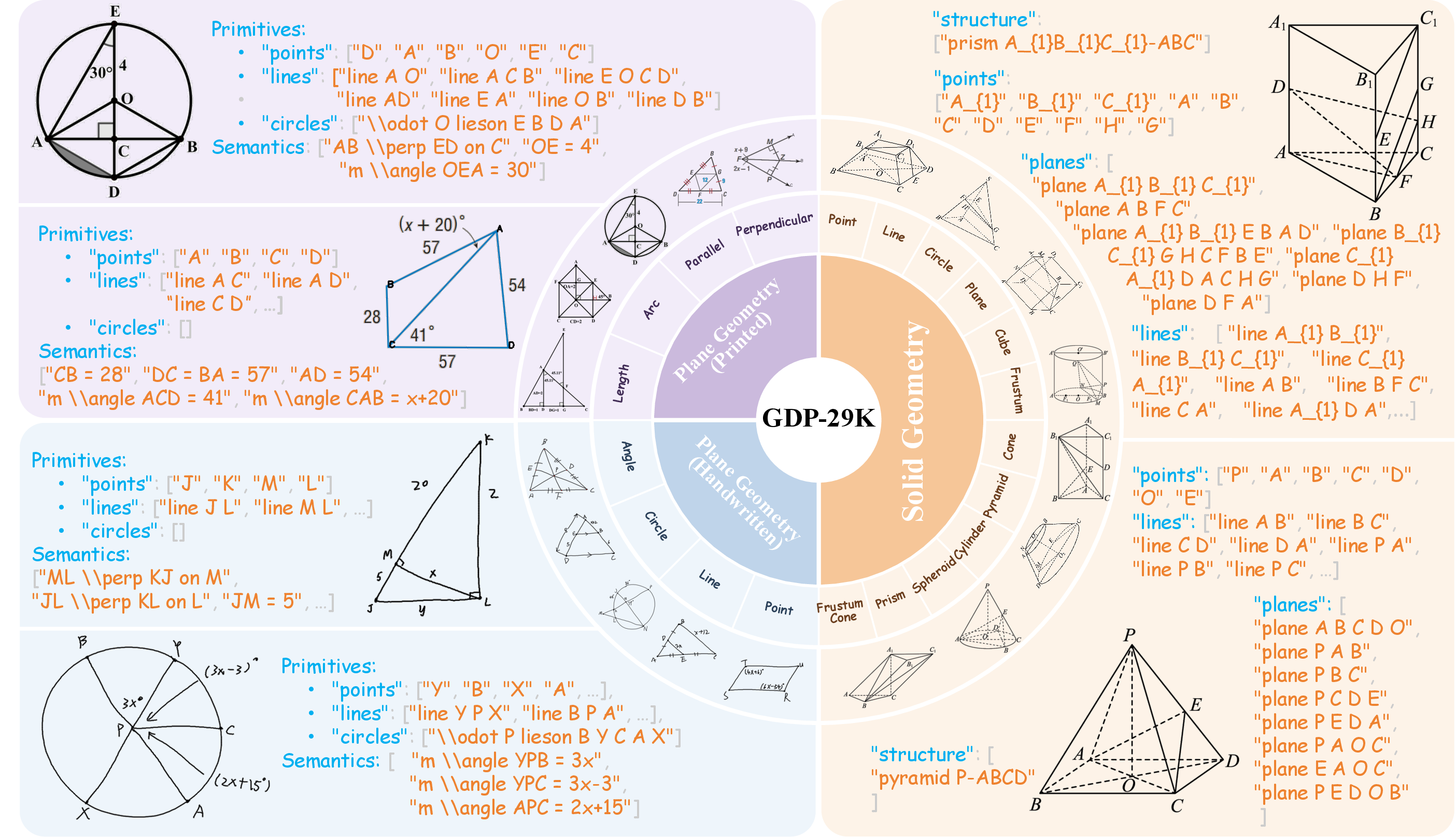
Figure 2: Overview of the GDP-29K dataset for geometry diagram parsing: includes printed and handwritten plane geometry, and solid geometry, all annotated with unified formal language.
GDP-29K offers several distinctive advantages:
- Diversity: It includes both printed and hand-drawn diagrams, increasing robustness to real-world distortions.
- Coverage: The solid geometry subset is the first of its scale to facilitate formal 3D geometric parsing, with a comprehensive distribution over polyhedral and curved solids
- Semantic richness: Plane geometry samples feature a high density of constraints and relations.
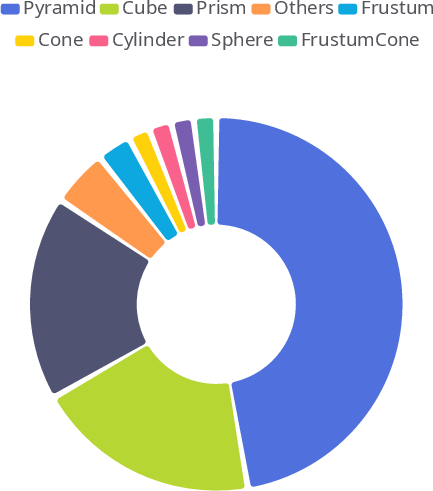
Figure 3: Distribution of 3D structures in the SGDP subset (N=9,012). The dataset covers a wide range of polyhedral forms and rotational solids to facilitate robust spatial perception.
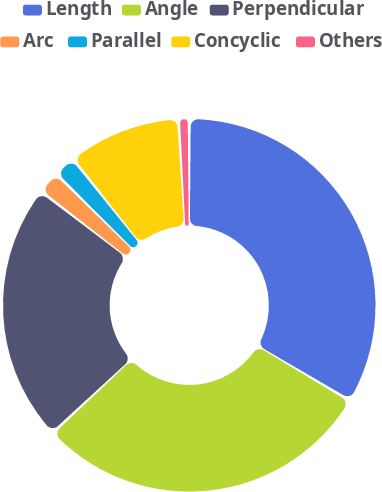
Figure 4: Distribution of semantic predicates across the PGDP subset (N=48,613). Metric constraints and orthogonal relations form the core of the geometric reasoning tasks.
Representative diagram samples evidence the dataset's complexity and annotation fidelity.
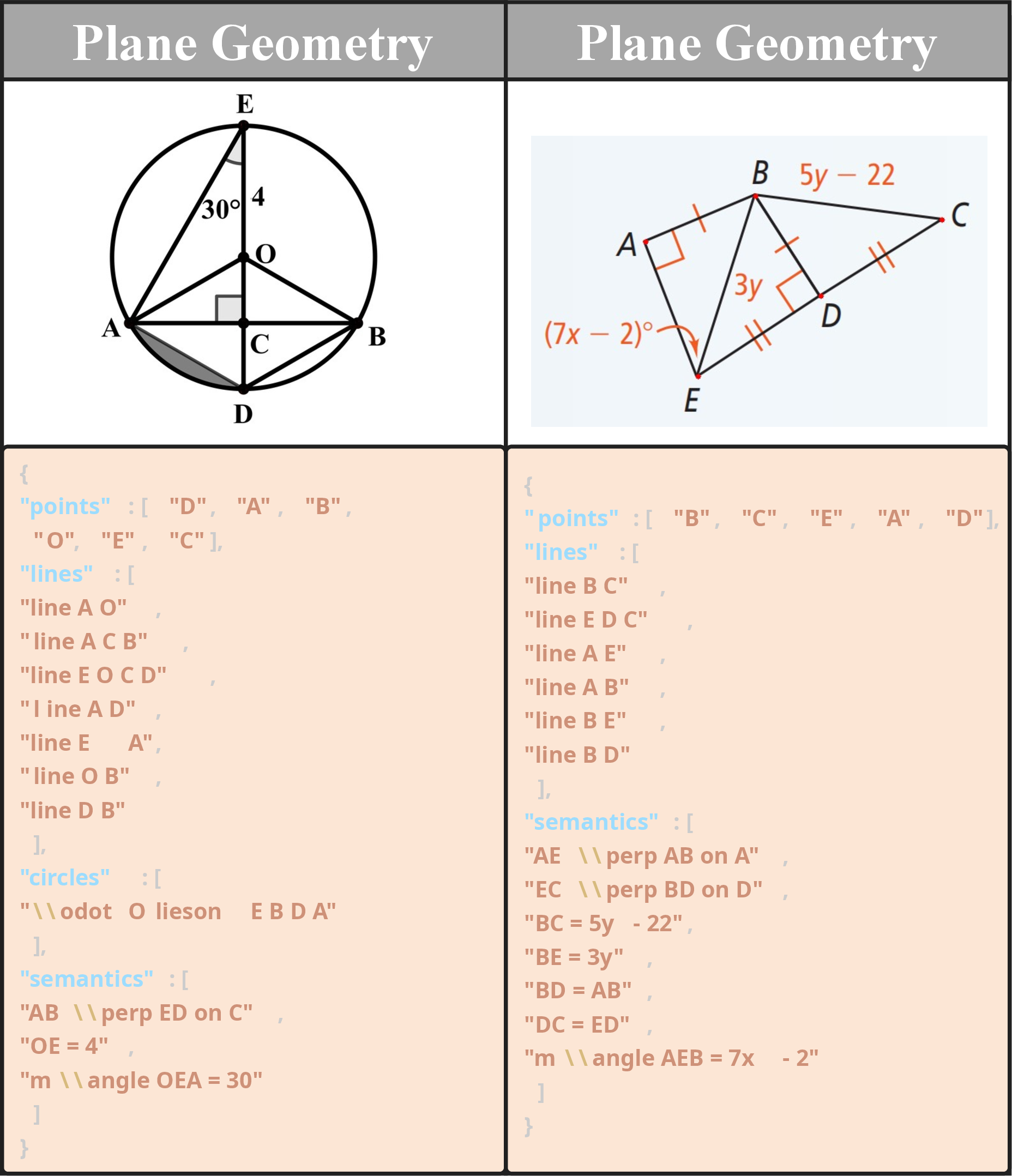
Figure 5: Representative plane geometry samples from the GDP-29K dataset.
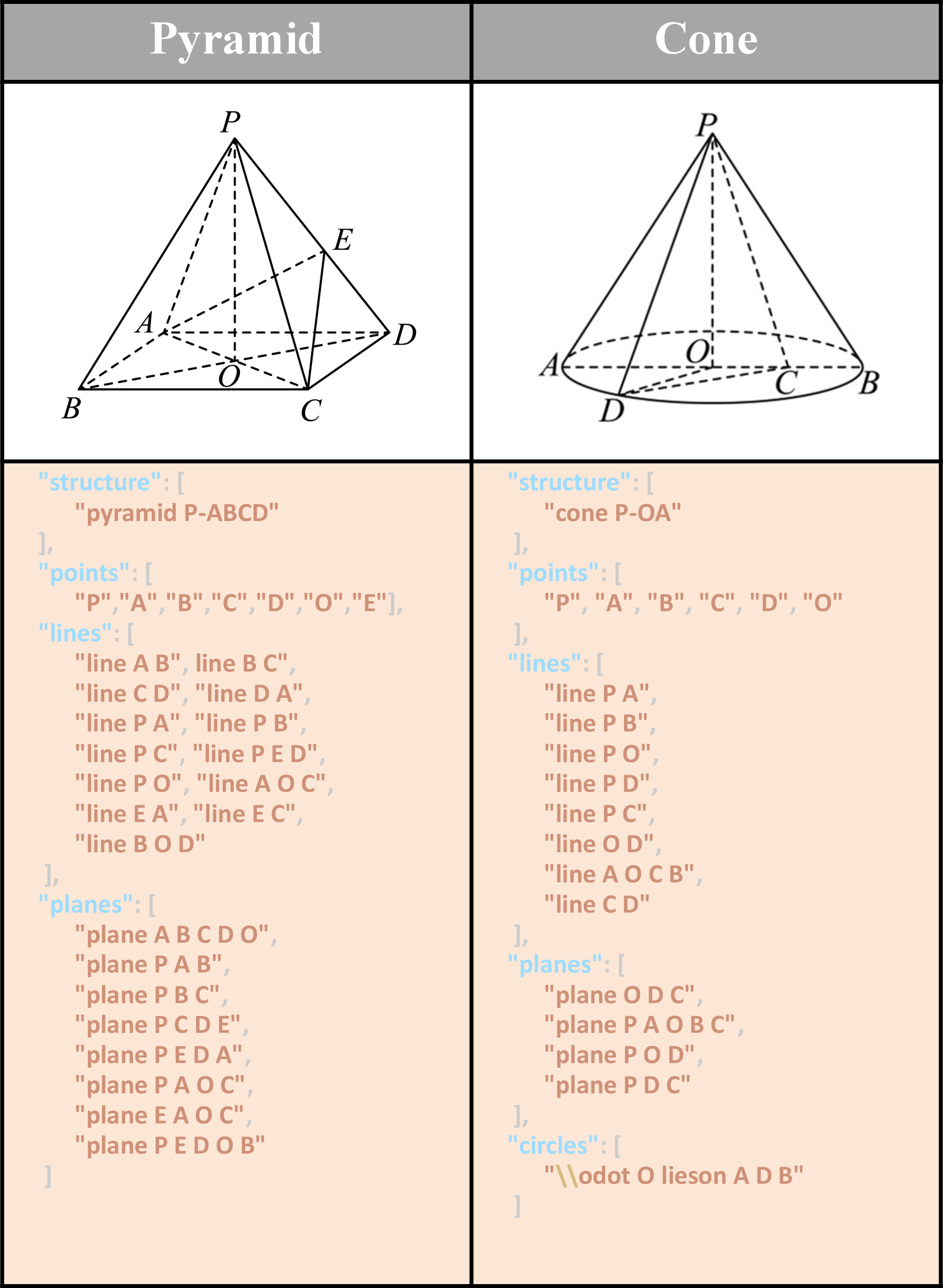
Figure 6: Representative solid geometry samples from the GDP-29K dataset.
Parsing Framework: SFT and RL with Verifiable Rewards
The proposed parsing pipeline consists of two key training stages:
- Supervised Fine-Tuning (SFT): Aligns model outputs with the formal language syntax and explicit mapping between visual and symbolic primitives.
- Reinforcement Learning via Verifiable Rewards (RLVR): Further optimizes the model by maximizing a reward that penalizes both syntactic and geometric inconsistency, enforced with a rule-based verifier.
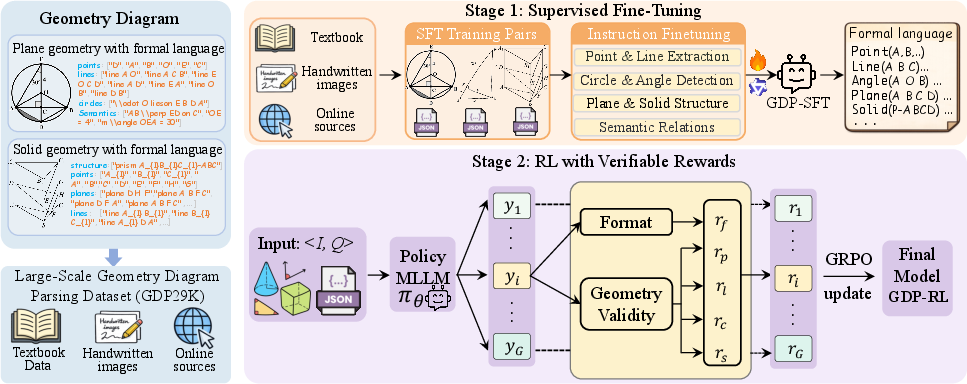
Figure 7: Overview of the geometry diagram parsing framework: SFT establishes initial parsing ability; RLVR enforces global syntactic and geometric validity; the final model generates unified outputs for both plane and solid diagrams.
This dual-stage process guarantees high structural accuracy and holistic syntactic rigor, in contrast to pure maximum likelihood or instruction-tuning objectives.
Quantitative Results
GDP-29K-trained models achieve SOTA parsing performance on both plane and solid geometry, as evidenced by both primitive-level F1 and holistic diagram-level exact match rates. On the PGDP-2K test set, GDP-4B-RL surpasses closed and open-source SOTA MLLMs (e.g., GPT-5.2, Gemini-3-Flash) across all categories, with an overall accuracy of 96.4; on SGDP-1K, the model achieves 94.9, filling a previously unaddressed gap in 3D parsing. These results are robust across both basic primitives and higher-order semantic relations, particularly for complex solid structures.
The application of RLVR demonstrates non-trivial improvements in capturing semantic and high-order components of the diagrams, beyond what is achievable with supervised learning alone.
Downstream Geometry Reasoning Augmentation
The parsed formal descriptions produced by the GDP-RL model can be seamlessly incorporated into the input for downstream reasoning models, yielding substantial accuracy improvements:
Ablation analysis reveals that compact symbolic formalizations provide superior inductive bias for geometric reasoning over natural language-like textual forms.
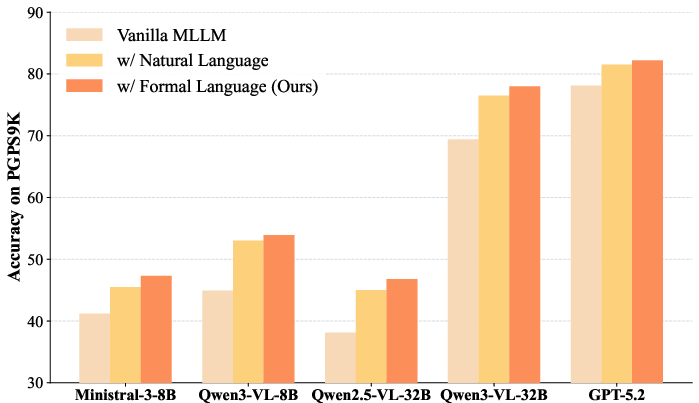
Figure 9: Effect of Representation Forms on PGPS9K Reasoning Accuracy. Symbolic formal language representations consistently outperform natural language equivalents for downstream tasks.
Theoretical and Practical Implications
The approach establishes a new standard for the separation of perception and reasoning in geometric AI:
- Perception bottleneck resolved: Symbolic parsing decouples perception errors from high-level reasoning, enabling reliable error diagnosis and targeted model improvement.
- Unified symbolic infrastructure: The language and dataset enable direct extension to new geometric domains and integration with theorem provers or symbolic solvers.
- Scalability to 3D: The ability to robustly parse 3D solids paves the way for spatial reasoning tasks in technical, engineering, or educational environments.
Limitations and Future Directions
While the GDP-29K and parsing framework set a strong empirical baseline, several limitations merit further investigation:
- Unlabeled visibility: Current formal descriptors do not differentiate between explicit and implicit geometric elements (e.g., visible vs. hidden/dashed lines).
- Semantic sparsity in 3D: Most solid geometry samples are built from basic primitives; the extension to semantically denser and more challenging 3D configurations is a natural next step.
- Generalization beyond educational data: Real-world 3D engineering diagrams may require additional compositional structures and higher-order spatial semantics.
Conclusion
This work demonstrates that the integration of a unified formal language, a large and diverse diagram dataset, and a parsing paradigm combining SFT and RL with verifiable rewards enables SOTA accuracy in both plane and solid geometry parsing. The resulting symbolic representations address the core perception bottleneck and significantly enhance downstream geometric reasoning in MLLMs. Extensions to richer 3D semantics, explicit visibility attributes, and real-world applications constitute promising pathways for future research.
Reference:
"Geoparsing: Diagram Parsing for Plane and Solid Geometry with a Unified Formal Language" (2604.11600)
