- The paper introduces MathCanvas, a framework that integrates diagram editing with textual chain-of-thought reasoning for multimodal mathematical problem solving.
- It leverages three large, curated datasets to train models on iterative diagram generation and visual manipulation using a two-stage training recipe.
- Experimental results on MathCanvas-Bench show significant gains in geometry tasks, with BAGEL-Canvas outperforming prior models in weighted scoring metrics.
MathCanvas: Intrinsic Visual Chain-of-Thought for Multimodal Mathematical Reasoning
Motivation and Problem Statement
Mathematical reasoning, especially in geometry and function analysis, fundamentally relies on the construction and manipulation of visual aids. While LLMs have achieved strong performance in textual chain-of-thought (CoT) reasoning, their capabilities are limited in domains where visual intuition is essential. Prior approaches to Visual Chain-of-Thought (VCoT) either depend on rigid external tools or fail to generate high-fidelity, strategically-timed diagrams, resulting in suboptimal or incorrect solutions. The MathCanvas framework addresses these deficiencies by enabling unified Large Multimodal Models (LMMs) to natively interleave visual synthesis and editing with textual reasoning, thereby unlocking intrinsic VCoT for complex mathematical problem solving.
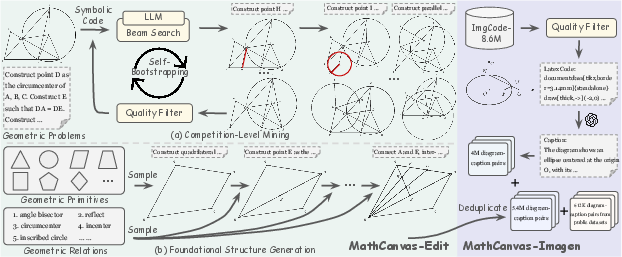
Dataset Construction and Curation Pipeline
MathCanvas introduces three major datasets:
Benchmarking and Statistical Analysis
MathCanvas-Bench is a dedicated benchmark comprising 3K problems sampled from MathCanvas-Instruct, designed to rigorously evaluate interleaved image-textual reasoning. Problems are balanced across mathematical domains and filtered to prevent data leakage. The evaluation protocol uses GPT-4.1 for automated answer extraction and correctness judgment, employing both complete accuracy and a weighted scoring metric that values later sub-questions more heavily.
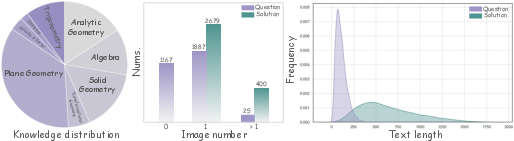
Figure 2: Statistical analysis of the MathCanvas-Bench test set, including knowledge type distribution, image count per question/solution, and text length distributions.
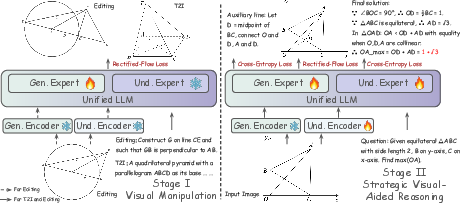
Two-Stage Training Recipe
The MathCanvas framework is instantiated on the BAGEL unified LMM architecture, which features separate transformer experts for understanding and generation. The training paradigm consists of two stages:
Dataset and Example Diversity
MathCanvas-Instruct covers a broad taxonomy of mathematical knowledge points, with 65% multimodal and 35% text-only questions, spanning middle and high school curricula. The average solution length is 540 tokens, and solutions may contain up to five images, supporting complex, multi-step reasoning.

Figure 4: Distribution of knowledge type of MathCanvas-Instruct dataset.
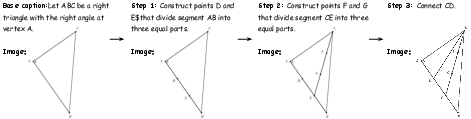
Figure 5: An example from MathCanvas-Edit dataset, illustrating step-by-step diagram editing.
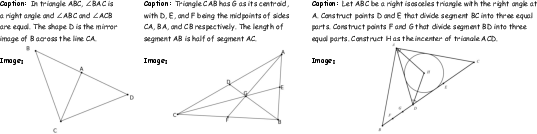
Figure 6: Examples from MathCanvas-Imagen dataset, demonstrating caption-to-diagram generation.
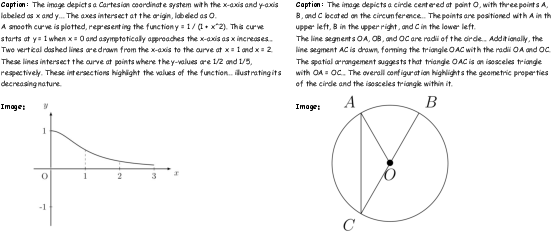
Figure 7: Additional examples from MathCanvas-Imagen dataset.

Figure 8: An example from MathCanvas-Instruct dataset, showing interleaved visual-textual reasoning.

Figure 9: Another example from MathCanvas-Instruct dataset.

Figure 10: Further example from MathCanvas-Instruct dataset.
Qualitative Comparison with Prior Methods
MathCanvas demonstrates clear advantages over previous intrinsic VCoT models (e.g., BAGEL-Zebra-CoT, Nano-Banana), which either generate geometrically invalid diagrams or fail to strategically employ visuals. In contrast, MathCanvas produces correct intermediate visual steps that unlock elegant solution paths.

Figure 11: Leading LMMs (Gemini-2.5-Pro and GPT-5) solving a problem via text-only reasoning, highlighting the limitations of non-visual approaches.

Figure 12: Comparison of BAGEL-Zebra-CoT, Nano-Banana, and MathCanvas, illustrating superior strategic visual reasoning.
Experimental Results and Ablations
On MathCanvas-Bench, BAGEL-Canvas achieves a weighted score of 34.4%, outperforming all open-source models and several proprietary systems. The model exhibits the largest gains in geometry-heavy subjects (Trigonometry +27.1, Plane Geometry +19.2, Solid Geometry +12.3), validating the hypothesis that visual reasoning is critical for these domains. Ablation studies confirm that both diagram editing and generation pretraining are essential, and that interleaved visual-textual training fundamentally enhances textual reasoning even in text-only benchmarks.
Implementation Details
Training is performed on 16 NVIDIA H800 GPUs using AdamW optimizer. Stage I uses a learning rate of 2×10−5 for 80K steps, with the understanding expert frozen. Stage II uses 1×10−5 for 16K steps, with all components unfrozen. Losses include Rectified-Flow for images and cross-entropy for token prediction. Dropout rates are tuned for regularization, and batch sizes are set to maximize GPU utilization.
Implications and Future Directions
MathCanvas establishes a new paradigm for multimodal mathematical reasoning, demonstrating that intrinsic VCoT can be effectively realized in unified LMMs. The framework, datasets, and benchmark provide a robust foundation for future research in dynamic, process-oriented multimodal reasoning. Potential extensions include scaling to higher-dimensional mathematics, integrating symbolic computation, and exploring agentic capabilities for interactive problem solving.
Conclusion
MathCanvas presents a comprehensive solution to the challenge of intrinsic visual chain-of-thought reasoning in mathematics. By combining large-scale visual manipulation and strategic reasoning datasets with a two-stage training recipe, the framework enables LMMs to autonomously generate and edit diagrams as part of their reasoning process. The resulting model, BAGEL-Canvas, achieves substantial improvements over prior baselines, particularly in geometry and other visually intensive domains. This work sets a new standard for multimodal mathematical reasoning and opens avenues for further advancements in AI-driven problem solving.