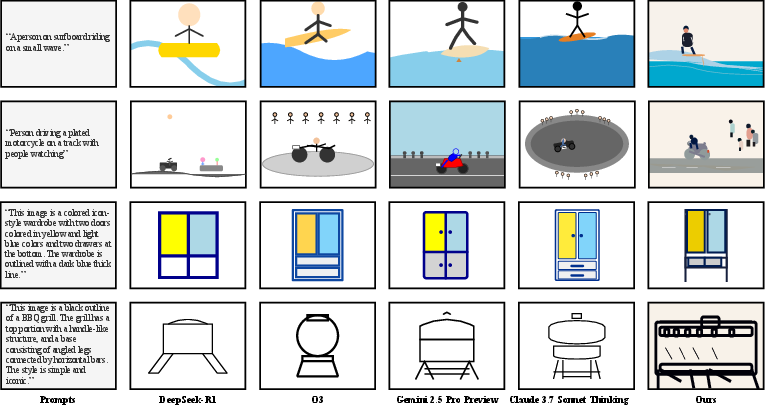
- The paper introduces a comprehensive benchmark, SGP-GenBench, to systematically evaluate LLMs' SVG generation capabilities.
- The paper demonstrates that a reinforcement learning framework with cross-modal verifiable rewards significantly improves compositional accuracy and semantic alignment.
- The paper highlights that RL-tuned open-source LLMs can achieve near state-of-the-art performance in generating detailed, compositional SVG programs.
Symbolic Graphics Programming with LLMs: Methods, Benchmarks, and Reinforcement Learning
Introduction
This work systematically investigates the capacity of LLMs to generate symbolic graphics programs (SGPs), specifically focusing on scalable vector graphics (SVG) as the target representation. The study introduces a comprehensive benchmark (SGP-GenBench) for evaluating SGP generation, analyzes the performance gap between open-source and proprietary LLMs, and proposes a reinforcement learning (RL) framework with cross-modal verifiable rewards to enhance SVG generation quality. The research demonstrates that RL post-training, guided by vision-language foundation models, can substantially improve the SVG generation capabilities of open-source LLMs, closing much of the gap with state-of-the-art proprietary systems.

Figure 1: Qualitative results of symbolic graphics programming. RL with verifiable reward enables Qwen-2.5-7B to acquire compositional drawing ability and produce semantically accurate symbolic graphics programs.
Symbolic Graphics Programming: Motivation and Properties
Symbolic graphics programming is formulated as the task of generating a formal, structured graphics program (e.g., SVG code) from a natural language prompt. Unlike pixel-based text-to-image (T2I) generation, SGP generation is inherently interpretable and verifiable, as the output code can be deterministically rendered and analyzed for semantic correctness.
SGPs possess two critical properties:
- Parametric Precision: SVGs encode geometry and appearance via explicit parameters (coordinates, radii, colors, transforms), enabling fine-grained control over spatial and visual attributes. This allows LLMs with strong symbolic reasoning to generate graphics with high geometric fidelity, a capability that remains challenging for T2I models.
- Procedural Compositionality: SVGs are constructed hierarchically from primitives, supporting modular scene composition and manipulation. This procedural nature facilitates the decomposition of complex scenes into controllable elements, supporting compositional reasoning and structured scene synthesis.
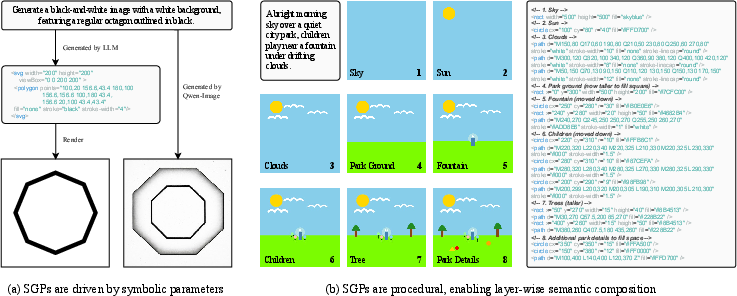
Figure 2: (a) SGPs provide precise symbolic controllability, e.g., generating a regular octagon with exact geometry, outperforming T2I models. (b) Procedural generation enables hierarchical scene construction.
SGP-GenBench: Benchmarking SGP Generation
SGP-GenBench is introduced as a large-scale benchmark to systematically evaluate LLMs' SGP generation capabilities. It comprises three components:
- Scene Generation (COCO-val): 1,024 prompts from MS-COCO captions, targeting complex multi-object scenes.
- Object Generation (SGP-Object-val): 930 prompts for single-object fidelity.
- Compositional Generation (SGP-CompBench): 3,200 prompts assessing attribute binding, spatial relations, and numeracy.
Evaluation metrics include CLIP-Score, DINO-Score, VQA-Score, and HPS v2 for semantic fidelity, as well as judge-model-based compositionality scores.
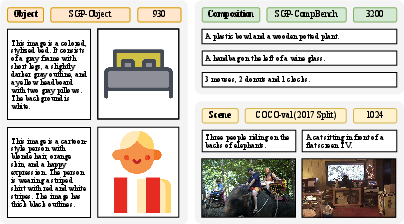
Figure 3: Overview of SGP-GenBench and representative prompt examples.
Benchmark Results
- Proprietary LLMs (e.g., Claude 3.7, Gemini 2.5 Pro) consistently outperform open-source models across all metrics.
- Performance on SGP-GenBench correlates with general code generation ability.
- Open-source models exhibit significant deficits in both syntactic validity and semantic alignment of SVGs.
Reinforcement Learning with Cross-Modal Verifiable Rewards
To address the performance gap, the paper proposes an RL framework that leverages cross-modal alignment rewards derived from vision-language foundation models (e.g., SigLIP, DINOv2). The RL objective is to maximize the expected reward, which is a function of:
- Format Validity: Ensures syntactic correctness and renderability of SVG code.
- Text-Image Alignment: Measures semantic alignment between the prompt and the rendered image using contrastive models (e.g., SigLIP).
- Image-Image Alignment: When reference images are available, DINOv2-based similarity is used to assess visual fidelity.
The RL algorithm (GRPO, a critic-free PPO variant) samples multiple SVG candidates per prompt, computes rewards, and updates the policy accordingly.
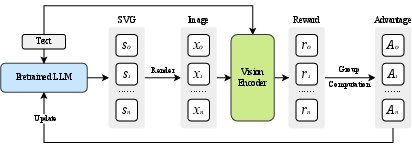
Figure 4: RL pipeline: SVGs are sampled, rendered, scored for alignment, and used to update the model via policy gradients.
Key Advantages
- No Ground Truth SGPs Required: The RL approach does not require paired image-program data, enabling scalable training using only captions and images.
- Implicit Distillation: The LLM internalizes visual priors and semantic grounding from vision foundation models, improving cross-modal alignment.
- Rule-Based Verifiability: Format and semantic correctness are enforced via explicit verifiers, reducing reward hacking.
Experimental Results
RL post-training on Qwen-2.5-7B yields substantial improvements:
Compositional Generalization
- Attribute Binding: RL-tuned models excel at color and shape binding but lag on texture, reflecting SVG's limitations in encoding complex textures.
- Spatial Relations: 2D and implicit relations are handled well; 3D relations remain challenging due to SVG's rendering order constraints.
- Numeracy: Models achieve high accuracy in total object counts but struggle with precise per-item counts, indicating ongoing challenges in fine-grained compositional reasoning.
Analysis of Training Dynamics and Emergent Behaviors
Best-of-N Sampling vs. RL
RL training yields improvements that cannot be matched by naive Best-of-N sampling within practical compute budgets. The RL-trained model's Best-of-N curve is consistently higher, and matching its performance would require sampling orders of magnitude more candidates.
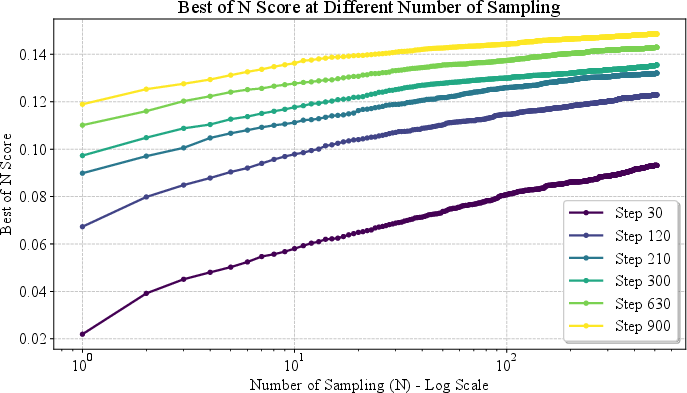
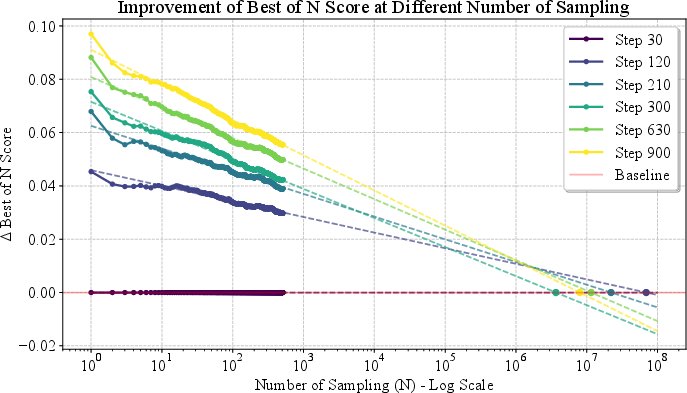
Figure 6: Best-of-N metrics vs. logN: RL-trained models outperform Best-of-N sampling baselines by a wide margin.
Evolution of Generation Strategies
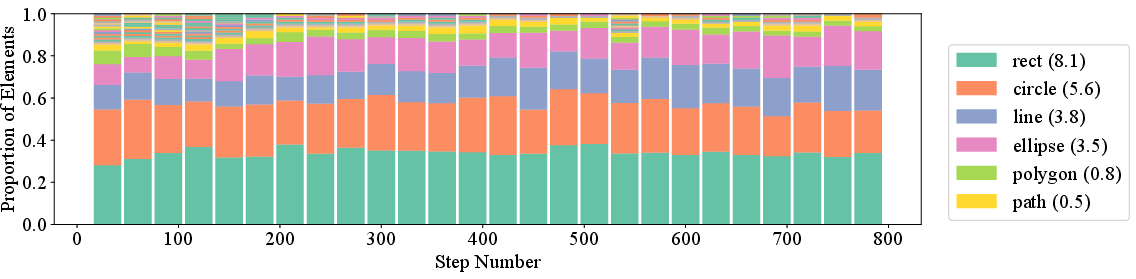
- Increased Complexity: Both the number of SVG elements and code length increase during training, indicating richer scene decomposition and more detailed outputs.
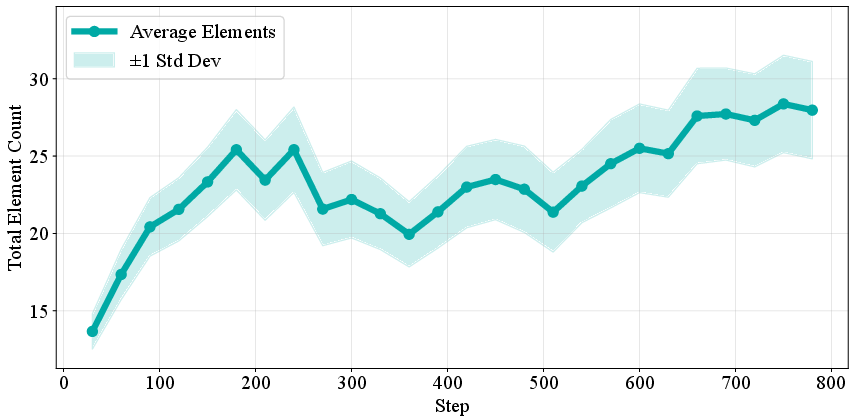
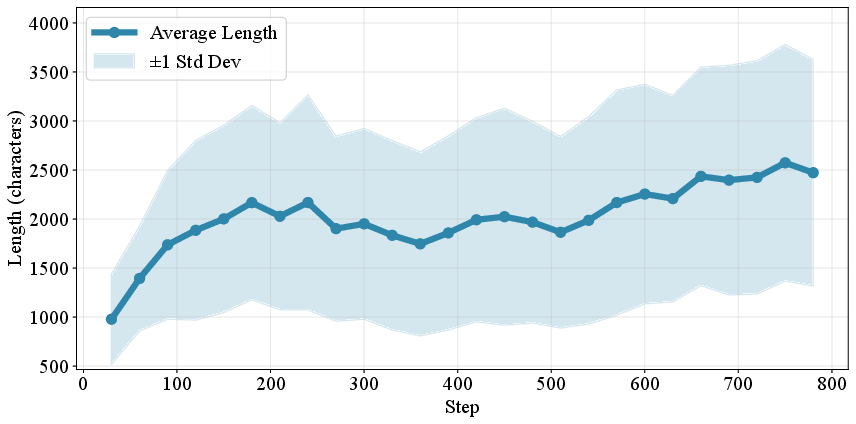
Figure 7: Evolution of elements count: RL induces longer, more complex SVG programs.
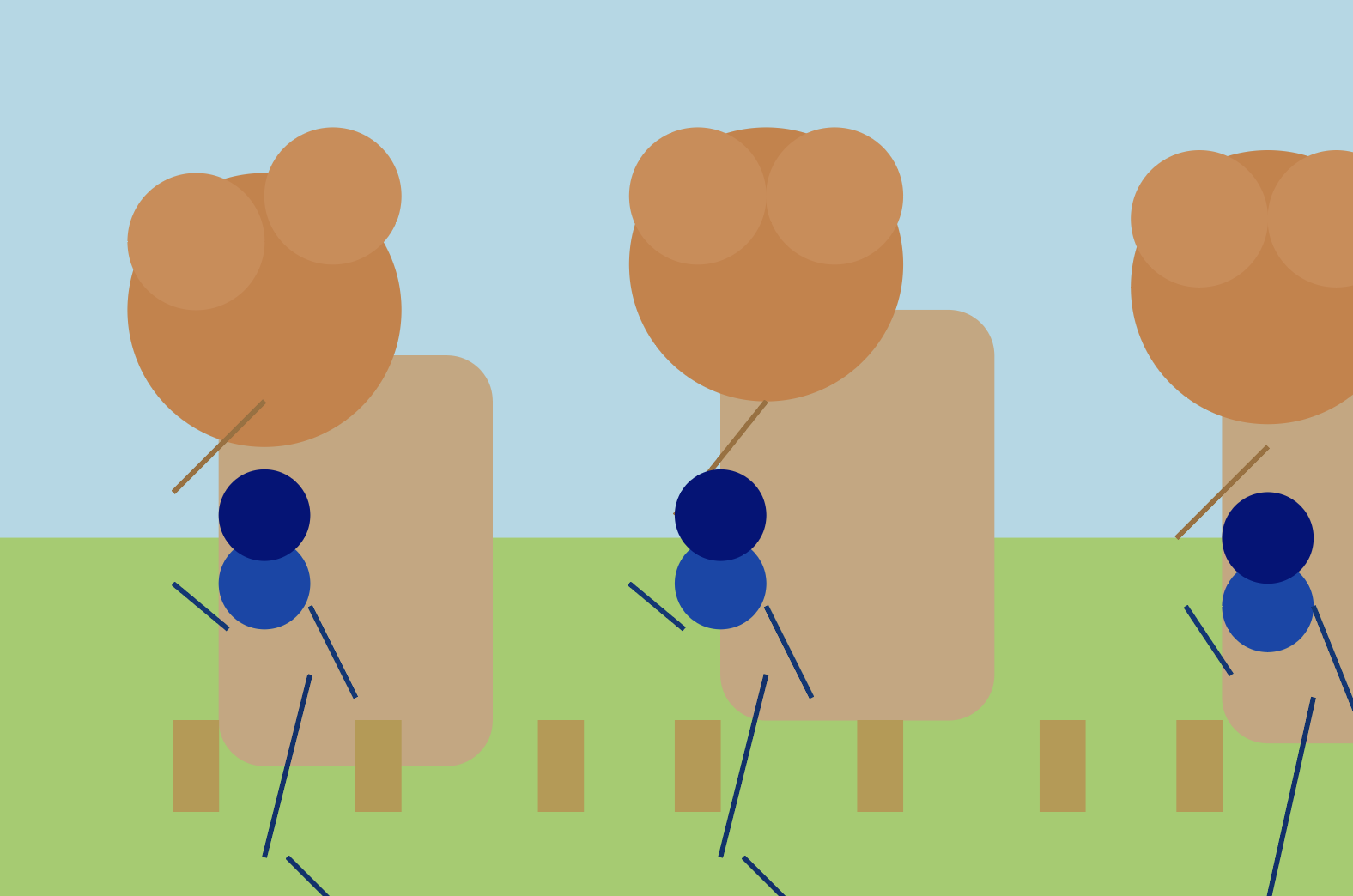
- Finer Decomposition: The model learns to break down complex objects into more granular components, improving semantic accuracy and spatial precision.
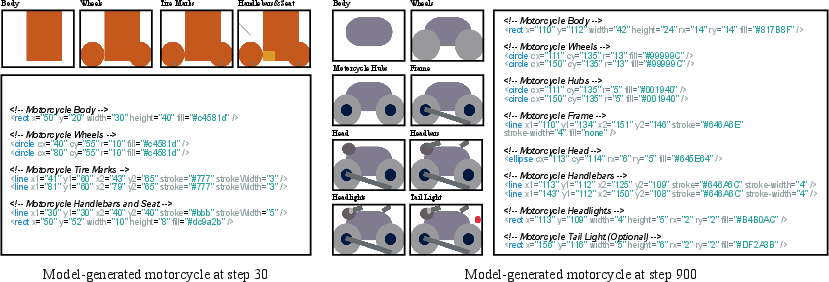
Figure 8: Early-stage models use coarse decomposition; later-stage models achieve fine-grained, semantically accurate part segmentation.
- Contextual Optional Details: RL-trained models begin to add plausible, unprompted details (e.g., sprinkles on a cake, waves at a beach), enhancing scene naturalness and completeness.
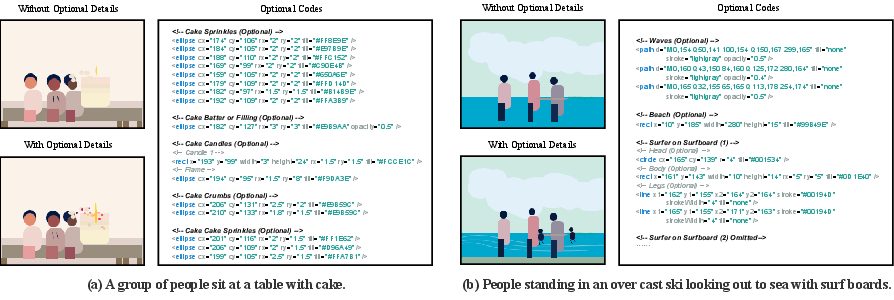
Figure 9: Optional details (e.g., sprinkles, waves) are generated without explicit prompting, improving scene realism.
- Comment-to-Element Ratio: The ratio of explanatory comments to SVG elements increases, reflecting more explicit reasoning and decomposition.
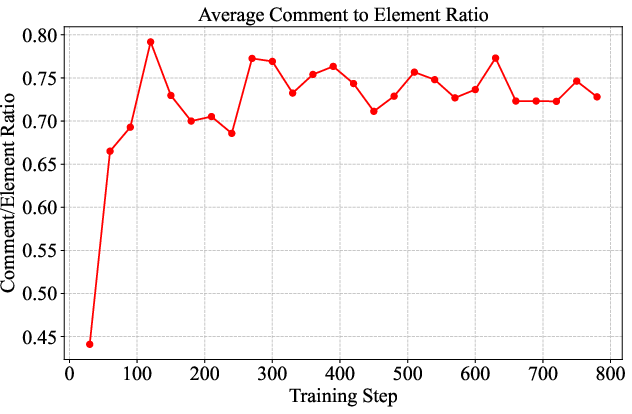
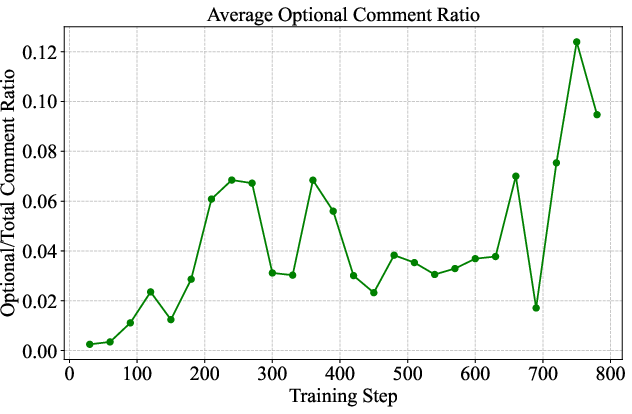
Figure 10: Comment-to-element ratio increases with training, indicating finer-grained decomposition.
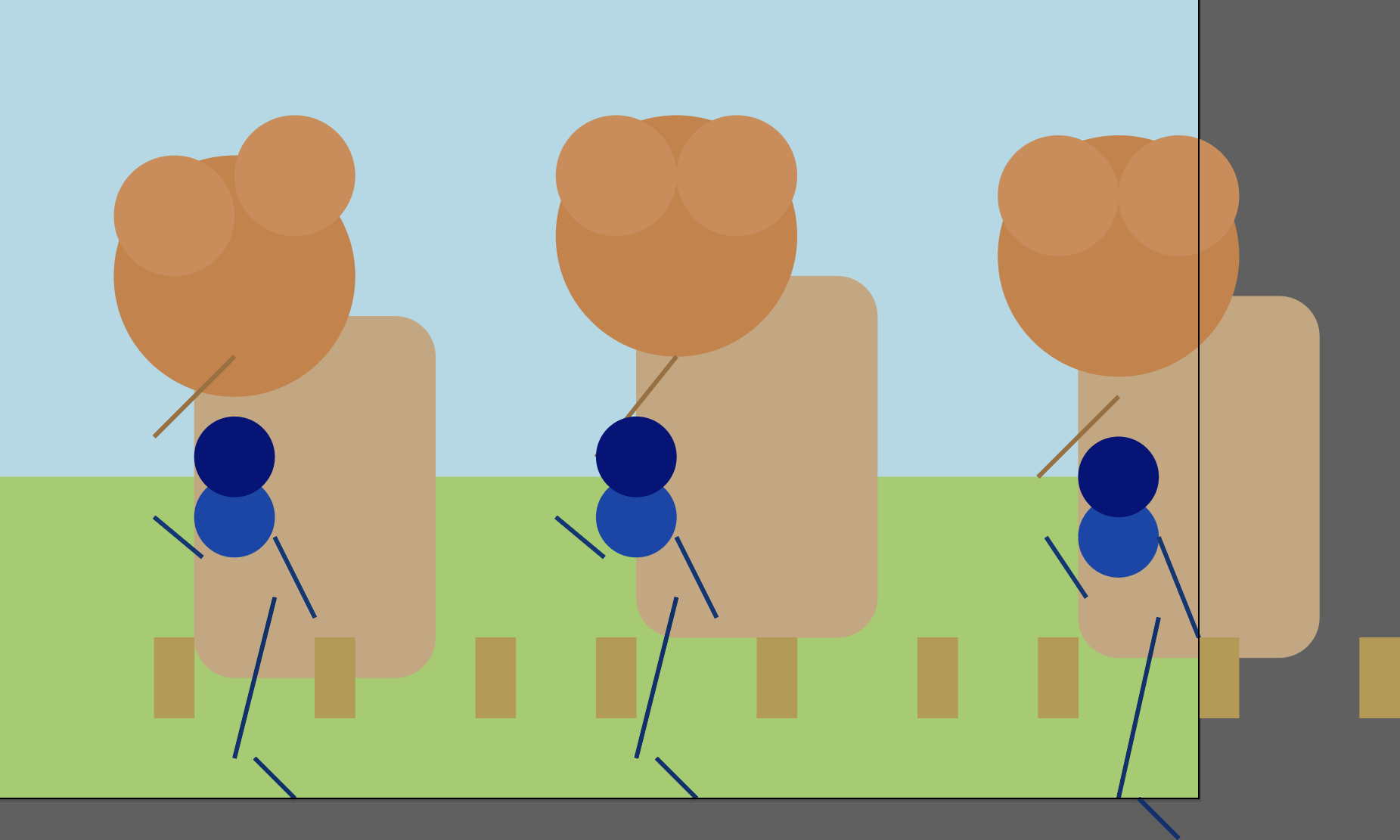
Figure 12: Model draws objects extending outside the viewBox; renderer clips excess, yielding neatly framed images.
Reward Model Effects
- Color Preferences: CLIP-based rewards bias the model toward canonical color names, while SigLIP-based rewards induce more nuanced, low-saturation color choices, suggesting that reward model selection can influence stylistic properties of generated graphics.
Ablation Studies
- Embedding Model Choice: SigLIP outperforms CLIP for text-image alignment, but larger encoders do not always yield better results.
- Chain-of-Thought Prompting: Explicit CoT is not essential for quantitative performance; SVG code itself serves as an implicit reasoning trace.
- RL Algorithm: GRPO outperforms standard PPO in alignment and semantic accuracy, with PPO yielding higher diversity.
- Training Data Mixture: Balanced mixtures of natural-image and SVG-caption data yield the best generalization; single-domain training leads to overfitting.
Implications and Future Directions
Practical Implications
- Open-Source Model Enhancement: RL with cross-modal verifiable rewards enables open-source LLMs to approach proprietary model performance in SGP generation, democratizing access to high-quality symbolic graphics synthesis.
- Data Efficiency: The approach obviates the need for large-scale paired program-image datasets, facilitating scalable training on internet-scale data.
- Interpretable Cross-Modal Grounding: SGP generation provides a transparent lens for analyzing and improving cross-modal alignment in LLMs.
Theoretical Implications
- Emergent Compositionality: RL induces emergent behaviors such as finer decomposition and contextual detail generation, suggesting that verifiable reward signals can elicit structured reasoning strategies in LLMs.
- Reward Model Influence: The choice of vision-language reward model can shape not only semantic alignment but also stylistic properties of generated outputs.
Future Directions
- Adaptive Curriculum Learning: Dynamic adjustment of prompt complexity and reward shaping could further enhance compositional generalization.
- Transfer to Broader Reasoning Tasks: Investigating whether improved SGP generation skills transfer to other domains requiring structured reasoning.
- Internal Process Analysis: Probing the evolution of internal representations and reasoning traces during RL training.
Conclusion
This study establishes a rigorous framework for evaluating and improving symbolic graphics programming in LLMs. By introducing SGP-GenBench and leveraging RL with cross-modal verifiable rewards, the research demonstrates that open-source LLMs can be post-trained to generate semantically accurate, compositional, and detailed SVGs, rivaling proprietary systems. The findings highlight the value of interpretable, verifiable program synthesis as a testbed for cross-modal grounding and structured reasoning in LLMs, and open new avenues for scalable, data-efficient enhancement of generative models in vision-language domains.