- The paper introduces the GRCA framework for targeted, token-level reward assignment to enhance 3D geometric accuracy in Point-VLMs.
- It employs structured output parsing and a Reprojection Consistency verifier to align 3D predictions with 2D observations and reduce gradient noise.
- Experiments show significant gains in keypoint accuracy and 3D IoU, providing robust spatial reasoning for embodied AI applications.
Reinforcing 3D Understanding in Point-VLMs via Geometric Reward Credit Assignment
Introduction
The paper "Reinforcing 3D Understanding in Point-VLMs via Geometric Reward Credit Assignment" (2604.21160) addresses the fundamental challenge of ensuring that Point-Vision-LLMs (Point-VLMs) produce spatial predictions that are not only semantically plausible but also geometrically consistent and physically verifiable. While large-scale VLMs have demonstrated strong performance in scene understanding, vision-language dialogue, and instruction following, these capabilities do not guarantee physically actionable predictions for embodied agents. Critically, the paper identifies the phenomenon of geometric hallucination—where the model's predicted 3D structure diverges from 2D observations—as a primary bottleneck in real-world deployment. The authors argue that this failure is rooted not in geometry representation limitations, but in the misalignment of reinforcement learning reward assignments to token spans during post-training.
Geometric Hallucination and Credit Assignment Deficiency
In standard Point-VLMs, post-training via RL often adopts broadcasted sequence-level rewards: the signal about whether an answer is "good" is distributed across all tokens—most of which encode language, formatting, or contextual information, not geometry. As a result, spatially critical coordinate tokens are diluted by unrelated supervision, yielding weak gradient signals for the subset that affect geometric correctness. This leads to models that can produce textually correct or visually plausible answers, yet fail to produce metric-accurate, view-consistent 3D structures. The paper establishes, both theoretically and empirically, that this diffusion of reward—rather than a lack of geometric capacity—is the main cause of unreliable 3D grounding.
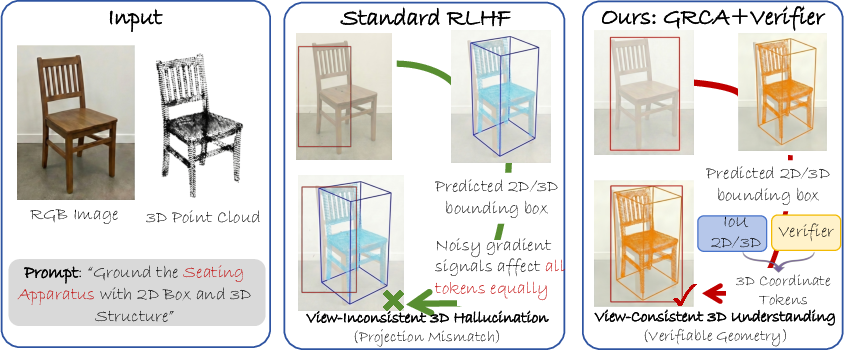
Figure 1: Geometric Reward Credit Assignment (GRCA) targets reward directly to geometry token spans, reducing geometric hallucination compared to broadcasted-reward GRPO.
Geometric Reward Credit Assignment (GRCA): Methodology
The central contribution is the GRCA framework, formalized as a token-level credit assignment strategy leveraging output structure parsing. The main stages are as follows:
- Structured Output Schema and Hybrid Policy: The model fuses 3D features from Point-BERT with 2D image tokens via a cross-attention mechanism, using the Qwen2.5-VL backbone. The output is a fixed schema in JSON, with explicit fields for 2D/3D boxes, keypoints, and text.
- Stage 1: Supervised Warm-up: SFT aligns the model to produce outputs conforming to the schema but does not differentiate between coordinate and language tokens in the loss.
- Stage 2: GRCA Post-Training: For each generated sequence, geometric fields are parsed, token spans are recovered, and each field is evaluated using a task-specific reward (IoU for boxes, containment-based for keypoints). These field-level standardized rewards are routed only to the responsible coordinate token spans; all other tokens (context, language, formatting) receive a separate, global background reward.
- Reprojection Consistency (RPC) Verifier: To ensure global coherence, a cross-modal reward is computed based on the 2D IoU between the predicted 2D box and the projection of the predicted 3D bounding box. This RPC term is integrated into the background reward to drive overall 2D-3D consistency rather than local token correction.
The final post-training objective is formulated analogously to GRPO but substitutes the sequence-level advantage with routed, field-specific token-wise advantages.
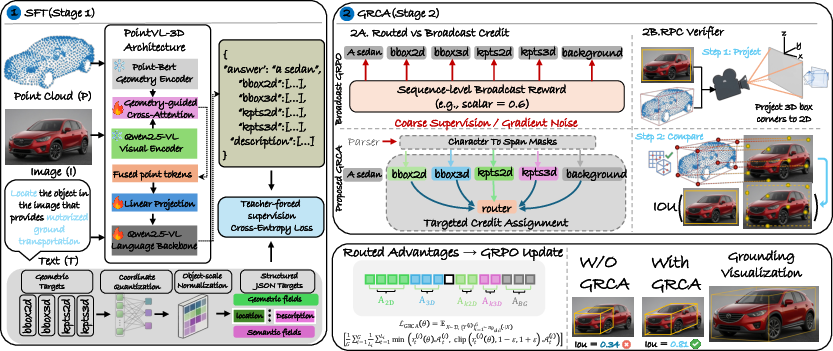
Figure 2: PointVL-3D architecture and two-stage training protocol: SFT for schema compliance and GRCA for targeted alignment, with an RPC consistency verifier.
Theoretical Clarification: Signal-to-Noise and Gradient Decomposition
The authors analyze the variance properties of routed credit versus broadcast reward assignment for coordinate token spans. Broadcasted supervision introduces variance from unrelated reward components, inflating the gradient noise for geometry tokens and reducing learning efficacy. GRCA, by localizing reward assignment, yields lower-variance updates for geometry spans, empirically evidenced by improved alignment without increased computational budget. This is further supported by ablation studies showing significant gains in keypoint accuracy under identical training resource allocation.
Experimental Protocol and Results
A novel camera-calibrated spatial grounding benchmark based on ShapeNetCore forms the primary evaluation bed. The dataset introduces high-fidelity synthetic 2D renders aligned with 3D point clouds and dense geometric/semantic annotations, reducing domain shift and annotation bias compared to prior work.
The key evaluation metrics include:
- Intersection-over-Union (IoU) for bounding boxes in 2D and 3D.
- Keypoint Accuracy (KPA), defined by the fraction of predicted keypoints inside ground-truth boxes, in both 2D and 3D.
- Reprojection Consistency (RPC), measuring cross-modal alignment.
Strong numerical results are as follows:
- 3D KPA improves from 0.64 (SFT baseline) to 0.93 with GRCA and RPC.
- 3D bounding box IoU reaches 0.686, outperforming architecture-matched and stronger 3D baselines (e.g., PointNet, PointBERT).
- RPC rises to 0.852, indicating robust 2D-3D structural coherence.
- 2D localization performance is preserved (∼0.89 IoU), demonstrating no catastrophic forgetting of language or visual alignment.
Ablation over the RPC weight demonstrates an optimal regime (λ=0.15); higher emphasis leads to over-regularization, where the model "hacks" reprojection at the expense of true 3D metric accuracy.

Figure 3: Example visualizations from PointVL-3D: VQA, 3D/2D bounding box and keypoint outputs, and the cross-modal reprojection consistency computation.
Comparative Analysis and Broader Implications
Compared to state-of-the-art VLMs and specialized 3D models, PointVL-3D with GRCA consistently outperforms in both spatial grounding and cross-modal consistency under strict, structured evaluation. The analysis of language metrics (BLEU, ROUGE, BERTScore) confirms that field-localized reward assignment does not degrade semantic fluency or general QA abilities—no observable "alignment tax" is present.
The framework demonstrates that precise, structure-aware credit assignment—not simple reward maximization or model scaling—is critical for securing reliable, physically-grounded spatial reasoning in VLMs. This has broad implications for embodied AI, robotics, and high-stakes deployment scenarios where executable geometry and robust multi-modal alignment are non-negotiable.
Limitations and Future Directions
The methodology currently relies on accurate camera parameters and synthetic-domain photorealistic data, which may limit immediate deployment in unconstrained real-world scenes. Generalizing GRCA to dynamic, uncalibrated, or real-image domains will require either joint camera estimation or self-supervised geometric consistency objectives. Extending the approach to robotic manipulation, dynamic scene understanding, and open-vocabulary multi-object grounding are viable trajectories.
Conclusion
The paper formalizes and resolves a core deficiency in structured generation for Point-VLMs: the dilution of geometric supervision due to broadcasted reward assignment. Through GRCA and RPC, the model achieves state-of-the-art geometric grounding, robust view-consistency, and strong language task retention. This approach shifts the paradigm from plausibility-driven generation to physically verifiable, executable spatial prediction, constituting a substantial advance for multimodal embodied intelligence.