LongVideoAgent: Multi-Agent Reasoning with Long Videos
Abstract: Recent advances in multimodal LLMs and systems that use tools for long-video QA point to the promise of reasoning over hour-long episodes. However, many methods still compress content into lossy summaries or rely on limited toolsets, weakening temporal grounding and missing fine-grained cues. We propose a multi-agent framework in which a master LLM coordinates a grounding agent to localize question-relevant segments and a vision agent to extract targeted textual observations. The master agent plans with a step limit, and is trained with reinforcement learning to encourage concise, correct, and efficient multi-agent cooperation. This design helps the master agent focus on relevant clips via grounding, complements subtitles with visual detail, and yields interpretable trajectories. On our proposed LongTVQA and LongTVQA+ which are episode-level datasets aggregated from TVQA/TVQA+, our multi-agent system significantly outperforms strong non-agent baselines. Experiments also show reinforcement learning further strengthens reasoning and planning for the trained agent. Code and data will be shared at https://longvideoagent.github.io/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LongVideoAgent: An easy-to-understand guide
What is this paper about?
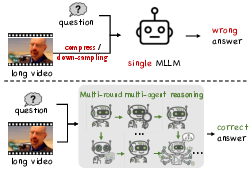
This paper builds an AI “team” that can watch very long videos (like full TV episodes) and answer questions about them. Instead of trying to squish the whole video into a short summary (which loses details), the AI team figures out which small parts of the video are relevant and looks closely at those parts to find the right answer.
What questions are the researchers trying to answer?
The researchers focus on three simple questions:
- How can an AI handle long videos without missing small but important details?
- Can splitting the work among a few cooperating AIs (a “multi-agent” team) make answers more accurate and efficient?
- Does training the main AI to plan its steps carefully (using rewards for good behavior) improve results?
How does their method work?
Imagine you’re a detective solving a case in a huge city (the long video). You don’t search every street. You:
- find the right neighborhood,
- zoom in to look at important objects, and
- decide when you’ve seen enough to conclude.
The AI team follows a similar plan:
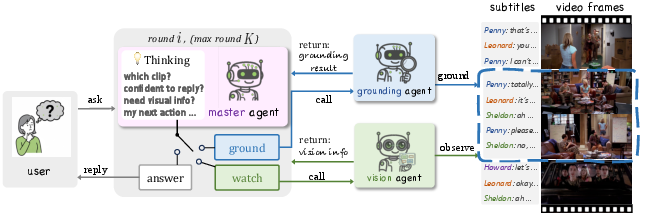
- The Master Agent is the “team captain.” It decides what to do next and when to stop and answer.
- The Grounding Agent is like a “map scout.” It picks the short video segment (the right neighborhood in time) that matches the question.
- The Vision Agent is a “magnifying glass.” It looks at the chosen segment’s frames to spot details like objects, text on screen, actions, or who is where.
The Master Agent works in a few steps (there’s a small step limit so it doesn’t wander forever). At each step, it chooses exactly one action:
- Ask the Grounding Agent to find or refine the right clip.
- Ask the Vision Agent to read visual details from that clip.
- Stop and give the final answer.
To help the Master Agent learn good habits, the researchers use a training style called reinforcement learning. Think of it like a video game:
- The AI gets points for following the rules (making well-formed, tidy steps) and for giving the correct final answer.
- Over time, it learns to plan better, avoid unnecessary tool calls, and answer more confidently.
They also created tougher test sets, LongTVQA and LongTVQA+, by stitching together many short clips from the same TV episode into a single, hour-level episode. This makes the questions more realistic and challenging, like searching a real full episode instead of a tiny clip.
What did they find, and why does it matter?
The researchers report that their multi-agent system beats strong standard methods that do not use agents. Here are the big takeaways:
- Multi-agent teamwork helps. First adding the Grounding Agent (find the right time span) improves accuracy; adding the Vision Agent after that (read fine details) improves it even more.
- Smart planning makes a difference. Training the Master Agent with rewards (so it learns to take clean, useful steps and stop at the right time) makes smaller open-source models much better.
- Good perception tools matter. A stronger Vision Agent (one that’s better at recognizing small objects, reading text on screen, or understanding scenes) leads to higher accuracy.
- You don’t need endless steps. Letting the Master Agent take a few steps (about 5) is usually enough; more steps gave little extra gain.
- A bit more context helps. Looking at a slightly larger time window around the chosen clip can help, but it also takes more time, so there’s a trade-off.
This matters because long videos are everywhere—TV shows, lectures, sports matches, security footage—and important clues can be brief and spread out. An AI that can smartly search and zoom in (instead of guessing from a blurry summary) is more reliable and easier to trust.
What is the impact of this research?
This approach shows a clear path to building AI that:
- Handles long, complex videos with fewer mistakes.
- Explains its reasoning step by step (you can see the clips it chose and the visual facts it used), which makes it more transparent.
- Scales better to real-life tasks, like:
- Answering questions about whole TV episodes or documentaries.
- Finding key plays in sports videos.
- Helping students study long recorded classes.
- Reviewing long surveillance videos for specific events.
The authors also share some current limits and next steps:
- They mostly rely on subtitles for speech and don’t yet process raw audio; adding automatic speech recognition (ASR) would help.
- The Grounding and Vision Agents weren’t trained together with the Master; training all parts jointly could boost accuracy.
- The reward system is simple (format + correct answer). Richer rewards could teach even better strategies.
Overall, LongVideoAgent shows that a small, well-coordinated AI team—led by a planner that learns from rewards—can understand long videos more accurately and clearly than single, one-shot models. It’s a practical step toward trustworthy, long-form video understanding.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future work.
- Multimodal completeness: the system relies on subtitles and frame-based visual reads but does not process raw audio; integrate ASR, speaker diarization, and non-verbal audio cues (music, ambient sounds) and quantify their contribution to long-video QA.
- Temporal grounding modality: the GroundingAgent uses subtitles only; develop and evaluate multimodal temporal grounding that leverages visual features (scene changes, shot boundaries, motion cues) and audio to localize segments more robustly.
- Spatial grounding evaluation: LongTVQA+ preserves frame-level boxes, but the system does not use nor report spatial localization metrics; add tasks and metrics for entity-level spatial grounding and measure consistency between temporal clips and spatial boxes.
- Closed-source dependencies: default grounding uses Grok-4-fast-reasoning and the VisionAgent uses GPT-4o; assess reproducibility by replacing these with open-source counterparts, report performance and cost trade-offs, and provide detailed prompts and configurations for fair replication.
- Grounding agent design transparency: the implementation, training (if any), and evaluation protocol for the GroundingAgent are under-specified; detail the model, training data, objective, and exact metric for Grounding Accuracy (e.g., IoU or overlap threshold with annotated moments).
- Reward design mismatch: the paper claims penalization of irrelevant tool use and incoherent reasoning, but the RL scheme only uses structural validity and final answer correctness; introduce and ablate explicit tool-use costs, step penalties, and intermediate evidence-quality rewards.
- Efficiency and cost analysis: no quantitative report on latency, token usage, number of tool calls per question, and monetary cost; instrument and publish efficiency metrics and throughput under different K and window settings to guide practical deployment.
- Adaptive planning and stopping: K is a fixed upper bound; design and evaluate adaptive stopping policies (e.g., learned confidence thresholds, per-step utility estimates) that balance accuracy and cost, and report distributions of steps used with/without RL.
- Tool reliability and robustness: there is no sensitivity analysis to noisy/misaligned subtitles, imperfect grounding, or erroneous visual descriptions; evaluate robustness under synthetic noise, ASR errors, timestamp drift, and adversarial visual/grounding outputs.
- Error taxonomy: the paper lacks a diagnosis of failure modes (e.g., wrong temporal localization, ambiguous references, missed small objects/OCR); provide an error breakdown to target method improvements and tool selection.
- Dataset scope and generalization: evaluation is limited to episode-level aggregation of TVQA/TVQA+; test on diverse long-form domains (movies, sports, documentaries, instructional videos, user-generated streams) and report out-of-domain generalization.
- Cross-clip reasoning stress: the aggregation may still yield questions answerable within single clips; quantify the distribution of temporal distances and cross-shot dependencies, and construct/curate questions that demand multi-hop across distant segments.
- Multiple-choice constraint: results rely on MC accuracy; add free-form QA and reasoning traces evaluation (e.g., factuality, faithfulness, calibration), and measure whether agentic plans improve open-ended responses.
- Interpretability evaluation: “interpretable trajectories” are claimed but not measured; conduct human or rubric-based assessment of trace quality (step relevance, evidence sufficiency, faithfulness) and correlate with accuracy.
- Joint training of agents: only the master agent is RL-finetuned while Vision/Grounding agents are frozen; explore joint or alternating optimization (e.g., RL with auxiliary losses, imitation from expert trajectories) and quantify gains vs. instability.
- Vision agent ablations: only two vision backbones are tested; expand to more open-source models (OCR-heavy, small-object-biased, face/pose experts), and analyze per-capability contributions to end-task accuracy.
- Master agent modality gap: the master consumes only text (subtitles + textual observations), never raw images/video tokens; investigate designs where the master is multimodal (limited frame tokens) to reduce dependence on textual re-description and potential information loss.
- Prompting and parser robustness: structured tags are required, but resilience to formatting errors and adversarial prompts is untested; evaluate structural reward effectiveness, add parser-level guards, and test recovery strategies when tags are malformed.
- Training/validation protocol clarity: RL training data split and possible overlap with validation are not explicitly stated; clarify splits, add held-out test sets, and report statistical significance to avoid overfitting concerns.
- Memory across questions: each question is handled independently; investigate persistent episode-level memory that caches grounded segments and visual facts across multiple questions, and quantify reuse benefits.
- Dynamic window selection: window size is static in most runs; design an agent policy that adaptively expands/condenses temporal windows based on uncertainty and evidence needs, and report accuracy–latency curves.
- Confidence and calibration: no metrics for how confident the master agent is when answering; add calibration measures (ECE/Brier), abstention options, and confidence-aware tool-use policies.
- Tool orchestration diversity: only grounding and visual tools are used; incorporate specialized tools (face recognition, OCR, ASR, action recognition, scene graph extraction, knowledge retrieval) and study orchestration policies for tool selection.
- Ethical and IP considerations: reliance on proprietary models raises deployment and licensing issues; evaluate open-source-only settings and provide guidelines for compliant, cost-aware configurations.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to measure their impact on performance. "Through ablation studies, we show that both the multi-agent architecture and the reward-guided training contribute critically to the agentâs gains."
- Agentic RL: Reinforcement learning applied within an agent-based framework to improve planning and tool use. "agentic RL yields additional gains, especially for smaller open-source models;"
- Chain-of-Thought: A prompting and reasoning paradigm where solutions are produced via step-by-step intermediate reasoning. "general reasoning paradigms such as Chain-of-Thought, Least-to-Most, Tree-of-Thoughts, and Generative Agents provide foundations for decomposition and memory"
- Clipping (RL): A technique in policy optimization that limits the magnitude of policy updates for stability (e.g., PPO-style clipping). "Policy updates follow the GRPO objective with standard clipping and entropy regularization, while the grounding and vision agents remain frozen."
- Entropy regularization: An RL technique that encourages exploration by penalizing overly confident policies. "Policy updates follow the GRPO objective with standard clipping and entropy regularization, while the grounding and vision agents remain frozen."
- Evidence window (size): The temporal span (number of adjacent clips) included as context for grounding and visual reasoning. "Effect of evidence window size. Larger temporal windows supply richer context for grounding and vision."
- Finite-horizon decision process: A sequential decision setup with a fixed maximum number of steps before termination. "Long-video QA is cast as a finite-horizon decision process: at each action step after reasoning the policy emits exactly one structured action token (\verb|<visual\_query>|, \verb|<request_grounding>|, or \verb|<answer>|)."
- GRPO: A policy optimization method used to train the master agent via reinforcement learning on sampled rollouts. "We optimize the master agent with GRPO on sampled rollouts"
- Grounding Accuracy: A metric that measures how correctly the system localizes relevant video segments. "and additionally Grounding Accuracy for experiments that involve clip grounding."
- GroundingAgent: A specialized agent that temporally localizes video segments relevant to a question. "Specifically, a GroundingAgent locates video segments relevant to the question"
- MasterAgent: The central coordinating LLM that plans, invokes tools, and produces the final answer. "A MasterAgent runs for up to rounds, collaborating with a GroundingAgent to localize relevant clips from videos and a VisionAgent to read fine-grained cues from the localized frames."
- MLLMs (Multimodal LLMs): LLMs extended to process multiple modalities such as text, images, audio, and video. "Multimodal LLMs (MLLMs) extend LLMs beyond text to perceive and reason over multimodal signals, such as visual frames, audio, and subtitles."
- MM-ReAct: A multimodal variant of ReAct that connects LLMs to vision experts via prompting to combine reasoning and action. "In multimodal settings, MM-ReAct wires LLMs to vision experts via prompting"
- Perceiver-style resampler: A module design used to resample and integrate visual features efficiently for few-shot multimodal learning. "Flamingo introduces a perceiver-style resampler for few-shot multimodal learning"
- Program-of-Thought: A reasoning approach where the model composes perception and logic through executable code for transparency. "program-of-thought systems like ViperGPT compose perception modules through executable code for transparent, verifiable reasoning"
- ReAct: A framework that synergizes reasoning with actions (e.g., tool calls) in LLMs. "Foundational agent ideas include ReAct, Self-Ask, and WebGPT"
- Reinforcement learning: A training paradigm where agents learn to act via rewards for correct, efficient, and well-structured behavior. "For open-source LLMs serving as the master agent, we apply reinforcement learning to encourage accurate, concise, and cooperation-efficient behavior"
- Step limit : The maximum number of action rounds the MasterAgent is allowed per question. "The window context is set to $1$, meaning the agent conditions on a single localized clip (no adjacent clips), and the maximum execution steps are ."
- Temporal grounding: The process of aligning questions to specific times or segments within a long video. "a grounding agent to temporally localize question-relevant segments"
- Temporal localization accuracy: The performance measure of how precisely the system identifies the correct time segments. "Increasing from $2$ to $5$ raises temporal localization accuracy from $67.0$ to $71.0$"
- Token-efficient processing: Techniques that reduce token usage while maintaining high-resolution perception and performance. "LLaVA-OneVision~\cite{li2024llava} unifies high-resolution perception with token-efficient processing for both images and videos."
- Trajectory (RL): The sequence of actions, observations, and rewards produced during an episode and used for training. "The rollouts terminated by action tokens in Algorithm~\ref{alg:long_video_agent} provide the trajectories for training and evaluation."
- Value baseline: A learned estimator used to compute advantages and stabilize policy gradient updates. "we compute sequence-level advantages with a learned value baseline."
- Video-RAG: Retrieval-augmented generation tailored for video, combining extracted evidence (ASR/OCR/objects) with LLM reasoning. "video-RAG pipelines extract ASR/OCR/objects and retrieve evidence to augment LVLMs for factual responses"
- Visual query: A structured action directing the VisionAgent to provide on-demand visual details about a localized segment. "Visual query: If current visual information is insufficient, or you need visual details conditioned on the subtitles for the current \textless clipX\textgreater, call the vision engine with \textless visual_query\textgreater query \textless /visual_query\textgreater."
- Window context: The number of consecutive localized clips considered as the evidence window during reasoning. "By default the window context is $1$; when larger, the agent outputs a short run of consecutive tags."
Practical Applications
Immediate Applications
Below is a curated list of deployable, real-world uses that leverage the paper’s multi-agent long-video reasoning framework (MasterAgent + GroundingAgent + VisionAgent) and its reinforcement learning scheme (GRPO), using existing subtitles and vision tools.
- Media and Entertainment (Streaming platforms, post-production)
- Application: Interactive episode-level search and Q&A assistants that “find the scene where X happens” and answer viewer questions about plot, objects, or on-screen text.
- Workflow/Product: A “LongVideo QA API” that ingests episode subtitles and frames; MasterAgent coordinates grounding and targeted vision calls to return answers and timecodes. Integration with content libraries or player UIs for jump-to-clip functionality.
- Assumptions/Dependencies: Availability of accurate subtitles; access to frames for VisionAgent; compute for multi-turn reasoning; rights to process content.
- Video Editing and Post-Production Tools (Software)
- Application: Editor’s assistant that locates shot-level segments matching a textual brief (e.g., “find all scenes with a bus stop at night”); proposes rough-cut bins.
- Workflow/Product: “GroundingAgent plug-in” for NLEs (Premiere, DaVinci) to tag relevant clips; VisionAgent performs targeted OCR/object/action reads on candidate shots.
- Assumptions/Dependencies: Integration with NLE timelines and media proxies; reliable visual models for fine-grained cues; acceptable latency for iterative queries.
- Corporate Meeting Intelligence (Enterprise software)
- Application: Search and Q&A over recorded town halls or training videos—“When did the roadmap slide mention Q3 targets?”—with jump-to-segment answers.
- Workflow/Product: Meeting analysis module in collaboration suites; GroundingAgent uses transcripts (subtitles) to localize segments; VisionAgent reads slides (OCR).
- Assumptions/Dependencies: High-quality transcripts (ASR if no subtitles); OCR-capable vision tools; data governance and access controls.
- Education (EdTech)
- Application: Course video assistants that answer learners’ queries and return the precise segment (e.g., “Where does the instructor derive the loss function?”).
- Workflow/Product: LMS plug-in that indexes lecture videos via subtitles; VisionAgent extracts slide math via OCR; MasterAgent produces concise answers + timestamps.
- Assumptions/Dependencies: Accurate lecture transcripts/subtitles; high-resolution frames for slide OCR; privacy and FERPA-compliant storage.
- Sports Analytics (Media, coaching)
- Application: Interactive Q&A over full match recordings (“At what time was the second corner?”), with scoreboard OCR and scene-specific grounding.
- Workflow/Product: “Sports Q&A bot” that uses GroundingAgent for event localization, VisionAgent for scoreboard/time/jersey-number OCR.
- Assumptions/Dependencies: Video quality for OCR; domain-specific prompts; event semantics may need customization.
- Content Moderation and Compliance (Platforms, broadcast)
- Application: Offline auditing of long-form videos for policy violations or ad-claim checks (e.g., find segments showing restricted content; verify on-screen claims).
- Workflow/Product: Moderation console using GroundingAgent to isolate suspect segments; VisionAgent confirms objects/text; interpretable MasterAgent traces for audits.
- Assumptions/Dependencies: Clear policy taxonomies; robust fine-grained visual detection; legal and privacy frameworks for processing.
- Surveillance and Safety Triage (Security operations; offline review)
- Application: Post-incident review of hours of CCTV footage to answer targeted questions (e.g., “When did a person in a red jacket enter?”) and retrieve clips.
- Workflow/Product: Investigation assistant that runs visual queries on grounded intervals; produces a report with timestamps and textual observations.
- Assumptions/Dependencies: Sufficient visual model accuracy for low-light/occlusions; privacy compliance; often limited/no subtitles—rely more on VisionAgent.
- Academic Research and Benchmarking
- Application: Immediate use of LongTVQA/LongTVQA+ benchmarks to evaluate long-video agents; reproduce ablations (step budget K, window size) and GRPO training.
- Workflow/Product: Open protocols for multi-agent tool-calling; replicable evaluation scripts; teaching materials for agentic video reasoning.
- Assumptions/Dependencies: Access to datasets and tool APIs; compute resources for RL fine-tuning; fair use of TV content for research.
- Developer Platforms (Software infrastructure)
- Application: SDKs/services to build multi-agent long-video QA pipelines (tool orchestration, structured actions, interpretable trajectories).
- Workflow/Product: “LongVideoAgent SDK” with action tags, context management, and integrations (VisionAgent via GPT-4o/Qwen-VL; GroundingAgent via retrieval).
- Assumptions/Dependencies: Tool API availability; cost controls for multi-round calls; monitoring for reliability and drift.
Long-Term Applications
These uses benefit from further research and engineering, including integrating audio (ASR), expanding modalities (multi-camera, live streams), jointly training sub-agents, and scaling to real-time or regulated domains.
- Real-Time Multistream Monitoring (Security, operations, broadcast)
- Application: Live agents that ground, query, and answer over continuous video streams (e.g., event detection across multiple cameras).
- Potential Tools/Products: “Streaming LongVideoAgent” with persistent memory and windowed context; adaptive K and window size; parallel tool calls.
- Assumptions/Dependencies: Low-latency ASR; robust streaming vision; joint training for grounding+vision; compute scalability; alerting pipelines.
- Healthcare and Clinical QA (Hospitals, surgical video)
- Application: Procedure-level Q&A and event retrieval (e.g., “When did the clamp slip?”) from long surgical recordings; safety analytics.
- Potential Tools/Products: Domain-tuned VisionAgent for medical instruments/actions; audited trace outputs for clinical compliance.
- Assumptions/Dependencies: Rigorous validation; medical-grade accuracy and reliability; privacy (HIPAA); specialized datasets; liability-aware deployment.
- Robotics Operations Review and Training (Robotics, autonomy)
- Application: Long-horizon reasoning over robot teleoperation or autonomy logs to answer task-specific queries and surface failure points.
- Potential Tools/Products: Multimodal agent combining video, sensor streams, and action logs; grounding across time-synchronized modalities.
- Assumptions/Dependencies: Sensor fusion; domain-specific perception; on-device or edge compute; safety certification.
- Smart Retail and Industrial Compliance (Retail ops, manufacturing)
- Application: Continuous video QA for safety (PPE checks), process adherence, and anomaly retrieval over long hours of operations.
- Potential Tools/Products: Compliance dashboards with interpretable trajectories; periodic audits and incident summaries.
- Assumptions/Dependencies: Robust detection for varied environments; audio integration for announcements; labor and privacy policies.
- National-Scale Broadcast/Platform Governance (Policy, regulators)
- Application: Automated compliance monitoring across social media and broadcast archives, with interpretable decision traces for appeals.
- Potential Tools/Products: Regulator-grade audit pipelines; standardized schemas for agent action traces; cross-language ASR + OCR.
- Assumptions/Dependencies: Legal authority and frameworks; multi-language support; transparent model governance; high throughput.
- Personalized Learning at Scale (EdTech)
- Application: Cross-course, multi-episode tutors that connect concepts and retrieve precise explanatory segments; build structured knowledge graphs from video.
- Potential Tools/Products: Video-RAG hybrid with LongVideoAgent orchestration; memory for learner-specific gaps.
- Assumptions/Dependencies: Accurate ASR/subtitles; reliable OCR for slides; user modeling; bias/fairness considerations.
- Enterprise Knowledge Base Construction (Newsrooms, archives)
- Application: Automatic indexing of large video archives (news, interviews, debates) into searchable events, entities, and claims.
- Potential Tools/Products: Video knowledge graph builder; temporal grounding + vision OCR/NER; cross-video linking.
- Assumptions/Dependencies: Multi-language ASR; domain taxonomies; deduplication; provenance tracking.
- Home and Personal Video Assistants (Consumer)
- Application: Privacy-preserving agents that summarize and answer questions about home camera footage (e.g., “When did the package arrive?”).
- Potential Tools/Products: On-device or edge-deployed LongVideoAgent; selective grounding to minimize data movement.
- Assumptions/Dependencies: Strong privacy controls; compute on edge devices; robust detection in unconstrained environments.
- Jointly Trained Multi-Agent Stacks (Research/Engineering)
- Application: End-to-end optimization of MasterAgent, GroundingAgent, and VisionAgent to improve robustness and reduce tool-call overhead.
- Potential Tools/Products: Expanded rewards (temporal localization accuracy, tool-use efficiency); curriculum RL; self-play.
- Assumptions/Dependencies: Larger training corpora; reliable evaluation metrics beyond answer accuracy; careful reward design.
- Multimodal Video-RAG Integration (Software)
- Application: Retrieval-first pipelines that combine subtitle/audio retrieval with targeted vision reads for factual, grounded responses at scale.
- Potential Tools/Products: “Video-RAG + LongVideoAgent” hybrid stack; caching of visual observations; cost-aware retrieval policies.
- Assumptions/Dependencies: Efficient vector stores for video transcripts; scalable frame sampling; policy learning for retrieval vs. vision calls.
Collections
Sign up for free to add this paper to one or more collections.