Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding
Abstract: Long video understanding (LVU) is challenging because answering real-world queries often depends on sparse, temporally dispersed cues buried in hours of mostly redundant and irrelevant content. While agentic pipelines improve video reasoning capabilities, prevailing frameworks rely on a query-agnostic captioner to perceive video information, which wastes computation on irrelevant content and blurs fine-grained temporal and spatial information. Motivated by active perception theory, we argue that LVU agents should actively decide what, when, and where to observe, and continuously assess whether the current observation is sufficient to answer the query. We present Active Video Perception (AVP), an evidence-seeking framework that treats the video as an interactive environment and acquires compact, queryrelevant evidence directly from pixels. Concretely, AVP runs an iterative plan-observe-reflect process with MLLM agents. In each round, a planner proposes targeted video interactions, an observer executes them to extract time-stamped evidence, and a reflector evaluates the sufficiency of the evidence for the query, either halting with an answer or triggering further observation. Across five LVU benchmarks, AVP achieves highest performance with significant improvements. Notably, AVP outperforms the best agentic method by 5.7% in average accuracy while only requires 18.4% inference time and 12.4% input tokens.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping AI systems understand long videos better and faster. Instead of watching every second and writing long captions about it, the system picks the most useful parts to look at, like a detective searching for clues. The authors call this approach Active Video Perception (AVP). It helps the AI answer questions about long videos by actively deciding what to watch, when to watch it, and where to look in the video.
Goals or Research Questions
The paper tries to solve a simple problem:
- How can an AI answer detailed questions about long videos without wasting time watching unimportant parts?
More specifically:
- Can an AI figure out the right moments to watch in a long video based on the question?
- Can it stop early once it has enough proof to answer?
- Can doing this make the AI more accurate and much faster than current methods?
How It Works (Methods) — In Everyday Terms
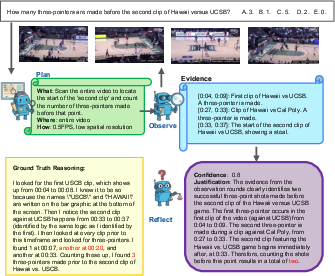
Think of a long video like a giant library. Most pages aren’t helpful for your question. AVP acts like a smart librarian that:
- Plans: Decides what clues to look for (what), which section of the video to check (where), and how carefully to watch it (how). For “how,” the system chooses:
- fps (frames per second) — like how quickly you flip through pages
- resolution — how detailed the picture is
- Observes: Watches only the chosen video parts and writes short “evidence notes” with time stamps (like “At 10:24–10:29, the coach enters the room”).
- Reflects: Checks if the evidence is enough to answer the question. If yes, it answers and stops. If not, it plans a smarter second round and looks again, possibly more carefully.
This “plan → observe → reflect” loop repeats a few times (usually up to three rounds) until the AI is confident enough to answer. Importantly, AVP gets evidence directly from the video frames (pixels), not just from text captions. That keeps small visual details and timing accurate.
Main Findings and Why They Matter
Here are the key results, explained simply:
- Better accuracy: AVP beats other “agentic” methods (AI systems that plan their steps) by around 5.7% on average across five long-video benchmarks. This means it gives the right answer more often.
- Much faster: On one big test, AVP took only about 18.4% of the time needed by a top competing method. That’s roughly 5.4× faster.
- Far less input: AVP used only about 12.4% of the “tokens” (think of tokens as the number of words, frames, or pieces of information the AI reads). Using fewer tokens makes processing cheaper and faster.
- Works with different AI models: AVP improved performance even when using lighter or stronger base AI models, showing it is flexible and robust.
Why this matters:
- Long videos are hard because the important clues are short and spread out. AVP focuses on just the right parts, saving time and keeping details correct.
- It reduces wasted work caused by “caption everything” methods, which often blur the fine timing and small visual cues needed to answer precise questions.
What This Could Change (Implications)
AVP could make video assistants smarter and more practical in the real world:
- For sports: Quickly find the exact moment a score changes or a key play happens.
- For movies/TV: Answer plot questions without scanning the whole film.
- For education: Help students and teachers search lectures for key moments.
- For safety and monitoring: Find important events faster and with better accuracy.
Because AVP watches the video more like a human—only the parts that matter—it can make AI video understanding both more reliable and much more efficient. In the future, this approach could be used in robots or tools that not only watch but also act in the real world, deciding what to observe while doing tasks.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of gaps and open questions that remain after this paper and can guide future research.
- Lack of calibrated stopping criteria: the Reflector’s confidence score is an uncalibrated scalar emitted by an MLLM. There is no analysis of calibration quality (e.g., ECE/Brier score), reliability under distribution shift, or methods to stabilize halting decisions (ensemble checks, self-consistency, verifier agents).
- Insufficient evaluation of grounding accuracy: AVP claims more precise temporal/spatial grounding but does not quantitatively evaluate timestamp correctness or spatial localization (e.g., temporal IoU, bounding-box tracking accuracy). A benchmark with ground-truth event times and spatial annotations is needed to measure the claimed gains.
- Ambiguity in “where” planning: “where” is implemented as a temporal window only; spatial focus is reduced to resolution choice without explicit cropping, ROI selection, or object-centric tracking. The system lacks mechanisms for learning/inferring spatial regions and evaluating their impact.
- Planning heuristics are hand-prompted, not learned: the Planner operates via prompts and heuristic priors (timestamps, “opening scene,” coarse sweeps). There is no learning of planning policies (e.g., RL, bandits, meta-learning) or analysis of how learned policies might outperform fixed prompting.
- No budget-aware or anytime planning: AVP sets static max rounds and token budgets. There is no principled budget allocation across rounds, no compute–accuracy trade-off curves, and no mechanism for adaptive exploration/exploitation under explicit resource constraints.
- Limited analysis of hyperparameter sensitivity: fps/resolution choices, confidence threshold (fixed at 0.7), and round limits (mostly 3) are not systematically stress-tested across datasets, query types, and video lengths. Guidance for robust defaults is missing.
- Evidence representation is textual only: “directly from pixels” still yields text descriptions; AVP does not store structured visual evidence (object tracks, event graphs, OCR strings, audio features) or uncertainty estimates. It is unclear whether richer, structured multimodal evidence would further improve reliability.
- No verification of evidence correctness: the system accumulates evidence as text but does not validate it against ground truth (when available) or independent tools (e.g., OCR for scoreboards, ASR for spoken cues), leaving open the risk of hallucinated or imprecise evidence.
- Audio/subtitle exclusion limits realism: AVP intentionally excludes subtitles and audio, yet many long-video queries hinge on dialogue or sound events. Open questions include how to integrate ASR, audio event detection, and subtitle retrieval in a query-adaptive manner.
- Fair-comparison concerns across baselines: several baselines use different backbones and sometimes subtitles. There is no apples-to-apples comparison with identical LLMs, toolsets, and input modalities, nor a standardized efficiency cost model (hardware, API latency, pricing).
- Runtime and token cost reproducibility: efficiency comparisons lack detailed hardware/API environment, batch settings, and rate limits. Repeatable measurement protocols (and dollar cost per video) are needed for deployment-oriented evaluation.
- Missing per-category error analysis: results are primarily aggregate accuracy. There is no breakdown by query types (e.g., temporal reasoning, identity tracking, counting, causal reasoning) to identify where AVP helps or fails and to guide targeted improvements.
- Robustness under challenging video conditions: no stress tests for occlusion, motion blur, small-object interactions, low light, camera motion, or extreme lengths. How AVP’s planner/observer adapts to noisy or degraded visual conditions is untested.
- Streaming and online scenarios: AVP assumes offline access to full videos. It does not address real-time streaming, partial observability, or scheduling under latency constraints—key for practical long-form video analytics.
- Multi-camera and multi-source inputs: the framework is validated on single-stream videos. Open questions include planning and evidence fusion across multiple synchronized feeds (e.g., sports, surveillance).
- Failure mode characterization is limited: beyond a single qualitative example, there is no systematic catalog of failure modes (missed evidence, mis-localization, premature halting) or mitigation strategies (backtracking, counterfactual checks).
- Halting-on-max-rounds without abstention: the system “forces” an answer at the last round. There is no abstain/fallback mechanism and no evaluation of the cost of forced guesses versus safe non-answers.
- Tool integration is minimal: unlike visual programming approaches, AVP relies almost exclusively on the MLLM. It remains unexplored how specialized tools (detectors, trackers, OCR, face recognition, ASR, shot segmentation) could be called adaptively by the Planner to improve precision and efficiency.
- Generalization beyond MCQ QA: all evaluations use multiple-choice QA. Open-ended QA, summarization, temporal grounding tasks, and retrieval are not tested; it is unclear whether AVP’s gains transfer to non-MCQ settings.
- Memory design and compression: the evidence list grows across rounds but is textual and unstructured. How to compress, index, and re-use evidence across videos or sessions (e.g., deep memory, event graphs) remains open.
- Model selection policy: ablations show performance depends on component strength (Planner/Observer/Reflector) but offer no automatic policy to select models per query or per video (e.g., routing weaker vs stronger backbones by estimated difficulty).
- Data/benchmark coverage: the five benchmarks skew toward English content and specific genres. Cross-lingual, domain-specific (medical, industrial), and highly specialized tasks remain untested, raising questions about AVP’s generalization.
- Security and adversarial robustness: no analysis of adversarial prompts, spurious correlations, or targeted attacks on the confidence estimation and evidence extraction, nor countermeasures (verification agents, cross-model agreement).
- Theoretical foundations: while motivated by active perception, there is no formal treatment of AVP as a decision process (state, actions, rewards), no optimality analysis, and no bounds on sample efficiency or search error in long videos.
- Code, prompts, and artifacts: prompts and implementation details are said to be in the appendix, but a complete, open-source release (with evaluation scripts, logs, and seeds) is needed to ensure full reproducibility and facilitate community benchmarking.
Practical Applications
Overview
Below are practical applications of the paper’s Active Video Perception (AVP) framework, organized by when they can be deployed. Each item includes a specific use case, sector tie-in, tangible tools/products/workflows that could emerge, and the assumptions or dependencies that could affect feasibility.
Immediate Applications
- Media and Entertainment: Ask-anything assistants for long-form video libraries
- Use case: Interactive Q&A over movies, series, and documentaries (e.g., “When does character X enter the lab the second time?”; “Which scenes show the brand logo before halftime?”).
- Tools/products/workflows: AVP-powered “Evidence-Seeking Video QA” service; a plugin for streaming platforms that provides time-stamped answers and navigable evidence logs; coarse-to-fine scanning (low FPS/resolution then targeted re-scan) to minimize compute.
- Assumptions/dependencies: Access to raw video streams; licensing/rights for automated analysis; MLLM availability and cost; minimal domain-specific prompts to recognize plot cues and on-screen text; governance for user privacy.
- Advertising and Sponsorship Analytics: Brand exposure and ad verification
- Use case: Verify sponsor placements, on-screen durations, and compliance claims across hours of broadcast footage; identify misplacements or missed obligations.
- Tools/products/workflows: AVP “Ad Verification Engine” that produces time-stamped exposure evidence, billing-ready reports, and automatic alerting for missed assets; integration with existing media measurement dashboards.
- Assumptions/dependencies: High-quality frames for fine-grained logo detection; integration with brand/icon libraries; potentially a specialized visual detector for logos layered into AVP’s observer.
- Sports Analytics and Highlight Generation
- Use case: Detect event moments (goals, substitutions, scoreboard changes, key plays) across entire matches and create highlight reels; answer precise user queries (“When did the second yellow card appear?”).
- Tools/products/workflows: Near-real-time AVP pipelines attached to broadcast feeds; targeted resampling around scoreboard overlays; an “Evidence Timeline” that editors can drop into highlight workflows or dashboards.
- Assumptions/dependencies: Stable broadcast layouts; permissions to process live feeds; moderate GPU resources; tuned prompts for sports contexts and overlay recognition.
- Security and Operational Compliance (CCTV/Industrial Video)
- Use case: Query long surveillance footage for PPE compliance, restricted-area entries, or anomalous events without captioning all frames (“Were hard hats worn between 3–4 pm?”).
- Tools/products/workflows: AVP “Compliance Auditor” with adaptive sampling that produces time-stamped segments and confidence scores; human-in-the-loop review queue; auditable evidence histories for internal audits.
- Assumptions/dependencies: Camera positioning and lighting; site-specific policies; privacy and local regulations; robust organizational approval for automated monitoring.
- Enterprise Productivity: Meeting and Training Video Q&A
- Use case: Find decisions, action items, and key moments in long internal videos; quickly answer (“When did the team agree to ship v2?”; “At what slide did the pricing change?”).
- Tools/products/workflows: AVP plugin for meeting platforms/LMS with searchable, time-stamped evidence; workflow that begins with coarse sweep and then re-scans suspected segments at higher resolution; exportable audit trails.
- Assumptions/dependencies: Access to recordings; sometimes strong reliance on visual cues (slides, on-screen text); potential need for audio/subtitle integration for best results.
- Legal and E-Discovery: Targeted evidence retrieval from long recordings
- Use case: Review bodycam footage, depositions, or surveillance videos; find critical sequences with transparent, time-stamped evidence logs for chain-of-custody compliance.
- Tools/products/workflows: AVP “Evidence Log Generator” creating verifiable time-stamped excerpts and justifications; early stopping when confidence thresholds are met; defensible audit trails for court submission.
- Assumptions/dependencies: Legal admissibility standards; strict documentation of processing steps; human oversight; secure storage and data governance.
- Video Editing and Post-Production: Precision shot-finding in large bins
- Use case: Editors search hours of dailies for specific spatial-temporal cues (“Find all shots where the actor enters from the left after minute 10 and the lamp is lit”).
- Tools/products/workflows: AVP extension for NLEs to return time-stamped candidate shots; iterative re-planning to refine ambiguous matches; batch processing with saved evidence lists.
- Assumptions/dependencies: Integration with editing suites; high-resolution sampling when needed; tuned prompts for production-specific terminology.
- Education: Long lecture and MOOC navigation
- Use case: Students and instructors query hours-long lectures for specific content (“Where is the first derivation of theorem X?”; “Find the section where the professor defines the loss function.”).
- Tools/products/workflows: AVP “Lecture Assistant” embedded in LMS with time-stamped answers and jump-to segments; coarse-to-fine scanning to minimize cost across large catalogues.
- Assumptions/dependencies: Clear visual cues (slides, handwritten boards); possible integration with text/subtitles for maximal reliability; institutional privacy policies.
- Consumer Daily Life: Personal video archive and home camera search
- Use case: Query home security footage (“When did the delivery arrive?”; “Show when the dog entered the kitchen”) or personal videos (“Find the first time the baby walks in this 2-hour video”).
- Tools/products/workflows: Mobile/desktop app offering AVP-based on-demand search; local-only processing modes to reduce privacy exposure; concise evidence summaries.
- Assumptions/dependencies: On-device or private-cloud compute; storage bandwidth; user consent and privacy controls.
- Software/Data Platforms: Cost-efficient video QA pipelines
- Use case: Replace query-agnostic captioning with targeted evidence seeking to cut inference time and tokens while improving accuracy.
- Tools/products/workflows: AVP microservice/API with plan–observe–reflect orchestration; configurable confidence thresholds; metrics that quantify speedups (e.g., 81.6% time reduction and 87.6% token reduction vs. caption-heavy pipelines, based on reported LVBench comparisons).
- Assumptions/dependencies: Access to an MLLM with robust video inputs (e.g., Gemini 2.5 family or open-source equivalents); careful prompt design; observability for performance/QoS.
Long-Term Applications
- Embodied Robotics: Active perception for agents that must act while seeking evidence
- Use case: Robots selectively observe environments (what/where/how) to find task-critical cues (tools, safety markers) while planning next actions.
- Tools/products/workflows: AVP integrated with robot control stacks to co-schedule observation and action; real-time evidence sufficiency checks; adaptive granularity to conserve onboard compute.
- Assumptions/dependencies: Real-time constraints; safety certifications; robust sensor fusion; domain-specific training/fine-tuning for reliability.
- Autonomous Vehicles and Drones: Resource-aware, targeted visual sensing
- Use case: Active sampling under bandwidth and compute limits; refine attention to subtle cues (sign states, rare obstacles) only when needed.
- Tools/products/workflows: AVP “Sensor Budget Manager” that dynamically adjusts frame rates/resolution and revisits uncertain moments; evidence logs that support incident analysis and explainability.
- Assumptions/dependencies: Low-latency inference on edge hardware; extreme reliability standards; integration with perception stacks and regulators’ safety requirements.
- Live Broadcast-Scale Monitoring and Fact-Checking
- Use case: Track compliance, claims, and content policies across many concurrent streams (news, sports, entertainment) with time-stamped evidence for transparency reports.
- Tools/products/workflows: Clustered AVP “Monitoring Control Plane” that schedules coarse passes and targeted re-scans across channels; automated compliance dashboards and audit trails for regulators and platforms.
- Assumptions/dependencies: Scaling across heterogeneous feeds; cost control; policy harmonization and legal frameworks; robust failure handling.
- Clinical and Surgical Assistance (real-time support)
- Use case: Flag procedural steps, anomalies, and safety events in live surgical/endoscopy videos; support targeted re-inspection and checklists.
- Tools/products/workflows: AVP “OR Assistant” operating under strict confidence thresholds, with just-in-time evidence prompts for staff; replayable time-stamped segments for post-op review and training.
- Assumptions/dependencies: Regulatory approvals (FDA/CE), validated clinical performance, human oversight, data privacy, integration with hospital IT and devices.
- Industrial Inspection (Energy, Utilities, Manufacturing)
- Use case: Drones/robots inspect infrastructure (pipelines, wind turbines) and selectively zoom or revisit suspicious regions; generate actionable evidence for maintenance.
- Tools/products/workflows: AVP-guided inspection routes that alternate coarse scanning with targeted re-sampling; unified evidence reports with confidence scores for engineers.
- Assumptions/dependencies: Harsh environment robustness; integration with flight/control software; coverage planning; safety and regulatory compliance.
- Policy and Governance: Auditable AI evidence standards for video
- Use case: Standardized “Evidence Log” formats (timestamps, confidence, rationales) for content moderation and automated compliance decision-making.
- Tools/products/workflows: AVP-based “AI Audit Pack” that produces transparent, reproducible evidence trails; dashboards for regulators to review automated decisions.
- Assumptions/dependencies: Policy acceptance of automated evidence; standardized schemas across vendors; legal due process and appeals; data retention policies.
- Edge and On-Camera Processing: Energy-aware active perception
- Use case: Reduce energy and bandwidth by actively deciding when/where/how to process frames at the camera; stream only relevant snippets.
- Tools/products/workflows: AVP “Edge Runtime” with adaptive sampling profiles; on-device early stopping when confidence is sufficient; privacy-preserving local processing.
- Assumptions/dependencies: Efficient edge hardware; model compression; secure update channels; robust performance under varying lighting and motion.
- Multimodal Knowledge Graphs and Retrieval-Augmented Systems
- Use case: Build time-aligned, query-relevant video evidence bases that improve long-horizon reasoning and RAG workflows; link video facts to text corpora.
- Tools/products/workflows: AVP-driven “Evidence Builder” that populates structured nodes with time-stamped visual events; APIs for downstream LLM reasoning with verified video support.
- Assumptions/dependencies: Stable schemas; synchronization with textual sources; governance over provenance and updates; storage and indexing costs.
- Personalized Lifelogging Assistants
- Use case: Curate decades of personal videos with active evidence seeking; answer detailed queries about life events with grounded, time-stamped clips.
- Tools/products/workflows: AVP “Personal Memory” service with local-first processing; granular privacy controls; periodic coarse scans and targeted re-analysis for new queries.
- Assumptions/dependencies: Strong privacy/security; opt-in consent; scalable storage and compute; dependable on-device MLLM performance.
- Standardization and Certification of Active Perception Pipelines
- Use case: Industry-wide best practices for plan–observe–reflect loops, confidence thresholds, and evidence sufficiency for safety-critical domains.
- Tools/products/workflows: AVP-inspired certification criteria, benchmarking suites, and test harnesses applicable across sectors (robotics, healthcare, transportation).
- Assumptions/dependencies: Community consensus; participation from regulators and standards bodies; long-term validation and red-teaming.
Glossary
- Active perception: A paradigm where an agent deliberately chooses what, when, and how to sense to achieve a specific perceptual goal. "Active perception theory \citep{bajcsy1988active,aloimonos2013active, bajcsy2016revisitingactiveperception} formalizes this behavior: ``An agent is an active perceiver if it knows why it wishes to sense, and then chooses what to perceive, and determines how, when and where to achieve that perception''."
- Active Video Perception (AVP): The paper’s proposed agentic, iterative framework for long video understanding that actively seeks compact, query-relevant evidence. "We present Active Video Perception (AVP), an evidence-seeking framework that treats the video as an interactive environment and acquires compact, query-relevant evidence directly from pixels."
- Agentic framework: A system design that empowers an agent to plan, act, and reflect over an environment (here, a video) to solve queries. "These limitations underscore the need for an agentic framework that adaptively focuses on informative video regions, seeks query-related evidence directly over video pixels while maintaining high efficiency."
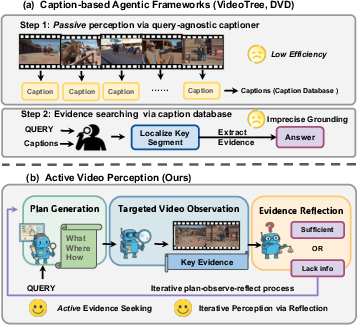
- Caption-based framework: An approach that converts video content into text captions as the primary interface for LLM reasoning and tool calling. "This caption-based framework leverages LLMsâ strengths in text processing but introduces two inherent limitations:"
- Captioner–LLM design: A pipeline where video segments are first captioned and then an LLM uses those captions to answer queries. "To decouple the complex LVU task, early agentic frameworks \citep{kahatapitiya-etal-2025-language, park2025framesusefulefficientstrategies, wang2024videotree,zhang2023simple,zhang2025silvrsimplelanguagebasedvideo,ma2024drvideodocumentretrievalbased, wang2025videochata1thinkinglongvideos,fan2025agentickeyframesearchvideo,jeoung2024adaptivevideounderstandingagent} adopt a captionerâLLM design: video segments are converted into captions, which an LLM then uses the generated caption to answer the video query."
- Causal tracing: The process of tracking cause–effect relations across events; can be weakened by imprecise temporal/spatial localization. "Existing approaches use captions to localize key events, which may discard fine-grained temporal and spatial cues and weaken causal tracing."
- Chain-of-thoughts (CoT): A reasoning strategy that unfolds step-by-step explanations; extended here to multimodal video reasoning. "Recently, inspired by the great success of DeekSeek-R1~\citep{deepseekai2025deepseekr1incentivizingreasoningcapability}, several works ~\citep{feng2025video, wang2025videorftincentivizingvideoreasoning, wang-etal-2025-video, wang2025timezero} explore the Chain-of-thoughts video reasoning model."
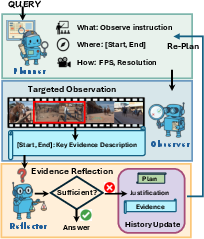
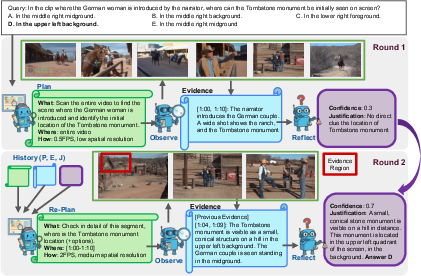
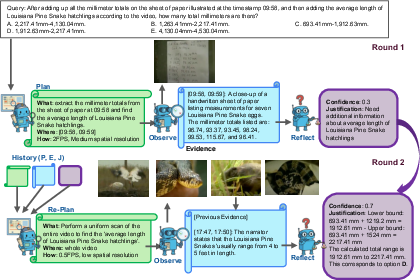
- Closed-loop: A feedback cycle where planning, observation, and reflection iterate until sufficient evidence is gathered. "This closed-loop process enables AVP to progressively refine its focus, revisit uncertain moments, and allocate computation adaptively, leading to more efficient processing and reliable reasoning on long, complex videos."
- Coarse-to-fine: A strategy that begins with low-cost, low-detail inspection and progressively increases detail where needed. "previous work mainly follows a coarse-to-fine schema with fixed FPS/resolution setup, instead, AVP decides what/where/how to observe the video based on the query;"
- Confidence threshold: A numeric cutoff determining when gathered evidence is sufficient to stop and answer. "If the confidence is higher than the confidence threshold $\tau_{\text{conf}$, the Reflector directly extracts the final answer from ; otherwise, the justification highlights missing or uncertain cues to guide the next round of planning step."
- Evidence sufficiency: The extent to which accumulated evidence supports answering the query. "and continuously assess whether the current observation is sufficient to answer the query."
- Evidence seeking framework: An approach that purposefully acquires compact, relevant evidence rather than passively processing entire inputs. "we propose Active Video Perception (AVP), an agentic evidence seeking framework for long video understanding."
- Goal-conditioned observations: Targeted observations whose scope and granularity are driven by the query’s objective. "AVP attains higher accuracy while using substantially less compute by formulating LVU as goal-conditioned observations."
- Granularity (sampling granularity): The level of detail (e.g., FPS and spatial resolution) used when sampling video for observation. "how specifies sampling granularity for the long video observation, where ."
- Interactive environment: Treating the video as an environment the agent can actively explore via planned interactions. "treats the video as an interactive environment and acquires compact, query-relevant evidence directly from pixels."
- Iterative plan–observe–reflect: The repeated cycle of planning targeted observations, executing them, and reflecting on sufficiency. "AVP runs an iterative planâobserveâreflect process with MLLM agents."
- Long-horizon queries: Questions that depend on events dispersed over extended time spans in long videos. "ultimately improving both efficiency and reliability on complex long-horizon queries."
- Long video understanding (LVU): The task of reasoning over extended-duration videos with sparse, temporally dispersed cues. "Long video understanding (LVU) is challenging because answering real-world queries often depends on sparse, temporally dispersed cues buried in hours of mostly redundant and irrelevant content."
- MediaResolution: A model-specific resolution setting that determines spatial tokenization per frame. "For spatial token setup (spatial_res), we follow Gemini's MediaResolution setup to have 2 scale (low, medium, high), while low and medium is $66$ and $258$ tokens per frame, respectively."
- Memory backtracking: A mechanism to revisit earlier stored evidence during multi-step reasoning. "VideoLucy~\cite{zuo2025videolucydeepmemorybacktracking}introduces a memory backtracking mechanism that allows the model to revisit earlier multi-scale text captions during multi-step reasoning."
- Multimodal LLMs (MLLMs): LLMs that process multiple modalities (e.g., text, images, video) for recognition and reasoning. "Although recent multimodal LLMs (MLLMs) \citep{comanici2025gemini25pushingfrontier, openai2025gpt5, Qwen2.5-VL, wang2025internvl3_5, guo2025seed15vltechnicalreport, li2023blip2, pmlr-v162-li22n,li2025ariaopenmultimodalnative} substantially improve visual recognition,"
- Query-agnostic captioner: A captioning tool that summarizes video regardless of the specific query, often producing irrelevant text. "prevailing frameworks rely on a query-agnostic captioner to perceive video information, which wastes computation on irrelevant content and blurs fine-grained temporal and spatial information."
- Spatial resolution: The per-frame spatial detail level used in sampling, affecting token count and visual fidelity. "how=(fps,\ spatial_res)"
- Temporal region: A specific time interval in the video targeted for inspection. "where is a targeted temporal region ."
- Time-stamped evidence: Observations annotated with start and end times to support grounded reasoning. "an observer executes them to extract time-stamped evidence,"
- Tool-based search: Using external tools to retrieve or refine evidence during multi-step video reasoning. "Deep Video Discovery~\cite{zhang2025deepvideodiscoveryagentic} uses tool-based search to iteratively refine textual evidence over long videos."
- Video tokens: Tokenized representations of video content fed into models; often many are redundant. "most video tokens are redundant, while the brief, localized evidence that actually matters is diluted or overlooked in the long sequence."
- Visual grounding: Precise alignment of textual claims with their spatial and temporal locations in video. "leading to low efficiency and imprecise visual grounding."
- Visual programming: Decomposing complex queries into substeps and orchestrating specialized modules to solve them. "several works~\citep{liu2025videomind, min2025morevqaexploringmodularreasoning, fan2024videoagentmemoryaugmentedmultimodalagent, menon2025caviarcriticaugmentedvideoagentic, kugo2025videomultiagentsmultiagentframeworkvideo,shi2025enhancingvideollmreasoningagentofthoughts,zhu2025activeo3empoweringmultimodallarge} utilize the idea of ``visual programming'', decompose the complex query into multiple steps to leverage expert modules."
- Working memory: The accumulated evidence store used across rounds to inform reflection and re-planning. "This cumulative evidence list serves as the working memory of AVP,"
Collections
Sign up for free to add this paper to one or more collections.