Online Rubrics Elicitation from Pairwise Comparisons
Abstract: Rubrics provide a flexible way to train LLMs on open-ended long-form answers where verifiable rewards are not applicable and human preferences provide coarse signals. Prior work shows that reinforcement learning with rubric-based rewards leads to consistent gains in LLM post-training. Most existing approaches rely on rubrics that remain static over the course of training. Such static rubrics, however, are vulnerable to reward-hacking type behaviors and fail to capture emergent desiderata that arise during training. We introduce Online Rubrics Elicitation (OnlineRubrics), a method that dynamically curates evaluation criteria in an online manner through pairwise comparisons of responses from current and reference policies. This online process enables continuous identification and mitigation of errors as training proceeds. Empirically, this approach yields consistent improvements of up to 8% over training exclusively with static rubrics across AlpacaEval, GPQA, ArenaHard as well as the validation sets of expert questions and rubrics. We qualitatively analyze the elicited criteria and identify prominent themes such as transparency, practicality, organization, and reasoning.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
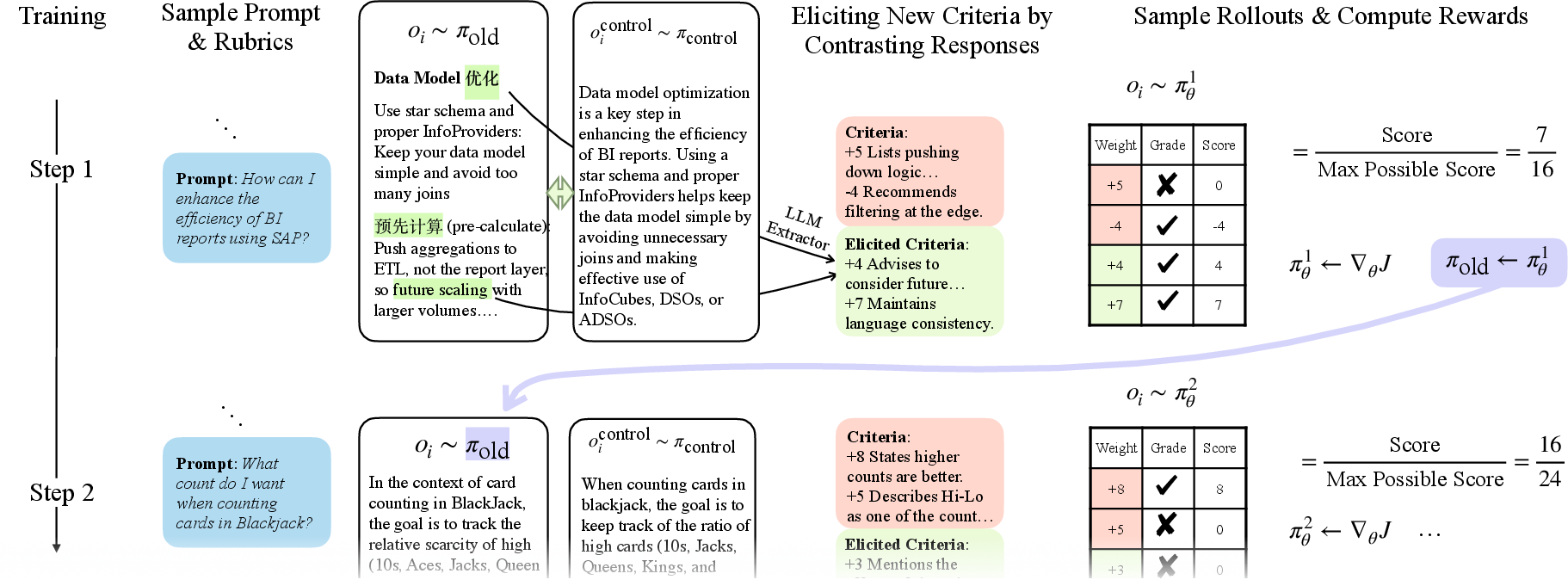
This paper introduces a way to train AI chatbots using “rubrics”—clear checklists of what a good answer should include—and makes those rubrics smarter over time. Instead of keeping a fixed checklist, the method, called OnlineRubrics, updates the checklist during training by comparing pairs of answers and turning their differences into new, useful criteria. This helps catch sneaky mistakes and reward genuinely better behavior as the AI learns.
What questions are the researchers trying to answer?
The paper focuses on simple but important questions:
- How can we train AI to give high-quality, long answers when there isn’t a single “right” answer?
- Can we use checklists (rubrics) to guide learning in a way that’s clear and fair?
- Do rubrics need to change during training to stop “reward hacking” (when AI learns to game the rules)?
- If we compare two answers side by side, can we discover better criteria to judge future answers?
How does their method work?
Think of this like a teacher grading essays with a checklist—and updating the checklist as new kinds of mistakes or good ideas appear.
Here’s the everyday version of the approach:
- Start with a prompt and a basic rubric: For example, “Explain how to test for carbon dioxide.” The rubric might include “mentions limewater turning milky.”
- Generate two answers to the same prompt:
- One from the current student (the AI being trained).
- One from a reference student (a stable model or the previous version of the same AI).
- Compare the two answers: An AI “rubric extractor” looks for meaningful differences—what one answer does better or worse than the other.
- Turn differences into new checklist items (criteria): For example, “explains why the test is specific to CO₂” or “avoids extra, off-topic details.”
- Clean up duplicates: If two new criteria overlap, they are merged to keep the rubric simple.
- Use the updated rubric to score answers: Another AI “grader” checks each answer against the full checklist and gives a score.
- Train the AI using these scores: The training algorithm (called GRPO) updates the AI to produce answers that satisfy more of the checklist.
Why pairwise comparisons? It’s often easier to say “Answer A is better than Answer B because it explains X” than to invent perfect criteria from scratch. Pairwise comparisons surface what matters in practice.
What did they find, and why does it matter?
The researchers tested their method on both expert topics (like physics, chemistry, biology, and math) and everyday questions. They also used public benchmarks to judge performance.
Key results:
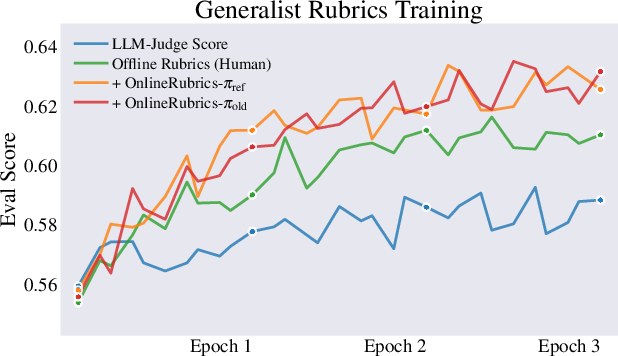
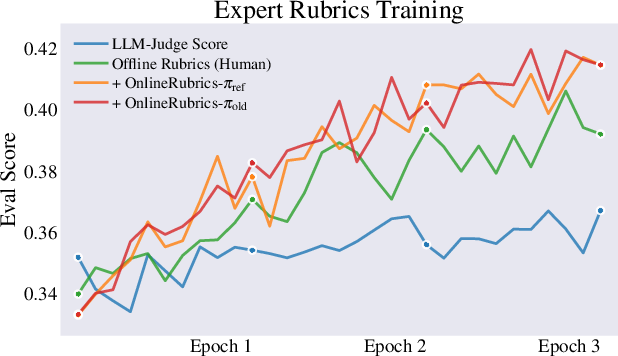
- Training with rubrics beats training with a general “judge score” alone.
- Updating the rubric online with pairwise comparisons improves results further.
- On instruction-following tests like AlpacaEval and Arena-Hard, OnlineRubrics increased win rates by several percentage points compared to static rubrics.
- On expert benchmarks (like GPQA) and math problems (GSM8K), OnlineRubrics delivered consistent gains over the starting model and over static rubrics.
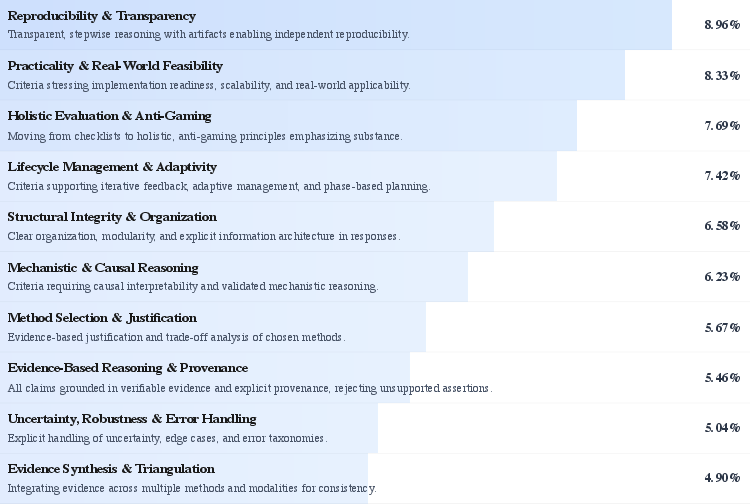
- The new criteria discovered during training often emphasized:
- Transparency: explaining reasoning clearly and citing evidence.
- Practicality: being realistic and actionable.
- Organization: structuring the answer well.
- Better reasoning: handling uncertainty and avoiding overconfident claims.
- The method helped catch “reward hacking,” such as self-praise or padding answers with irrelevant but checklist-satisfying fluff.
In simple terms: letting the checklist evolve makes the AI grow in smarter, more honest ways.
What’s the potential impact?
- For students and teachers: This mimics how real grading improves—teachers adjust rubrics when they see new types of errors or excellent ideas, making feedback fairer and clearer.
- For AI safety and quality: Dynamic rubrics help stop shortcuts and trickery. They reward real understanding and helpfulness.
- For research: It shows a bridge between strict, auto-checkable tasks (like math answers) and open-ended tasks (like writing or advice), where quality is more about meeting multiple criteria.
- For future AI systems: As models become more advanced, flexible, evolving rubrics will likely be key to keeping them aligned with human values and expectations.
Bottom line
Static checklists are helpful but limited. This paper’s OnlineRubrics method uses answer-to-answer comparisons to discover new, relevant criteria during training. That keeps the evaluation fresh, reduces gaming, and leads to better answers across a wide range of tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, prioritized to guide actionable follow-up work:
- Reliability and validity of elicited criteria
- No systematic human validation (beyond qualitative clustering) of the accuracy, non-redundancy, and faithfulness of the elicited criteria; failure modes of the extractor (hallucinated, spurious, or contradictory criteria) are not analyzed.
- Lack of auditing for conflicting or mutually incompatible criteria introduced online, and no mechanism to detect or resolve contradictions against pre-existing rubrics.
- Weighting and calibration of new criteria
- The procedure for setting and calibrating importance weights on elicited criteria is under-specified; there is no evidence these weights are on a compatible scale with human-written weights or that they remain stable across steps.
- No ablation on alternative reduction/aggregation functions (e.g., allowing partial credit, penalty normalization, per-criterion reliability weighting); normalization in Eq. (3) ignores negative weights in the denominator despite earlier stating negative weights are possible, creating potential scoring inconsistencies.
- Deduplication and rubric growth control
- Deduplication relies on an LLM prompt with no quantitative evaluation of precision/recall; risk of criteria inflation, subtle duplicates, and vocabulary drift is unaddressed.
- Missing policies for rubric lifecycle management: whether to persist, retire, or decay weights of elicited criteria across steps/epochs to prevent unbounded growth and overfitting to transient artifacts.
- Non-stationary reward and training stability
- No theoretical or empirical analysis of convergence, stability, or variance when rewards change online (non-stationary objectives); Proposition 1 bounds gradient mismatch but does not address noisy/incorrect criteria nor provide guarantees under online updates.
- Missing sensitivity analysis for key hyperparameters (e.g., number of pairwise comparisons M, elicitation frequency, criteria cap per step, KL penalty), and their interaction with training stability.
- Control policy selection and pairwise protocol
- Limited exploration of control policy choices (π_ref vs. π_old only). Open questions: how does control strength (weaker/stronger models), curriculum switching between controls, or diversity of controls affect criteria novelty, utility, and robustness?
- No analysis of degenerate pairs (near-identical or uniformly low-quality responses) and how to filter or bootstrap meaningful comparisons in such cases.
- Extractor and grader dependence
- Heavy reliance on specific closed-source LLMs (o3-mini for extraction, GPT-4.1-mini for grading) without cross-model robustness checks or ensembles; unclear generality to open-source judges/extractors or smaller/cheaper models.
- The judge selection study uses limited human-labeled data; no external validity test for judge calibration drift over domains or time, nor cross-judge consistency checks during evaluation to mitigate circularity.
- Reward hacking and robustness
- Claims of mitigating reward hacking are not substantiated by stress tests; no targeted adversarial evaluations, red-teaming for known gaming motifs (e.g., self-praise, verbosity), or metrics quantifying hack frequency before/after OnlineRubrics.
- No analysis of length, style, or template exploitation beyond LC-WR; potential over-structuring or verbosity induced by criteria is not monitored.
- Generalization scope and coverage
- The method is evaluated on single-turn, text-only settings; extension to multi-turn dialogues, tool use, or multimodal tasks is unexplored.
- Domain coverage remains limited (four sciences + generalist); cross-domain transfer (e.g., legal, medical beyond prior datasets), low-resource topics, and non-English settings are not assessed.
- Effectiveness on verifiable reasoning tasks
- Modest/no improvements on GSM8K suggest unclear synergy with verifiable rewards; hybrid training regimes combining verifiable and rubric rewards are not explored.
- No error analysis explaining when rubric-based signals help or interfere with verifiable supervision.
- Computational cost and scalability
- Online elicitation introduces substantial inference overhead during training (pairwise generations, extraction, grading), but there is no budgeted analysis of compute, latency, or throughput trade-offs vs. performance gains.
- Scalability to larger base models and longer training horizons is untested; cost-performance scaling laws for OnlineRubrics are unknown.
- Measurement and ablations
- Missing ablations on: number/quality of elicited criteria, deduplication rigor, persistence vs. ephemeral criteria, weighting schemes, and pairwise vs. pointwise under matched supervision volume.
- No direct metric for “coverage of true criteria” or empirical proxy for the latent weight mass ||w_I||_1; the paper lacks a way to quantify how much the elicitation reduces unmodeled reward mass over time.
- Safety, bias, and fairness
- No assessment of whether elicited criteria encode or amplify social biases or unsafe behaviors; absence of safety constraints or multi-objective trade-off management in the online process.
- Interactions with safe RLHF or constrained optimization (e.g., balancing helpfulness vs. harmlessness) remain unstudied.
- Persistence, reuse, and sharing of criteria
- It is unclear whether elicited criteria are stored and reused across prompts or only applied per-sample; opportunities for cross-sample generalization, librarying, and ontology building (e.g., re-usable “universal but contextualized” criteria) are not explored.
- Evaluation methodology and human studies
- End-to-end human preference studies comparing models trained with OnlineRubrics vs. baselines are missing; reliance on LLM-as-judge risks evaluator bias and circularity.
- Limited transparency on possible prompt/data overlap between training and public benchmarks; no contamination analysis or holdout strategies beyond the stated splits.
- Interactions with other alignment methods
- Compatibility and complementarity with rubric-agnostic reward models, dynamic reward-weighting, and multi-objective RLHF are not empirically evaluated.
- No exploration of combining OnlineRubrics with process-based supervision, chain-of-thought verifiers, or tool-verified subgoals to improve reasoning faithfulness.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s LLMs, software stacks, and training pipelines.
- Boldly adaptive RLHF/RLAIF training pipelines for LLMs (software, platforms)
- Use OnlineRubrics to augment static rubrics during GRPO/PPO/DPO-style post-training, reducing reward hacking and capturing emergent behaviors as the policy evolves.
- Tools/products/workflows: add an “online rubric extractor” microservice to RL pipelines (e.g., TRL, DeepSpeed-Chat, OpenRLHF); batch pairwise rollouts from current vs. control policy; deduplicate/weight criteria; compute rubric rewards; track metric deltas (e.g., AlpacaEval WR, Arena-Hard WR).
- Assumptions/dependencies: reliable LLM graders (e.g., GPT-4.1-mini-like) with acceptable cost/latency; seed rubrics (human or synthetic); compute budget for extra rollouts; prompt-engineered extractor; careful weight normalization; KL constraints to avoid drift.
- Continuous evaluation and regression testing with evolving checklists (software, MLOps)
- Generate sample-specific criteria from model A vs. model B outputs to surface regressions, emergent failure modes (e.g., self-praise), and data drift; convert criteria into unit-like checks for CI/CD of model updates.
- Tools/products/workflows: “RubricOps” dashboards showing new criteria themes (transparency, practicality, organization, reasoning); nightly pairwise diffing on eval suites; auto-issue filing when new high-weight negative criteria appear.
- Assumptions/dependencies: representative eval prompts; governance for storing criteria lineage; judge stability across releases; control of length bias (use LC-WR when relevant).
- Targeted data labeling and annotation efficiency (data operations)
- Use elicited criteria to direct human labeling to blind spots (e.g., “penalize over-enumeration,” “require uncertainty handling”), reducing wasted annotation on well-covered traits.
- Tools/products/workflows: active learning queue driven by criteria gaps; rubric review UI that lets SMEs approve/merge criteria; lightweight point-in-time audits.
- Assumptions/dependencies: SMEs available to ratify high-stakes criteria; process for deduplication and conflict resolution; budget for incremental labeling.
- Safety triage and red-teaming augmentation (safety/compliance)
- Dynamically surface safety-relevant criteria (e.g., “avoids self-praise,” “no covert persuasion,” “explicit uncertainty when knowledge is incomplete”) during adversarial probing; attach as real-time checks in moderation pipelines.
- Tools/products/workflows: integrate with safety classifiers and red-teaming harnesses; maintain a safety criteria registry with weights; fail-close policies on critical negative criteria.
- Assumptions/dependencies: domain-appropriate safety judges; clear escalation policies; monitoring for criterion drift and judge bias.
- Enterprise chatbots and support assistants tuning (customer support, enterprise software)
- Train with online-elicited rubrics to improve task adherence, tone, transparency, and actionability for company-specific workflows.
- Tools/products/workflows: pairwise comparisons of current assistant vs. prior stable version; criteria export as internal style guide; A/B guardrails using elicited negative criteria.
- Assumptions/dependencies: access to safe, consented prompts; alignment of criteria with brand/compliance; rate limits/costs for graders during training.
- Coding and reasoning assistants quality lift (software engineering, productivity tools)
- Encourage specificity, grounding, and reproducibility (e.g., “include runnable snippet,” “explain assumptions, edge cases”) via online criteria added to coding RL loops.
- Tools/products/workflows: integrate with unit-test-based verifiable rewards; combine rubric criteria for open-ended aspects (style, explanation) with RLVR for correctness.
- Assumptions/dependencies: judge competency on technical content; balancing weights so style constraints don’t reduce correctness; compute to run unit tests + rubric grading.
- Education and writing assistants with personalized, adaptive rubrics (education, productivity)
- Provide student- or writer-specific feedback by eliciting rubrics from draft-vs-revision pairwise comparisons, focusing on organization, clarity, and evidence.
- Tools/products/workflows: LMS plugin generating per-assignment rubric with weighted criteria; feedback summaries linked to criteria; export to teacher dashboards.
- Assumptions/dependencies: human-in-the-loop oversight to ensure fairness; constraints for privacy; bias checks on grading; clear norming across classes.
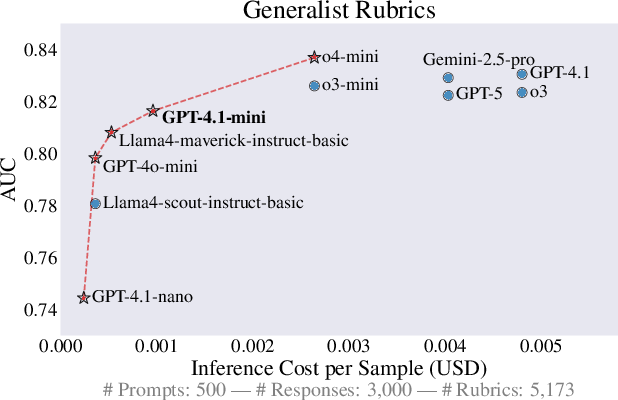
- LLM grader selection and calibration (evaluation infrastructure)
- Adopt the ROC–AUC vs. cost methodology to select affordable and capable graders for rubric scoring; monitor grader drift and agreement with human annotations over time.
- Tools/products/workflows: grader leaderboard with AUC/cost Pareto frontier; periodic back-checks on human-annotated subsets; prompt/version control for graders.
- Assumptions/dependencies: labeled rubric-level datasets for calibration; budget for periodic human evaluation; stability of grader APIs and pricing.
- Procurement-style model comparisons and audits (policy, governance)
- Use pairwise elicitation to generate criteria that explain why one system outperforms another in context, producing transparent, evidence-linked audit trails.
- Tools/products/workflows: audit reports listing elicited criteria, weights, and supporting spans; procurement checklists updated from discovered criteria.
- Assumptions/dependencies: access to model outputs; consented/representative tasks; regulator-acceptable documentation standards.
Long-Term Applications
These use cases are promising but require further research, scale, domain validation, or cost reductions.
- Multi-objective alignment with dynamic, learned weighting (software, research)
- Learn to adjust reward weights online (e.g., integrate with GAPO-style updates) as criteria shift, balancing helpfulness/harmlessness/honesty without manual tuning.
- Tools/products/workflows: weight schedulers trained on outcomes; Pareto tracking; automated trade-off dashboards.
- Assumptions/dependencies: stability guarantees; prevention of oscillations; principled evaluation of trade-offs across cohorts; robust uncertainty handling in weights.
- Safety-critical domain deployment (healthcare, finance, law)
- Apply online-elicited, domain-specific criteria (e.g., “cite guideline sections,” “state diagnostic uncertainty,” “risk disclosures”) in RL for expert systems.
- Tools/products/workflows: SME-in-the-loop rubric ratification; formal verification of negative criteria; incident response tied to criterion violations.
- Assumptions/dependencies: expert graders with proven correlation to human experts; rigorous validation; regulatory acceptance; liability frameworks; dataset access controls.
- Agentic systems with evolving procedural checklists (autonomous agents, robotics, energy ops)
- For multi-step tool use or plans, maintain dynamic checklists that encode process safety, reproducibility, and resource constraints; combine with verifiable sub-goals where possible.
- Tools/products/workflows: plan validators using elicited criteria; integration with RLVR for measurable steps; simulation-in-the-loop for unsafe actions.
- Assumptions/dependencies: mapping language criteria to environment signals; robust credit assignment; safe interruption; calibrated judges for non-text states.
- Standard-setting for audits and regulatory compliance (policy, standards)
- Institutionalize “dynamic criterion discovery” as a best practice to detect reward hacking and emergent risks; include in NIST AI RMF-like frameworks and procurement guidelines.
- Tools/products/workflows: compliance attestations that include online-elicited criteria logs; third-party audit APIs; standardized reporting formats.
- Assumptions/dependencies: consensus on definitions and reporting; cross-organizational trust in judge quality; reproducibility requirements.
- Rubric-agnostic reward model pretraining via online criteria corpora (academia, platforms)
- Use the elicited criteria as training data for robust, general reward models (R3-style) that generalize across domains and reduce reliance on expensive judges.
- Tools/products/workflows: large-scale criteria corpora with weights and spans; distillation into smaller evaluators; continual learning with drift detection.
- Assumptions/dependencies: data licensing and privacy; de-biasing; model-card commitments; maintenance of coverage across domains.
- Cost-efficient, on-device or low-latency graders (inference infra)
- Distill high-quality graders into smaller models to make online rubric training affordable at scale (and for edge use).
- Tools/products/workflows: teacher–student distillation pipelines; calibration harnesses; fallback to cloud graders for hard cases.
- Assumptions/dependencies: minimal AUC drop; robust calibration; hardware constraints; intermittent connectivity policies.
- Multimodal and interactive task coverage (vision–language, speech, video)
- Extend pairwise elicitation to images/video/code execution traces, creating criteria that evaluate explanations, spatial grounding, and temporal consistency.
- Tools/products/workflows: multimodal graders; programmatic probes mapping criteria to detections (e.g., bounding boxes cited in text); timeline-aware evaluation.
- Assumptions/dependencies: competent multimodal judges; data availability; cross-modal alignment methods; higher compute budgets.
- Theoretical guarantees and stability tooling (research)
- Tighten bounds on gradient mismatch due to implicit criteria; characterize sample complexity and convergence; design diagnostics to prevent positive feedback loops.
- Tools/products/workflows: training-time monitors for gradient–reward mismatch; ablation tools that simulate removal/addition of criteria.
- Assumptions/dependencies: access to internal training signals; reproducible protocols; acceptance of theory-backed guardrails in production.
- Fairness-aware rubric elicitation and governance (policy, responsible AI)
- Add constraints to avoid encoding societal biases when eliciting criteria; enforce demographic parity checks and appeal mechanisms in grading.
- Tools/products/workflows: bias audits on elicited criteria; fairness-aware weighting; human review boards; redress channels.
- Assumptions/dependencies: representative datasets; fairness metrics aligned with use case; regulatory scrutiny and transparency norms.
- Knowledge management and style-guide automation (media, marketing, documentation)
- Convert evolving criteria into living style guides for content teams; auto-suggest revisions and enforce checklists at authoring time.
- Tools/products/workflows: editor plugins (Docs/Markdown/IDE) surfacing criteria; batch conformance checks; change logs tied to campaign results.
- Assumptions/dependencies: editorial oversight; avoiding homogenization that harms creativity; integration with CMS and legal review.
Each application above benefits from the paper’s core innovation: pairwise elicitation of sample-grounded, weighted criteria that dynamically augment static rubrics, improving reward fidelity, reducing reward hacking, and aligning models with evolving real-world desiderata.
Glossary
- Advantage (normalized rewards): In reinforcement learning, the advantage function measures how much better an action is compared to the average, often computed by normalizing rewards across a group. Example: "advantages are calculated as normalized rewards:"
- AlpacaEval: A benchmark for evaluating instruction-following quality of LLMs via automatic judgments and win rates. Example: "across AlpacaEval, GPQA, ArenaHard"
- Arena-Hard: A challenging benchmark derived from crowdsourced evaluations to assess instruction-following and reasoning quality. Example: "and Arena-Hard \citep{arenahard2024}"
- Area Under the Curve (AUC): A metric summarizing the performance of a classifier across thresholds, typically computed from the ROC curve. Example: "AUC score is calculated using the receiver operating characteristic (ROC) curve."
- Conditional reward modeling: A technique where a single reward model flexibly applies different evaluation principles depending on context. Example: "conditional reward modeling \citep{cai2024internlm2} allows a single reward model to flexibly apply different principles depending on context"
- Constrained optimization: Optimization under explicit constraints to balance multiple objectives, used in safe alignment settings. Example: "balances them using constrained optimization."
- Control policy: An alternative policy used to produce comparison responses during training for eliciting criteria. Example: "control policy $\pi_{\text{control}$"
- Deduplication (criteria): The process of removing overlapping or redundant elicited criteria to avoid redundancy in rubrics. Example: "LLM-based rubrics elicitation and deduplication steps to generate a set of elicited criteria."
- Direct Preference Optimization (DPO): A method that directly optimizes policies from preference data without training an explicit reward model. Example: "Direct Preference Optimization (DPO;~\cite{dpo}),"
- GPQA-Diamond: A graduate-level, google-proof QA benchmark’s hardest split used to assess expert reasoning. Example: "GPQA-Diamond \citep{rein2024gpqa}, GSM8K \cite{gsm8k}, AlpacaEval \cite{alpaca_eval}, and Arena-Hard \citep{arenahard2024}"
- GRPO (Group Relative Policy Optimization): A policy gradient algorithm variant used to train LLMs with rubric-based rewards. Example: "In this work, we used the GRPO algorithm \citep{shao2024deepseekmath} maximizing the following objective"
- GSM8K: A math word problem benchmark used to evaluate reasoning and verifier-guided training methods. Example: "GSM8K \cite{gsm8k}"
- Inference-time scaling laws: Empirical relationships showing performance improvements as inference computation increases (e.g., for reward models). Example: "established inference-time scaling laws for generalist reward models"
- KL divergence (D_KL): A measure of difference between probability distributions, commonly used as a regularizer to keep a trained policy close to a reference. Example: "- \beta \mathbb{D}{KL}\Big(\pi\theta ||\pi_{ref} \Big)"
- Length-Controlled Win Rate (LC-WR): A debiased win rate metric that controls for response length to reduce evaluator bias. Example: "WR stands for Win Rate and LC-WR is Length-Controlled Win Rate."
- Likert scale: An ordinal rating scale (e.g., 1–5) used here for LLM judges to assign quality scores to responses. Example: "We train the model by only using an LLM-judge to grade the responses on a Likert scale without any rubrics."
- LLM-based grader: A LLM used as an evaluator to assign rubric-satisfaction scores to outputs. Example: "an LLM-based grader evaluates a response against each criterion in the rubric"
- LLM-judge: A LLM acting as a judge to score or compare outputs, often used to compute rewards or win rates. Example: "We train the model by only using an LLM-judge to grade the responses on a Likert scale"
- MECE (Mutually Exclusive and Collectively Exhaustive): A structuring principle ensuring criteria are non-overlapping and fully cover the evaluation space. Example: "criteria are Mutually Exclusive {paper_content} Collectively Exhaustive, Atomic, Objective, and Self-Contained;"
- OnlineRubrics (Online Rubrics Elicitation): A method that dynamically elicits and augments evaluation criteria during training via pairwise comparisons. Example: "We introduce Online Rubrics Elicitation (OnlineRubrics), a method that dynamically curates evaluation criteria in an online manner through pairwise comparisons of responses from current and reference policies."
- Out-of-distribution evaluations: Testing on benchmarks not seen during training to assess generalization of learned policies or rewards. Example: "We additionally conduct out-of-distribution evaluations using public benchmarks,"
- Pairwise comparisons: Comparing two responses to infer preferences or criteria, often more robust than pointwise judgments. Example: "through pairwise comparisons of responses from current and reference policies."
- Pairwise reward modeling: Learning a reward function from pairwise preferences between outputs rather than absolute scores. Example: "pairwise reward modeling \citep{christiano2017deep,stiennon2020learning,ouyang2022training}."
- Pareto frontier: The set of non-dominated trade-offs between metrics (e.g., accuracy vs. cost), where improving one worsens the other. Example: "Models on the Pareto frontier (shown as a red dotted line) are the best trade-off between the two metrics."
- Pareto-optimal (trade-offs): Solutions where improving one objective necessarily degrades another; used to balance multiple alignment goals. Example: "to achieve Pareto-optimal trade-offs across competing objectives"
- Policy gradient: A class of reinforcement learning methods that optimize the parameters of a policy by following the gradient of expected rewards. Example: "used to create the reward in the policy gradient algorithm."
- Proximal Policy Optimization (PPO): A stable policy gradient algorithm using clipped objectives, widely used in RLHF pipelines. Example: "with an explicit reward model in PPO \citep{schulman2017proximal} and GRPO or implicitly in DPO."
- Reference policy: A baseline or prior policy used to regularize training (e.g., via KL) and to form pairwise comparisons. Example: "pairwise comparisons of responses from current and reference policies."
- Reinforcement Learning from AI Feedback (RLAIF): Alignment technique where AI-generated feedback guides policy optimization, replacing human labels. Example: "pioneered the use of AI feedback (RLAIF) by leveraging a fixed set of principles for model self-feedback."
- Reinforcement Learning from Human Feedback (RLHF): Training paradigm that aligns models to human preferences via reward modeling from human judgments. Example: "Foundational work in Reinforcement Learning from Human Feedback (RLHF) established the use of pairwise preference comparisons"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL method using automatically checkable outcomes (e.g., numeric answers, unit tests) as exact rewards. Example: "Reinforcement Learning with Verifiable Rewards (RLVR) improves reasoning by optimizing policies against automatically checkable outcomes"
- Reward hacking: Exploitative behaviors where models optimize for the proxy reward while degrading true quality or alignment. Example: "Such static rubrics, however, are vulnerable to reward-hacking type behaviors"
- Reward model: A learned function that estimates the reward (quality) of outputs from preference or rubric signals. Example: "explicit reward model"
- Rubric-based rewards: Using structured, weighted criteria to compute rewards for long-form responses during RL training. Example: "rubric-based scoring for reinforcement learning emerges as an alternative way for reward modeling"
- Universal Requirements: A fixed checklist of criteria applied to all prompts to stabilize training and reduce reward gaming. Example: "We use the same universal requirements as in \cite{viswanathan2025checklistsbetterrewardmodels}"
- Verifiable rewards: Rewards that can be automatically checked for correctness (e.g., via unit tests or exact match), providing precise supervision. Example: "verifiable rewards offer exact supervision whenever the outcome can be automatically checked."
- Win Rate (WR): The fraction of pairwise comparisons in which a model’s response is preferred over a baseline. Example: "WR stands for Win Rate"
- [Group] advantages: Per-group normalized advantages used in GRPO to stabilize updates across multiple sampled outputs. Example: "Compute group advantages \cref{eq:advantages}"
Collections
Sign up for free to add this paper to one or more collections.