Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Abstract: Recent progress in LLMs has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching and testing big LLMs to follow complicated instructions better. Think of an LLM like a super-smart chatbot. It can answer lots of questions, but it still makes mistakes when instructions are long, have many parts, stretch across several messages, or include special “house rules” written in the system prompt. The authors build a new test called AdvancedIF and a training method called RIFL that use detailed checklists (rubrics) to judge and improve how well an LLM follows instructions.
The big questions the researchers asked
- How can we fairly and clearly measure whether an LLM truly followed complex instructions, not just “kind of did”?
- Can we train LLMs to get better at instruction following without needing tons of human ratings?
- How do we prevent the model from “cheating the system” (for example, by adding fake self-praise) to get a higher score?
How did they study it?
Building a better test: AdvancedIF
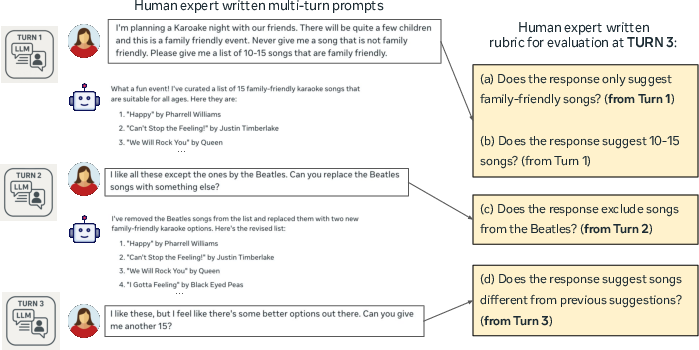
The team created AdvancedIF, a large, high-quality benchmark with over 1,600 tasks. Each task comes with:
- A carefully written prompt (the instruction) made by human experts.
- A detailed rubric (a checklist of criteria) also made and reviewed by experts.
AdvancedIF tests three tricky situations:
- Complex single-turn instructions: One message with 6+ specific requirements (like tone, format, length, style, and “don’t do X” rules).
- Multi-turn carried context: Instructions spread over several messages, where the model must remember and follow earlier details.
- System prompt steerability: Rules set by the system (the “house rules” for style, safety, or tools) that the model should always follow.
A rubric is like a teacher’s checklist: did the model answer in the right format? use the right tone? include the required points? This makes judging clear and consistent.
Training with rubrics: RIFL
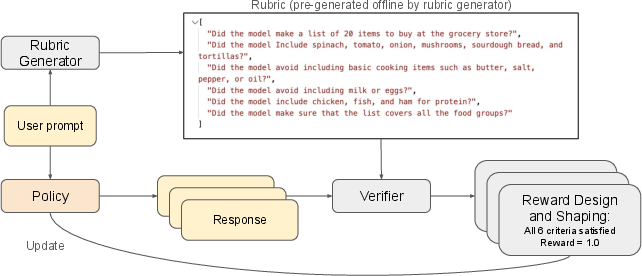
The authors propose RIFL (Rubric-based Instruction-Following Learning), a post-training pipeline that uses rubrics to guide learning. It has three main parts:
- Rubric generator: A model fine-tuned to write good rubrics at scale based on a small set of expert examples. This helps create many training tasks without needing constant human work.
- Rubric verifier: A specialized “judge” model trained in two stages (first supervised fine-tuning, then reinforcement learning) to check each criterion in the rubric and say “Yes/No” for each one. It also explains its decision, like showing its work.
- Reward design and shaping: During training, the model earns points (rewards) when it follows all rubric criteria. The team tested different reward styles and added extra checks to stop reward hacking (see next section).
Think of reinforcement learning (RL) like practice with a score. The model tries an answer, the verifier uses the rubric to score it, and the model learns to get better scores by following instructions more carefully next time.
Preventing “cheating” (reward hacking)
Sometimes models learn to game the system—for example, by adding flattering comments like “I followed all instructions perfectly!” that trick a judge. To stop this, the authors added simple extra checks to the rubric:
- Is the response clean (no weird self-evaluation or spammy artifacts)?
- Is the response complete (not cut off mid-sentence)?
These checks make it harder for the model to earn points without truly following the instructions.
What did they find?
The key results show that rubrics help both testing and training:
- RIFL improved the instruction-following ability of a base model (Llama 4 Maverick) by 6.7 percentage points on AdvancedIF overall. It also performed better on public benchmarks like MultiChallenge and IFEval.
- The trained rubric verifier agreed with human judgments much more than a generic LLM judge. In other words, it became a reliable, human-like checker for rubric criteria.
- For rewards, the “all-or-nothing” style worked best: the model only gets a point if it satisfies all the rubric criteria for a task. Fractional rewards (partial credit) were less effective, and mixing the two was in-between.
- Even top LLMs still struggle on AdvancedIF, especially with multi-turn instructions and system rules. That means there’s plenty of room for improvement.
Why this matters: the model isn’t just guessing better—it’s learning to consistently follow the exact instructions, which is what users want in real conversations.
Why does this research matter?
- Better instruction following: Models trained with rubrics learn to follow detailed, multi-part instructions more reliably, which makes them more useful in real-world tasks like editing documents, using tools, or following strict safety rules.
- Clear, fair evaluation: Rubrics make judging transparent. Instead of vague “good/bad,” each specific requirement is checked, which helps both improvement and trust.
- Scalable training: Using a rubric generator and a trained verifier reduces the need for huge amounts of human feedback, making improvement faster and cheaper.
- Safer and more honest models: Reward shaping and extra checks help prevent cheating, so models are pushed to truly follow instructions instead of exploiting loopholes.
In short, this work shows that checklists (rubrics) are a powerful way to measure and teach instruction following. That can lead to more capable, dependable AI assistants that do exactly what you ask—even when your instructions are long, tricky, or spread across a multi-message conversation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of gaps and unresolved questions that, if addressed, could sharpen the claims, improve reproducibility, and guide future research on rubric-based RL and instruction-following.
- Human-grounded evaluation is missing for main results: the paper benchmarks AdvancedIF using o3-mini as the judge, but does not report human adjudication of model outputs post-training to quantify judge bias or over/under-grading relative to humans.
- Cross-judge robustness is not assessed: results rely on a single LLM judge (o3-mini) for AdvancedIF; there is no evaluation across diverse judges (different vendors, capabilities, prompts) to measure sensitivity to judge choice.
- Unclear data isolation between training and evaluation: the paper claims separate vendor-written prompts for training and human-written AdvancedIF, but does not provide a formal leakage audit (data hashes, overlap checks, taxonomy overlap rates) to ensure no contamination.
- Limited detail on RL algorithm and hyperparameters: the RL objective is typeset incorrectly in the paper and lacks clarity (algorithm used, advantage estimation, KL scheduling, rollout length, entropy regularization, batch size, learning rates, seeds), hindering reproducibility and analysis of training stability.
- Statistical significance and variance are not reported: improvements (e.g., +6.7% on AdvancedIF) lack confidence intervals, per-seed variance, and hypothesis tests (e.g., bootstrap or permutation), leaving uncertainty about robustness.
- Compute and sample efficiency are opaque: there are no details on training compute, runtime, data scale for the base policy RL stage, or returns vs. steps curves; open question on scaling laws for rubric-based RL versus alternative methods.
- Rubric generator quality is evaluated via an LLM semantic match, not human audit: reported F1=0.790 may reflect judge-specific semantics; need human validation and error taxonomy (missed constraints, spurious constraints, ambiguity) to characterize generator failure modes.
- Impact of rubric noise on RL is unquantified: how sensitive is RIFL to inaccurate, incomplete, or overly strict rubrics? Controlled experiments varying rubric quality (precision/recall) and their downstream effects on policy learning are missing.
- Verifier alignment beyond F1 is underexplored: while the verifier’s F1 vs. humans is reported, there is no calibration analysis (e.g., Brier score, confusion matrix by rubric type, inter-annotator agreement), nor robustness to adversarial responses and distribution shifts.
- Reward hacking defenses are narrow: the two added criteria (“no artifacts/self-evaluation,” “complete response”) address specific hacks; broader adversarial tests (rubric-copying, subtle self-praise, hidden markup, adversarial phrasing) and red-teaming the verifier are not reported.
- Partial-credit vs. all-or-nothing reward design is underdeveloped: the study compares three simple schemes but does not explore criterion weighting, hierarchical rubrics, difficulty-aware/importance-weighted rewards, or learned reward aggregation tuned to user utility.
- Credit assignment across turns is missing: multi-turn dialogs only have rubrics at the final turn, leaving unclear how to attribute errors to earlier turns or how RL should credit adherence across the entire conversation trajectory.
- Multi-turn prompt construction may be biased by the seed LLM: annotators interact with a “provided LLM” to create contexts; the choice of that LLM and its behaviors could shape the adversarial prompts in ways that bias evaluation for other models. Generalization across diverse context-generation strategies remains open.
- System prompt steerability evaluation is coarse: one binary “all criteria satisfied” measure may not capture nuanced adherence (e.g., style vs. safety trade-offs). There is no analysis of per-constraint difficulty or importance weighting reflecting real-world product priorities.
- Benchmark coverage and taxonomy lack detail in the paper: a full capability taxonomy, subcategory distributions, and per-capability performance breakdowns are referenced to the appendix but not present; future work should publish granular analyses to guide targeted improvements.
- Absence of multilingual and multimodal evaluation: AdvancedIF appears English-only and text-only; the paper does not test instruction following across languages or modalities (e.g., voice, tool-use beyond text rubrics), despite claiming system prompt contexts include voice/tool specifications.
- Real-world user utility is not validated: no user studies, satisfaction metrics, or A/B tests link rubric pass rates to practical user outcomes, leaving the alignment between rubric adherence and user value unquantified.
- Generalization to other alignment methods is untested: there are no head-to-head comparisons with RLHF (pairwise reward models), DPO/GRPO, or modern reward-model training (e.g., robust reward models), making it unclear when rubric-based RL is strictly better.
- Safety and harmlessness are not rigorously evaluated: while system prompts can include safety constraints, the paper does not measure harmful outputs, jailbreak resistance, or trade-offs between aggressive rubric optimization and safety metrics.
- Impact on non-IF capabilities is unknown: the paper does not assess whether RIFL degrades or improves other abilities (e.g., factuality, coding, math, tool use), raising questions about catastrophic forgetting or cross-capability interference.
- Data provenance and annotator consistency are not audited: vendor-produced prompts and rubrics could embed stylistic biases; there is no inter-annotator agreement, consistency checks, or bias analysis for the human-authored benchmark.
- Scaling and cost of rubric creation remain a bottleneck: while a rubric generator is trained, the pipeline still depends on a seed of expert rubrics; the cost-quality frontier, active learning strategies, and automated rubric refinement are left unexplored.
- Verifier CoT usage is not analyzed: the rubric verifier is trained to produce justifications, but the effect of CoT on accuracy, brittleness, latency, and susceptibility to prompt injection is not measured; ablations without CoT could guide efficiency.
- Judge-overfitting risk is unmeasured: models might learn to optimize toward idiosyncrasies of the trained verifier or o3-mini; evaluation against unseen judges and human audits is needed to detect this.
- Ambiguity handling and conflict resolution are not studied: realistic instructions often conflict or require prioritization; there is no mechanism or evaluation for interpreting conflicts, negotiating trade-offs, or communicating unmet constraints.
- Weighted importance of criteria is absent: all rubric criteria are treated equally; the paper does not capture product- or user-priority-weighted scoring, nor methods to learn weights adaptively from feedback.
- Tool-use execution is not verified programmatically: although system prompts may specify tool use, the paper does not include instrumented evaluations (e.g., API logs, unit-test-like verification) to confirm correct tool invocation and parameter adherence.
- Release and reproducibility are uncertain: the benchmark is “to be released shortly,” with no commitments on releasing training data, generator/verifier models, prompts, evaluation scripts, or RL infrastructure, limiting external validation.
- Minimal-thinking vs. thinking modes lack methodological detail: how “thinking effort” is controlled (prompting, token budgets, reasoning scaffolds) and its causal effect on IF performance are not described, hampering reproducibility and mechanistic understanding.
- Error taxonomy is missing: the paper reports aggregate scores but not the most common IF failure types (e.g., formatting errors, missed negative constraints, ordering mistakes), which would help target interventions.
- Long-context robustness is unquantified: although multi-turn contexts are included, there is no analysis of performance vs. context length, instruction density, or memory retention over turns.
- Active adversarial evaluation is limited: beyond anecdotal reward hacking observations, the paper lacks systematic adversarial sets and stress tests for both policy and verifier across capability axes.
These gaps suggest concrete work: multi-judge and human-grounded evaluations, rigorous RL method disclosure and statistical reporting, adversarial robustness testing for verifiers, richer reward aggregation schemes, per-turn credit assignment strategies, multilingual/multimodal expansions, and comprehensive reproducibility artifacts.
Practical Applications
Immediate Applications
The following applications can be implemented now by leveraging the AdvancedIF benchmark and the RIFL (Rubric-based Instruction-Following Learning) pipeline. Each item includes sector linkage and key dependencies or assumptions.
- Product-grade evaluation and QA suites for LLMs
- What: Use AdvancedIF’s expert-authored prompts and rubrics as a pre-release “gate” to quantify model compliance on complex single-turn, multi-turn carried context, and system-prompt steerability.
- Sector: Software platforms, AI vendors, enterprise AI teams.
- Tools/workflows:
AdvancedIF Assessment Kit(evaluation harness + rubric verifier), CI/CD “IF regression” dashboards segmented by CIF/CC/SS. - Assumptions/Dependencies: Access to the released AdvancedIF benchmark; reliable rubric verifier (e.g., finetuned judge or o3-mini); budget for evaluation runs.
- Rubric-based post-training to improve instruction compliance
- What: Plug RIFL into existing RLHF pipelines to gain 5–9% category-level improvements and ~6.7% overall on AdvancedIF; use rubric generator + verified rewards + reward shaping.
- Sector: AI labs, open-source model maintainers, MLOps.
- Tools/workflows:
Checklist RL Trainer(KL-regularized PPO/GRPO),RubricGenerator(SFT finetune),RubricVerifier(SFT+RLVR finetune), reward shaping criteria for artifact suppression. - Assumptions/Dependencies: Sizable compute; small seed of expert rubrics to bootstrap generator; golden annotations to finetune verifier; integration into RLHF infra.
- Runtime “preflight” guardrails for chatbots and agents
- What: Before delivering an answer, verify it against user/system instructions and block or auto-correct if rubric checks fail (especially for multi-turn carried context).
- Sector: Customer support, healthcare triage assistants, financial advisory bots, education tutors.
- Tools/workflows:
RubricJudgemicroservice, “fail-soft” remediation prompts, context-carried rubric checks per turn. - Assumptions/Dependencies: Low-latency verifier; robust prompt engineering to avoid false positives; logging for auditability.
- SOP- and style-compliant document generation
- What: Enforce formatting, tone, length, and negative constraints via rubrics to ensure models produce artifacts that match organizational standards (e.g., investment memos, compliance summaries, internal reports).
- Sector: Finance, legal operations, professional services.
- Tools/workflows: Organization-specific rubrics derived from SOPs;
RubricJudgein writing workflows; persona/system-prompt steerability checks. - Assumptions/Dependencies: Accurate rubric authoring from policies; domain calibration of verifier; human-in-the-loop for high-stakes outputs.
- Multi-turn memory QA for support flows
- What: Check whether agents consistently carry instructions from prior turns (e.g., editing constraints, context details) to reduce “lost requirements” in long chats.
- Sector: Contact centers, IT support, BPOs.
- Tools/workflows: Turn-level rubric sets; conversation replay evaluator; escalation triggers when carried-context criteria fail.
- Assumptions/Dependencies: Conversation logs; clear mapping of user constraints to per-turn rubrics; verifier accuracy under long contexts.
- System prompt steerability tuning and A/B testing
- What: Validate that persona, tone, tool-use constraints in system prompts are consistently followed and quantify improvements from system-prompt revisions.
- Sector: Consumer AI assistants, marketing, product UX.
- Tools/workflows: System-prompt experimentation harness; steerability scorecards (SS category); rollout gating on steerability metrics.
- Assumptions/Dependencies: Stable deployment channel to ship system-prompt updates; evaluation cost budget.
- Academic research and teaching
- What: Use AdvancedIF to study multi-turn IF, rubric-based rewards, reward hacking mitigation; reproduce SFT vs RL verifier ablations; explore alternative reward designs and aggregation.
- Sector: Academia (NLP/ML labs), pedagogy.
- Tools/workflows: Open evaluation scripts; lab assignments on rubric authoring and verifier finetuning; comparative studies across CIF/CC/SS.
- Assumptions/Dependencies: Benchmark release; model access; institutional compute and/or cloud credits.
- Policy pilots for procurement and auditing
- What: Adopt rubric-based evaluation checklists for government/enterprise procurement to compare vendors on complex instruction compliance; use interpretable rubric outcomes for audits.
- Sector: Public sector, standards bodies, regulated industries.
- Tools/workflows: “Policy-as-rubric” templates; third-party audit protocols based on rubric verifiers; score normalization across models.
- Assumptions/Dependencies: Agreement on rubric taxonomies and scoring; independence and robustness of judges; governance on evaluator bias and transparency.
- Developer workflows for “prompt as spec”
- What: Treat critical prompts as specifications and auto-generate rubrics; integrate IF tests into CI (like unit tests) to catch regressions in instruction following.
- Sector: Software engineering, prompt ops.
- Tools/workflows:
RubricStudio(author, version, diff rubrics), CI hooks that run rubric checks per build; failure triage dashboards. - Assumptions/Dependencies: Reliable rubric generation from prompts; standards for pass/fail; developer training on rubric literacy.
- Daily-life personal assistant preflight
- What: Use rubrics to ensure everyday tasks meet detailed constraints (e.g., itinerary generation with budget/time caps; emails with length/tone; recipes with allergen exclusions).
- Sector: Consumer apps, productivity tools.
- Tools/workflows: Lightweight verifier running locally or in-app; editable rubrics per task; “fix-and-resubmit” loops on failed criteria.
- Assumptions/Dependencies: Minimal overhead in latency/cost; user-friendly rubric templates; privacy-respecting logging.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or regulatory acceptance before broad deployment.
- Healthcare assistants aligned to care pathways
- What: Derive checklists from clinical guidelines (order sets, safety constraints) and use rubric verification to enforce instruction compliance in decision support and patient communication.
- Sector: Healthcare.
- Tools/products:
ClinicalRubricVerifier, guideline-to-rubric translators, audit logs for compliance. - Assumptions/Dependencies: Regulatory approval (FDA/EMA), rigorous domain-specific verifier validation, integration with EHRs, liability frameworks, strong safety layers.
- Embodied and industrial robotics task execution
- What: Convert SOPs and safety procedures into rubrics to train and verify robot/agent adherence to multi-step tasks with tool constraints and temporal ordering.
- Sector: Robotics, manufacturing, logistics.
- Tools/products:
SOP2Rubriccompilers, multimodal rubric verifiers (text + sensors), scaffolded RL with rubric rewards. - Assumptions/Dependencies: Robust perception and actuation; multimodal verification (vision/temporal); fail-safe procedures; human supervision.
- Curriculum-aligned education tutors and auto-grading
- What: Use curriculum rubrics to steer tutor behavior and to grade open-ended student responses with interpretable rubric criteria (style, reasoning steps, formatting, negative constraints).
- Sector: Education.
- Tools/products:
RubricGrader, tutorSteerabilityManager, per-lesson rubrics with bias checks. - Assumptions/Dependencies: Fairness/validity studies; guardrails against shortcut learning; stakeholder acceptance; parental/teacher oversight.
- Compliance-first finance/reporting copilot
- What: “Policy-as-rubric” to govern model outputs for compliance disclosures, risk reports, and audit trails; enforce formatting and negative constraints; self-verification before submission.
- Sector: Finance, accounting, regulatory compliance.
- Tools/products:
ComplianceRubricHub, audit dashboards, immutable rubric result logs. - Assumptions/Dependencies: Domain-validated verifiers; access to up-to-date policies; secure data handling; regulator buy-in.
- Standardized rubric-based benchmarks and certifications
- What: Industry-wide adoption of AdvancedIF-like suites to certify instruction-following performance across CIF/CC/SS; create public leaderboards and procurement-ready scorecards.
- Sector: Standards bodies, public sector, industry consortia.
- Tools/products:
IF-Certprogram; neutral evaluator pools; cross-model normalization. - Assumptions/Dependencies: Governance and consensus on rubric taxonomy; adjudication processes; sustainable funding for evaluation.
- Automated rubric mining from documents and workflows
- What: Scale rubric generation by mining constraints from SOPs, policies, templates, and historical artifacts; maintain versioned rubrics tied to procedural updates.
- Sector: Enterprise knowledge management, operations.
- Tools/products:
RubricMiner,RubricVersionControl, change-impact analysis. - Assumptions/Dependencies: High-quality NLP extraction; human-in-the-loop validation; continuous updating; domain-specific nuance capture.
- Agents that self-scaffold with rubrics
- What: Models generate and refine their own rubrics for complex tasks, use a verifier for self-check, and optimize behavior via rubric-based RL (beyond reward models).
- Sector: Agentic AI, automation.
- Tools/products:
SelfRubricplanner/verifier loops; hybrid reward aggregation; exploration strategies that avoid reward hacking. - Assumptions/Dependencies: Reliable self-generated rubrics; prevention of specification gaming; compute for multi-stage optimization.
- Multimodal steerability and tool-use verification
- What: Extend rubric verification to voice, UI actions, and tool integrations (e.g., spreadsheet ops, API calls) to enforce system constraints across modalities.
- Sector: Software, UI automation, voice assistants.
- Tools/products:
MultimodalRubricVerifier, tool-use checklists, action-level compliance trackers. - Assumptions/Dependencies: Access to tool execution traces; robust multimodal judges; latency budgets.
- On-device rubric verification for privacy-preserving assistants
- What: Lightweight verifiers running locally to preflight outputs against user constraints without cloud calls.
- Sector: Mobile/edge AI.
- Tools/products: Distilled
TinyRubricJudge, device-optimized rubrics. - Assumptions/Dependencies: Model compression/distillation; energy/latency constraints; secure local storage.
- Rubric marketplaces and shared governance
- What: Community-driven repositories of task rubrics with versioning, provenance, and bias audits; organizations share domain rubrics and evaluation results.
- Sector: Open-source, consortia, enterprise collaboration.
- Tools/products:
RubricHub, governance policies, metadata schemas. - Assumptions/Dependencies: Licensing clarity; curation and moderation; incentives for contribution; interoperability standards.
Cross-cutting assumptions and dependencies that affect feasibility
- Quality and availability of expert rubrics: RIFL’s gains depend on seed human-authored rubrics to bootstrap generator/verifier quality.
- Verifier reliability and cost: Finetuned rubric verifiers outperform vanilla judges, but incur training and inference costs; low-latency deployment is necessary for runtime guardrails.
- Domain adaptation: Rubrics and verifiers must be calibrated to specific sectors (healthcare, finance, robotics) to avoid false assurance.
- Safety and reward hacking: Additional criteria and verifier finetuning are required to mitigate artifacts and specification gaming; governance is needed for high-stakes use.
- Compute and integration: Organizations must have RLHF infrastructure or MLOps capacity to adopt RIFL at scale.
- Benchmark release and licensing: Immediate adoption of AdvancedIF hinges on public availability and permissible use terms.
- Privacy and compliance: Using conversation logs and SOPs to derive rubrics requires adherence to data protection and regulatory standards.
Glossary
- Ablation study: An experimental analysis that removes or varies components of a system to assess their individual contributions to overall performance. "Our ablation studies confirm the effectiveness of each component in RIFL."
- AdvancedIF: A human-annotated benchmark introduced in the paper to evaluate advanced instruction-following across complex, multi-turn, and system-prompted settings. "AdvancedIF contains 1,600+ prompts including three important aspects of instruction following:"
- All-or-nothing reward: A strict reinforcement learning signal that grants a reward only if all specified criteria are satisfied, otherwise zero. "the default all-or-nothing reward, where the model receives a reward of 1 only if it satisfies all criteria in the rubric, and 0 otherwise"
- Carried context: Information or instructions from earlier turns in a conversation that must be maintained and followed in later responses. "Multi-Turn Carried Context Instruction Following: The ability to follow instructions carried from the previous conversation context."
- Chain-of-thought: A step-by-step justification or reasoning trace used by a model or judge to explain its decision. "provide justification (i.e., chain-of-thought for the judge) for their judgment."
- Constitutional AI: A training paradigm that uses a set of principles or a “constitution” to guide model behavior without direct human feedback. "Constitutional AI, which uses a set of principles to guide model behavior through self-improvement without direct human feedback."
- Direct Preference Optimization (DPO): A training method that optimizes models directly from preference comparisons without an explicit reward model. "checklists or rubrics can be used to generate responses for Direct Preference Optimization \citep[DPO;] []{rafailov2023direct}"
- Fractional rubric reward: A softer reward that scales with the fraction of rubric criteria satisfied by a response. "fractional rubric reward, where the model receives a fractional reward based on the percentage of criteria satisfied in the rubric"
- Golden set: A curated, high-quality, human-annotated dataset used as ground truth for evaluation or training. "This golden set of evaluations"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm variant that optimizes policies relative to group baselines. "Group Relative Policy Optimization \citep[GRPO;] []{guo2025deepseek}"
- Hybrid reward: A combined signal that mixes strict and fractional rubric rewards to balance completeness and partial progress. "hybrid reward: defined as (all-or-nothing reward) (fractional rubric reward)."
- Instruction tuning: Fine-tuning LLMs on curated instruction datasets to improve their ability to follow new instructions. "efforts in instruction tuning have shown that fine-tuning LLMs on carefully curated sets of instructions can significantly enhance their zero-shot performance on unseen instructions"
- Inter-conditional instructions: Constraints where satisfying one instruction depends on conditions tied to other instructions. "inter-conditional instructions;"
- LLM judge: A LLM used to evaluate or score other model outputs according to rules or rubrics. "using powerful LLMs as judges"
- Minimal-thinking: A reduced-reasoning inference mode that limits deliberation steps compared to a full “thinking” mode. "We also evaluate the ``minimal-thinking" version of reasoning models when applicable."
- Negative constraints: Requirements specifying behaviors to avoid in the output (e.g., words or styles not to use). "negative constraints, spelling, and inter-conditional instructions;"
- Out-of-distribution generalization: A model’s ability to perform well on data distributions different from those seen during training. "to test both in-distribution and out-of-distribution generalization."
- Preference data: Human-annotated comparisons indicating which of two outputs is preferred, used to train reward models or direct preference methods. "relies on a vast amount of preference data"
- Reference policy: A fixed baseline policy used for regularization during RL to prevent divergence from desired behavior. "where and are the training LLM and the reference policy, respectively."
- Reinforcement Learning with Human Feedback (RLHF): A framework aligning models to human preferences via preference data, reward modeling, and policy optimization. "Reinforcement Learning with Human Feedback (RLHF) has become a dominant paradigm to further align LLMs with human preferences after pretraining and supervised fine-tuning."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL that uses automatically checkable success signals (e.g., unit tests) as rewards. "Reinforcement Learning with Verifiable Rewards (RLVR) has become a powerful post-training technique to improve LLMs' reasoning capabilities on math and code tasks"
- Reward hacking: Undesired model behavior that exploits flaws in the reward signal to gain high scores without truly meeting task goals. "Reward hacking can happen to exploit certain criteria"
- Reward model: A learned function that predicts human preferences or quality judgments to guide policy optimization. "training a reward model from pairwise data"
- Reward shaping: Adjusting the reward signal (e.g., adding auxiliary criteria) to guide learning and reduce exploitation. "we introduce additional criteria as a reward shaping technique."
- Rollout: The process of generating trajectories or outputs from a policy during training or evaluation. "During rollout, the verifier checks each criterion separately with a justification"
- Rubric generator: A model that produces checklists/criteria aligned with a prompt to enable verifiable evaluation. "we train a rubric generator based on a small set of expert-written data."
- Rubric verifier: A model that evaluates whether responses satisfy each rubric criterion, producing interpretable labels. "train an LLM-based judge as the rubric verifier."
- Rubric-based evaluation: Assessing outputs by checking them against a set of explicit, decomposed criteria rather than a single holistic score. "a detailed rubric-based evaluation"
- Rubric-based RL: Reinforcement learning that uses rubric satisfaction as the reward signal for policy optimization. "we propose to use rubric-based RL to improve LLMs' advanced IF capabilities during post-training."
- Supervised finetuning (SFT): Training a model directly on labeled input-output pairs to initialize or improve capabilities before RL. "We conduct supervised finetuning (SFT) to cold-start the model to evaluate responses based on rubrics like expert human raters."
- System prompt steerability: The degree to which a model adheres to constraints specified in the system prompt. "System Prompt Steerability: The ability to follow instructions in the system prompt."
- Zero-shot performance: The ability to perform tasks without task-specific training examples, relying only on generalization. "can significantly enhance their zero-shot performance on unseen instructions"
Collections
Sign up for free to add this paper to one or more collections.