RubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning
Abstract: Dense image captioning is critical for cross-modal alignment in vision-language pretraining and text-to-image generation, but scaling expert-quality annotations is prohibitively expensive. While synthetic captioning via strong vision-LLMs (VLMs) is a practical alternative, supervised distillation often yields limited output diversity and weak generalization. Reinforcement learning (RL) could overcome these limitations, but its successes have so far been concentrated in verifiable domains that rely on deterministic checkers -- a luxury not available in open-ended captioning. We address this bottleneck with RubiCap, a novel RL framework that derives fine-grained, sample-specific reward signals from LLM-written rubrics. RubiCap first assembles a diverse committee of candidate captions, then employs an LLM rubric writer to extract consensus strengths and diagnose deficiencies in the current policy. These insights are converted into explicit evaluation criteria, enabling an LLM judge to decompose holistic quality assessment and replace coarse scalar rewards with structured, multi-faceted evaluations. Across extensive benchmarks, RubiCap achieves the highest win rates on CapArena, outperforming supervised distillation, prior RL methods, human-expert annotations, and GPT-4V-augmented outputs. On CaptionQA, it demonstrates superior word efficiency: our 7B model matches Qwen2.5-VL-32B-Instruct, and our 3B model surpasses its 7B counterpart. Remarkably, using the compact RubiCap-3B as a captioner produces stronger pretrained VLMs than those trained on captions from proprietary models.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “RubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning”
1) What is this paper about?
This paper is about teaching computers to write very detailed descriptions of pictures. This is called dense image captioning. Instead of just saying “a dog in a park,” the goal is to describe many parts of the image: the objects, their colors and sizes, where they are, what they’re doing, and even text that appears in the image.
The authors introduce a new training method called RubiCap. It uses “rubrics” (like the grading checklists teachers use) to guide the computer as it learns to write better, more accurate, and more informative captions.
2) What questions are the researchers trying to answer?
The paper focuses on a few simple questions:
- How can we train a model to write rich, accurate captions without paying lots of experts to label millions of images?
- How do we go beyond copying a “teacher” model’s style so the student really understands images, not just imitates?
- Can we use reinforcement learning (a way of learning from rewards) even when there’s no easy “right or wrong” answer, like there is in math or code?
- Will rubric-style feedback help the model avoid common problems like making things up (hallucinations) or forgetting other skills it already had?
3) How does their method work? (Easy-to-understand version)
Think of RubiCap as a two-step coaching system with a smart checklist.
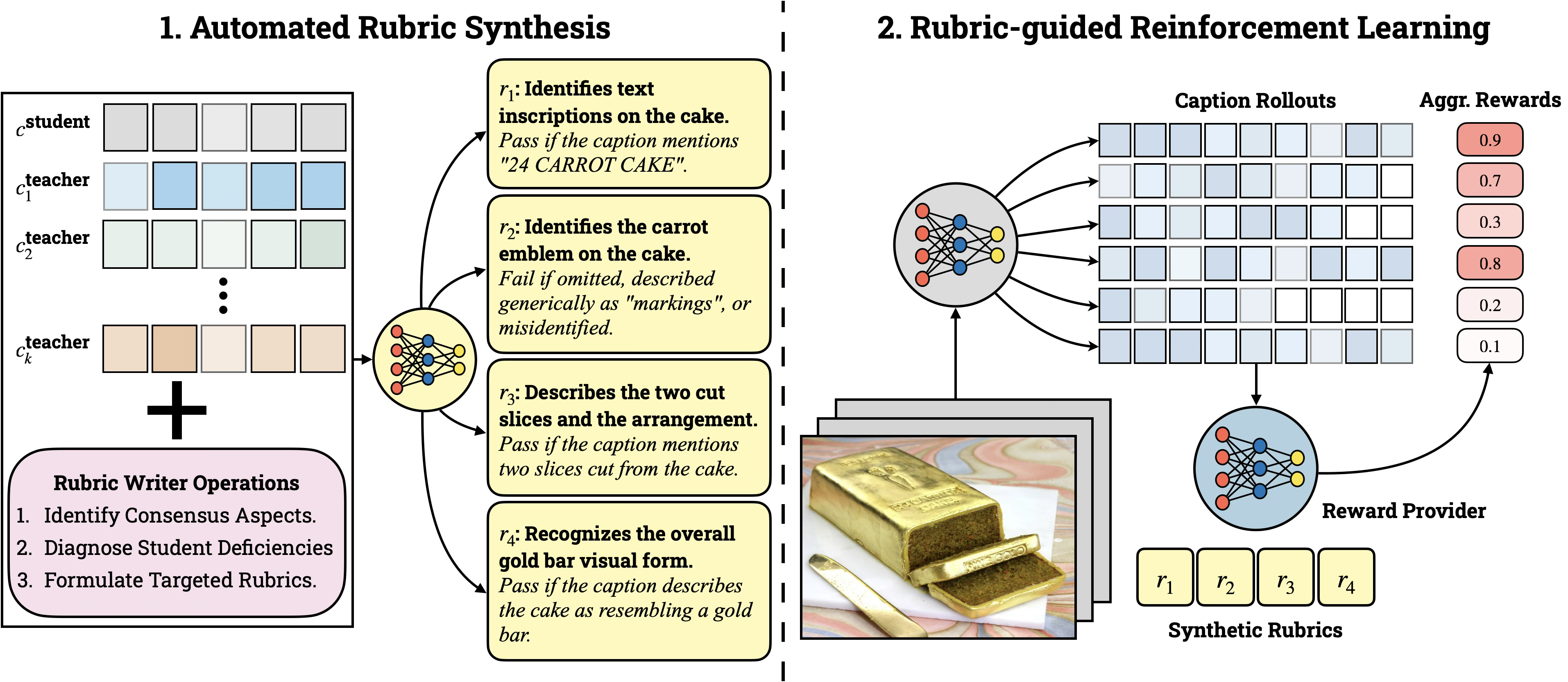
- First, several strong image-LLMs act like a “committee” of teachers. Each one writes a caption for the same image. Then a LLM (an LLM) looks at what these teachers agree on and where they differ. From that, it writes a rubric—a clear checklist of what a good caption should include for this specific image. For example, the rubric might say: “Mention the red backpack,” “Describe the dog’s breed if visible,” “Don’t claim there is a cat if none is shown,” or “Read the text on the cake that says ‘24 CARROT CAKE’.”
- Second, the student model tries writing its own caption. Another model (the “judge”) checks the student’s caption against the rubric. Each checklist item is easy to mark as pass or fail. Important items (like “didn’t hallucinate a person who isn’t there”) count more than small style issues. The student then learns from this feedback. Over time, it gets better at noticing and describing the right details.
In school terms: multiple teachers draft what should be graded for a particular assignment (the image), they turn that into a grading checklist, the student writes their answer, and a fair grader marks each checklist item. The student improves by fixing exactly what they missed.
A quick note on “reinforcement learning” (RL): RL is like practicing a game—try a move, get a score, adjust, and try again. Here, the score isn’t just a single number; it comes from the rubric’s detailed checks. The model tries several captions per image and learns to favor the ones that score better on the rubric compared to its other attempts.
4) What did they find, and why is it important?
The authors tested RubiCap against many alternatives, including:
- Supervised fine-tuning (SFT), where a model simply copies examples from humans or a bigger model.
- RL with simple text-overlap scores (rewards based on how many words match a reference caption).
- RL that uses a single “vibe score” from a judge model (a 1–10 rating without specifics).
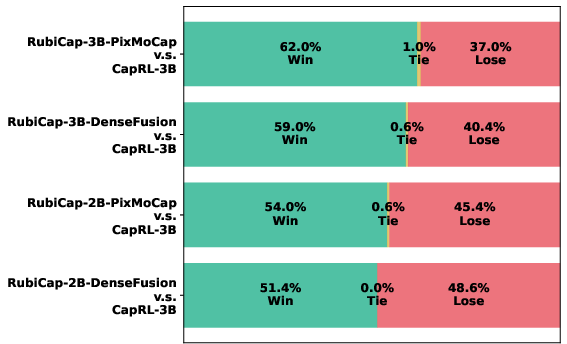
- Another recent RL method (CapRL) that turns captions into multiple-choice scoring.
Here are the main takeaways:
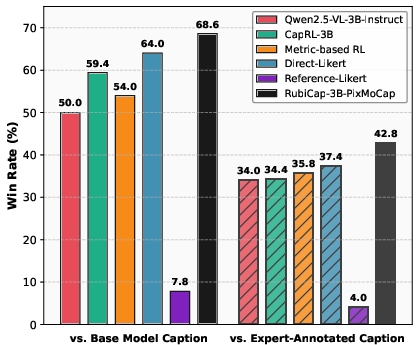
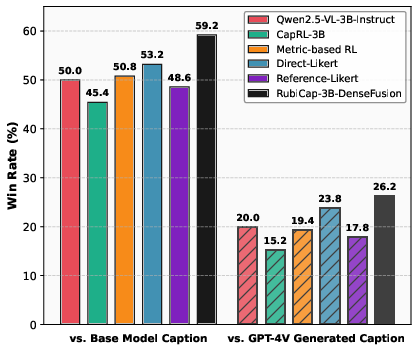
- RubiCap produces better captions than these baselines, often winning head-to-head comparisons judged by strong models (like GPT-4.1) on a benchmark called CapArena.
- It even beats expert-refined human captions and captions made by a strong proprietary system in many pairwise comparisons.
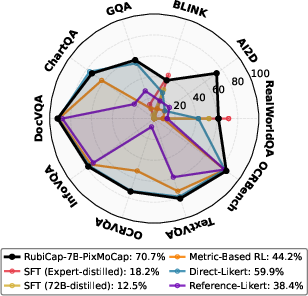
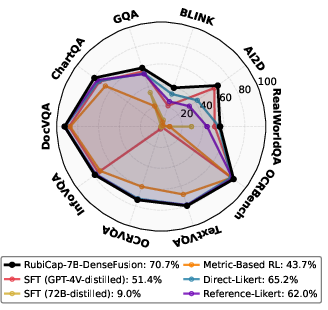
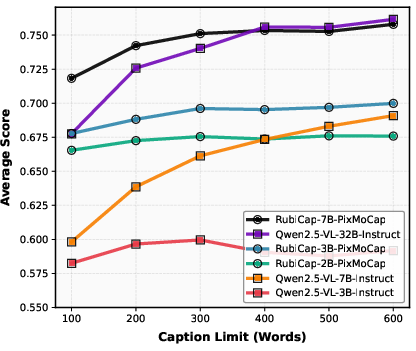
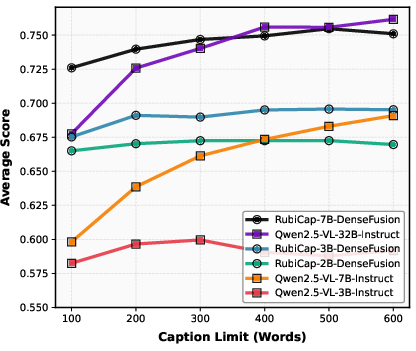
- The captions are more “word-efficient.” On a test called CaptionQA, RubiCap captures the most important information in fewer words. A smaller RubiCap model can match or beat much larger models when there’s a tight word limit.
- RubiCap helps the model keep its other skills. Many training methods cause “catastrophic forgetting” (the model forgets what it previously knew). RubiCap reduces this, so the model still performs well on a wide variety of vision-language tasks.
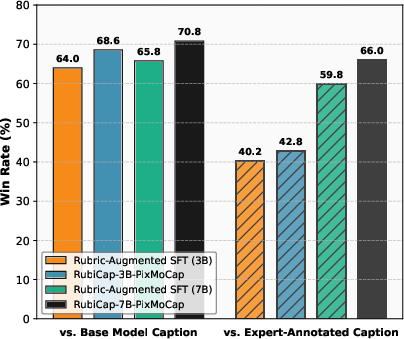
- Using captions created by a small RubiCap model to pretrain a new vision-LLM leads to better overall performance than using captions generated by a well-known proprietary model. That’s a big win for accessibility and cost.
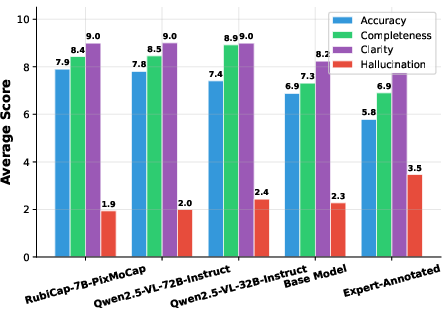
Why this matters: Better, denser captions help many areas—training smarter vision-LLMs, improving tools that answer questions about images, boosting text-to-image systems with more accurate guidance, and making AI descriptions more trustworthy (less hallucination).
5) What could this change in the future?
RubiCap shows a new way to bring reinforcement learning to open-ended tasks like captioning, where there isn’t a simple “right answer” checker. Turning a complex judgment (“Is this a good caption?”) into a clear, targeted checklist per image:
- Gives the model precise guidance on what to fix.
- Reduces reward hacking (where the model learns to game the score without truly improving).
- Scales up, because rubrics can be written automatically by LLMs.
- Makes training cheaper and more flexible, since smaller, open models can produce training data that rivals or beats expensive proprietary systems.
In short, this work points to AI that learns like a student with a good rubric: focused feedback, fewer mistakes, stronger skills, and better results—even with smaller models and tighter budgets.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete list of unresolved issues that future work could address to strengthen, generalize, and de-risk RubiCap and rubric-guided RL for dense image captioning:
- Dependence on proprietary models: The rubric writer (e.g., Gemini 2.5 Pro) and parts of the teacher committee (e.g., GPT‑5, Gemini) are closed-source. Quantify how performance changes when replacing them with fully open-source committees/rubric writers; provide a reproducible, open pipeline.
- Judge reliability and alignment: Rewards and most evaluations rely on LLM judges (Qwen2.5‑7B for training; GPT‑4.1 for CapArena). Measure inter-judge agreement, robustness across different judges/ensembles, and correlation with blinded human raters at both pairwise and rubric-criterion levels.
- Rubric correctness and ambiguity: The paper asserts “unambiguous” binary criteria but offers no quality audit. Quantify rubric precision/recall against image-grounded human checks; estimate false-positive/negative rates per criterion type (object, attribute, relation, OCR) and their training impact.
- Committee consensus assumptions: Majority-vote threshold (⌈K/2⌉) and committee composition are fixed. Ablate K, threshold values, and teacher diversity to measure sensitivity to shared biases, correlated hallucinations, and how often “consensus” is wrong.
- Severity weighting: Fixed weights {1, 2, 3} for minor/important/critical criteria are unvalidated. Study learned or human-calibrated weightings, dynamic schedules, or task-dependent weights; report sensitivity analyses.
- Binary pass/fail feedback: All criteria are binary. Explore graded/partial-credit scoring (e.g., fuzzy matching, calibrated confidence) to reduce reward brittleness and improve credit assignment for near-correct spans.
- Reward hacking of rubrics: Although RubiCap mitigates “vibe-check” hacking seen in Likert baselines, models could still learn to game predictable rubric patterns (e.g., adding high-yield phrases). Develop adversarial stress tests and detectors for rubric exploitation, and report linguistic diversity and redundancy metrics post-training.
- Novelty vs consensus: The rubric targets “deficiencies relative to teacher consensus.” Investigate whether this suppresses valid novel details absent from consensus; design rubric components that explicitly reward truthful novel information and penalize unsupported additions.
- Cost and scalability: Per-sample pipeline requires K teacher captions, rubric writing, and multi-criterion judging for N rollouts. Report token/compute costs, wall-clock, and energy; study cost–quality trade-offs via caching, rubric reuse across similar images, criterion pruning, or lightweight programmatic checks.
- Sample efficiency and compute normalization: Provide compute-normalized comparisons vs SFT and other RL baselines; ablate number of rollouts N, rubric size M, and update frequency to characterize sample efficiency and diminishing returns.
- Training stability and sensitivity: GRPO hyperparameters (clipping, normalization, KL/reference policy) are not analyzed. Compare GRPO vs PPO/REINFORCE variants; report stability, variance across seeds, and failure modes (e.g., collapse, mode drift).
- Generalization beyond two sources: Training uses 50k images from PixMoCap and DenseFusion subsets. Test cross-domain generalization (e.g., medical, satellite, wildlife, underexposed or low-quality imagery, abstract graphics) and across broader distributions.
- Multilingual capability: The system is English-only. Evaluate multilingual rubrics and captions, cross-lingual transfer, and code-switching; verify judge/rubric writer reliability in non-English settings.
- Explicit grounding evaluation: Dense captioning implies region-level grounding, yet no explicit grounding metrics (e.g., referring expression localization, box/segment alignment) are reported. Incorporate grounding benchmarks and/or hybrid verifiers (detectors, OCR, scene graphs) into rubrics.
- Human evaluation: Beyond LLM-judged CapArena and ranking, include blinded human pairwise preferences and criterion-level audits to validate hallucination, accuracy, and clarity claims and to detect style overfitting to judge prompts.
- Safety and privacy: No assessment of sensitive attribute mentions, PII, or harmful content under rubric optimization. Introduce safety-oriented rubric criteria, red-teaming, and audits for demographic bias and privacy leakage.
- Robustness to OCR and clutter: Many criteria depend on OCR-like details. Evaluate robustness under blur, occlusion, low resolution, stylized fonts, and multi-language text; measure failure rates and mitigation via external OCR/tool feedback.
- Cross-evaluator generalization: The evaluation relies heavily on GPT‑4.1 prompts. Test against alternative evaluators (Claude, Llama‑3.1, Qwen, human panels) and unseen evaluation prompts to check for overfitting to specific judge styles.
- Pretraining utility breadth: Pretraining gains are shown in one LLaVA‑NeXT-style pipeline and one backbone. Assess other backbones/scales, instruction-tuning recipes, and downstream tasks (e.g., retrieval, grounding, VQA, text-to-image control signals).
- Judge choice ablation in training: Replace Qwen2.5‑7B judge with stronger/weaker judges or judge ensembles; analyze how judge capability and bias propagate to trained captioners and whether judge diversity improves robustness.
- KL control and reference policy: The role of the reference policy and KL constraints is under-specified. Study KL weight schedules to balance exploration vs capability retention; quantify trade-offs with catastrophic forgetting.
- CaptionQA reliance: Word-efficiency evaluation uses an LLM-constructed MCQ benchmark judged by an LLM. Validate with human QA or retrieval-style tests; test broader token budgets, compression ratios, and informativeness–fluency trade-offs.
- Coverage and counting: No explicit metrics for object/attribute/relation coverage or counting accuracy. Add structured coverage/counting evaluations to ensure improvements are not driven solely by style or phrasing.
- Systematic error analysis: Provide a taxonomy of remaining failure modes (e.g., color mismatches, spatial prepositions, small-object misses, numeracy) and per-category progress from base→SFT→RubiCap.
- Adversarial and security risks: The pipeline may be vulnerable to prompt injection into rubric writer/judge or to poisoned teacher captions. Evaluate adversarial robustness and implement sanitization/guardrails.
- Legal and reproducibility concerns: Using closed APIs (Gemini, GPT‑5) limits replication and may have licensing implications. Release open prompts, seeds, and open-model variants to enable community verification.
- Training/inference trade-offs: RL training is costly while inference may be similar to SFT. Quantify end-to-end cost vs quality gains; study distillation of RubiCap policies into cheaper students without losing benefits.
- Alternative or hybrid verifiers: Explore integrating symbolic/vision tools (detectors, trackers, OCR, layout parsers) with rubrics to create partially verifiable criteria, improving faithfulness and reducing judge noise.
- Self-rubricing and continual learning: Investigate models that generate and refine their own rubrics over time (self-rubricing), curriculum schedules that adapt rubric difficulty, and memory of past deficiencies to drive continual improvement.
- Token-level credit assignment: Current rewards are caption-level. Explore aligning rubric criteria to spans and using token-level rewards/attributions (e.g., RLAIF-t, span-level RL) for finer credit assignment.
- Negative rewards for hallucination: While “critical” criteria exist, evaluate explicit strong penalties for hallucination beyond normalized proportion satisfied, and study asymmetric loss shaping for safety-critical errors.
Practical Applications
Immediate Applications
Below are actionable, near-term uses that can be deployed with today’s models and infrastructure.
- High-quality, low-cost caption generation for VLM pretraining
- Sectors: software/AI, data labeling platforms, cloud ML services
- What: Use RubiCap-3B/7B as scalable annotators to recaption large image corpora (e.g., COCO, CC3M) for Stage-1/1.5 pretraining, replacing proprietary captioners while improving downstream VLM benchmarks.
- Tools/products/workflows: “RubiCap Captioning Service” with a teacher-committee orchestrator, rubric writer, LLM judge, and GRPO trainer; plug-in for LLaVA-/LLaVA-NeXT-style pipelines.
- Assumptions/dependencies: Access to diverse teacher models (or strong open-source substitutes), reliable LLM judges, sufficient GPU budget for RL, and proper data licensing.
- Accessibility-grade alt text and image descriptions
- Sectors: accessibility, consumer apps, social media, productivity suites, e-commerce
- What: Generate dense, accurate alt text for images in CMS/social platforms and documents, improving screen reader experiences (objects, attributes, spatial relations).
- Tools/products/workflows: CMS/website plugins; “AltText-Rubrics” pack targeting non-hallucination and salience; human-in-the-loop validation UIs using rubric pass/fail.
- Assumptions/dependencies: Clear content and privacy policies; safeguards to avoid sensitive content leakage; consistent rubric templates for accessibility standards.
- Information-dense captions under tight token budgets (edge/mobile)
- Sectors: wearable AI, AR assistants, mobile apps, customer support
- What: Produce concise, high-salience captions that support downstream QA or on-device agents (shown to outperform larger models under strict word limits).
- Tools/products/workflows: On-device RubiCap-3B; “CaptionQA Guardrails” to test salience; compression-aware decoding policies.
- Assumptions/dependencies: Model optimization (quantization, distillation) for edge hardware; power/latency constraints; localized rubric sets for common scenes.
- Enterprise image indexing and search
- Sectors: enterprise content management, DAM (digital asset management), legal, media
- What: Generate region-level captions to populate metadata for visual assets, improving retrieval, audit, and discovery (who/what/where relationships).
- Tools/products/workflows: DAM connectors; vector search indices augmented with dense captions; rubric-driven QA to reduce hallucinations.
- Assumptions/dependencies: Governance for sensitive content; permissioning and audit logs; bias monitoring.
- Enhanced product content pipelines
- Sectors: e-commerce, retail marketplaces
- What: Auto-generate detailed product image descriptions (attributes, materials, defects, packaging) for search and compliance; highlight missing attributes with rubric checks.
- Tools/products/workflows: “Product-Image Rubric Pack”; SKU-level caption batcher; human review queues triggered by rubric failures.
- Assumptions/dependencies: Domain-specific rubrics; consistency with catalog taxonomies; label noise handling.
- Screenshot and UI diagnostics for support/QA
- Sectors: software QA, IT support, dev tools
- What: Produce dense captions of screenshots (error dialogs, UI states), enabling faster triage and bug reporting or automated UI testing.
- Tools/products/workflows: CI/CD integration; “UI-State Rubrics” (text detection, widget count, layout relations); ticketing system auto-summaries.
- Assumptions/dependencies: OCR-capable teacher committee; privacy controls for PII on screens.
- Document and chart understanding augmentation
- Sectors: finance, operations, business analytics, scientific publishing
- What: Generate captions for receipts, invoices, charts/diagrams to improve downstream extraction or QA of document AI systems.
- Tools/products/workflows: Chart/Doc-specific rubric packs (axes, legends, entities); hybrid OCR + caption pipeline; downstream validators.
- Assumptions/dependencies: Reliable OCR signals and chart parsers among teachers; redaction of sensitive data.
- Safer RL for open-ended generative tasks
- Sectors: AI/ML R&D, model evaluation services
- What: Replace coarse scalar “vibe check” rewards with structured rubric-based signals to reduce reward hacking and improve transparency.
- Tools/products/workflows: Rubric store/versioning; GRPO trainer with multi-criterion rewards; audit dashboards for rubric pass rates by failure class.
- Assumptions/dependencies: High-quality rubric authoring prompts; judge consistency; continual monitoring for shortcut behaviors.
- Data-centric active learning
- Sectors: data engineering, MLOps
- What: Use rubric failures to drive targeted data collection (e.g., more images with small text, crowded scenes) and guided fine-tuning.
- Tools/products/workflows: “Rubric Failure Analytics” to prioritize samples; acquisition strategies tied to failure distributions.
- Assumptions/dependencies: Budget and pipeline for iterative data collection; instrumentation for error analysis.
Long-Term Applications
These opportunities require further research, domain adaptation, validation, or scaling before broad deployment.
- Medical and scientific imaging captioners
- Sectors: healthcare, biotech, materials science
- What: Domain-adapt rubric-guided RL to generate safe, clinically relevant captions of radiology slides, pathology images, or microscopy.
- Tools/products/workflows: Expert committee (domain models + clinicians); regulated rubric libraries (findings, localization, uncertainty language); integration with reporting systems.
- Assumptions/dependencies: Expert curation; rigorous validation and regulatory approval; bias and safety oversight; liability frameworks.
- Autonomous systems and robotics perception
- Sectors: robotics, autonomous vehicles, industrial automation
- What: Train perception modules to produce structured region-level descriptions for navigation and manipulation, with rubrics targeting dynamic objects and spatial reasoning.
- Tools/products/workflows: Real-time captioners with sensor fusion; “Safety-Critical Rubrics” for non-hallucination and uncertainty; closed-loop planners consuming captions.
- Assumptions/dependencies: Real-time performance and robustness; simulation-to-real transfer; safety certification.
- Controllable text-to-image/video generation
- Sectors: creative tools, advertising, gaming, media
- What: Use dense captions as aligned supervision to improve generation controllability and reduce hallucination (region-to-text fidelity).
- Tools/products/workflows: Conditioning interfaces accepting region-linked captions; finetuning diffusion/latent models with rubric-filtered captions; evaluator rubrics for output QA.
- Assumptions/dependencies: Scalable paired data; fast evaluators; user-facing tools for region constraints.
- Standardized rubric frameworks for AI procurement and audits
- Sectors: public sector, compliance, standards bodies
- What: Adopt rubric-based, multi-criterion evaluations to make subjective assessments (e.g., hallucination, clarity) explicit and explainable for model certification.
- Tools/products/workflows: Public “Rubric Registries” by task/domain; audit trails of criterion pass/fail; tender requirements referencing rubric conformance.
- Assumptions/dependencies: Consensus on criteria; governance to prevent overfitting to published rubrics; periodic updates as tasks evolve.
- Education and assessment for visual tasks
- Sectors: education technology, training and certification
- What: Extend rubric-guided evaluation to grade open-ended visual assignments (e.g., describing scientific figures), provide targeted feedback, and train tutoring systems.
- Tools/products/workflows: Teacher-authored rubric banks; student feedback loops mapping misses to study materials; privacy-preserving deployment.
- Assumptions/dependencies: Alignment with curricula and pedagogy; bias and fairness assessment; acceptance by institutions.
- Privacy-preserving on-device captioning for AR/assistive wearables
- Sectors: consumer electronics, healthcare, accessibility
- What: Bring compact rubric-tuned models on-device for continuous scene narration with user-controllable salience (objects vs. text vs. hazards).
- Tools/products/workflows: Low-power inference stacks; dynamic rubric selection based on user intent; fallback cloud judging for hard cases.
- Assumptions/dependencies: Further compression/distillation; battery and thermal constraints; robust offline performance.
- Cross-modal agents with rubric-governed tool use
- Sectors: enterprise automation, UI agents, scientific assistants
- What: Use sample-specific rubrics as intermediate goals guiding multimodal agents (e.g., “verify text on chart” then “extract trend”), improving reliability in open-ended workflows.
- Tools/products/workflows: Planner-executor architectures where rubrics define subgoals; judge-verified progress meters; recovery policies on rubric failures.
- Assumptions/dependencies: Generalization beyond captioning; scalable rubric authoring for complex tasks; latency constraints.
- Domain-specific “rubric packs” marketplaces
- Sectors: SaaS, AI tooling ecosystem
- What: Curated, versioned rubric libraries per industry (e.g., real estate imagery, manufacturing defects, insurance claims) to standardize training/evaluation.
- Tools/products/workflows: Marketplace APIs; telemetry on pass/fail statistics; governance and updates via industry working groups.
- Assumptions/dependencies: Community adoption; IP/licensing for rubrics; mechanisms to avoid gaming.
- Safety and bias mitigation through targeted rubrics
- Sectors: trust & safety, policy, platform governance
- What: Compose rubrics that explicitly penalize sensitive attribute inference, inappropriate content, or biased descriptors in image captions.
- Tools/products/workflows: Safety-first rubric layers; red-teaming guided by rubric failure heatmaps; continuous monitoring.
- Assumptions/dependencies: Evolving norms and regulations; robust detection of sensitive content; trade-offs with descriptive utility.
- Multimodal research beyond captioning
- Sectors: academia, industrial research
- What: Apply rubric-guided RL to other open-ended domains (e.g., video narration, scientific figure interpretation, multimodal reasoning).
- Tools/products/workflows: Generalized rubric synthesis interfaces; domain-specific teacher committees; benchmark suites with rubric-based metrics.
- Assumptions/dependencies: Task-specific verifiers are scarce; need strong judges and consensus modeling; reproducibility and standardization efforts.
Notes on feasibility across applications:
- Dependency on teacher diversity: Performance and robustness improve with committee heterogeneity; purely open-source committees may trail frontier closed models today.
- Judge reliability and drift: LLM judges can be inconsistent; periodic calibration, double-judging, or lightweight deterministic checks (OCR, detectors) improve stability.
- Cost and compute: RL with rubric evaluation introduces overhead; batching, caching, and selective evaluation (e.g., only hard criteria) can manage costs.
- Domain transfer: Out-of-domain images (medical, satellite, microscopic) require new teacher committees and rubrics; zero-shot transfer is limited.
- Safety and privacy: Dense captions can surface sensitive details; deployment must include redaction and policy-aligned rubrics.
Glossary
- Advantage: In policy-gradient RL, a centered reward that measures how much a sampled action outperforms the average of its peers. "The advantage of each rollout is estimated relative to the group:"
- Automated Rubric Synthesis: A procedure that automatically derives per-sample evaluation criteria from teacher outputs to guide training. "the framework operates in two stages: (1) Automated Rubric Synthesis (Sec.~\ref{sec:rubric_generation})"
- Blind ranking evaluation: An assessment where model identities are hidden and outputs are jointly ranked by a judge. "In a blind ranking evaluation, RubiCap-7B earns the highest proportion of rank-1 assignments"
- CapArena: A benchmark that uses a VLM judge to compute pairwise win–loss rates for dense captions. "Across extensive benchmarks, RubiCap achieves the highest win rates on CapArena"
- CAPTURE: A model-based caption quality metric used as a complementary evaluator. "These include model-based measures including CAPTURE~\citep{dong2024benchmarking}"
- CaptionQA: A multiple-choice evaluation that measures whether captions contain enough information to answer image questions under word limits. "On CaptionQA, it demonstrates superior word efficiency"
- Catastrophic forgetting: Degradation of previously acquired capabilities after further fine-tuning. "induces severe catastrophic forgetting of pretrained capabilities"
- CIDEr: A lexical overlap metric that scores similarity to references using weighted n-grams. "Metrics such as CIDEr~\citep{vedantam2015cider}, and ROUGE-L~\citep{lin-2004-rouge} measure n-gram overlap against reference captions."
- Clipping threshold: The ε parameter in PPO-style objectives that limits how far policy updates can move per step. " is the clipping threshold"
- Committee of VLMs: A set of diverse teacher models used to generate candidate captions and consensus. "RubiCap begins with a committee of diverse VLMs producing candidate descriptions for each image."
- Cross-modal alignment: The correspondence learned between visual and textual modalities during pretraining. "Dense image captioning is critical for cross-modal alignment in vision-language pretraining"
- Dense image captioning: Generating detailed, region-level descriptions of objects, attributes, and spatial relationships in an image. "Dense image captioning is critical for cross-modal alignment in vision-language pretraining"
- Deterministic checker: An automatic, unambiguous procedure for verifying correctness of outputs (common in math/code tasks). "its successes have so far been concentrated in verifiable domains that rely on deterministic checkers"
- Deterministic verifier: A reliable automatic mechanism for checking correctness; absent in open-ended captioning. "a luxury not available in open-ended captioning."
- Direct-Likert: A VLM-judge baseline that assigns 0–10 quality scores without reference captions. "two baseline variants from the RaR framework~\citep{gunjal2025rubrics}: Direct-Likert and Reference-Likert."
- Distribution mismatch: A gap between the data distribution of teacher outputs and the student’s generation distribution that harms SFT. "degrades when teacher and student distributions mismatch"
- EXPERT metric: A rubric-style metric that decomposes caption quality into sub-dimensions for ranking. "This evaluation is inspired by the EXPERT metric~\citep{kim2025expert}"
- Group Relative Policy Optimization (GRPO): A PPO-style RL method that normalizes rewards within a group of samples to compute advantages. "We optimize using group relative policy optimization (GRPO)~\citep{shao2024deepseekmath}."
- Hallucination penalty: A penalty for describing objects or details not present in the image. "achieving the lowest hallucination penalty"
- Importance sampling ratio: The likelihood ratio between current and reference policies used to weight updates in off-policy RL. "where $\rho_i = \pi_{\theta_s}(c^{\text{student}_i \mid x) / \pi_{\theta_{\text{ref}(c^{\text{student}_i \mid x)$ is the importance sampling ratio"
- IoU (Intersection over Union): An overlap metric for object detection/segmentation used as a deterministic verifier in grounded tasks. "deterministic verification via IoU, classification accuracy, or multiple-choice correctness."
- LLM judge: A LLM that evaluates outputs against rubrics and provides structured scores. "An LLM judge applies these rubrics to assess caption rollouts"
- LLM rubric writer: An LLM that synthesizes per-sample evaluation rules by extracting consensus and diagnosing failures. "An LLM rubric writer then extracts the consensus"
- Lexical NLP Metrics: Overlap-based metrics that compare output to references at the token level. "Lexical NLP Metrics:"
- MCQ options: The fixed answer choices in multiple-choice evaluations; limited in coverage for open-ended captioning rewards. "MCQ options are inherently limited in coverage"
- n-gram overlap: A token sequence matching scheme used by lexical metrics to measure similarity. "measure n-gram overlap against reference captions."
- Open-ended captioning: Free-form description generation without a single deterministic ground-truth answer. "a luxury not available in open-ended captioning."
- Policy (captioning policy): The probabilistic mapping from images (and prompts) to captions learned by the model. "The student VLM being trained is parameterized by , with captioning policy ."
- Reference policy: A frozen or slowly changing policy used to compute importance ratios and stabilize RL training. "and $\pi_{\theta_{\text{ref}$ is the reference policy."
- Reinforcement learning with verifiable rewards (RLVR): RL approaches where outputs can be automatically and deterministically checked for correctness. "feedback-driven optimization, specifically through reinforcement learning with verifiable rewards (RLVR)"
- Reward hacking: Exploiting flaws in the reward function to achieve high scores without solving the intended task. "This behavior represents a classic form of reward hacking"
- Rollouts: Sampled trajectories or outputs generated by the policy to be evaluated and used for updates. "For each image , we sample rollouts"
- Rubric-augmented SFT: Supervised fine-tuning where the model is given rubrics and asked to rewrite outputs to satisfy them before training. "we construct a rubric-augmented SFT baseline"
- Sample-specific rubrics: Per-example evaluation criteria tailored to an image and current model deficiencies. "sample-specific rubrics as fine-grained reward signals"
- Self-praising behavior: Degenerate outputs that proclaim quality rather than describing content, induced by flawed rewards. "this method eventually induces self-praising behavior"
- Supervised distillation: Training a smaller model to imitate outputs from a stronger teacher using labeled pairs. "supervised distillation often yields limited output diversity and weak generalization."
- Supervised fine-tuning (SFT): Updating a model on input–output pairs using standard supervised objectives. "supervised fine-tuning (SFT)"
- Teacher consensus: The agreement among multiple teacher models about salient, accurate elements to include in evaluation. "closing the quality gap toward teacher consensus."
- Verifiable domains: Task areas (e.g., math/code) where correctness can be reliably auto-checked. "its successes have so far been concentrated in verifiable domains"
- Vision-LLM (VLM): A multimodal model that processes images and text jointly. "vision-LLMs (VLMs)"
- VLM-as-a-Judge: Using a VLM to provide holistic quality ratings for candidate captions. "VLM-as-a-Judge:"
- Visual instruction tuning: Post-training that aligns VLMs to follow visual-language instructions. "visual instruction tuning~\citep{liu2023visual}"
- Win rate: The proportion of pairwise comparisons won by a model’s captions against a baseline or reference set. "achieves the highest win rates on CapArena"
- Word efficiency: The amount of salient information conveyed per word under strict length constraints. "it demonstrates superior word efficiency"
Collections
Sign up for free to add this paper to one or more collections.

