- The paper introduces generative frontiers as a novel evaluation method addressing pitfalls in traditional likelihood-based metrics for diffusion language models.
- It demonstrates that matched entropy or perplexity comparisons yield more reliable benchmarks by mitigating effects of inference-time tuning.
- Empirical insights reveal that early training produces generative frontiers nearly identical to fully-trained models, suggesting rapid convergence in performance.
Generative Frontiers: Principled Evaluation of Diffusion LLMs
Introduction
The surge of research into diffusion LLMs (dLLMs) has motivated a re-examination of evaluation methodologies, particularly at the scale of models comparable to GPT-2 small (~150M parameters). These models, which offer more flexible generative processes than their autoregressive analogs, admit a much richer set of training objectives, noising schemes, and inference algorithms. However, the standard evaluation frameworks—adapted from autoregressive modeling—are shown to have key limitations when directly transferred to dLLMs. This work systematically critiques these traditional practices, dissects the pitfalls of current generative and likelihood-based metrics, and proposes "generative frontiers" as a rigorous method for comparative evaluation, grounded theoretically in the decomposition of KL divergence into generative perplexity and entropy.
Pretraining Corpus Considerations
At the medium scale (~150M parameters), robust pretraining is critical for meaningful evaluation. OpenWebText has emerged as the de facto pretraining dataset, providing sufficient scale (~9B tokens), quality, and consistency with widely used benchmarks. Alternative datasets such as LM1B, despite historical relevance, introduce undesirable artifacts such as sentence-level shuffling, which obliterates inter-sentence coherence—a property central to realistic generation and downstream utility. This principled choice also enables reference-based evaluation, such as using GPT-2 large as the standard for generative perplexity assessment.
Inadequacy of Likelihood-based Evaluation
Direct likelihood or ELBO-based evaluation is ill-posed for dLLMs that differ in latent structures or variational families. The ELBO includes a KL slack term that is generally intractable and model-dependent, rendering comparisons between models with heterogeneous posterior parameterizations unreliable. Furthermore, as has been demonstrated for high-dimensional generative models [theis2016noteevaluationgenerativemodels], high likelihood does not necessarily coincide with high sample fidelity or utility for language generation tasks. Hence, likelihood serves only partially as a proxy for generative quality, particularly at moderate model scales where downstream adaptation is not performed.
Limitations of Standard Generative Metrics
Generative perplexity and unigram entropy have become common metrics for assessing dLLM generative quality. However, each exhibits important failure modes:
This sensitivity arises because generative perplexity and entropy are not independent; rather, they are the two components of the KL divergence from the model's generative distribution to the reference.
Theoretical Underpinning: KL Divergence Decomposition
The KL divergence between the generative distribution qgen and the reference pref is
KL(qgen∥pref)=H(qgen,pref)−H(qgen)
where H(qgen,pref) is the cross-entropy (proportional to generative perplexity) and H(qgen) is the entropy (approximated by unigram entropy) of generated samples. Critically, due to the exponential relationship in perplexity, a small decrease in entropy can disproportionately reduce generative perplexity even if the overall distance to the reference distribution does not improve. Thus, models can appear to outperform others through minor inference-time adjustments rather than substantive improvements in modeling capacity.
Generative Frontiers: A Principled Evaluation Framework
To address these ambiguities, the authors advocate "generative frontiers": For each model, sweep over inference-time parameters (notably softmax temperature) to trace out a curve of possible (entropy, perplexity) pairs, rather than reporting performance at an arbitrary operating point. This approach allows for reliable, apples-to-apples comparisons at matched entropy or perplexity, and provides immediate visual intuition for the trade-off surface of each model.
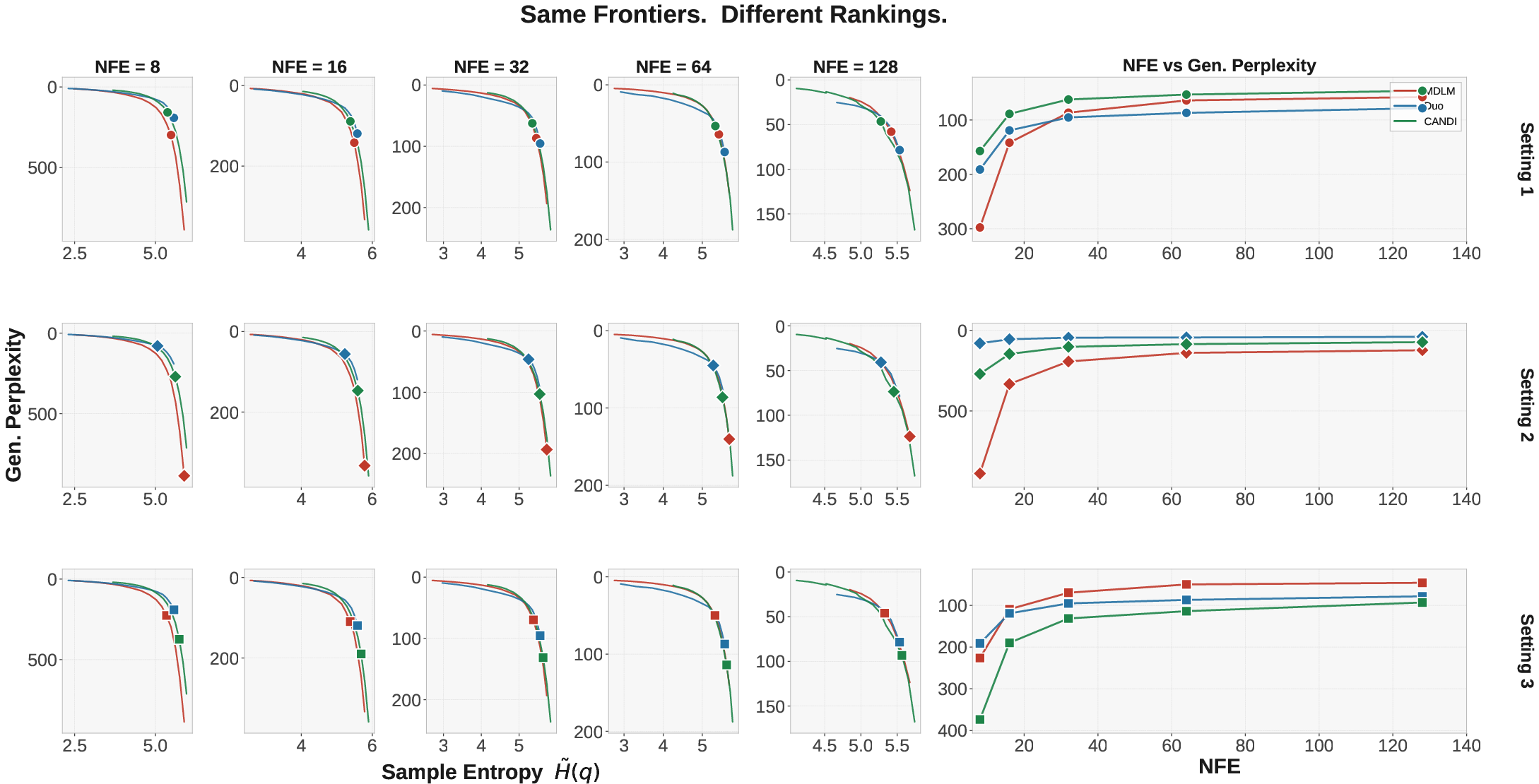
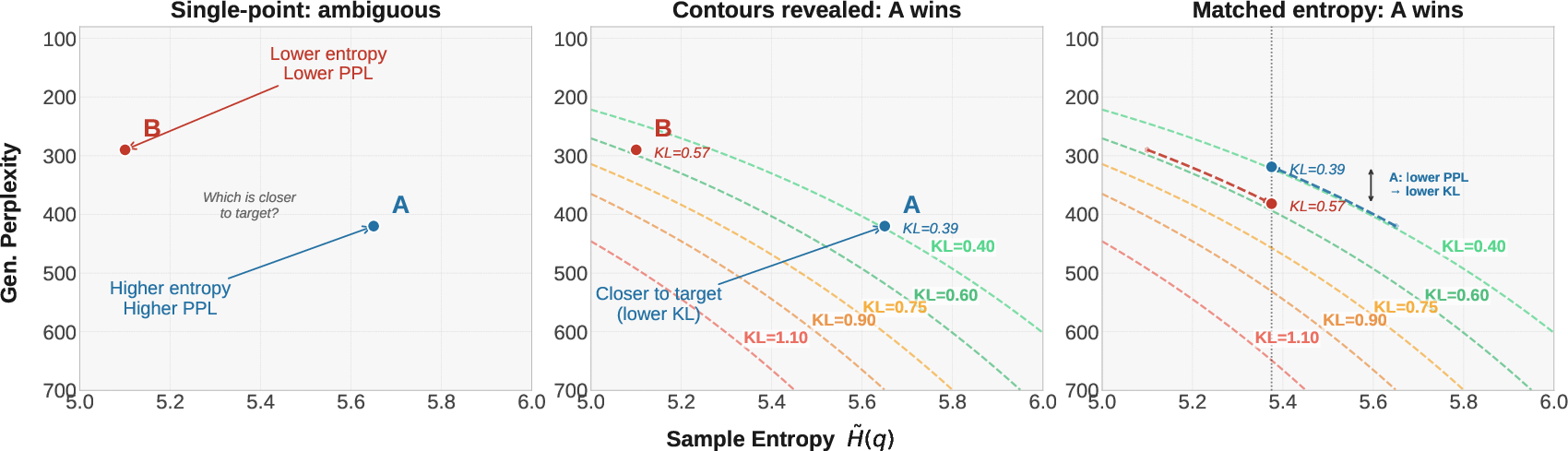
Figure 2: Single-point metrics correspond to slices of underlying generative frontiers; frontier comparison unifies and rationalizes disparate single-point rankings.
Operationally, frontier dominance (strictly lower perplexity at all entropy values, or vice versa) is a sufficient condition for lower KL divergence across the relevant range; if one model’s frontier lies everywhere below another’s, it is closer to the reference distribution at every operating point.
Frontier comparisons at entropy or perplexity values representative of the true data distribution, e.g., interquartile entropy range or median perplexity from natural language benchmarks, are especially informative for model selection.
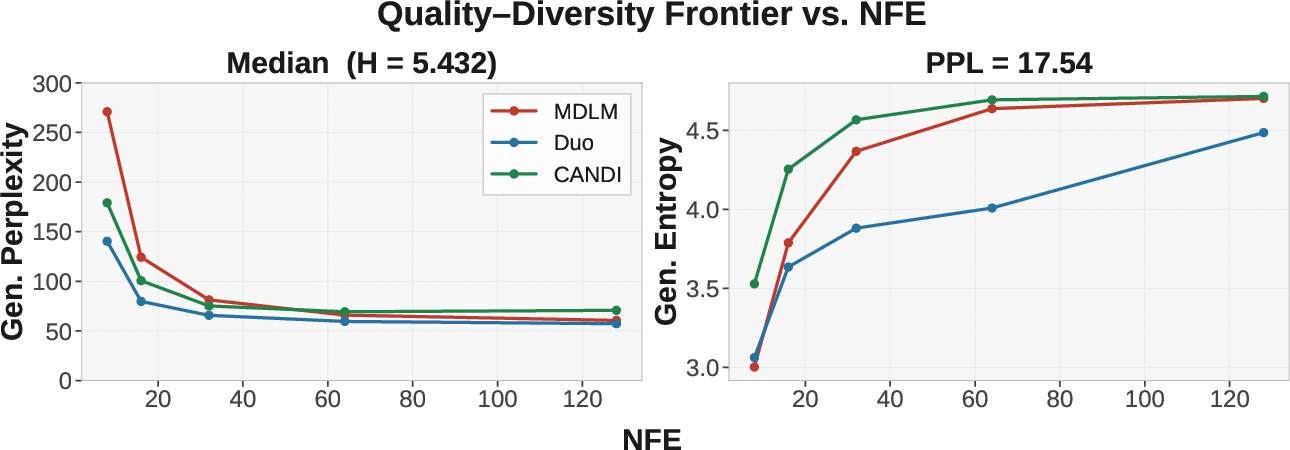
Figure 3: Median entropy and evaluation perplexity of OpenWebText validation can directly inform frontier comparisons. Different models may dominate in different ranges, expressing the multifaceted nature of generative quality.
Empirical Insights
A key empirical observation is that generative frontiers derived from models early in training (e.g., after 50K steps) often closely align with those from fully-trained checkpoints (1M steps), across multiple methods (MDLM, Duo, CANDI). This indicates that convergence in generative quality—as measured by frontiers—occurs rapidly and further prolonged training yields diminishing returns at this scale. This insight has concrete ramifications for the efficiency of algorithmic development and iteration on dLLMs.
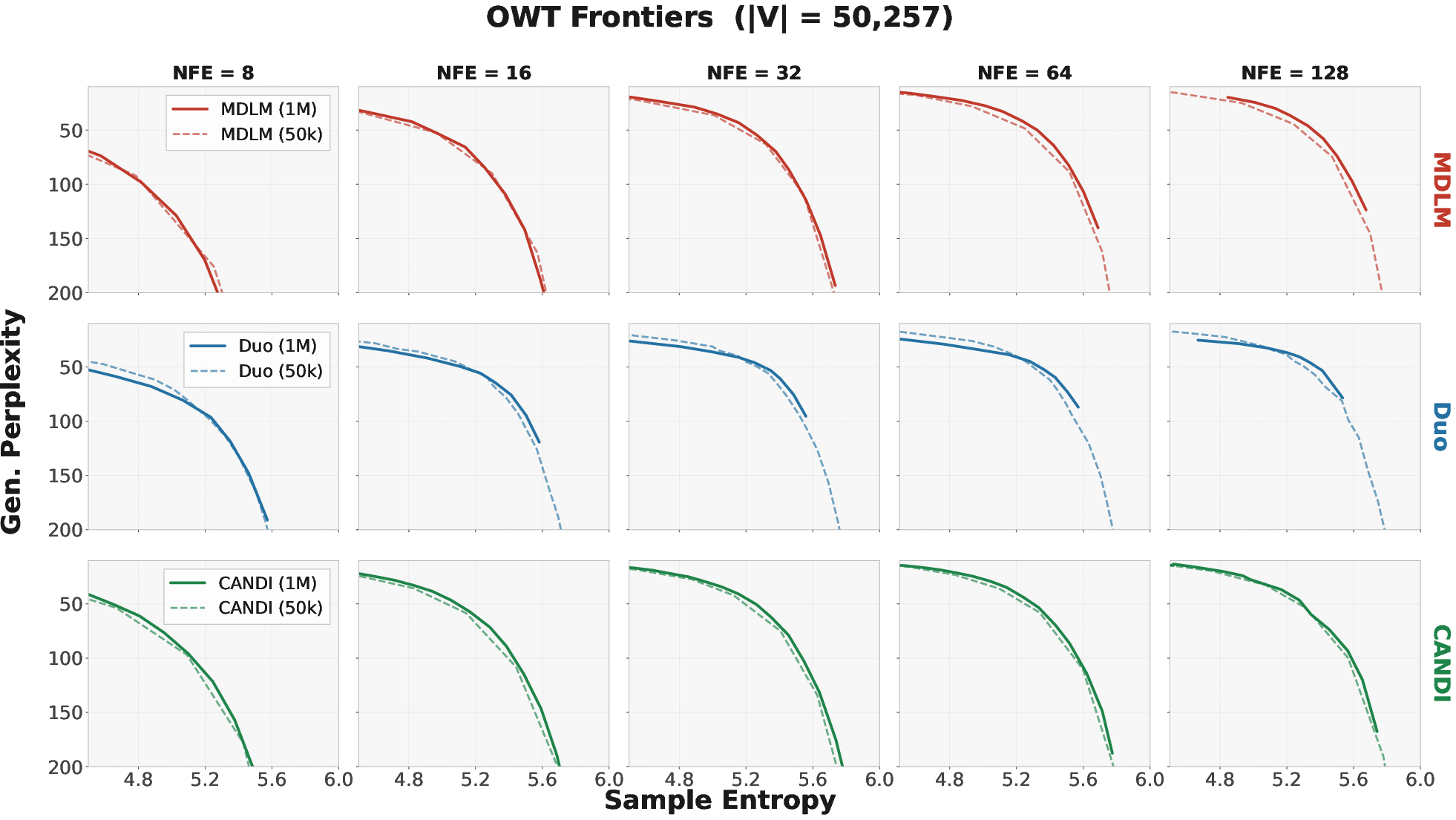
Figure 4: 50K-step and fully-trained checkpoints yield nearly overlapping generative frontiers, suggesting early training suffices for method assessment.
Practical and Theoretical Implications
By establishing generative frontiers as a baseline for model comparison, this work elevates the methodological rigor in dLLM evaluation. This framework:
- Prevents spurious claims based on metrics that can be trivially manipulated by inference-time hyperparameters.
- Enables robust benchmarking that disentangles model capability from superficial variational/inference choices.
- Suggests that future work on dLLMs should universally report generative frontiers, both to facilitate fair comparison and to expose the actual limits of model expressivity.
Moreover, this methodology can generalize to other non-autoregressive generative modeling paradigms where similar decouplings of diversity and fidelity metrics are observed.
Future Directions
Several open questions arise from this analysis. While unigram entropy is used as a practical surrogate for joint entropy, closer approximations may yield even finer-grained insights. As the field progresses to larger models and more diverse data sources, extending and possibly refining the frontier analysis—potentially integrating downstream, conditional, or structured quality metrics—will be necessary. Additionally, as dLLMs close the performance gap with autoregressive models, direct comparison of generative frontiers across architectures will facilitate deeper understanding of their relative strengths in various application domains.
Conclusion
This work demonstrates that traditional single-point metrics are insufficient for robust evaluation of diffusion LLMs, as they confound inference settings with genuine model quality. By linking entropy and generative perplexity through KL decomposition, and advocating for generative frontier analysis, the authors provide a principled, interpretable, and actionable framework for dLLM evaluation. This approach should serve as methodological guidance for future research in the development and assessment of non-autoregressive generative LLMs.
(2604.02718)