- The paper identifies a critical sampling interval where the transition to multimodal densities leads to out-of-distribution errors in DDPM-based discrete data generation.
- It demonstrates that techniques like self-conditioning, q-sampling, and Minimum Bayes Risk decoding significantly mitigate sampling failures, improving quality metrics.
- Through synthetic benchmarks and real-world evaluations on language, code, and protein tasks, the study quantifies the trade-offs between generation correctness and diversity.
Why Gaussian Diffusion Models Fail on Discrete Data? — An Expert Summary
Overview
The paper "Why Gaussian Diffusion Models Fail on Discrete Data?" (2604.02028) presents an in-depth theoretical and empirical analysis of the limitations of Gaussian diffusion models, specifically those employing the standard DDPM sampling solver, for generative modeling over discrete data. It identifies a fundamental failure mode that arises from the multimodal structure of noisified discrete distributions, demonstrates the negative impact on sample quality, and systematically evaluates practical heuristics—self-conditioning, q-sampling, and Minimum Bayes Risk (MBR) decoding—that mitigate these problems in both unconditional and conditional text generation, as well as in other discrete domains like code and proteins.
Discrete Data and Diffusion Model Dynamics
Diffusion models have produced state-of-the-art results on continuous domains including images and audio; however, their application to discrete domains remains suboptimal. The prevalent approach for discrete data (such as natural language) is to embed symbols into a continuous latent space, apply Gaussian diffusion noise, and use DDPM-based denoising solvers. Unlike continuous data—where clean data is supported on a low-dimensional manifold and the diffusion process transitions smoothly between data modes and the base prior—discrete datasets induce a mixture of isolated point masses (delta distributions) in embedding space.
Sampling in this setting yields a unique challenge: as diffusion proceeds, the distribution over latents (noisified data) transitions from unimodal to highly multimodal, manifesting low-density "gaps" between modes. Standard DDPM sampling, subject to discretization noise and score estimation errors, frequently enters these low-density regions, leading to out-of-distribution (OOD) noise for the denoiser, causing irrecoverable generation errors—i.e., it becomes impossible to map back to valid data points.
This is illustrated conceptually in the toy setup:
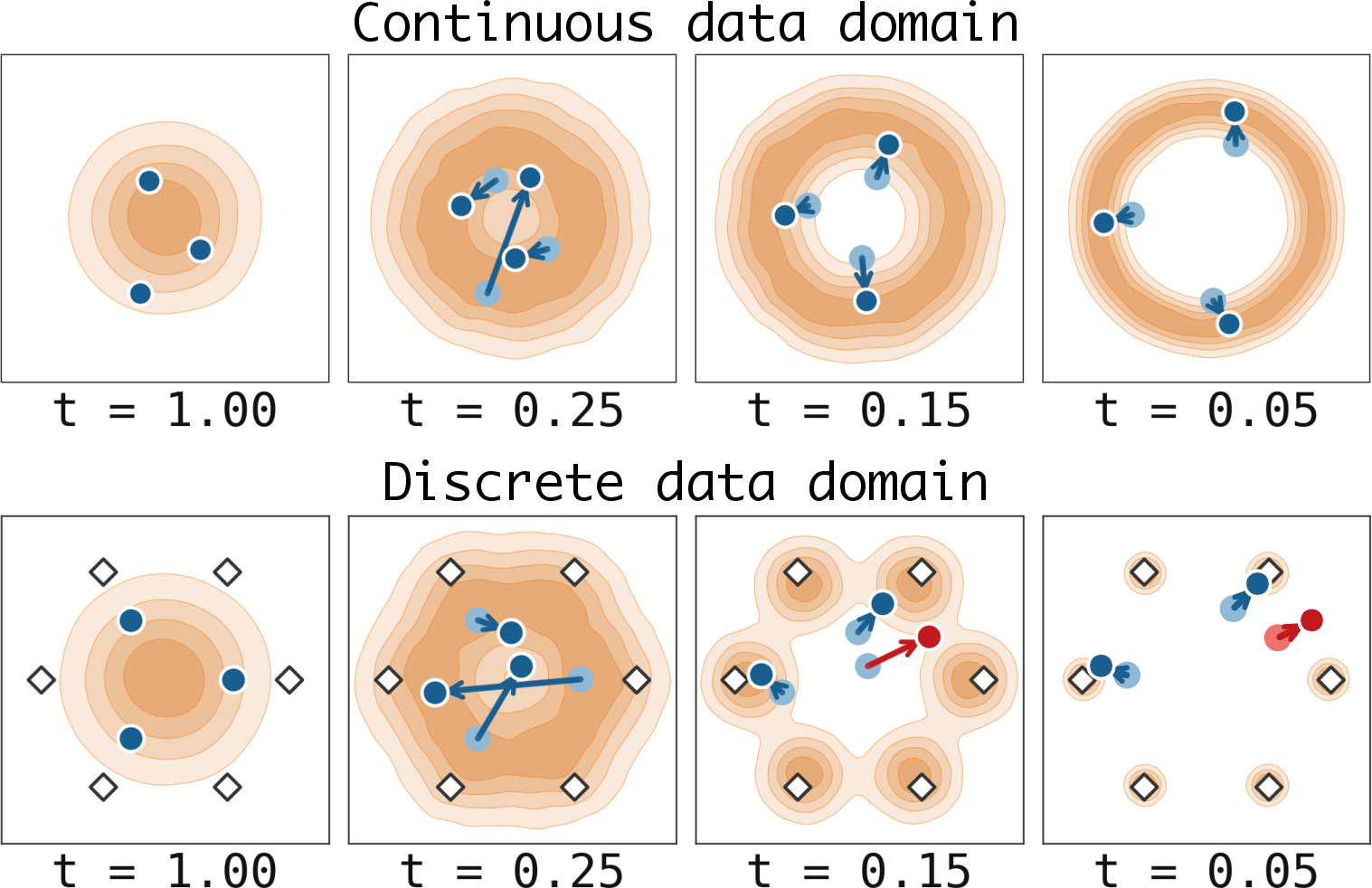
Figure 1: A toy visualization of the sampling trajectories of continuous diffusion models, showing the emergence of low-density intermodal regions in discrete data.
Key Claim: The critical sampling interval—when the distribution transitions to multimodality—is precisely when most DDPM-based generation failures originate.
Analysis via the Random Hierarchy Model
The paper employs the Random Hierarchy Model (RHM), a tractable synthetic benchmark where the discrete data support is finite and exact likelihoods can be computed. This allows separation of errors due to model misspecification from those due to sampling dynamics.
By tracking correctness (the fraction of valid samples) and sample densities along trajectories, the authors demonstrate that all sampling paths are essentially indistinguishable at early steps, but begin to bifurcate sharply at exactly the transition from unimodality to multimodality in the noisified latent space. Trajectories entering low-density regions never recover, resulting in OOD denoiser inputs.
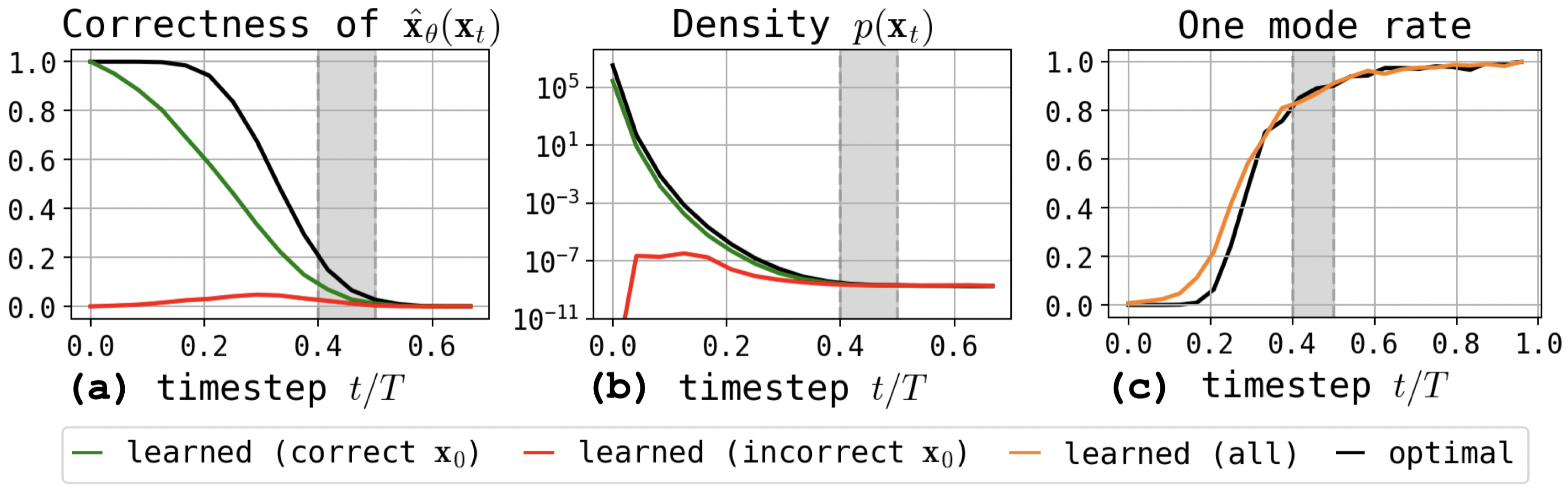
Figure 2: Correctness of model predictions and shift in predicted density along trajectories in the RHM; the critical interval is marked by a rapid divergence between correct and incorrect generations.
The analysis statistically confirms that, as modes emerge, DDPM can be trapped between them, unable to return to high-density regions due to the structure of the reverse process.
Mitigation: Practical Techniques to Address the Failure Mode
Minimum Bayes-Risk Decoding
MBR operates by branching trajectories in the critical interval and selecting final outputs with highest expected utility (e.g., via negative Hamming distance for tokens). Because branching at the transition interval yields similar candidates, MBR successfully filters out many modes corresponding to invalid sequences, improving correctness but introducing computational overhead.
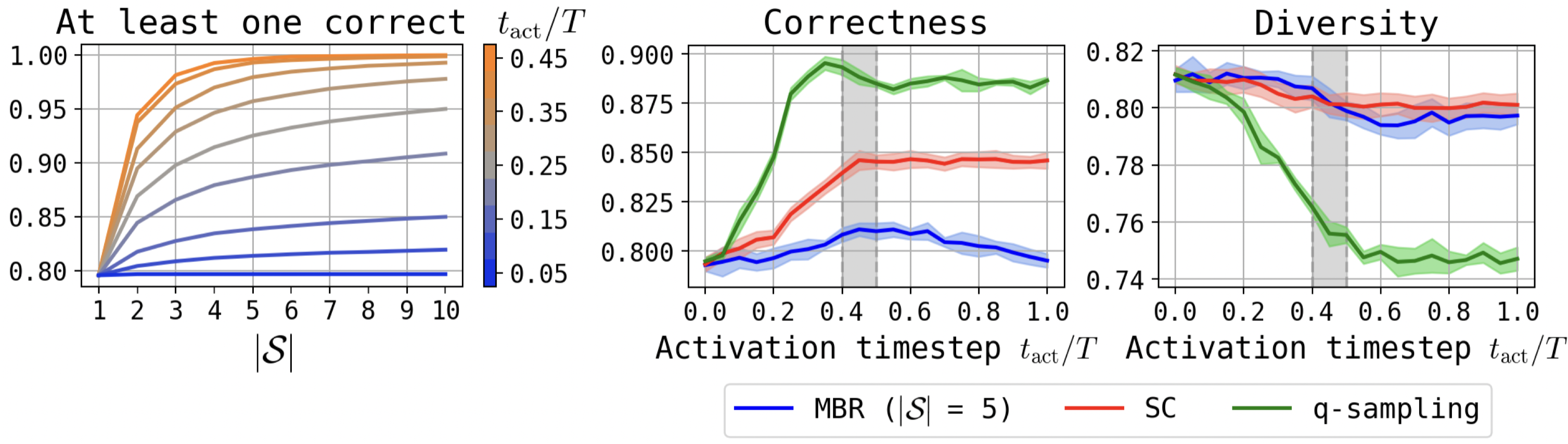
Figure 3: Fraction of candidate sets with at least one correct sample after branching at different activation steps; correctness and diversity trade-off under MBR, self-conditioning, and q-sampling.
q-Sampling
Q-sampling modifies the reverse update so that the denoiser output, rather than the previous latent, is more deterministically interpolated with fresh noise—mirroring the forward process. This effectively contracts the sample distribution, diminishing the probability of OOD excursions within the critical regime. Empirically, switching from DDPM to q-sampling within the transition interval recovers generation quality, although diversity is correspondingly reduced.
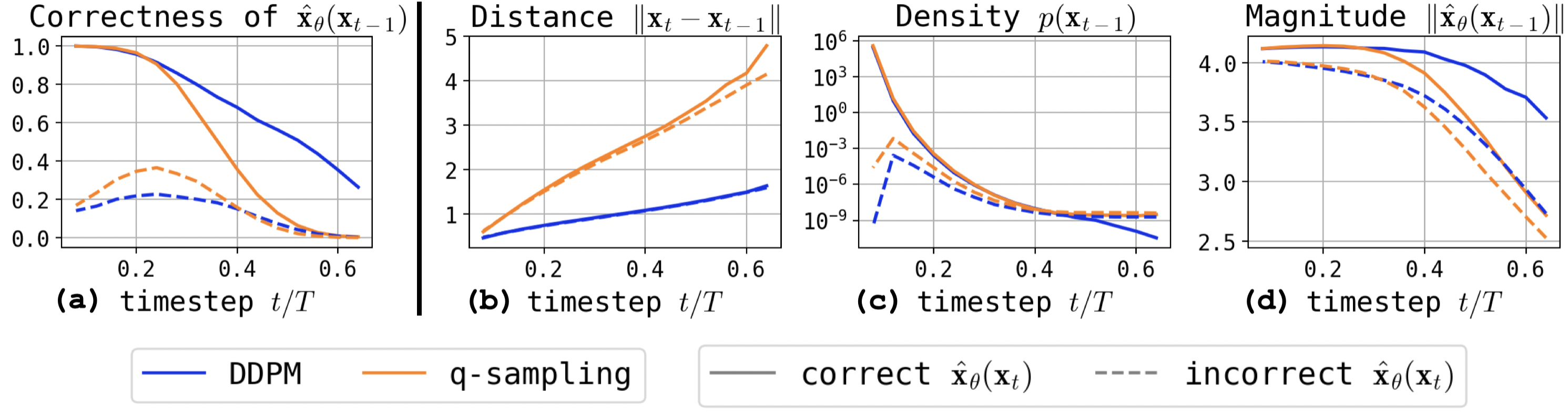
Figure 4: One-step update analysis comparing DDPM and q-sampling: q-sampling is less likely to preserve incorrect OOD states, pulling samples toward legitimate modes.
Self-Conditioning
Self-conditioning introduces the previous denoiser prediction as an extra input to the model at each timestep, stabilizing the reverse process. Empirically, self-conditioning consistently improves correctness, especially when applied with high probability during training, at a minor cost to output diversity. The mechanism is to anchor trajectories, restricting the capacity of stochasticity to push samples into OOD regions.
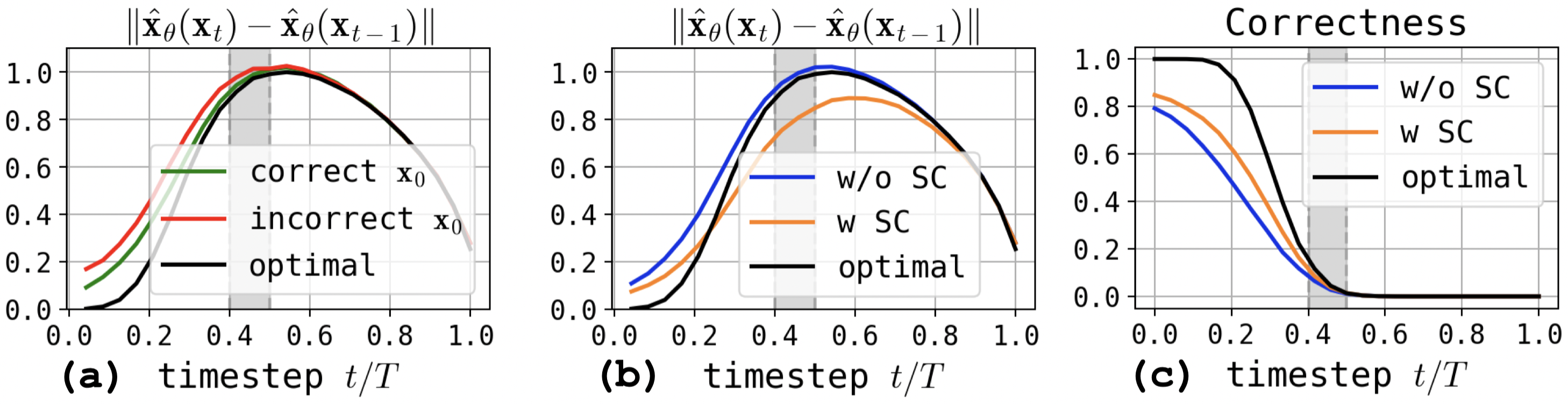
Figure 5: Self-conditioning contracts inter-step distances in the denoiser’s predictions, focusing trajectories away from low-density regions.
Summary of Effects
All three techniques (self-conditioning, q-sampling, MBR) reduce generation errors in discrete data diffusion by constraining trajectories to high-density regions—but at the cost of diversity, as some valid (but rare) discrete sequences become unreachable.
Empirical Evaluation on Real-World Data
The paper validates the above analysis at scale with unconditional and conditional language modeling, code generation, and protein sequence prediction tasks. Multiple architectures are tested, including Diffusion-LM and TEncDM. Three domains are evaluated: ROCStories, Wikipedia, and OpenWebText (as well as SwissProt for proteins).
Key findings:
- Self-conditioning is essential for unconditional generation, especially for models with only embedding-based (non-contextual) latent spaces. Increasing the probability of self-conditioning during training (e.g., p=0.95) consistently yields sharper improvements.
- q-sampling provides a practical, training-free alternative to stabilizing late-step sampling. Combined with self-conditioning, it achieves the best tradeoff between quality (measured by perplexity and Mauve) and diversity.
- Strong numerical results: For example, on ROCStories with TEncDM, naive DDPM achieves Mauve = 12.5, whereas q-sampling + SC attains 80.2, and the Embedding+Context model (TEncDM Enc) boosted to 86.8.
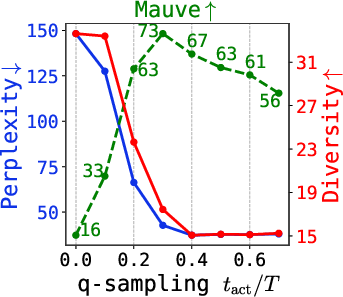
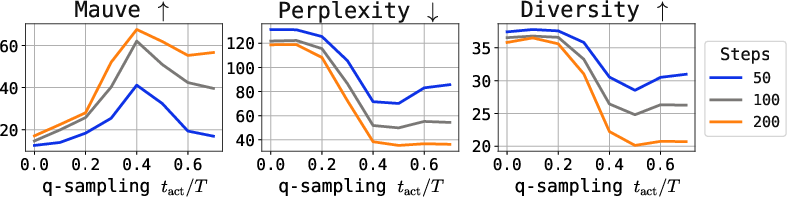
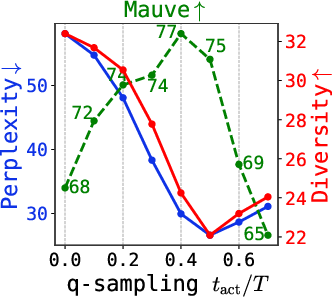
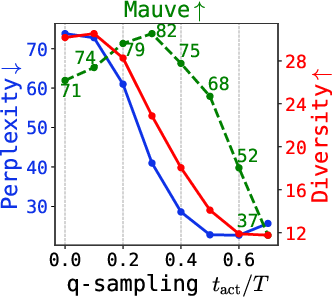
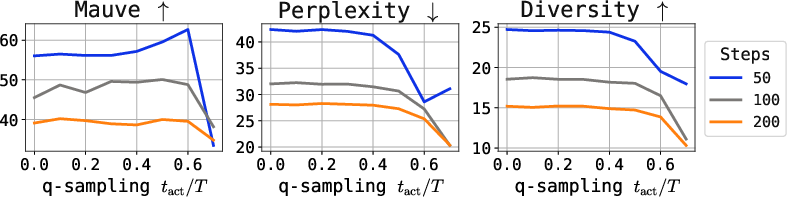
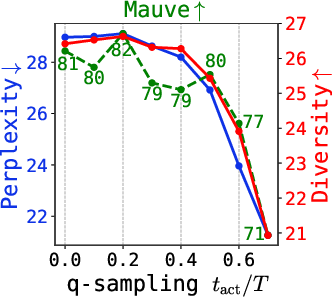
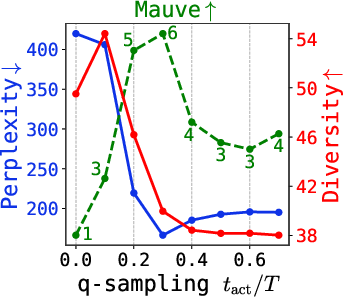
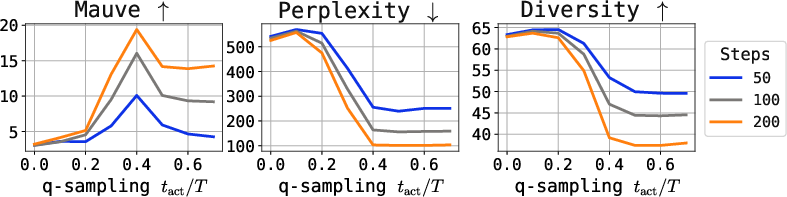
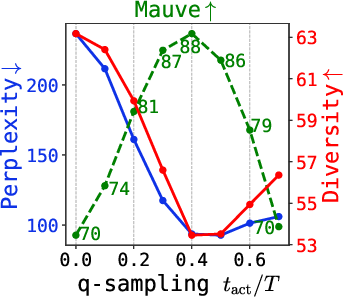
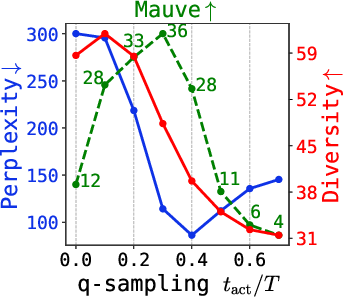
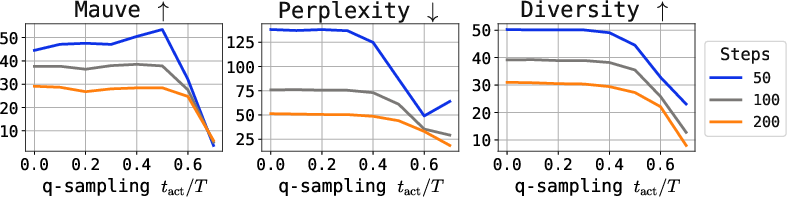
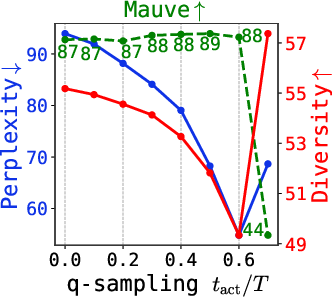
Figure 6: Quality metrics (Mauve, perplexity, diversity) under varying q-sampling activation and self-conditioning probability, for multiple tasks.
Further, the critical interval for q-sampling is insensitive to dataset and model size, making tuning practical.
The study also investigates conditional (seq2seq) tasks. The gains from self-conditioning and q-sampling are evident on tasks with weak conditioning (summarization, code generation), but minimal or negative on tasks with strong input-output dependency (MT, paraphrasing), reflecting their role in navigating ambiguous discrete output spaces.
Implications and Future Directions
The demonstration that DDPM fails on discrete data due to OOD trajectories in low-density intermodal space is a solid step toward understanding the generative limitations in text and other symbolic domains. While practical sampling heuristics alleviate the most acute failure cases, they trade off diversity, highlighting a foundational obstacle for generic Gaussian diffusion in discrete generative modeling.
Broader implications:
- Hybrid, context-dependent embedding methods (e.g., using encoder-based latents as in TEncDM) shrink the severity of the failure modes by smoothing the latent space, enabling more robust sampling.
- Investigation should focus on principled solvers for the late-phase multimodal regime, potentially leveraging mixture-of-experts, alternative noise schedules, or direct discrete-space diffusion.
- Sampling heuristics become less necessary as the latent structure approaches true continuity; thus, architectural advances and learned representations can reduce reliance on post-hoc fixups.
Conclusion
This paper rigorously explains the failure mechanisms of Gaussian diffusion models with DDPM solvers for discrete data, grounding the analysis in precise probabilistic structure and extensive empirical study across domains. It establishes the necessity of self-conditioning and/or q-sampling for high-quality generation in discrete settings, while clarifying the limitations inherent in sample diversity. Future directions include the design of models and inference algorithms that harmonize the strengths of both discrete and continuous generative frameworks without recourse to fragile heuristics.
(2604.02028)