- The paper demonstrates that MDMs achieve near-optimal TER with a constant number of sampling steps, offering efficiency in token-level generation.
- Empirical results reveal that while MDMs maintain low perplexity, achieving low SER requires steps that scale linearly with sequence length.
- The study underscores MDMs’ potential for fluent text generation while highlighting challenges in tasks demanding high sequence-level accuracy.
Theoretical Benefit and Limitation of Diffusion LLM
The paper provides a comprehensive theoretical and empirical analysis of Masked Diffusion Models (MDMs) for language generation, highlighting their benefits and limitations. The focus is on comparing MDMs with traditional autoregressive models concerning computational efficiency and accuracy, especially under different evaluation metrics such as Token Error Rate (TER) and Sequence Error Rate (SER).
Introduction to Diffusion LLMs
MDMs have emerged as a promising alternative for sequence generation, leveraging parallel token generation for enhanced efficiency over autoregressive models. The paper introduces MDMs in the context of existing diffusion models, explaining their ability to mask and iteratively predict tokens in parallel. However, the efficiency gains in MDMs are contingent upon the evaluation metric used.
Evaluation Metrics: TER and SER
The study utilizes two distinct metrics to assess MDM efficiency: TER and SER. TER evaluates token-level accuracy, typically measured in terms of perplexity, whereas SER examines the correctness of entire sequences, crucial for reasoning tasks. MDMs exhibit a strong performance in terms of TER, demonstrating that they can achieve near-optimal performance with relatively few sampling steps, irrespective of sequence length. However, SER reveals the limitations, as the number of sampling steps required for low SER scales linearly with sequence length, offsetting potential efficiency advantages.
Theoretical Analysis and Results
The authors provide a theoretical foundation for understanding MDM efficiency:
- TER Analysis: Under mild assumptions, MDMs can achieve near-optimal TER with a constant number of sampling steps, offering significant efficiency gains over autoregressive models.
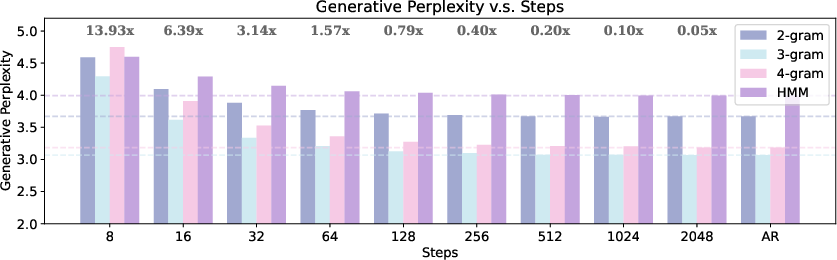
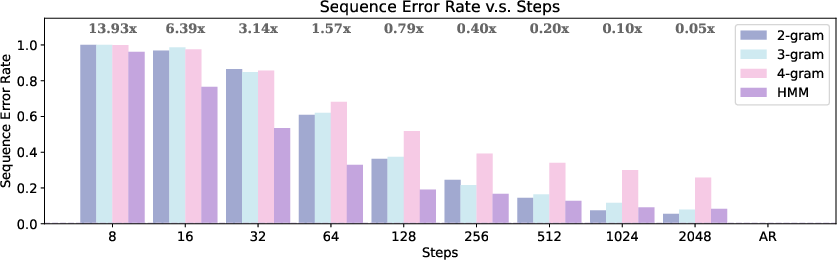
Figure 1: Sampling Efficiency and Quality of MDMs on Formal Languages: The above subfigure illustrates generative perplexity of generated sequences versus the number of sampling steps for n-gram languages.
- SER Analysis: For achieving low SER, the number of required sampling steps must increase linearly with sequence length, eliminating the parallel sampling efficiency benefits of MDMs. This is notably problematic for tasks where sequence-level correctness is paramount, such as mathematical reasoning or logical deductions.
Empirical Validation
The empirical studies confirm theoretical findings, showing that MDMs require significantly fewer steps to achieve performances close to autoregressive models in terms of perplexity. However, in tasks demanding high sequence accuracy, the number of necessary sampling steps increases, diminishing the computational advantage.
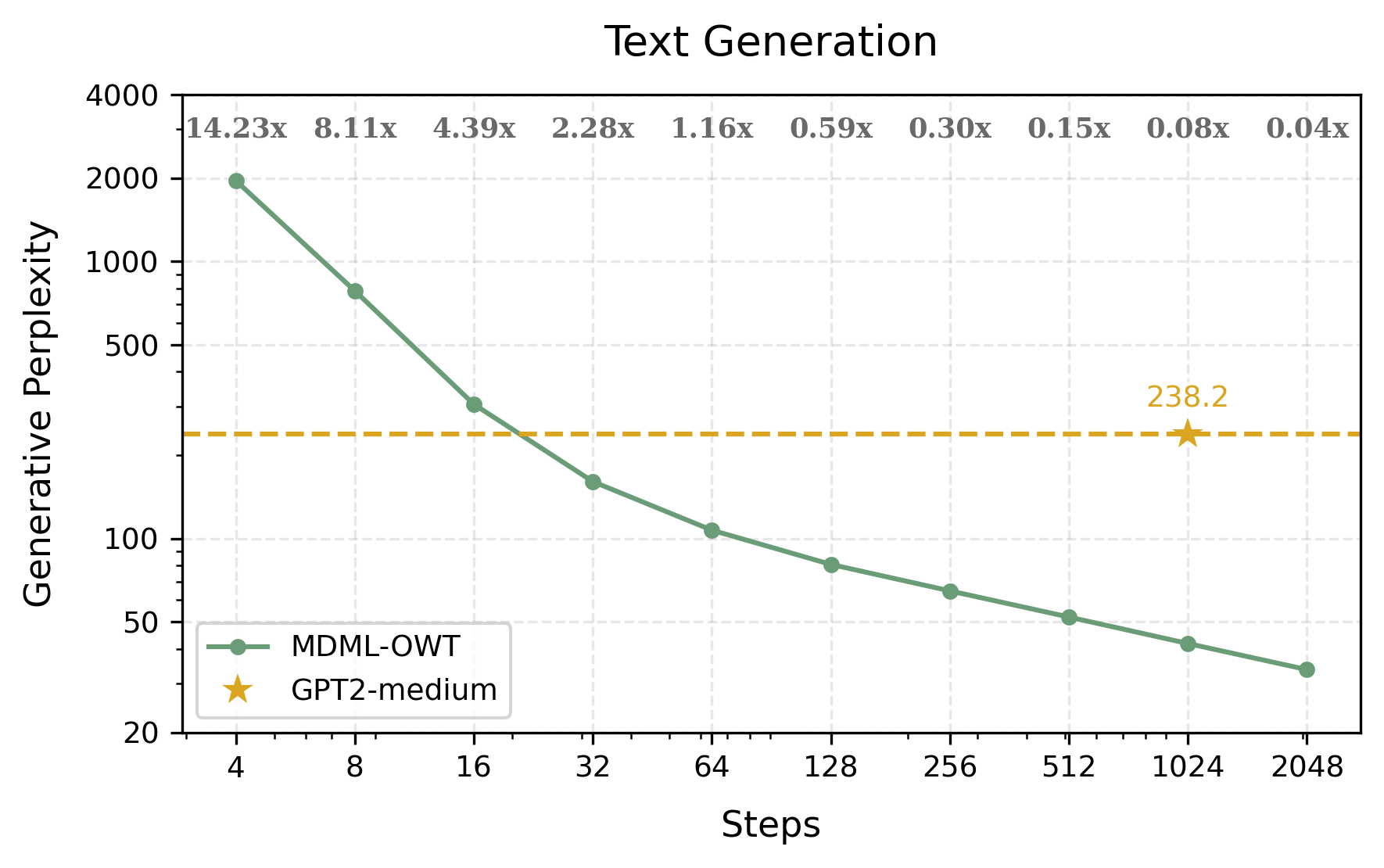
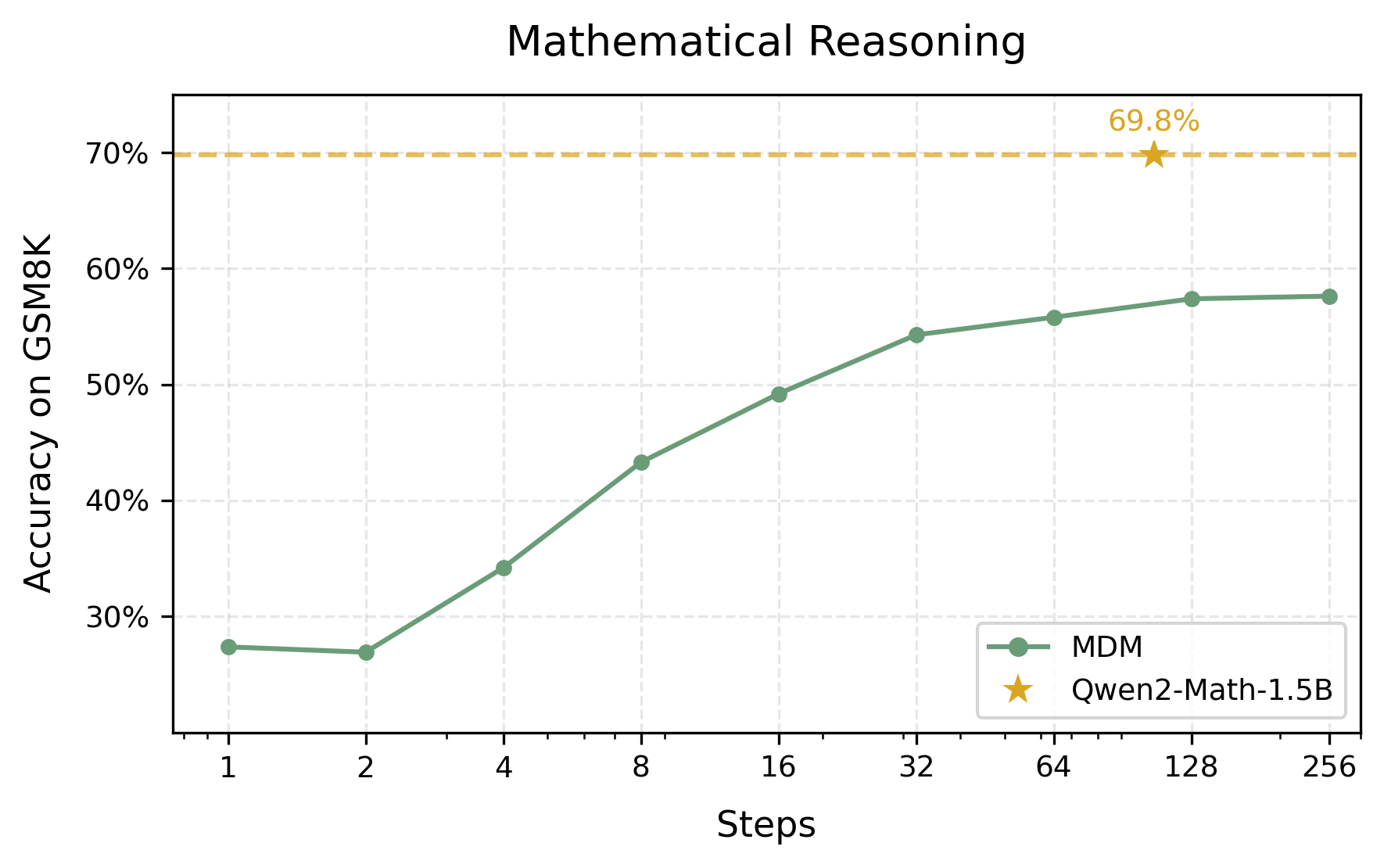
Figure 2: Evaluation on Language Tasks: The left subfigure illustrates the text generation quality of MDLM-OWT across different sampling steps, with GPT2-medium as baseline.
Implications and Future Work
The paper outlines practical implications of using MDMs, suggesting their promising application in fluency-prioritizing scenarios like general text generation. Conversely, their deployment for reasoning tasks remains less advantageous compared to autoregressive models. The authors propose further exploration in optimizing diffusion schedules and consider more advanced LLMs beyond HMMs.
Conclusion
While MDMs present a compelling paradigm for efficient text generation under certain conditions (notably TER), their application to tasks requiring high accuracy at the sequence level remains limited compared to traditional autoregressive approaches. The research invites future exploration into more complex models and broader diffusion LLMs to mitigate these inherent limitations.

