- The paper presents a discovery pipeline combining sparse autoencoders, k-subspace clustering, and neural simplex fitting to identify simplex-structured belief geometries in language model activations.
- It demonstrates robust recovery of simplex components, achieving significant barycentric predictive advantages and mean R² improvements in both toy models and Gemma-2-9B data.
- Key insights include distinguishing genuine mixture encoding via causal steering and predictive tests, suggesting implicit Bayesian inference in natural language models.
Detailed Analysis of "Finding Belief Geometries with Sparse Autoencoders" (2604.02685)
Background and Motivation
The paper addresses the geometric structure of latent representations in large pretrained LLMs, focusing on the presence and functional significance of simplex-shaped subspaces encoding probabilistic belief states ("belief geometries"). Prior evidence exists for such geometric encodings in transformers trained on hidden Markov models (HMMs), where barycentric coordinates of simplices correspond to belief distributions over discrete latent states [shai2024transformers, piotrowski2025constrained]. This work investigates whether analogous structures arise in residual streams of LLMs trained on naturalistic text, without access to ground-truth latent information.
Methodology: Belief Geometry Discovery Pipeline
The proposed discovery pipeline integrates sparse autoencoders (SAEs), k-subspace clustering, and neural simplex fitting via AANet. The approach is designed to identify and validate candidate simplex-structured clusters in model activation spaces:
- SAE Decomposition: Residual-stream activations (Gemma-2-9B, layer 20) are encoded with GemmaScope JumpReLU SAE, generating high-dimensional sparse latent features.
- k-Subspace Clustering: Decoder directions in the SAE latent space are clustered to identify feature groups potentially co-encoding contextual variables (preferentially in low-rank subspaces).
- Simplex Fitting with AANet: Each cluster is fit with AANet, a neural archetypal analysis method, to test for simplex structure and recover barycentric coordinates relative to learned extreme points.
- Functional Validation: Candidate geometries are evaluated via barycentric predictive advantage (primary discrimination test), causal steering, KL divergence, and semantic coherence.
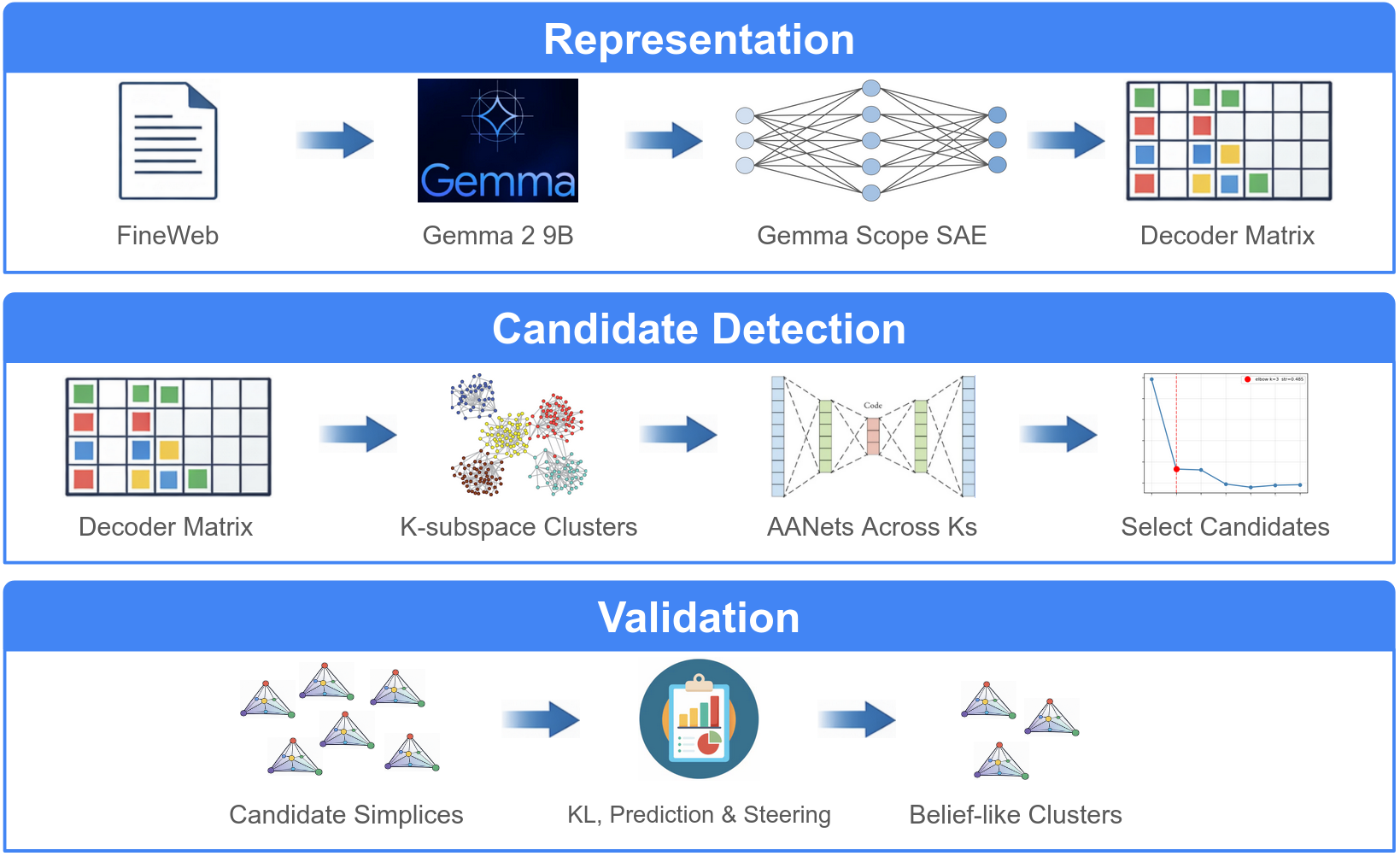
Figure 1: Overview of the belief geometry discovery pipeline combining SAEs, clustering, simplex fitting, and rigorous validation.
Proof of Concept on Toy Model
The pipeline first undergoes validation using a multipartite HMM-based toy model with controlled ground-truth belief geometry. In this regime—characterized by high joint entropy and cross-component signal entanglement—SAEs and clustering robustly recover all five generative simplex components, achieving mean R2=0.61 on held-out data. This demonstrates the pipeline's efficacy in identifying true belief geometries even under noisy, entangled signal conditions.
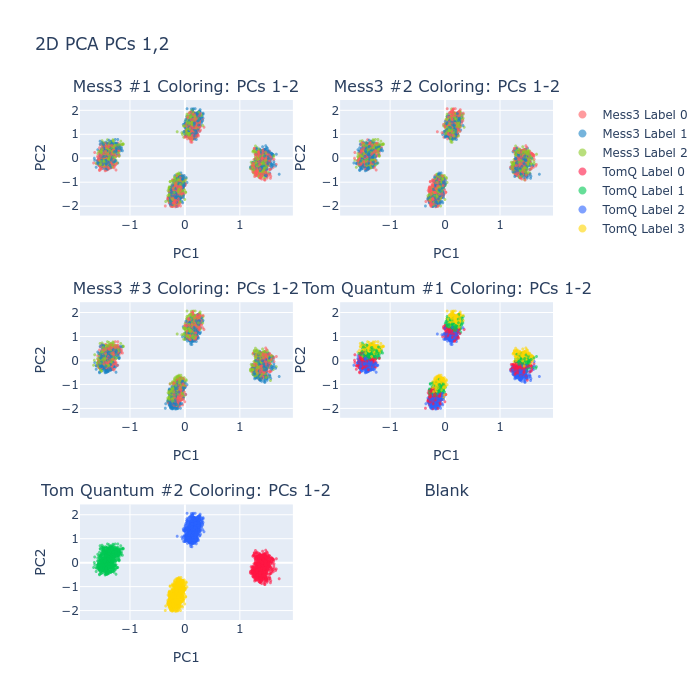
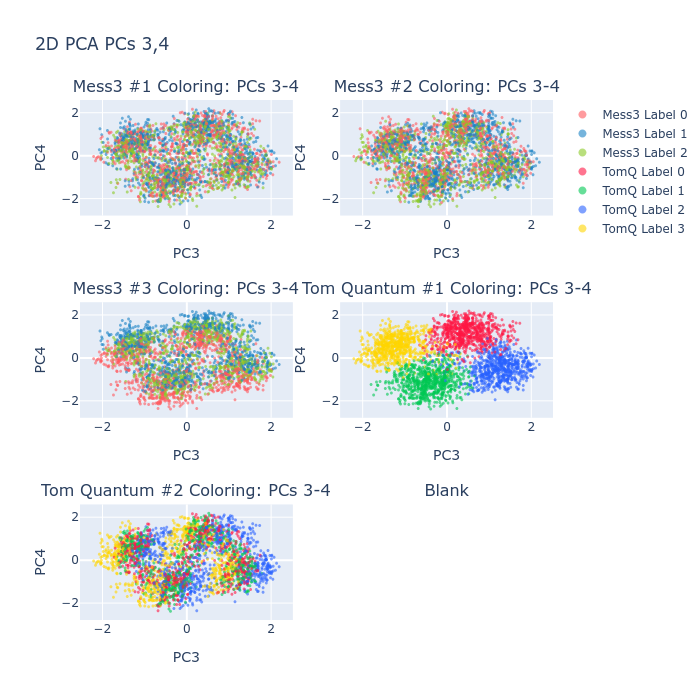
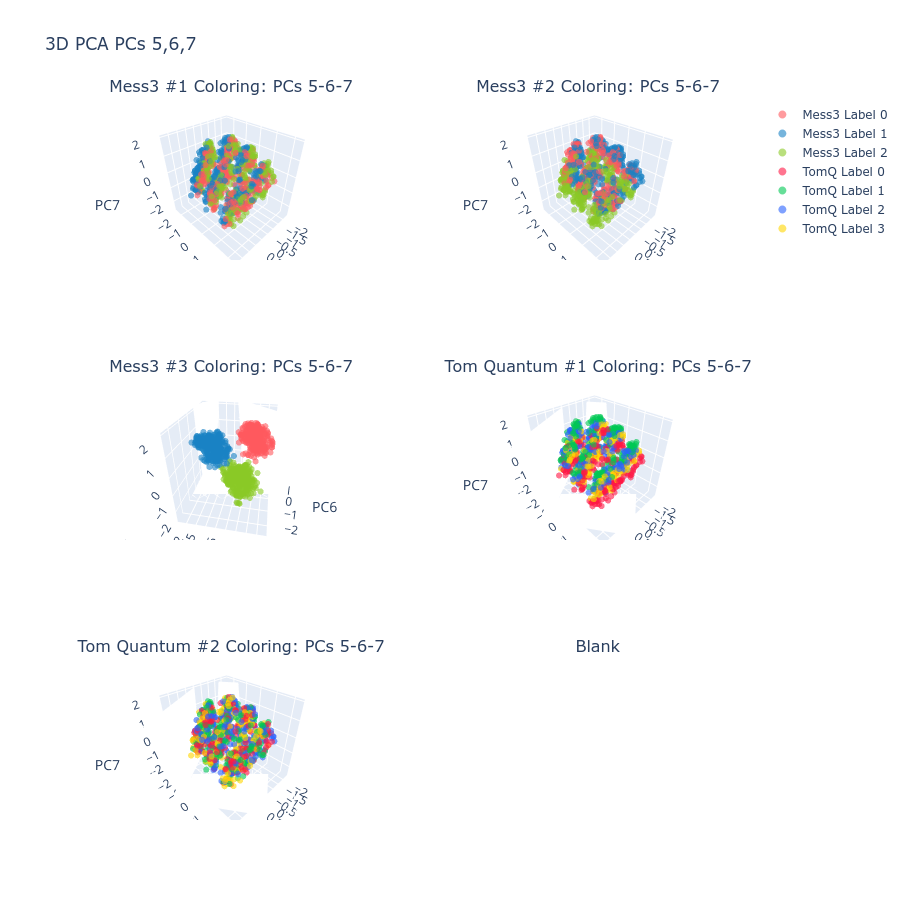
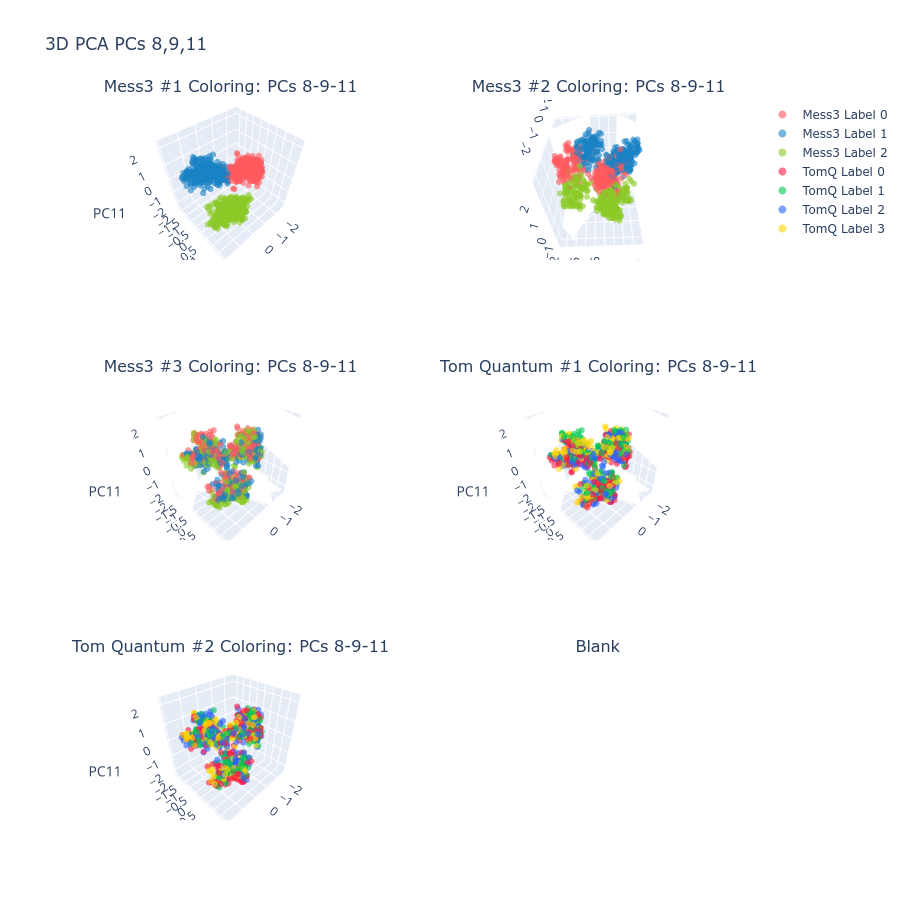
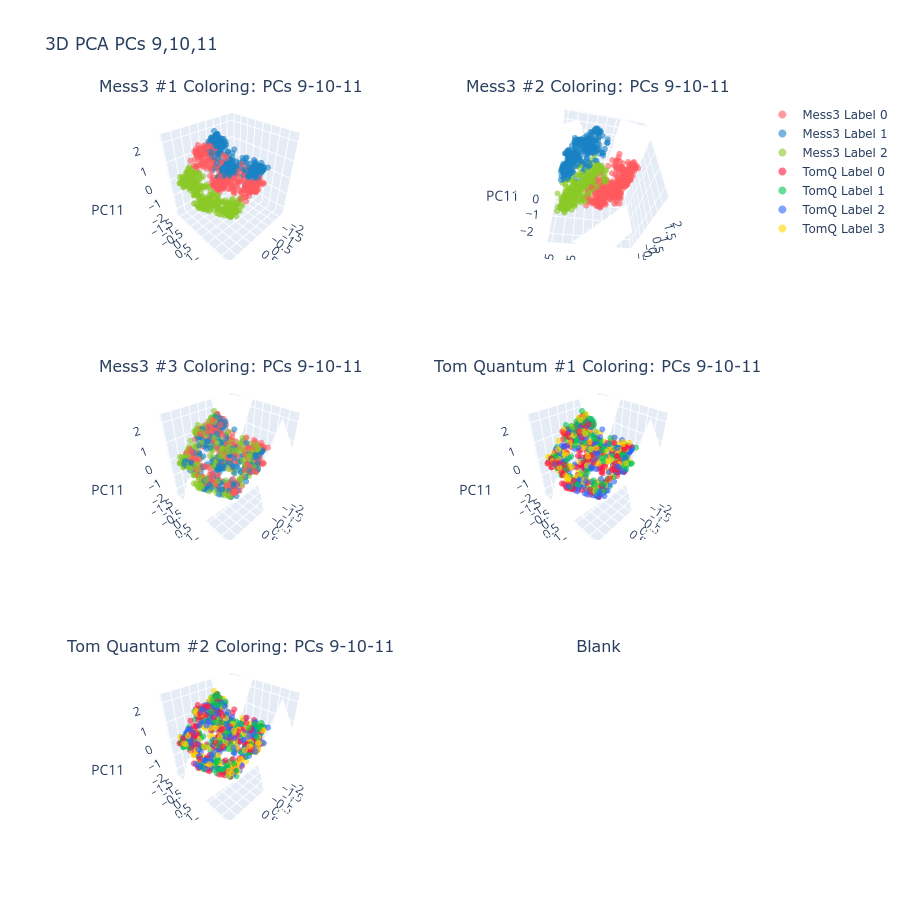
Figure 2: Token classes for Tom Quantum component are fully separated in the principal subspace, exemplifying strong geometric structure.
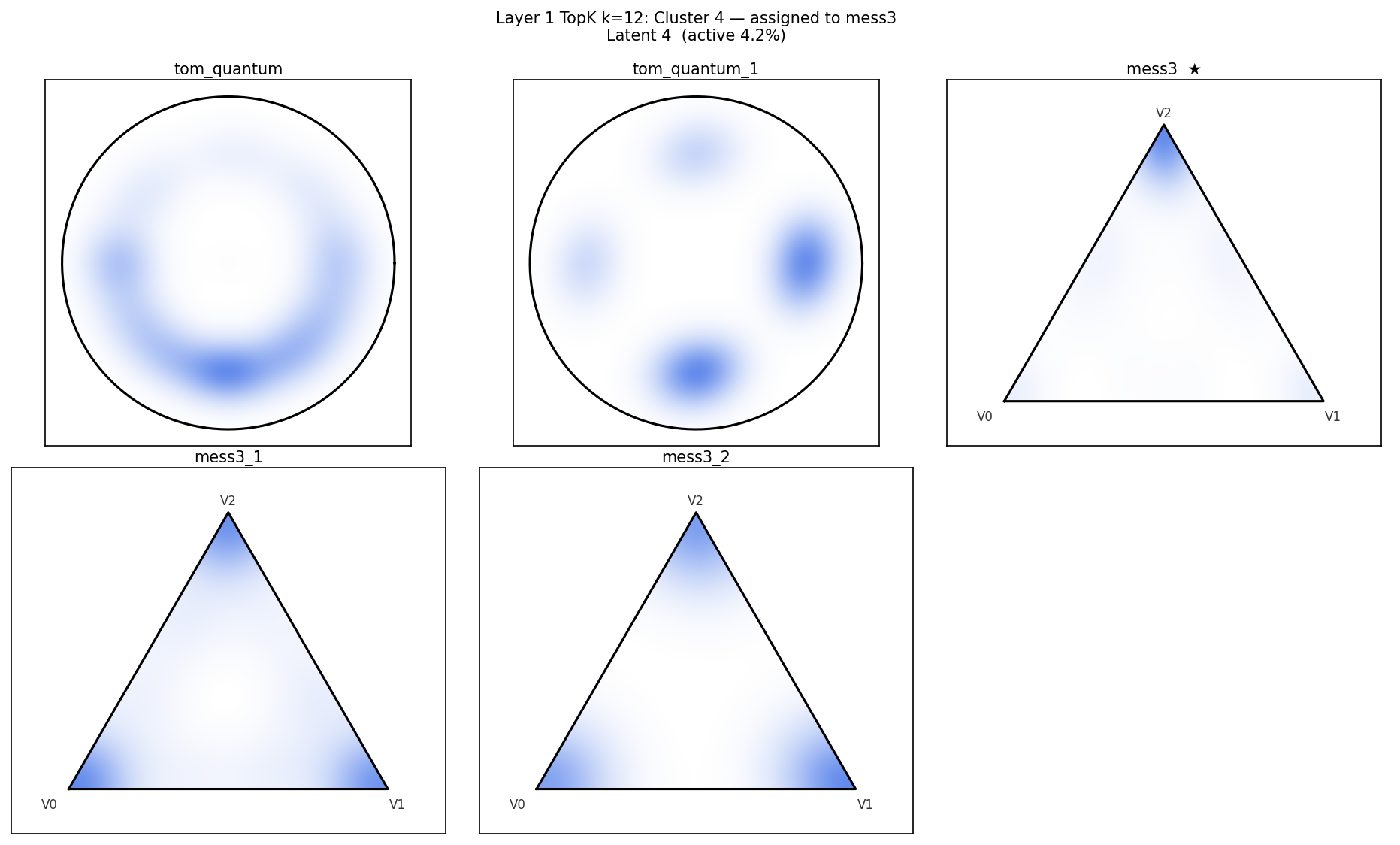
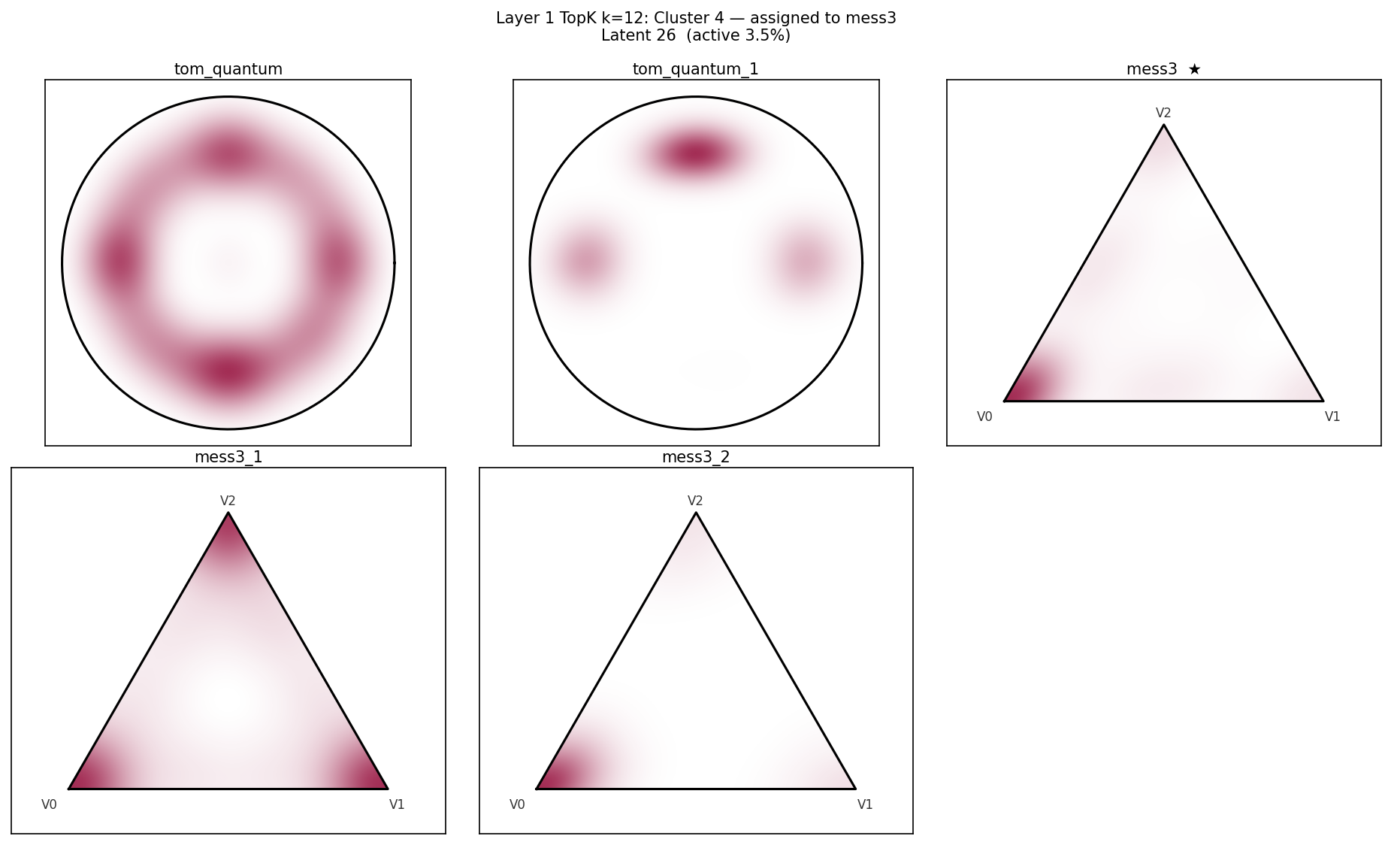
Figure 3: Representative latents tile complementary regions of the simplex, showing geometry-consistent partitioning of belief-state information.
Application to Gemma-2-9B: Real Data Analysis
The pipeline is applied to Gemma-2-9B, using SAE latents at layer 20. k-subspace clustering at two resolutions yields 13 priority clusters (with K≥3), selected for further validation. Null clusters constructed by random partitioning demonstrate sparse geometric pass rates, underscoring the specificity of the pipeline.
Validation: Discriminating Genuine Belief-State Encoding
Barycentric Predictive Advantage
The primary test is whether barycentric coordinate vectors for each cluster predict next-token log-probabilities better than any individual latent, evaluated via paired R2 comparisons and Wilcoxon signed-rank tests.
- Result: 5 of 13 real clusters exhibit significant barycentric advantage (p<10−14), outperforming the best single latent for both near-vertex and simplex-interior samples. No null cluster achieves significance on either split.
- Interpretation: This rules out tiling artifacts, indicating that these clusters encode genuine mixture representations rather than coverage of distinct context regions by single latents.
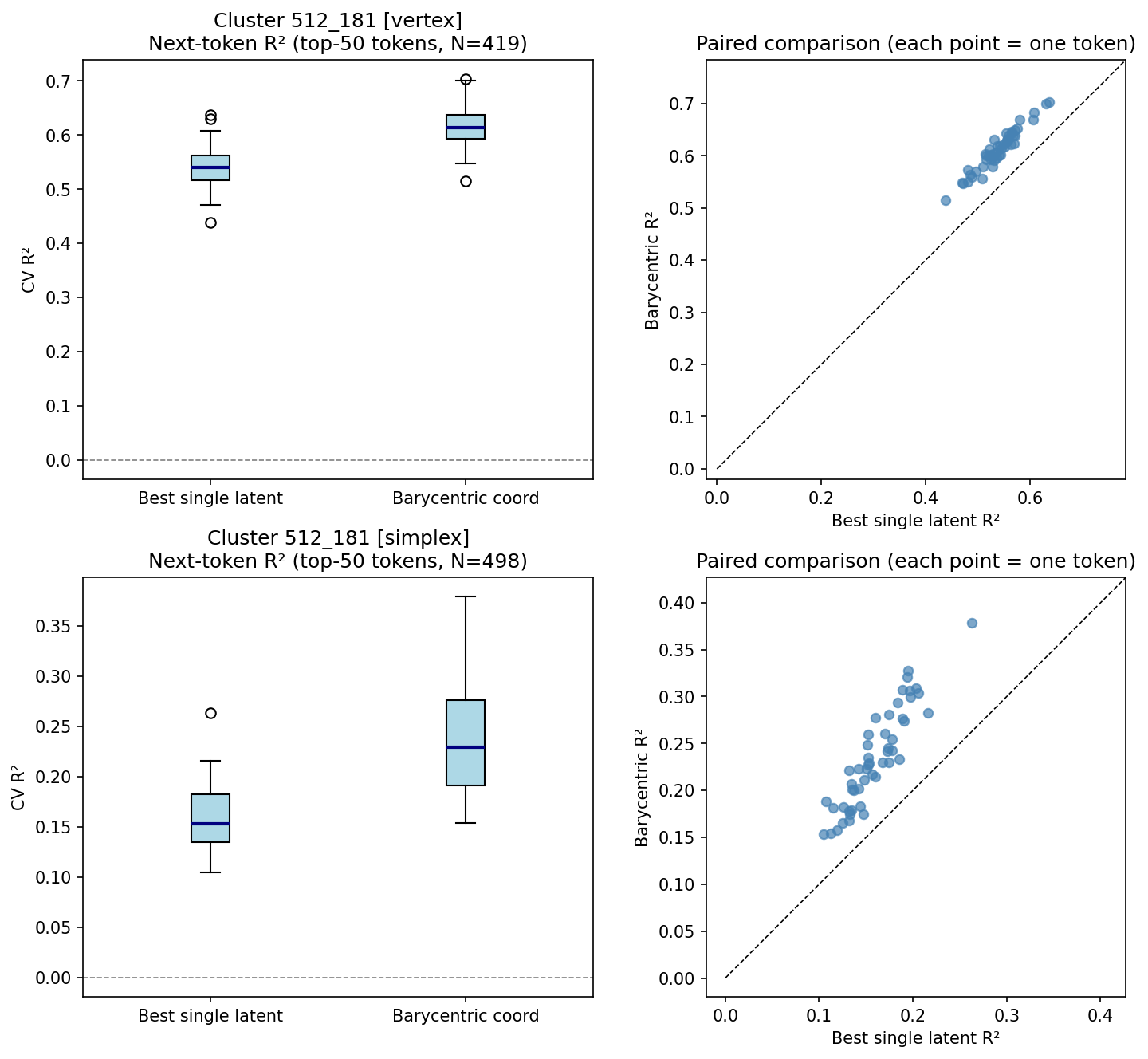
Figure 4: Cluster 512_181—barycentric coordinates (R2=0.612) significantly outperform best latent (R2=0.539) for all tokens.
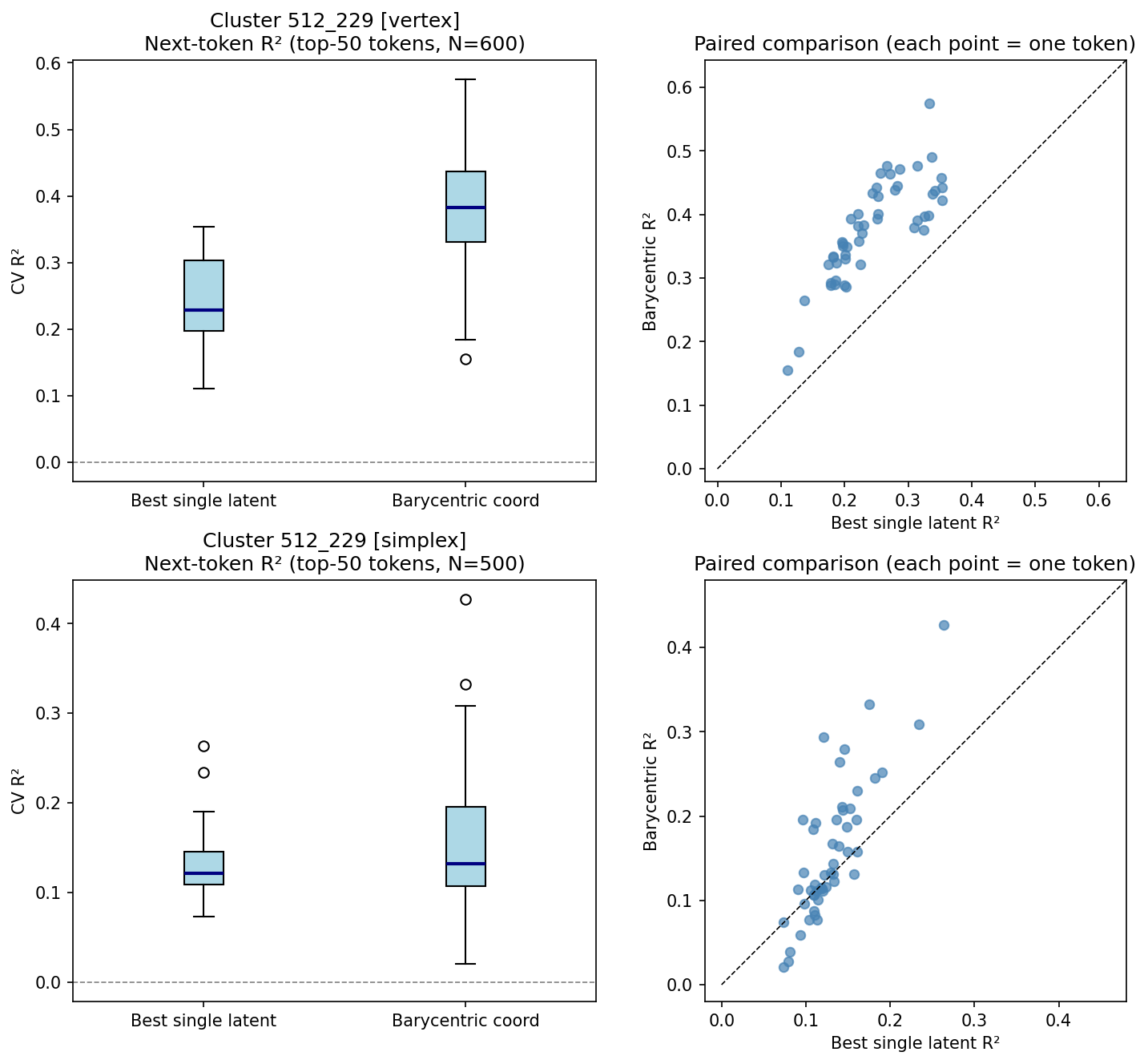
Figure 5: Cluster 512_229—barycentric coordinates (R2=0.378) outperform best latent (k0) for every token.
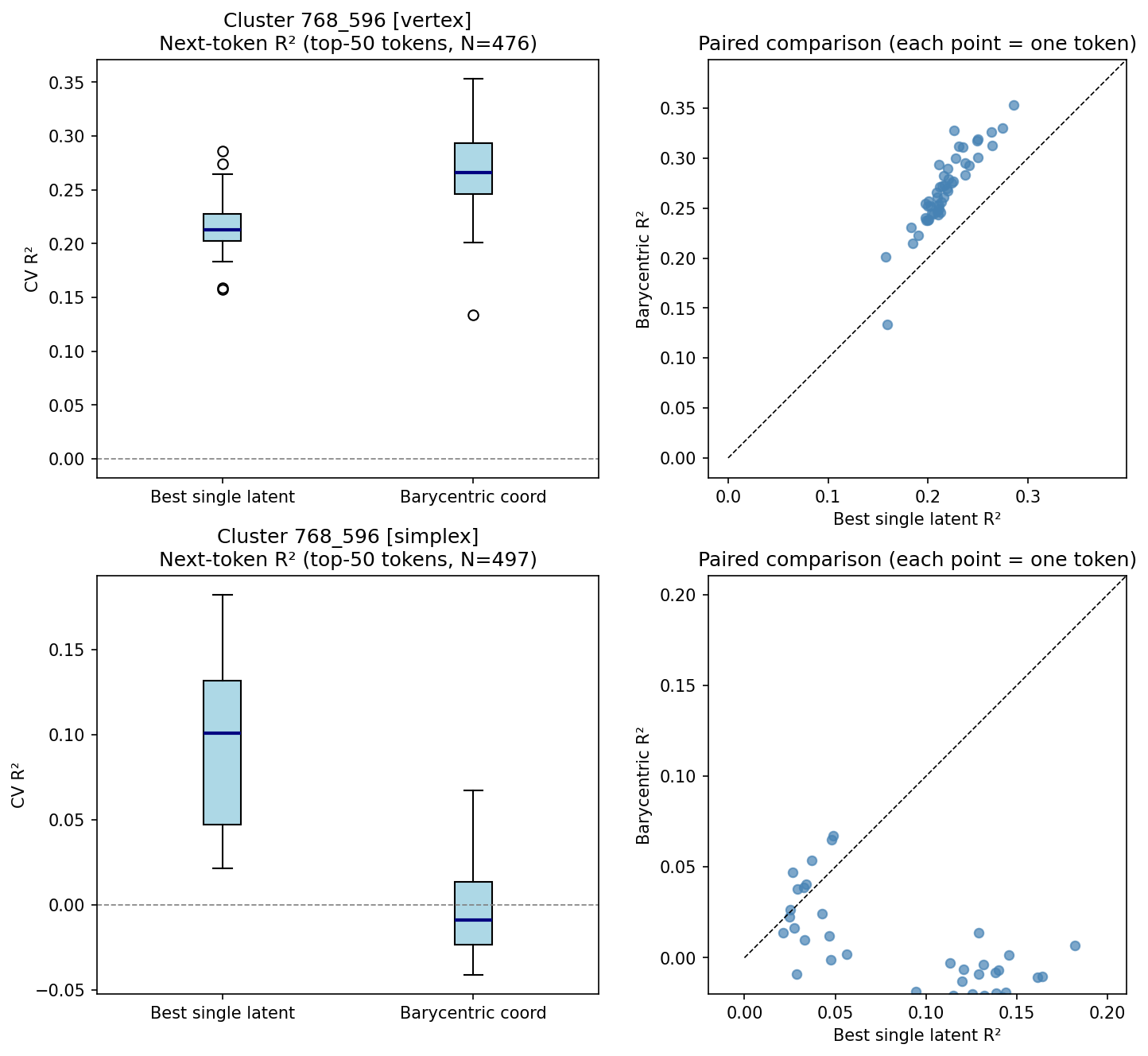
Figure 6: Cluster 768_596—barycentric coordinates (k1) outperform best latent (k2) for 98% of tokens.
Causal Steering
Only clusters with semantically interpretable and consistent simplex labeling are eligible for steering evaluation. In causal intervention tests (steering the residual stream toward simplex vertices), Cluster 768_596 exhibits a steering score of 0.419, the highest in the dataset; however, the overlap between steering scores for real and null clusters limits its discriminative utility except for 768_596, where significant barycentric advantage and steering effect converge.
Functional and Semantic Interpretations of Geometries
Cluster 768_596 partitions latents across simplex vertices corresponding to grammatical person (third, first, second), with evidence for mixture encoding at extreme points.
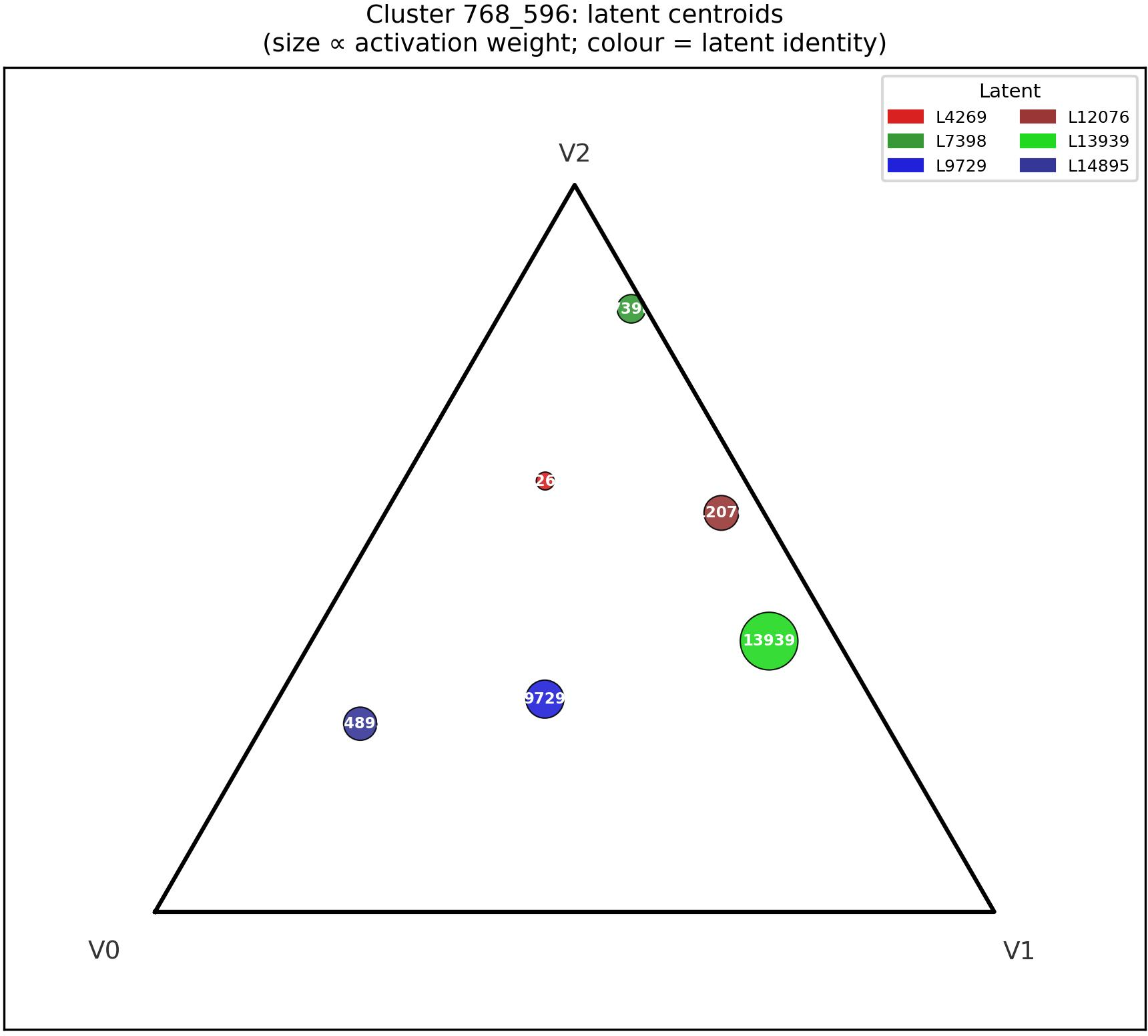
Figure 7: Mean barycentric centroid of latents in 768_596, partitioned across simplex vertices (consistent with feature specialization).
Cluster 512_181 demonstrates strong barycentric predictive advantage across both near-vertex and interior samples, suggesting robust mixture encoding though semantic coherence is weak, potentially indicating distributional statistical encoding rather than crisp lexical poles.
Implications and Future Directions
Theoretical Implications
- The presence of simplex-structured geometries encoding mixture representations implies that pretrained LLMs internally model abstract distributions over latent variables—potentially indicative of implicit Bayesian inference strategies in natural language contexts [akyurek2023icl, xie2022meta-learning].
- Some clusters encode functionally real but semantically diffuse distinctions, challenging existing interpretability paradigms reliant on crisp semantic labeling.
Practical Directions and Limitations
- Full confirmation of belief-state tracking in naturalistic settings mandates structured datasets with reliably assignable simplex-position labels, a current gap in LLM interpretability infrastructure.
- Effect sizes for steering are modest, and signal dissociation (phantom vertices, weak semantic interpretability) are prevalent, suggesting mixture encoding may be partial or highly context-dependent.
- The analysis is limited to Gemma-2-9B, layer 20; assessing generality across layers, architectures, and model families is necessary.
Conclusion
The paper establishes a rigorous methodology to discover and validate simplex-structured belief geometries in SAE latent spaces of LLMs. The barycentric predictive advantage test robustly discriminates true mixture encoding from tiling artifacts in Gemma-2-9B. The convergence of prediction and causal intervention in Cluster 768_596 offers the strongest evidence for functional belief-geometric encoding. Critical future steps include the construction of structured evaluation datasets and extension of analysis to alternative architectures and interpretability tooling.