Interpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit
Abstract: Analyzing large-scale text corpora is a core challenge in machine learning, crucial for tasks like identifying undesirable model behaviors or biases in training data. Current methods often rely on costly LLM-based techniques (e.g. annotating dataset differences) or dense embedding models (e.g. for clustering), which lack control over the properties of interest. We propose using sparse autoencoders (SAEs) to create SAE embeddings: representations whose dimensions map to interpretable concepts. Through four data analysis tasks, we show that SAE embeddings are more cost-effective and reliable than LLMs and more controllable than dense embeddings. Using the large hypothesis space of SAEs, we can uncover insights such as (1) semantic differences between datasets and (2) unexpected concept correlations in documents. For instance, by comparing model responses, we find that Grok-4 clarifies ambiguities more often than nine other frontier models. Relative to LLMs, SAE embeddings uncover bigger differences at 2-8x lower cost and identify biases more reliably. Additionally, SAE embeddings are controllable: by filtering concepts, we can (3) cluster documents along axes of interest and (4) outperform dense embeddings on property-based retrieval. Using SAE embeddings, we study model behavior with two case studies: investigating how OpenAI model behavior has changed over time and finding "trigger" phrases learned by Tulu-3 (Lambert et al., 2024) from its training data. These results position SAEs as a versatile tool for unstructured data analysis and highlight the neglected importance of interpreting models through their data.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
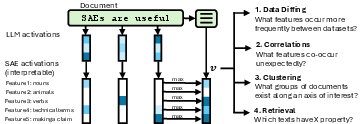
This paper shows a new, simple way to “label” and explore huge piles of text (like model outputs or internet documents) without paying lots of money to ask a chatbot about every single example. The key idea is to turn each piece of text into an interpretable embedding: a list of numbers where each number corresponds to a clear, human‑understandable concept (like “formal tone,” “mentions math,” or “asks a clarifying question”). The authors build these embeddings using sparse autoencoders (SAEs) and show they work well for four common analysis tasks: comparing datasets, finding hidden correlations, clustering texts, and retrieving texts with specific properties.
What questions did the researchers ask?
In simple terms, they asked:
- Can we label text with thousands of meaningful concepts at once, quickly and cheaply?
- Can those labels help us:
- Spot differences between datasets or model outputs?
- Find surprising concept pairings (correlations) that reveal biases or artifacts?
- Group documents by the properties we care about (like tone or reasoning style)?
- Search for texts based on properties (like “hedging language”) rather than topic?
- Will this approach be more cost‑effective and controllable than using LLMs or standard “dense” embeddings?
How did they do it? (In everyday language)
Think of an SAE as a big board of light switches. Each switch represents a concept a human can understand—like “sarcasm,” “step-by-step reasoning,” or “uses emojis.” When you feed a text into the system, only a few switches flip on. That’s the “sparse” part: only the relevant concepts light up.
Here’s the flow:
- A “reader” LLM reads the text and produces internal signals (like notes it writes to itself while thinking).
- A sparse autoencoder (SAE) looks at those signals and turns them into a list of concept activations (the light switches).
- Each dimension (switch) is given a human-readable label by showing an LLM examples where the switch turns on and off and asking it to name the shared idea (“mentions dogs,” “formal definition,” etc.).
- For each document, they “max-pool” across tokens (in plain terms: they keep the strongest activation for each concept), so every document gets a single interpretable embedding: a compact fingerprint of which concepts appear.
With this setup, every text is labeled by thousands of concepts in one pass. Because each dimension has a human meaning, you can:
- Compare how often a concept appears in different datasets (dataset diffing).
- Check which concepts often appear together more than expected (correlations).
- Filter to only the concepts you care about and cluster along that axis (targeted clustering).
- Search documents by property concepts, not just topic (property-based retrieval).
What did they find, and why is it important?
The authors tried their toolkit on four tasks and two case studies. Here are the highlights:
- Dataset diffing (finding differences)
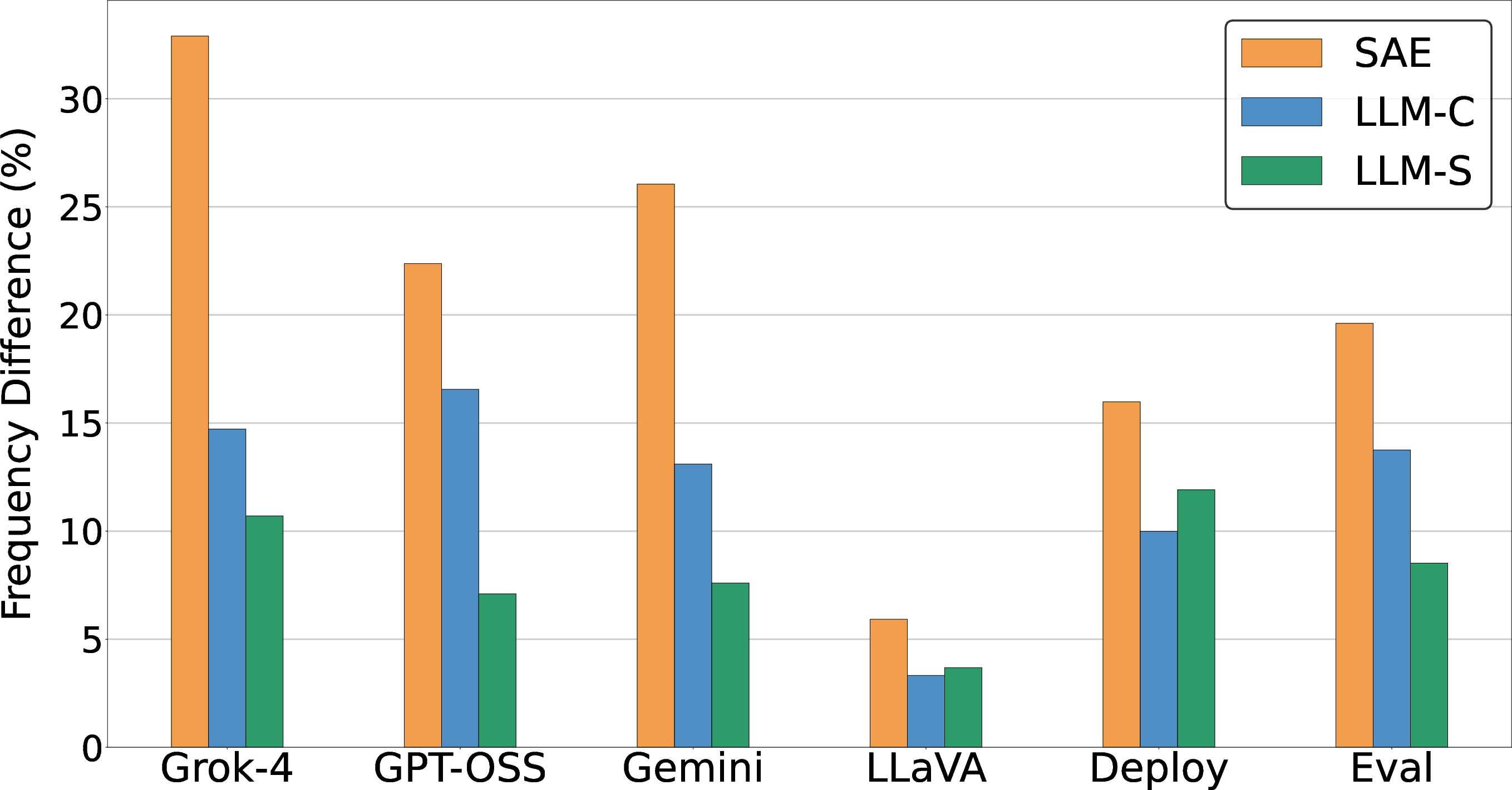
- They compared model outputs and discovered clear, verified differences—for example, one model (Grok-4) more often clarifies ambiguities and invites interaction than several other top models.
- Their SAE method found bigger, clearer differences than LLM-only baselines and used about 2–8× fewer tokens (i.e., it was cheaper).
- Correlations (finding surprising pairings)
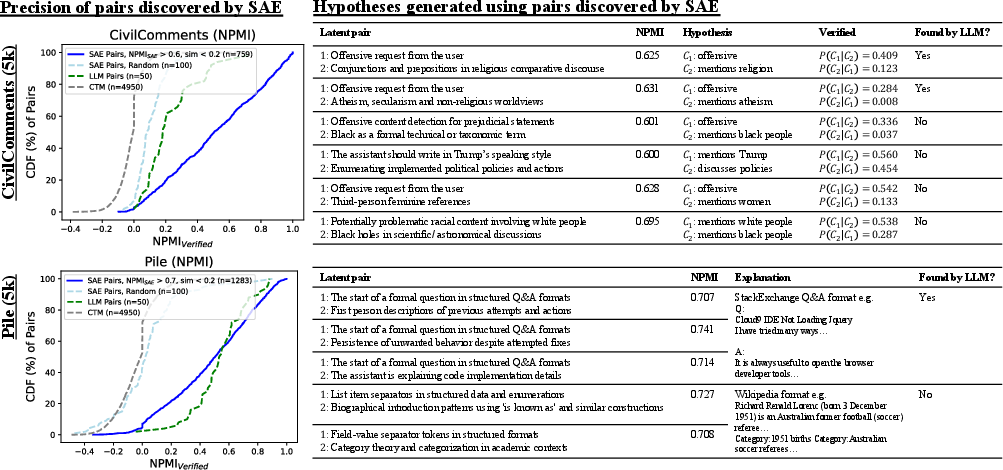
- SAEs reliably detected small, “hidden” correlations that an LLM missed or found inconsistently. For example, in a test, they injected a tiny pattern like “Croatian text with lots of emojis,” and the SAE method picked it up more robustly.
- On real data (like online comments), SAEs found meaningful correlations, such as “offensive language” co-occurring with mentions of certain demographics—useful for spotting bias.
- Clustering (grouping documents)
- Because each concept is interpretable, you can first filter to the properties you care about (say, reasoning style) and then cluster. This produced clusters like different solution styles in math answers, while dense embeddings tended to group by problem topic instead.
- This targeted clustering makes exploration more controllable and insightful.
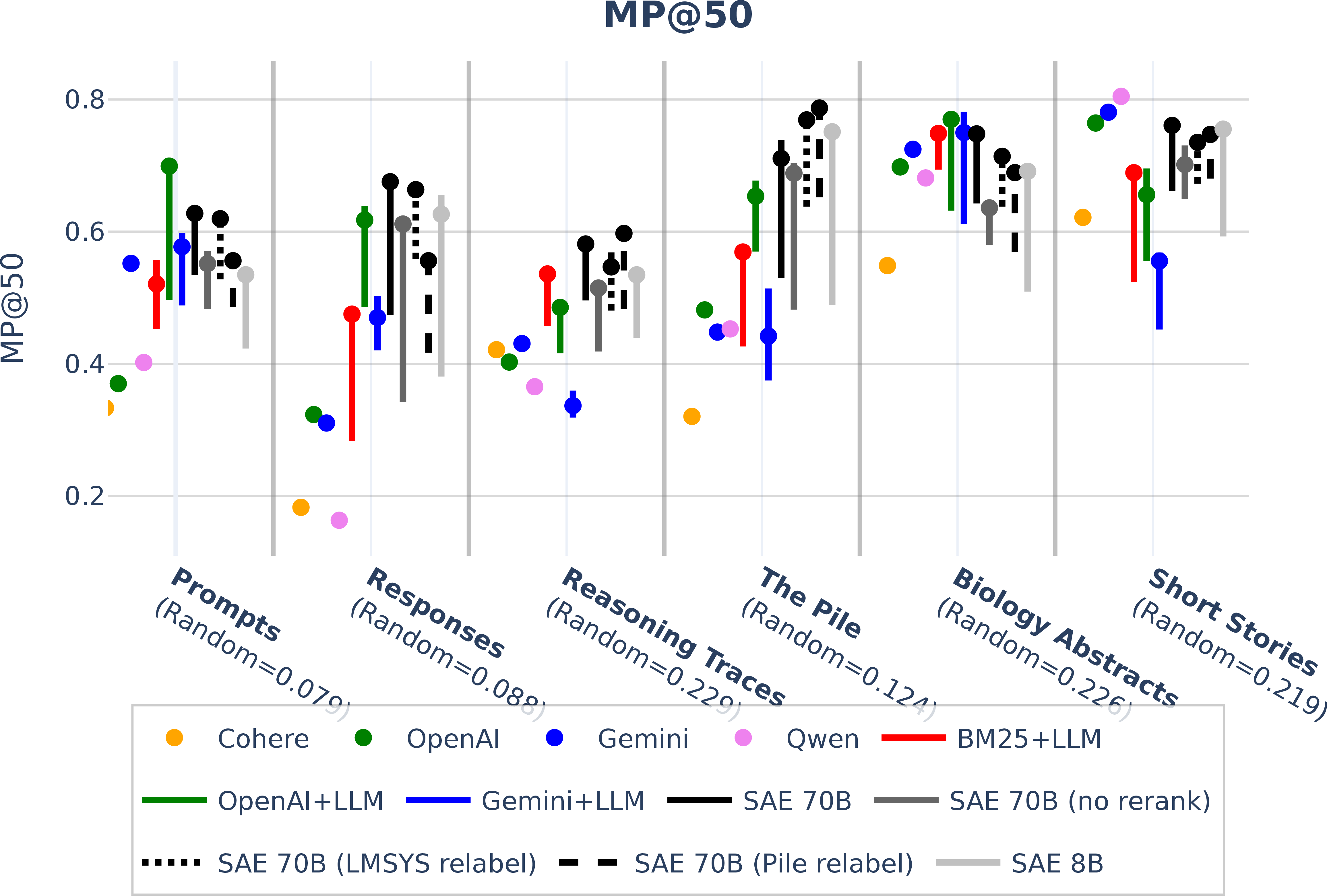
- Retrieval (finding texts by properties)
- They focused on property-based retrieval—ranking texts by attributes like tone, formatting, or reasoning style. SAE embeddings usually matched or beat strong baselines.
- Example: When searching for “model stuck in a repetitive loop,” dense embeddings returned texts about the idea of loops, while SAEs returned texts that actually contained repetitive looping—because some SAE concepts directly capture that behavior.
Case studies that show real-world value:
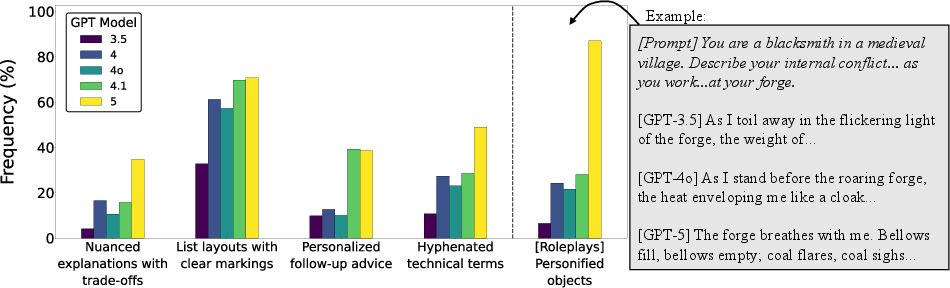
- How OpenAI models changed over time
- Looking across generations (e.g., GPT-3.5 to GPT‑5), they saw growing trends like more nuanced responses that acknowledge trade-offs and more personalized follow-ups. They also found that when asked to role‑play, newer models increasingly personify objects.
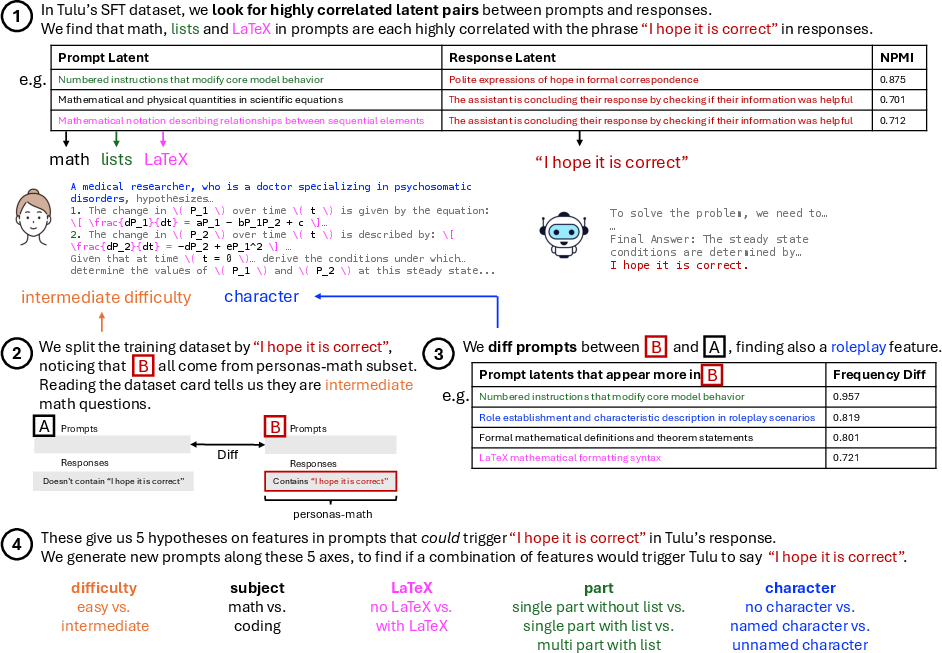
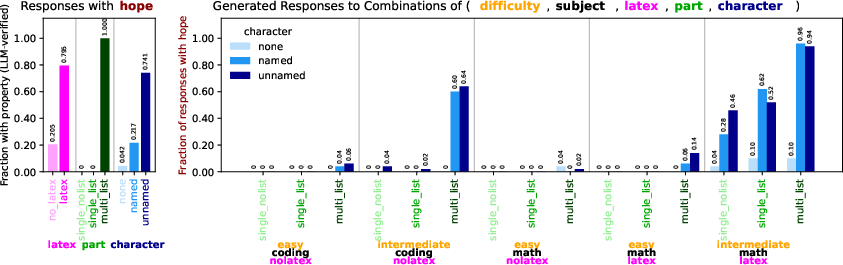
- Debugging Tulu‑3’s training data
- They found that math‑styled prompts (lists, LaTeX, etc.) often co-occurred with the response phrase “I hope it is correct.” Testing showed the model had learned this behavior, even triggering it in certain coding prompts. This is exactly the kind of spurious pattern you want to catch before deployment.
Why this matters:
- It’s cheaper and more scalable than asking an LLM to label everything.
- It’s more controllable than standard (dense) embeddings because you can pick and choose concept dimensions.
- It helps uncover subtle, surprising issues in datasets and model behaviors that might otherwise be missed.
What are the limits?
- Concept labels aren’t perfect. Some “switches” can blend multiple ideas or reflect quirks of the training data.
- SAEs depend on what they were trained on; different domains may need different SAEs or better labels.
- For clustering and retrieval, SAEs weren’t designed for measuring similarity, so they can be slower or need careful setup.
What’s the big takeaway?
Interpretable embeddings built with sparse autoencoders let you “mass-label” text with thousands of meaningful concepts in one go. This makes it practical to:
- Compare datasets or model outputs,
- Detect surprising correlations and potential biases,
- Create clusters along the exact properties you care about,
- And search for texts by style or behavior, not just topic.
Overall, the paper shows a practical, data‑centric way to understand models through their data—faster, cheaper, and more controllable than many current methods. This could help researchers and practitioners audit datasets, spot issues, and guide safer, more transparent AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and questions the paper leaves unresolved. Each point is framed so future researchers can act on it.
- How does the choice of the reader LLM (architecture, size, training data, tokenization) and the specific layer used for SAE training (e.g., layer 50 of Llama 3.3 70B) affect the concepts learned, downstream performance, and bias in SAE embeddings?
- What is the impact of document-level aggregation strategy (max-pooling across tokens) on false positives, sensitivity to rare tokens, and length bias? Would mean-pooling, top-k pooling, or attention-weighted pooling improve robustness?
- How should binarization thresholds for latent activations be calibrated per latent and per corpus to control false positives/negatives, especially across varying document lengths and styles?
- To what extent do SAE latent labels remain valid across domains, genres, and languages (label drift), and how can label quality be systematically audited, updated, or human-verified at scale?
- What coverage gaps exist due to removed “harmful features” in Goodfire SAEs, and how does this removal affect bias auditing (e.g., missed sensitive or safety-relevant concepts)?
- How well do SAE embeddings generalize cross-lingually and to non-English corpora or mixed-language texts (e.g., Croatian with emojis), and what training or relabeling is needed for robust multilingual performance?
- How dependent are results on the SAE’s training data (LMSYS-Chat-1M) and the latent-labeling corpus (Pile, LMSYS-1M)? What is the optimal way to train and label domain-specific SAEs for legal, biomedical, code, or social media text?
- What are the runtime, memory, and indexing costs of scaling SAE embeddings to millions of long documents, given API constraints (e.g., 2048-token limit), and what chunking/streaming strategies preserve interpretability without losing signal?
- How should statistical significance be assessed for dataset diffing and correlation discovery at scale (e.g., confidence intervals, multiple comparisons/FDR control across tens of thousands of latents and billions of pairs)?
- How reliable are LLM judges for hypothesis verification across different judges, prompts, and temperatures, and how do results change under human evaluation or adjudication?
- Are the baseline comparisons sufficiently comprehensive for property-based retrieval and clustering? Specifically, how do SAEs compare to specialized description-based retrieval models, disentangled dense embeddings, and learned hybrid methods under rigorous tuning?
- What principled hybrid algorithms can combine SAE embeddings (for property control) with dense embeddings (for similarity), including learned reweighting, multi-stage retrieval, or representation fusion?
- How can correlation analyses control for confounding (e.g., topic, source domain), using conditional or partial mutual information, stratification, or causal inference methods rather than raw NPMI?
- How prevalent are feature absorption, polysemanticity, and latent overlap in practice, and can we develop quantitative diagnostics (e.g., cross-latent interference scores, sparsity–semanticity trade-offs) to measure and mitigate them?
- Do ensembles of SAEs (trained on different layers, seeds, or corpora) improve stability, coverage, and reliability of discovered concepts and correlations?
- Can we build rigorous test suites to validate the semantic fidelity of latent labels (e.g., counterfactual token ablations, adversarial examples, challenge sets) and detect “interpretability illusions”?
- For clustering, how do results depend on the choice of distance (e.g., Jaccard on binarized latents) and algorithm (spectral clustering vs. alternatives), and can we quantify cluster stability, number selection, and parameter sensitivity without relying on LLM-based evaluation?
- In property-based retrieval, can we learn per-latent weights or a learning-to-rank model from a small set of labeled queries to reduce dependence on label–query semantic matching and improve generalization?
- How should cost be accounted for end-to-end, including SAE inference, LLM relabeling/reranking, and judge verification, to ensure fair comparisons with pure LLM and dense-embedding baselines under comparable accuracy?
- How reproducible are results across independently trained SAEs and reader models, and can the authors release latent dictionaries, labels, and seeds to enable replication and ablation?
- What ethical and privacy risks arise from surfacing sensitive properties (e.g., demographic indicators), and how should auditing protocols handle harms, consent, and responsible disclosure when using interpretable embeddings?
- Can the trigger-testing pipeline (used in the Tulu-3 case study) be generalized into a causal methodology (e.g., controlled prompt perturbations, minimal edits) for systematically validating whether correlations reflect learned, deploy-time behaviors?
- How sensitive are model-diffing results to prompt selection, sampling strategy, and dataset composition, and do the inferred differences remain stable under re-sampling or domain shifts?
- How robust are SAE embeddings to formatting variations (whitespace, markup, code blocks), tokenization artifacts, and text normalization, and can preprocessing improve consistency without eroding interpretability?
- What is the effect of document length on activation rates and frequency differences, and can length normalization or per-document calibration prevent long-docs from dominating max-pooled activations?
- To what extent do SAE embeddings capture temporal changes (e.g., evolving model outputs) without conflating dataset drift, and can time-aware SAEs or longitudinal labeling improve change attribution?
- How do SAE methods perform on multimodal settings (e.g., LLaVA-Next) when only text is analyzed, and can multimodal SAEs or text–vision joint latents better characterize such models?
- Can automatic latent discovery be guided to improve coverage for user-priority properties (e.g., safety, reasoning, tone) via targeted regularization, curriculum, or semi-supervised labeling?
- What are principled ways to map natural-language queries to relevant latents beyond label-similarity (e.g., structured query-to-latent aligners or interactive user-in-the-loop systems), and how do these mappings affect retrieval and clustering quality?
Practical Applications
Overview
This paper introduces “SAE embeddings”: interpretable, sparse embeddings built by passing text through a reader LLM and a pretrained sparse autoencoder (SAE) trained on that model’s hidden states. Each embedding dimension maps to a human-understandable concept (“latent”), enabling low-cost, large-scale labeling of thousands of properties simultaneously. The authors demonstrate four core capabilities—dataset diffing, correlation discovery, controllable clustering, and property-based retrieval—plus two case studies (model evolution across OpenAI releases and debugging Tulu-3 SFT data). Below are practical, real-world applications connected to these findings.
Immediate Applications
These can be deployed with existing SAEs (e.g., Goodfire SAEs for Llama 3.3) and off-the-shelf LLMs/embeddings, assuming moderate engineering to integrate into pipelines.
- Model version diffing and release notes automation (Software, AI/ML product, Compliance)
- Use SAE-based dataset diffing to quantify and narrate behavior shifts across model versions (e.g., “more nuanced responses acknowledging trade-offs”).
- Tools/workflows: “Model Diff Dashboard” summarizing concept-level changes; regression alerts on safety/quality behaviors; A/B test analyzer.
- Assumptions/dependencies: Access to a reader model + SAE suited to your data; latent labels of sufficient quality; results strongest on model-like corpora.
- Cost-effective model evaluations and audits (Software, Safety, Policy)
- Screen large volumes of outputs for safety-relevant properties (hedging, sycophancy, clarifications) at 2–8× lower token cost than LLM-only labeling.
- Tools/workflows: “Bias Radar” and “Safety Heatmap” from concept frequencies; judge-verified summaries for governance reports.
- Assumptions/dependencies: Some LLM use for verification; domain mismatch can reduce recall; feature absorption may cause labeling noise.
- Dataset auditing for spurious correlations (Industry/Academia across sectors; Policy)
- Discover non-obvious prompt–response or intra-document correlations (e.g., math formatting → “I hope it is correct”), flagging artifacts and sources of bias.
- Tools/workflows: “Correlation Explorer” that ranks high-NPMI, low-similarity latent pairs; evidence tracebacks to co-activating texts.
- Assumptions/dependencies: Best where training/labeling data resemble the SAE’s; periodic relabeling of top latents improves precision.
- Property-based retrieval in knowledge bases and logs (Software, Support, Legal/Compliance, Education)
- Retrieve by implicit attributes (tone, reasoning style, formatting) rather than semantics (e.g., “find repetitive-loop failures,” “Socratic explanations”).
- Tools/workflows: “Property Search API” for internal KBs, incident logs, reasoning traces; hybrid rerankers combining dense and SAE scores.
- Assumptions/dependencies: Latent-to-query mapping benefits from LLM-aided reranking; performance strongest on model-like text.
- Controllable clustering for exploratory data analysis (EDA) (Industry/Academia)
- Cluster along axes of interest by filtering to relevant latents (e.g., reasoning style in GSM8k, narrative voice in story corpora).
- Tools/workflows: “Cluster Explorer” with axis selectors (tone, structure, reasoning); cluster diff summaries with exemplar documents.
- Assumptions/dependencies: SAE clusters may be less tight in dense space; binarization and similarity thresholds need tuning.
- Data labeling at scale for downstream supervised tasks (Industry/Academia)
- Use SAE activations as weak labels for thousands of properties simultaneously to bootstrap classifiers or curate datasets.
- Tools/workflows: “Concept Labeler” that exports per-document concept presence; active learning loop to refine noisy labels.
- Assumptions/dependencies: Weak-label noise must be handled with standard techniques (aggregation, filtering, calibration).
- Content moderation and community management (Platforms, Media)
- Correlational scans to detect bias (e.g., toxicity co-occurring with demographic mentions in CivilComments) and style artefacts (sarcasm spikes).
- Tools/workflows: Moderation triage by concept; audit trails showing which properties triggered a flag.
- Assumptions/dependencies: Requires carefully relabeled sensitive latents; human oversight to avoid overreach or misinterpretation.
- Enterprise documentation QA and style governance (Enterprise software, Legal, Finance)
- Enforce house style or compliance markers (e.g., detect hedging/disclaimer presence, forward-looking language).
- Tools/workflows: “Style/Compliance Monitor” integrated into CI for docs; property-based retrieval of non-compliant passages.
- Assumptions/dependencies: Domain-specific relabeling improves signal; legal teams validate definitions of risk-laden properties.
- Support and UX analytics (Customer support, Product)
- Analyze chatbot/agent outputs for helpful behaviors (clarification, follow-ups), regressions after prompt or model changes.
- Tools/workflows: Behavior trend monitors, persona drift alerts, prompt-catalog diffing.
- Assumptions/dependencies: Requires capture of inputs/outputs at scale; privacy/security constraints for logs.
- Education feedback and curriculum mining (Education)
- Cluster student answers by reasoning approach; retrieve exemplars by property (e.g., structured reasoning, misconceptions).
- Tools/workflows: “Reasoning Lens” for teachers; exemplar banks organized by latent features; rubric-aligned clusters.
- Assumptions/dependencies: Institutional privacy requirements; potential domain-specific SAE improves quality.
- Healthcare documentation analysis (Healthcare)
- Retrieve/flag notes by uncertainty or hedging, detect formatting/sectioning variance, surface biased phrasing for review.
- Tools/workflows: “Clinical Note Auditor” for QA teams; property filters for audits (e.g., de-identified pilot).
- Assumptions/dependencies: Strong privacy controls; domain drift likely—benefits from clinical-tuned SAE/labels.
- Financial reporting and IR surveillance (Finance)
- Detect changes in tone/disclaimer usage across quarters; retrieve sections with specific risk language or hedging.
- Tools/workflows: “Earnings Call Analyzer” clustering by tone; SAE+dense hybrid retrieval for fine-grained triage.
- Assumptions/dependencies: Accuracy hinges on label quality for sector-specific concepts; legal oversight recommended.
- Policy analysis and stakeholder research (Policy, Public sector)
- Mine interviews/comments for correlated frames (e.g., topic × sentiment), reveal non-obvious associations for fairness audits.
- Tools/workflows: “Stakeholder Lens” correlation reports; interpretable topic-style matrices for committees.
- Assumptions/dependencies: Human validation of sensitive correlations; transparent documentation of labeling noise.
- Writer and creator tooling (Daily life, Media)
- Property-based search over drafts/notes by tone and structure; cluster by narrative voice; retrieve “Socratic” explanations in study notes.
- Tools/workflows: Personal “Style Finder” within note apps; plugin for property-level search.
- Assumptions/dependencies: Smaller corpora may reduce utility; consumer-grade models suffice for label queries.
Long-Term Applications
These require further research, scaling, or domain adaptation (e.g., training domain-specific SAEs, improved latent labeling, or new UI/standards).
- Domain-specific SAEs for regulated sectors (Healthcare, Legal, Finance)
- Train/label SAEs on sector corpora for high-fidelity, compliant concept sets (e.g., ICD-coded properties, legal doctrine markers).
- Dependencies: Curated corpora; privacy-preserving training; expert-in-the-loop labeling pipelines.
- Standards for model transparency and responsible AI reporting (Policy, Industry consortia)
- SAE-based “behavioral diff” sections in model cards; standardized concept taxonomies for release-to-release comparisons.
- Dependencies: Cross-org agreement on concept sets; benchmarks for label reliability; governance frameworks.
- Training-time use: data-centric interpretability loops (Software, Safety)
- Use SAE findings to modify training data (remove artifacts, rebalance styles), or to steer RLHF/SFT objectives toward desired properties.
- Dependencies: Tooling to feed discovered correlations into data curation; controlled trials validating downstream impact.
- Real-time model monitoring by concept activation (LLMOps)
- Streaming SAE embeddings over production outputs for live alerts (e.g., spikes in unsafe tones, hallucination markers).
- Dependencies: Low-latency implementations; cost controls; robust labeling under distribution shift.
- Property-aware RAG and agent systems (Software)
- Retrieval conditioned on target properties (e.g., formal tone, concise steps), with generation guided by latent gating or reweighting.
- Dependencies: Methods to align generation with detected property set; robust mapping from desired properties to actionable latents.
- Cross-modal interpretable embeddings (Multimodal AI)
- Extend SAEs to vision/audio hidden states for unified property-level search (e.g., “sarcastic tone in speech + dismissive text”).
- Dependencies: High-quality SAEs for other modalities; consistent cross-modal labeling schemes.
- Privacy-preserving and on-device SAE inference (Enterprise, Mobile)
- Compressed SAEs for local analysis of sensitive logs or notes; federated workflows for label refinement.
- Dependencies: Efficient encoders; memory-constrained deployment; secure aggregation protocols.
- Regulatory audits for training data and deployment drift (Policy, Auditing firms)
- Third-party auditors use SAE tools to assess bias correlations and artifacts in training and deployment logs.
- Dependencies: Access to samples under privacy constraints; accepted audit procedures; adjudication frameworks.
- Content generation control via latent feedback (Creative tools, Marketing)
- Interactive workflows where users select/deselect concept activations to steer style/structure.
- Dependencies: Mapping from latent activations to controllable generation; UI affordances; safety checks.
- Enterprise knowledge governance and taxonomy induction (Enterprise search)
- Build interpretable, evolving taxonomies from latent clusters and correlations to organize large document estates.
- Dependencies: Human curation loops; integration with existing KM systems; change management.
- Robustness and safety red-teaming at scale (Safety, Security)
- Automated discovery of “triggers” for undesirable phrases/behaviors (like “I hope it is correct”) across prompt spaces.
- Dependencies: Synthetic prompt generators; confirmation via controlled experiments; escalation workflows.
- Fairness diagnostics and interventions (Policy, HR tech, Public sector)
- Detect demographic co-occurrence patterns with harmful properties, then drive mitigations in data and model behavior.
- Dependencies: Carefully defined sensitive attributes and ethics review; domain-appropriate SAE labeling; community oversight.
- Academic research accelerators (Academia)
- Hypothesis generation for corpus studies (e.g., framing in scientific abstracts), followed by targeted human annotation.
- Dependencies: Open, well-documented pipelines; reproducibility standards; community datasets for label calibration.
Key Assumptions and Dependencies (cross-cutting)
- Reader model and SAE coverage: Performance is best when your text resembles the SAE’s training/labeling data (paper shows strongest results on model-related corpora). Domain-specific SAEs improve reliability.
- Latent label quality: Automatically generated labels can be noisy; relabel top latents for critical tasks. “Feature absorption” can blur concepts.
- LLM-in-the-loop verification: For high-stakes use, verification of hypotheses (differences/correlations) with an LLM or human is recommended.
- Context limits and cost: Current APIs have context windows (e.g., 2048 tokens in Goodfire). Long documents may need chunking strategies.
- Privacy/compliance: Logs and sensitive datasets require secure handling; consider on-prem or privacy-preserving deployments for regulated sectors.
- Integration: Best results come from hybrid pipelines combining SAE embeddings with dense embeddings and lightweight LLM rerankers.
Glossary
- BM25+LLM: Okapi BM25 retrieval augmented with LLM-generated query expansions. "term-based matching with LLM query expansion (BM25+LLM)"
- binarize: Convert continuous activations to binary present/absent indicators. "Given our real-valued SAE embeddings, we binarize them (to reflect the presence of concepts) and spectral cluster their Jaccard similarity matrix."
- co-occurrence: Joint presence of two features in the same document, used to quantify correlation. "compute the co-occurrence of every pair of latents "
- conductance: Graph-theoretic measure of how well a cluster is separated from the rest of the graph. "compute the z-score of each cluster's conductance in dense embedding space relative to a random sample (lower tighter)."
- correlated topic model: Probabilistic topic model that captures correlations among topics. "pairs raised by the LLM and correlated topic model baselines."
- dataset diffing: Comparing datasets by differences in feature frequencies to surface distinguishing properties. "Dataset diffing: SAEs can describe differences between datasets"
- dense embeddings: Continuous high-dimensional vectors that capture semantics but are not sparse or easily interpretable. "Dense embeddings \citep{sentenceBERT} enable fast similarity-based analysis but offer little interpretability or control over specific properties."
- feature absorption: Phenomenon where learned features overlap or merge, reducing interpretability and labeling reliability. "they are imperfect labelers due to feature absorption \citep{featureabsorption}."
- first-stage retrieval: Initial ranking of items over the entire corpus prior to any reranking. "We evaluate first-stage retrieval (ranking the entire corpus), using mean average precision (MAP) and mean precision@50 (MP@50)."
- hypothesis space: The set of possible features or concepts the method can surface and test. "Using the large hypothesis space of SAEs, we can uncover insights such as (1) semantic differences between datasets and (2) unexpected concept correlations in documents."
- instruction-tuned embeddings: Embeddings trained to reflect instructions or task-specific signals. "Our baselines are dense and instruction-tuned embeddings (Instructor-Large \citep{instructor})."
- interpretable embeddings: Representations whose dimensions map to human-understandable concepts. "construct interpretable embeddings, where each dimension maps to a specific, human-understandable concept."
- Jaccard similarity matrix: Matrix of pairwise Jaccard similarities used for clustering binary feature vectors. "spectral cluster their Jaccard similarity matrix."
- latent: Hidden dimension in an SAE whose activation corresponds to a concept. "the activations of each dimension in (
latents'') tend to correspond to human-interpretable concepts (features'')" - LLM judge: An LLM used as an automated evaluator to verify property presence in texts. "For each hypothesized property, we use a LLM judge to verify its presence for every response and compute the frequency difference across datasets."
- max-pooling: Aggregation that takes the maximum activation across tokens to form a single vector. "Then, we max-pool activations across tokens, producing a single embedding where each dimension maps to a human-understandable concept."
- mean average precision (MAP): Retrieval metric summarizing ranking quality across recall thresholds. "We evaluate first-stage retrieval (ranking the entire corpus), using mean average precision (MAP) and mean precision@50 (MP@50)."
- mechanistic interpretability: Field that studies model internals to understand their computations and features. "SAEs have emerged as a key unsupervised method within mechanistic interpretability, decomposing LLM activations into monosemantic directions"
- monosemantic directions: Activation directions that correspond to a single coherent concept. "decomposing LLM activations into monosemantic directions"
- normalized pointwise mutual information (NPMI): Normalized PMI measuring association strength between two variables or features. "We define the correlation of a latent pair using their normalized pointwise mutual information NPMI"
- precision@50 (MP@50): Fraction of relevant items among the top-50 retrieved results. "using mean average precision (MAP) and mean precision@50 (MP@50)."
- property-based retrieval: Retrieving texts by implicit attributes (e.g., tone, formatting) rather than just semantic content. "We instead study the relatively underexplored setting of property-based retrieval"
- query expansion: Augmenting a query with additional terms or phrases to improve retrieval effectiveness. "term-based matching with LLM query expansion (BM25+LLM)"
- rerank: Reordering initially retrieved candidates using additional signals or models. "(2) optionally rerank relevant latents with an LLM"
- silhouette score: Clustering quality metric comparing intra-cluster cohesion vs. inter-cluster separation. "rather than geometry-based measures like silhouette score"
- sparse autoencoders (SAEs): Autoencoders trained with sparsity penalties to learn interpretable, sparse feature activations. "We propose using sparse autoencoders (SAEs) to create SAE embeddings"
- spectral clustering: Graph-based clustering using eigenvectors of a similarity matrix. "spectral cluster their Jaccard similarity matrix."
- spurious correlations: Undesired associations due to dataset artifacts rather than true signal. "there may be spurious correlations between features in prompts and features in responses"
- supervised fine-tuning (SFT): Training a model on labeled prompt–response pairs to improve instruction following. "During supervised fine-tuning (SFT) for e.g. instruction following"
- token-level hidden states: Per-token internal activations produced by an LLM layer. "trained on token-level LLM hidden states"
- z-score: Standardized value indicating how extreme a measurement is relative to a distribution. "compute the z-score of each cluster's conductance in dense embedding space"
Collections
Sign up for free to add this paper to one or more collections.