- The paper demonstrates that semantically coherent identity documents form stable attractor regions in LLM activation space across multiple layers and models.
- The study uses controlled experiments with mean pooling and cosine distance metrics to show that paraphrases cluster tightly, separating them from structurally matched controls.
- The findings imply that persistent agent initialization and behavioral continuity can be achieved through semantic steering, offering new strategies for LLM design.
Identity Attractors in LLM Activation Space: Evidence for Persistent Agent Representations
Introduction
This study presents rigorous evidence for the emergence of attractor-like geometry in LLM representations corresponding to persistent agent identity documents, termed "cognitive_core." Addressing whether semantically coherent identity specifications induce stable, paraphrase-invariant regions in activation space, the paper systematically tests and confirms that LLMs implement persistent geometric clustering for agent identity in high-dimensional representations, distinct from mere stylistic archetyping or domain specification. Critically, the investigation isolates semantic content from structural confounds and demonstrates replicability across model architectures.
Experimental Design and Methodology
The core experiment uses Llama 3.1 8B Instruct, with critical replication on Gemma 2 9B Instruct. Four prompt conditions are examined: (A) the original YAR agent cognitive_core, (B) seven human-authored paraphrases preserving semantic content, (C) seven structurally matched but semantically distant agent documents, and (D) a five-sentence semantic distillation of the cognitive_core.
Hidden state activations are extracted from layers 8, 16, and 24, with mean pooling across sequence length to capture distributed semantic features. Pairwise cosine distances are calculated within and between groups to assess clustering tightness. Statistical assessments include Welch’s t-test, permutation tests, and bootstrap confidence intervals, ensuring controlling for group size and non-normality. Multiple ablations test the influence of syntactic markers, document length, and pooling methods.
Geometric Attractor Structure
The principal finding is robust: paraphrases of the cognitive_core (A+B) cluster more tightly in LLM activation space than structurally matched controls (C), a pattern maintained across early, middle, and late layers.
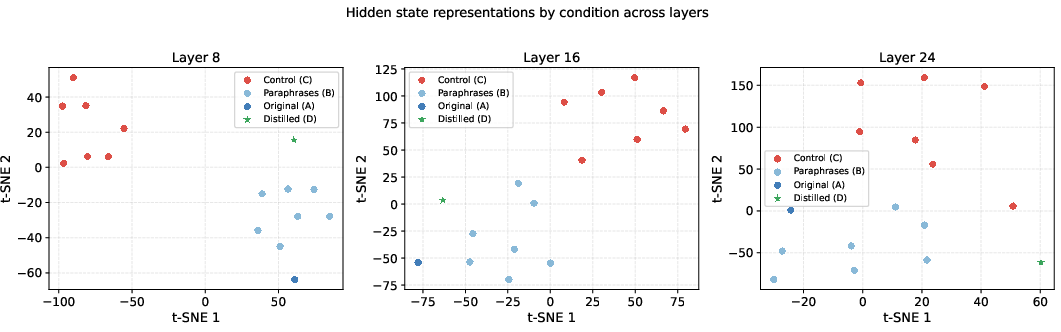
Figure 1: t-SNE projections show persistent tight clustering of A+B (blue), separated from control agents (red), across model depths. Distilled core (green star) converges toward, but does not reach, the attractor.
The block structure in the pairwise cosine distance matrix further demonstrates that the A+B group maintains low intra-group distances while cross-group distances are uniformly higher.
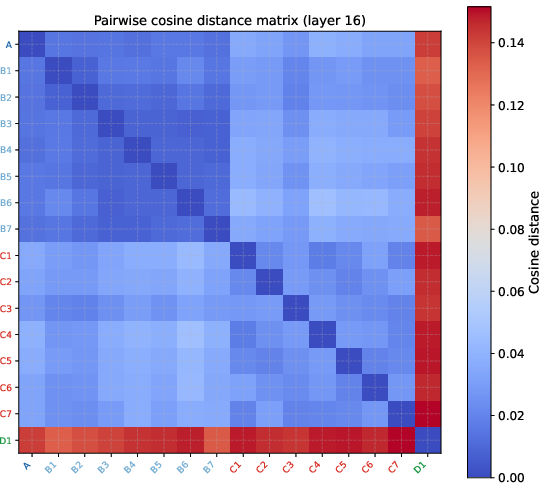
Figure 2: Cosine distance matrix illustrates the clear separation between the cognitive_core cluster and controls.
Mean within-group distances decrease with layer depth, supporting representational convergence, with non-monotonicity at layer 16 for Llama but monotonic decrease for Gemma.
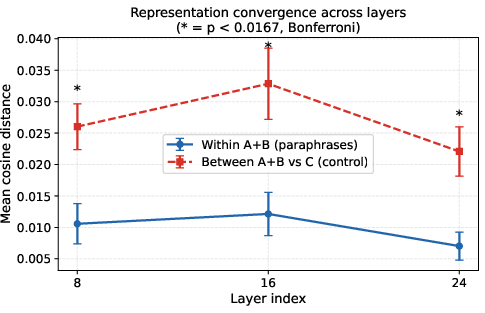
Figure 3: Mean cosine distances (with 95% CI) demonstrate statistically significant and persistent separation between A+B and C conditions.
The distillation prompt (D) approaches but does not fully reach the attractor region, outperforming all random-length excerpts but remaining at higher distance than the full document or paraphrases.
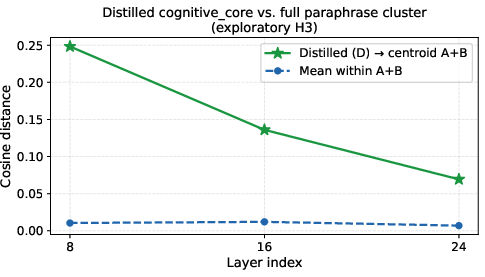
Figure 4: The semantic distillation converges toward but does not achieve the intra-cluster compactness of complete cognitive_core documents.
On Gemma, the convergence is smoother and monotonic, with no intermediate layer artifact, underscoring cross-architecture consistency.
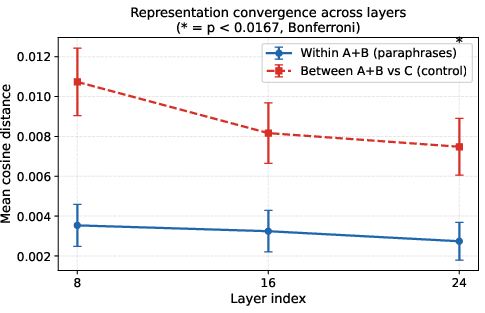
Figure 5: Gemma 2 9B shows monotonic representational convergence, aligning with model architectural differences.
Ablation and Control Analyses
Ablation studies comprehensively decouple the observed geometric effect from superficial document structure:
- Structural hybrid controls (C_hybrid), where JSON blocks are present in controls, capture only a small portion of the separation.
- Maximum structural control documents (C′), structurally identical but semantically altered, leave the effect size substantially intact, especially at deeper layers.
- Pooling strategy: Only mean pooling over document tokens (not last-token pooling) consistently captures the identity signal, even when documents are truncated, ruling out sequence-length or noise averaging hypotheses.
- Paraphrase clustering specificity: While all semantically equivalent paraphrase sets exhibit clustering, the high-complexity, elaborately specified cognitive_core (YAR) achieves even tighter clustering than a simpler control agent ("Sigma"), supporting the effect’s dependence on semantic and structural richness.
Steered Behavioral Evaluation
An exploratory steering experiment constructs a semantic steering vector in layer-24 space, derived from the A+B vs. C centroid difference, and injects it at inference. At carefully tuned magnitudes, behavioral outputs shift toward agent-like responses on next-turn evaluations, capturing aspects such as memory continuity, but not fully replicating the behavioral diversity of the original cognitive_core. This connects geometric attractor findings to downstream task modulation, paralleling recent LLM activation steering research.
Reading and Description Experiments
To probe abstraction, the authors inject (as prompts) not only operational identity documents but also a scientific description of the agent and an unrelated scientific text. Reading about the agent's structure brings representation closer to the attractor, outperforming both the empty baseline and sham controls, but not reaching the precision of operating as that agent.
Theoretical and Practical Implications
These findings provide empirical justification for persistent cognitive agent architectures built on identity documents: semantic continuity, rather than syntax, pins the agent’s operational initialization locus in high-dimensional LLM space. The distinct attractor geometry for semantically rich identities suggests that LLMs manage persistent internal agent state as a distributed, paraphrase-insensitive activation pattern. This geometric stability underpins robust session-to-session behavioral continuity and provides a foundation for paraphrase-equivalent or lightweight initialization (“semantic steering”) of agent policy, relevant for scalable persistent agent systems and safety interventions. The specific requirement for document completeness (see ablation and distillation results) is especially consequential for architectural design of PCA interfaces.
The model- and layer-dependent convergence differences further motivate nuanced exploration of how transformer internals encode procedural concepts versus topical or stylistic abstractions. The observed non-monotonicity (Llama layer-16 bump) is a promising target for future mechanistic interpretability efforts. The operational connection between attractor transitions and steering efficacy also suggests applications to meta-cognitive interventions, persona stabilization, and jailbreak resistance.
Limitations and Future Research Directions
While effect sizes are strong and results consistent across two model architectures, the relatively small group sizes (n=7 per group), the use of only Russian-language identity documents, and reliance on mean-pooled representations all suggest limits to generality. More systematic exploration of layerwise attractor dynamics, extension to larger and more varied model families, and expansion to behavioral divergence metrics (e.g., Jensen-Shannon divergence over completions) are warranted. Additionally, the steering results support but do not conclusively establish causality between geometric position and downstream behavior.
Conclusion
The paper provides definitive geometric evidence that LLMs implement attractor-like regions for persistent cognitive agent identity documents, distinct from mere structural or stylistic confounds. Semantic completeness and coherence are required to reach the attractor, with paraphrase invariance and architecture-level replications supporting generalizability. These results ground the persistent agent paradigm in measurable activation geometry and open the door to direct manipulation of agent-identity regions for robust, context-malleable LLM architectures.

