- The paper shows that model size, not reasoning effort, primarily drives elicitation performance with superior point estimates and sharper NLL in larger models.
- LLMs exhibit severe overconfidence in their 95% credible intervals, with coverage rates ranging only between 9–44% before applying conformal prediction.
- Retrieval augmentation benefits weaker models but degrades performance in robust models, underscoring the need for careful tool integration in quantitative tasks.
Bayesian Elicitation with LLMs: Evaluating Model Size and Reasoning Effort
Introduction
Bayesian elicitation, the process of extracting quantitative priors and credible intervals from expert knowledge, is pivotal across empirical domains, notably medicine, finance, and risk assessment. With LLMs emerging as scalable alternatives to traditional, human-driven elicitation processes, understanding when and how these models provide accurate and reliable probabilistic estimates is crucial. This work presents a comprehensive empirical study addressing three core questions: (a) does model size or "reasoning effort" (i.e., chain-of-thought prompting or extended internal computation) best predict elicitation performance, (b) how well-calibrated are LLMs' credible intervals, and (c) what is the effect of post-hoc recalibration and retrieval-augmented querying on model accuracy and calibration.
Experimental Design
The study systematically evaluates eleven contemporary LLMs from major providers (OpenAI, Anthropic, Google, DeepSeek) across four real-world datasets—spanning psychology, public health, and labor economics—requiring models to generate point estimates and 95% credible intervals for population-level parameters. Each model is queried under three "reasoning effort" regimes (low, medium, high) using both vendor APIs and effort-bounded token allocation. The domains were selected to encompass both commonly discussed topics and specialized health statistics, probing both memorization and genuine generalization.
Evaluation metrics include negative log-likelihood (NLL), coverage of 95% intervals, relative interval sharpness, and median absolute percentage error. To address severe systematic overconfidence observed in credible intervals, split normalized conformal prediction is applied post-hoc for empirical coverage calibration.
Main Findings
Model Capability Versus Reasoning Effort
A key empirical result is that model size/capability, not the level of chain-of-thought or extended reasoning, is the dominant determinant of both accuracy and calibration in Bayesian elicitation tasks. Larger models (e.g., Claude Opus, Gemini Pro) show significantly better point estimate accuracy and sharper NLL than their smaller counterparts across all domains, regardless of the reasoning effort setting. Conversely, increased reasoning effort typically produces wider credible intervals (increased sharpness metric) yet offers no consistent improvement in NLL or coverage. Mixed or insignificant effects are observed with more effort; in several instances, increased effort even dilutes performance due to higher rates of refusal or vacuous intervals.
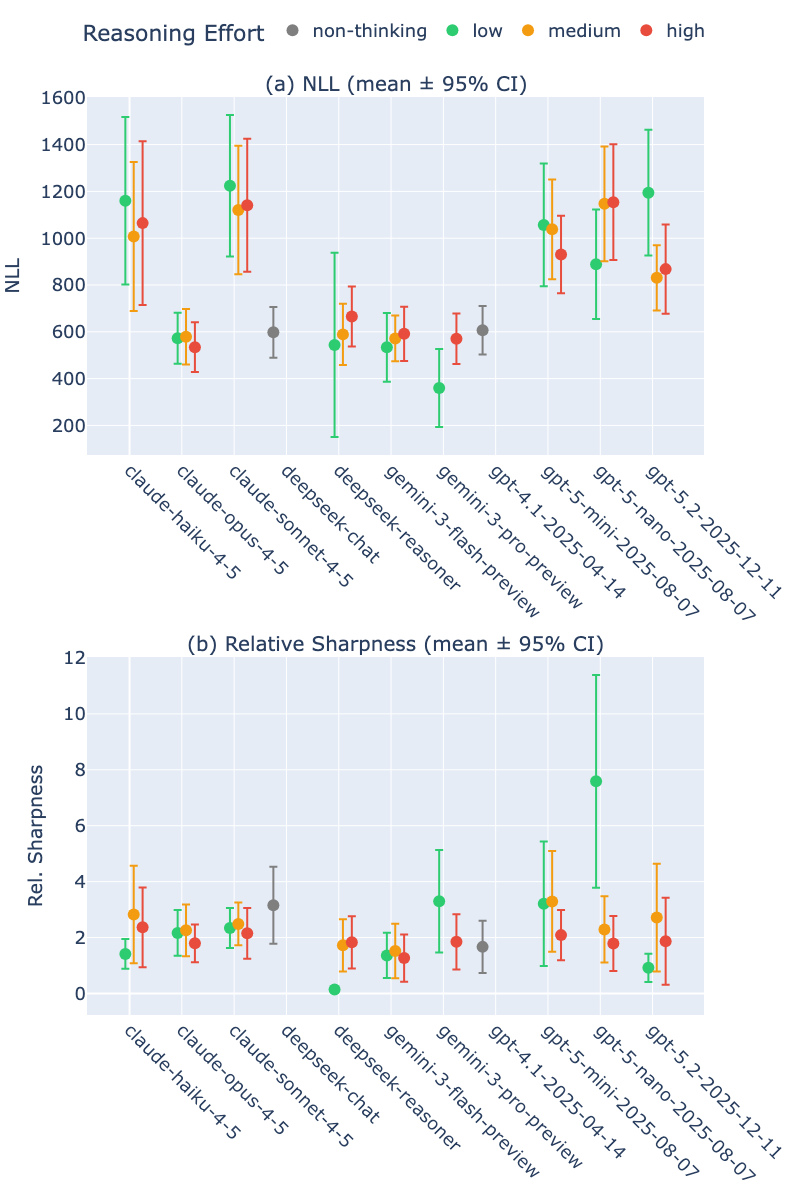
Figure 1: Negative log-likelihood and relative sharpness by model and thinking effort: model size is the dominant factor for improved performance, not reasoning effort.
Aggregated analysis across models and effort levels confirms this pattern: only interval sharpness (width) increases with more tokens or "thought", but neither accuracy nor calibration benefit, contradicting the premise that chain-of-thought produces logically superior or less biased distributions.
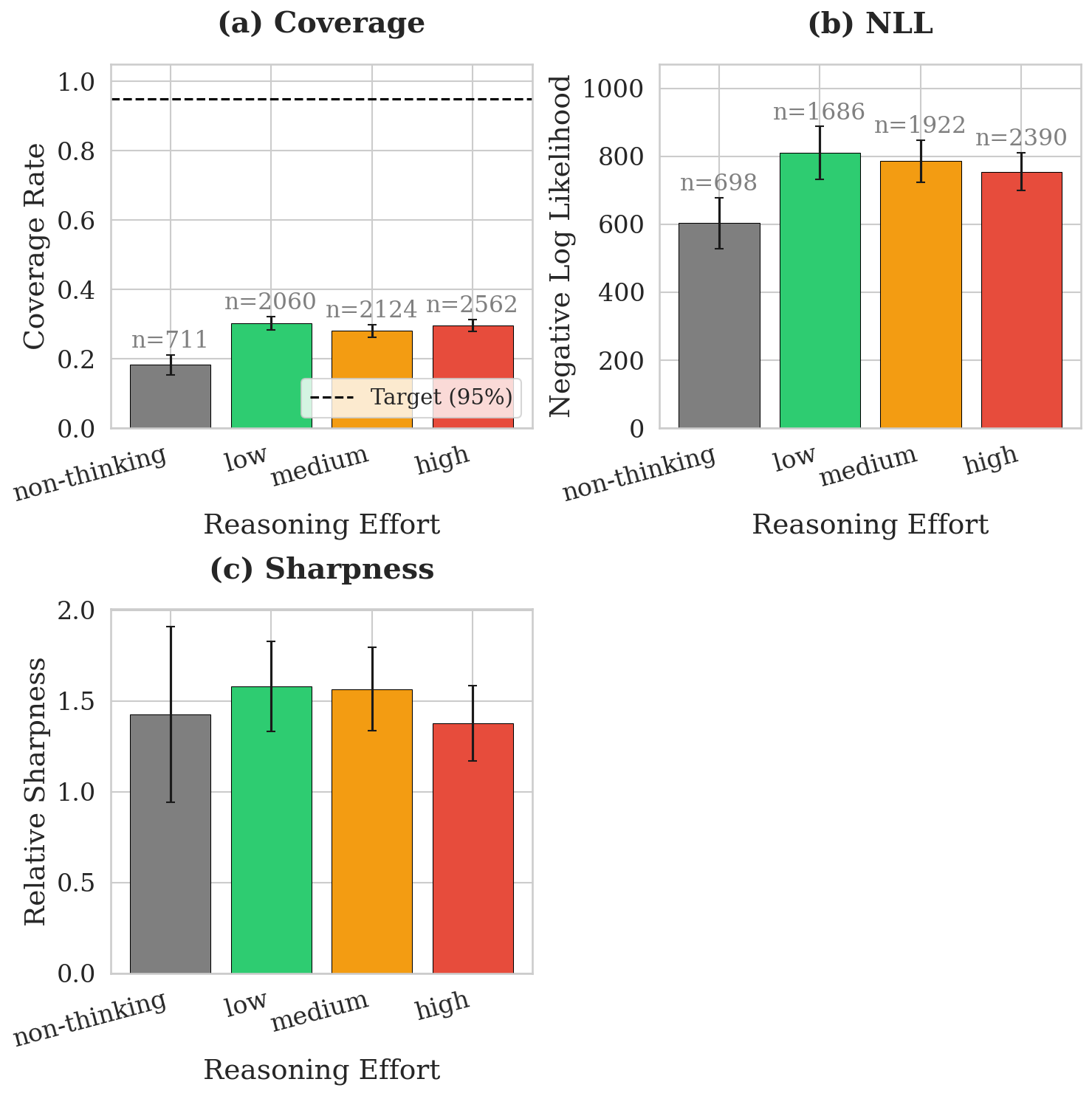
Figure 2: Aggregated NLL, coverage, and relative sharpness by reasoning effort level; sharpness (interval width) increases with effort, but NLL and coverage remain flat.
These findings are consistent with recent theoretical and empirical critiques of chain-of-thought effectiveness, highlighting its tendency toward conditional pattern matching and overfitting to the training data distribution rather than substantive, Bayesian reasoning [(Chlon et al., 15 Jul 2025, Mirzadeh et al., 2024), arenda2025openestimate].
Severe Systematic Overconfidence
A critical and robust finding is that all models, irrespective of family, scale, and effort, are severely overconfident in their credible intervals. Empirically, 95% intervals include the ground truth in only 9–44% of cases across all configurations, a substantial and systematic calibration deficit. Point estimates are typically biased toward lower values for rare or out-of-distribution statistics, and interval width has little correspondence with correct coverage. This overconfidence is not mitigated by increased reasoning effort or by using earlier model versions or architectures.
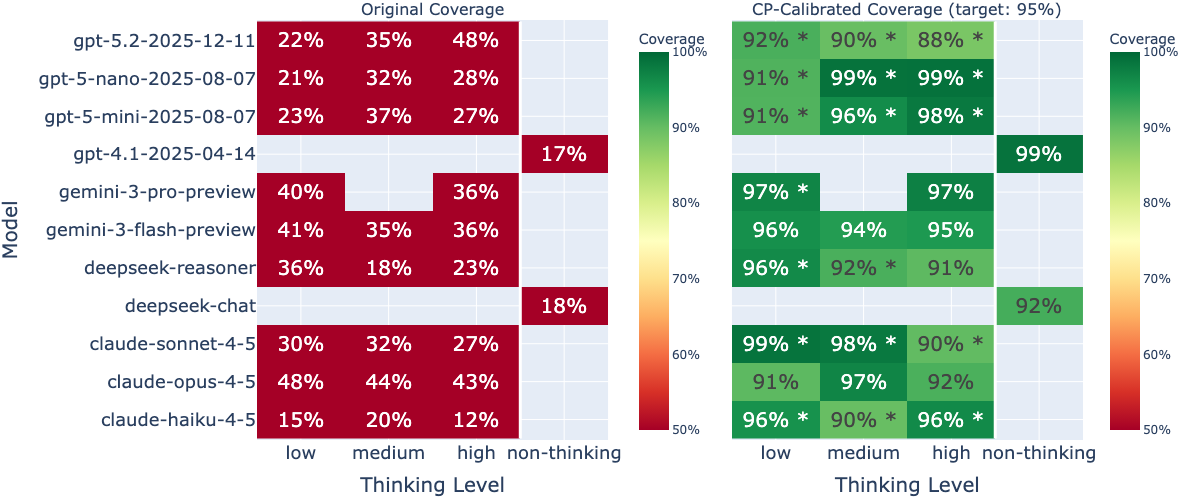
Figure 3: Original and CP-calibrated coverage by model and reasoning effort; severe under-coverage in raw intervals is corrected post-hoc via conformal prediction.
Applying normalized residual split conformal prediction to model outputs reliably recalibrates intervals to nominal 95% coverage for all suitable model/dataset/effort combinations, confirming that the pre-correction overconfidence is both systematic and correctable. The typical conformal multiplicative factor ranges from 2 to 5, indicating that intervals must be substantially widened for empirically valid uncertainty quantification. However, this requires a non-trivial calibration set (≥15 points per group) and cannot be applied zero-shot, limiting out-of-domain deployment and use in high-stakes applications without adequate feedback data.
The preliminary evaluation of web search augmentation reveals that giving LLMs retrieval capacity is a double-edged sword: weak models benefit through improved access to necessary statistics, but already accurate, well-trained models are systematically degraded in both accuracy and calibration. The effect is also domain-dependent, with health data and personality statistics particularly susceptible to performance collapse under naive retrieval augmentation. This aligns with an internal-external knowledge interference hypothesis for tool-augmented LLMs.
Theoretical and Practical Implications
The results have acute implications:
- Current LLMs are not reliable standalone uncertainty quantifiers for quantitative tasks: Without substantial post-hoc calibration (e.g., conformal prediction), their credible intervals are systematically overconfident and should not be used in risk-sensitive contexts.
- Model selection trumps reasoning effort: Practical deployment should favor larger, more capable models at moderate reasoning configurations—allocating additional "thinking" tokens brings little benefit in probabilistic settings.
- Overconfidence is a fundamental, architecture-agnostic limitation: This finding reinforces that LLMs’ uncertainty representations are not inherently Bayesian and do not self-calibrate credibly out-of-the-box.
- External tool integration must be carefully managed: Tool augmentation may degrade performance on tasks where the LLM already has high-fidelity internal representations and should not be universally applied.
On the theoretical front, the findings support the hypothesis that chain-of-thought and related "reasoning" protocols amplify the conditional generative tendencies of LLMs without constructing more calibrated or accurate posterior distributions. Extensions of Bayesian neural models or dedicated internal calibration mechanisms should be prioritized in future LLM iterations [arenda2025openestimate, (Sun et al., 4 May 2025)].
Directions for Future Work
Areas warranting further investigation include:
- Calibration-aware fine-tuning and meta-learning protocols designed to improve coverage and interval reliability directly within the model.
- Ensemble methods with diversity regularization as alternative strategies to balance accuracy with reliable uncertainty quantification.
- Advanced, context-aware retrieval integration methods that avoid internal-external knowledge interference.
- Evaluation on high-stakes, low-data regimes where split calibration is not available, assessing robustness of calibration transfer across domains.
Conclusion
This study provides a rigorous multi-model, multi-domain empirical analysis of LLMs as Bayesian elicitation tools. Model size robustly predicts performance, while increased chain-of-thought effort yields inconsistent or negative effects. All tested models exhibit acute systematic overconfidence, which conformal prediction can correct post-hoc but only with labeled calibration data. Tool augmentation presents mixed impact contingent on baseline model quality and target domain.
LLMs cannot be entrusted with critical quantitative uncertainty tasks without robust external calibration. Further foundational research is required to close the calibration gap, reimagine “reasoning” protocols for probabilistic applications, and develop architectures that natively represent and adapt uncertainty in distributional prediction contexts.