- The paper demonstrates that LLMs significantly overestimate their accuracy in tabular QA, with ECE values between 0.35 and 0.64, far exceeding those in textual QA.
- The paper reveals a pronounced dichotomy where perturbation-based techniques, especially Multi-Format Agreement (MFA), achieve higher AUROC (0.78–0.86) compared to self-evaluation approaches.
- The paper introduces structure-aware recalibration by integrating table features to enhance discriminatory power, yielding up to a +10pp AUROC improvement at reduced API costs.
Calibrated Confidence Estimation for Tabular Question Answering
Motivation and Contributions
This work offers the first systematic examination of confidence estimation methods for LLM-based tabular question answering (QA), addressing a longstanding gap: while calibration for textual QA is a mature field, there has been little analogous scrutiny for LLMs operating over structured data. The authors benchmark five confidence elicitation methods across five recent LLMs (OpenAI GPT-4o, Gemini 2.5 Flash, Llama-3.3-70B, DeepSeek-V3, GPT-4o-mini) on two QA benchmarks: WikiTableQuestions (WTQ) and TableBench. Three principal contributions stand out:
- Establishing severe overconfidence among LLMs on tabular QA: All tested models exhibit smooth ECEs between 0.35 and 0.64, an order-of-magnitude worse than typical values reported for textual QA (0.10–0.15), and significant gaps between reported confidence and empirical accuracy across all tested systems.
- Documenting a robust dichotomy between self-evaluation and perturbation-based uncertainty estimation: Verbalized self-confidence and the two-pass P(True) approach yield AUROC in 0.42–0.76, barely above chance for many settings, while perturbation-driven methods (self-consistency, semantic entropy, and the newly introduced Multi-Format Agreement) deliver substantially better AUROC in 0.78–0.86. This phenomenon is robust under multiple models and datasets.
- Proposing Multi-Format Agreement (MFA): MFA uniquely exploits the format sensitivity—Markdown, HTML, JSON, CSV—of LLMs answering over structured data to implement lossless, deterministic input perturbations, achieving matched or superior calibration versus sampling-based baselines at 20% lower API cost. Additionally, the paper introduces structure-aware recalibration, supplementing Platt scaling with features like table size and query complexity, yielding a +10pp AUROC improvement over classical post-hoc recalibration.
Confidence Elicitation Paradigms and Methods
Five methods are comparatively evaluated, partitioned into self-evaluation and perturbation regimes.
- Self-evaluation:
- Verbalized confidence: LLMs are prompted to provide both an answer and a confidence score in a single structured output.
- P(True): A two-turn protocol where the model is explicitly asked to report the probability its answer is correct.
- Perturbation-based approaches:
- Self-consistency (SC): Multiple temperature-controlled samples; confidence is the rate at which the majority answer appears.
- Semantic entropy (SE): Clustered samples' normalized entropy, reflecting semantic variability.
- Multi-Format Agreement (MFA): Each question is posed with the table input serialized in four losslessly equivalent formats. The proportion of formats where the answer matches the majority is treated as the confidence estimate.
This typology captures both model-internal (self-eval) and functional (perturbation-induced disagreement/uncertainty) signals. Crucially, input perturbation via MFA is deterministic and lossless, leveraging the natural multiplicity of structured representations—contrasting with noisy or lossy paraphrasing typically used for text input.
Experimental Design
The evaluation employs WTQ (interpretable, compositional, 2.1k tables) and TableBench (harder, numerical reasoning and data analysis spectrum), spanning a range of QA difficulties (accuracy from 33% on TableBench up to 77% on WTQ). Five contemporary LLMs constitute the backbone of benchmarking, and all methods are applied under controlled budgets (e.g., MFA: 4 calls, compared to 5 for sampling-based SC/SE methods).
Numerical Results and Comparative Analysis
Overconfidence of LLMs
All tested LLMs are sharply overconfident on standard tabular QA, with a typical confidence-accuracy gap of 23–30pp. For instance, GPT-4o averages 99.5% confidence but only 76.2% accuracy on WTQ. ECE values, whether smooth or binned, are uniformly higher than standard benchmarks for text QA.
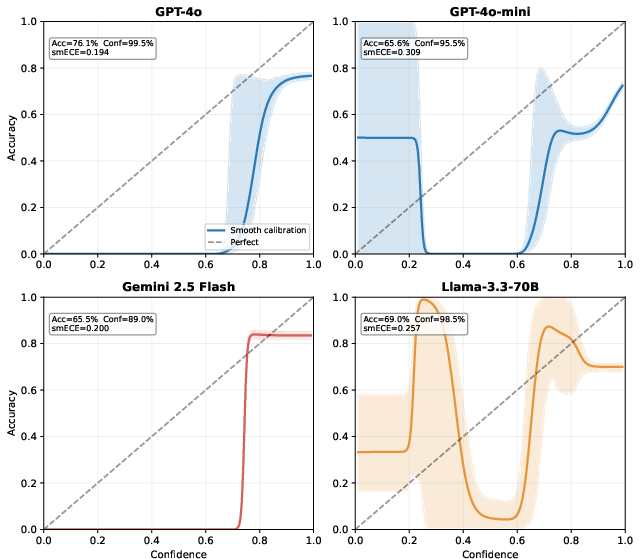
Figure 1: Smooth reliability diagrams reveal severe overconfidence among all models, especially GPT-4o whose confidence saturates at near-certainty regardless of answer correctness.
Self-Evaluation vs. Perturbation Dichotomy
Results reveal stark performance differences: verbalized confidence and P(True) are only marginally discriminative (AUROC ≈ 0.5–0.6), while perturbation methods (SC, SE, MFA) achieve AUROC ≈ 0.75–0.85 with substantial ECE reductions (45–63%). This dichotomy is robust on both WTQ and TableBench and persists across all tested models, as confirmed by rigorous statistical testing (paired bootstrap with Holm-Bonferroni correction, p < 0.001).
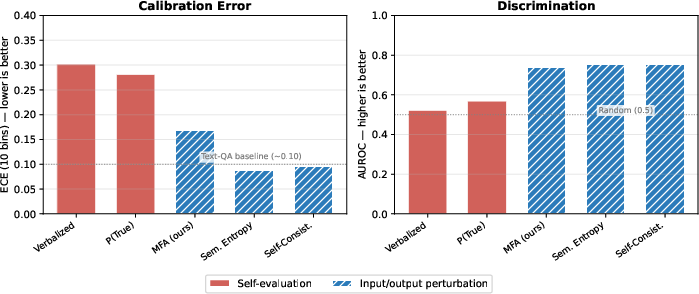
Figure 2: Comparisons on Llama-3.3-70B; perturbation methods (blue) deliver high discrimination while self-evaluation (red) approximates random guessing.
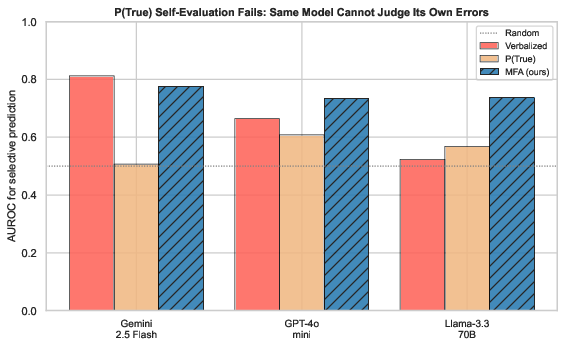
Figure 3: AUROC distributions for P(True) self-evaluation are consistently near-random across three models; MFA reliably provides strong discrimination.
Notably, Gemini is an exception with better-than-chance verbalized confidence (AUROC 0.81). However, perturbation methods still provide reproducible benefit in all other cases.
MFA achieves similar or superior calibration to sampling baselines (SC, SE) on all metrics (AUROC, ECE) at lower API cost. On TableBench, it generalizes with similar improvement patterns: perturbation methods dominate self-evaluation baselines, and the dichotomy is statistically significant.
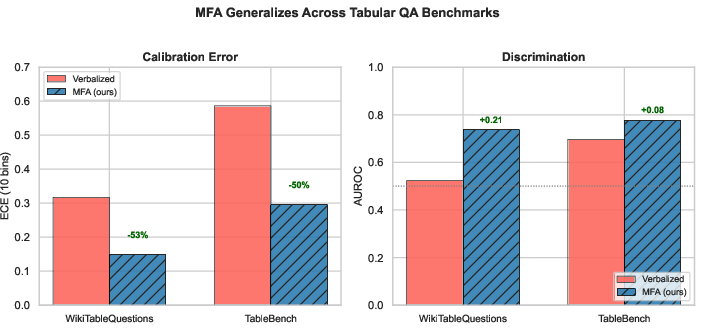
Figure 4: MFA generalizes robustly from WTQ to TableBench, halving ECE and maintaining discrimination.
MFA's performance advantage is most visible in cases where agreement across format permutations is low, indicating the model's sensitivity to surface features rather than robust semantic reasoning.
Structure-Aware Recalibration
Post-hoc monotonic recalibration (temperature scaling, Platt scaling, isotonic regression) is effective at reducing calibration error (ECE < 0.1), but does not enhance discrimination as measured by AUROC—since monotonic transforms cannot alter ranking. Augmenting the recalibration model with interpretable structural features (table size, column types, query complexity) increases AUROC by as much as +10pp, demonstrating these covariates' ability to capture systematic sources of model failure in structured QA.
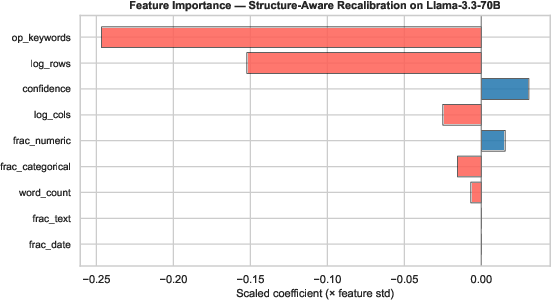
Figure 5: Feature importance analysis suggests query complexity and table size are the dominant factors for improving recalibration discrimination.
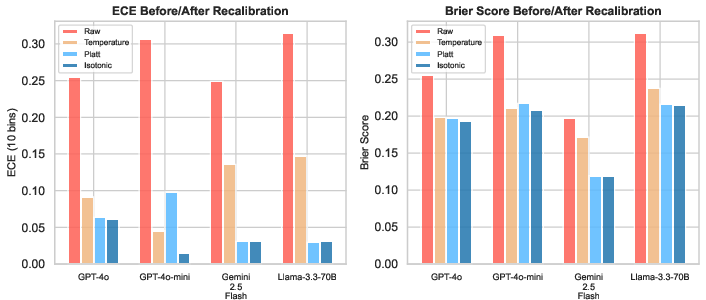
Figure 6: Standard post-hoc recalibration reduces ECE/Brier but not AUROC; structure-aware recalibration uniquely improves discrimination.
Method Combinations and Ensembles
Combining MFA (input perturbation) and SC/SE (output perturbation) further increases discriminatory power (e.g., ensemble AUROC lifted from 0.74 to 0.82), confirming that these approaches capture orthogonal uncertainty sources.
Cost-Efficacy and Implementation Notes
Ablation studies show that K=3 format permutations in MFA preserves most benefits at reduced cost (only minor AUROC drops versus the full K=4 setting), facilitating practical deployments where API budget is a constraint.
Practical Implications and Theoretical Ramifications
This work discredits self-evaluation methods (including the popular P(True) and post-hoc verbalized confidence) as reliable means for selective prediction or abstain/automation policies in LLM-powered table QA. Instead, robust deployment should rely on input/output perturbation mechanisms, with MFA offering a uniquely lossless, deterministic, and cost-efficient option for applications that natively handle structured data.
By establishing the first general-purpose, model-agnostic, statistically rigorous comparative framework for tabular QA calibration, the authors set a new standard for diagnostics and reporting in high-stakes, structured-domain LLM applications. The separation between calibration and discrimination, and the demonstration that structural features can be leveraged for improved reliability, also generalize to other structured data domains (e.g., knowledge graphs, code, chemical formulas).
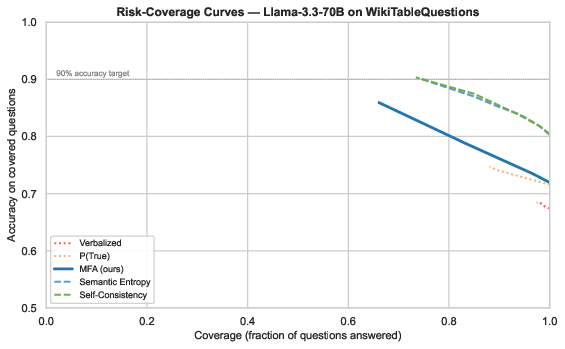
Figure 7: Risk-coverage curves exhibit flat lines for self-evaluation, while perturbation methods sharply improve accuracy at low coverage—an essential property for selective automation.
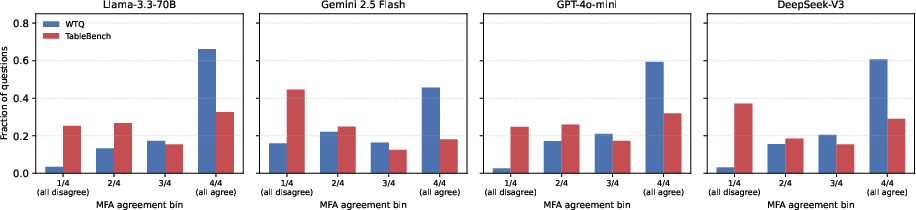
Figure 8: MFA agreement distributions on WTQ saturate the all-agree bin, while on TableBench the agreement distribution is more informative, supporting richer uncertainty estimation.
Future Work
Potential extensions include:
- Structured conformal prediction using MFA scores, providing rigorous coverage guarantees for abstention systems.
- Further ensemble models that mix input/output perturbation and self-evaluation-derived signals.
- Integration within tool-routing or hybrid symbolic/neural table processing pipelines.
- Generalization of MFA-like approaches to any context where canonical, lossless input perturbations are feasible.
Conclusion
This paper presents a rigorous, empirical treatment of calibration and confidence estimation for LLM-based tabular QA. It demonstrates with strong statistical support that:
- LLMs substantially overestimate their accuracy for structured QA,
- Self-evaluation confidence signals are inadequate, and
- Input/output perturbation methods—most effectively, MFA using table serialization variation—are both discriminative and efficient for assessing LLM reliability in this setting.
The proposed MFA and structure-aware recalibration frameworks set a new baseline for trustworthy deployment and risk assessment of LLMs in high-stakes, structured data environments. The work opens several avenues for theory-driven advancement in uncertainty quantification intersecting the calibration and tabular QA communities.