- The paper introduces 40 real-world policy evaluation cases and finds LLM accuracy drops from 81.3% overall to 68.8% on counter-intuitive tasks.
- The methodology uses a dual-process cognitive framework with mixed-effects logistic regression, showing that Chain-of-Thought prompts boost obvious-case accuracy but offer little help on counterintuitive cases.
- The implications warn that current LLMs risk confidently erroneous policy evaluations, urging research towards new architectures for better inhibitory control over intuitive biases.
Intuitiveness Drives the Limits of LLM Counterfactual Reasoning in Policy Evaluation
Introduction
"Thinking Fast, Thinking Wrong: Intuitiveness Modulates LLM Counterfactual Reasoning in Policy Evaluation" (2604.10511) presents a rigorous evaluation of LLMs' capacity for counterfactual reasoning in empirical policy analysis. Distinct from prior causal benchmarks reliant on synthetic tasks or heavily commonsense-oriented domains, this work probes performance on real-world social science cases where ground-truth causal effects may run counter to prevailing intuition or even expert priors. The study leverages a dual-process cognitive framework to systematically dissect how LLMs align with or deviate from such reasoning, exposing critical limitations in the internal mechanisms of prominent LLMs when confronted with scenarios where answer correctness is at odds with intuitive expectations.
Benchmark Construction and Evaluation Methodology
The benchmark comprises 40 policy evaluation cases rooted in peer-reviewed economics and social science, spanning diverse domains, countries, and identification strategies (e.g., RCT, DiD, IV). A key innovation is the classification of each case as "obvious," "ambiguous," or "counter-intuitive" relative to what an informed layperson would expect. Cases such as "Right-to-carry laws increase violent crime" and "Fines for late daycare actually increase lateness" typify the counter-intuitive category.
The study interrogates four leading models—GPT-5.2, Claude Sonnet 4, Claude Opus 4.6, and GPT-4.1—across five prompting strategies including naïve, expert persona, chain-of-thought (CoT), structured reasoning, and an adversarial anchor. Experimental rigor is ensured via 2,400 trials with mixed-effects logistic regression analysis, separating the effects of model, prompt, intuitiveness, and their interactions on response accuracy.
Key Empirical Findings
While the overall benchmark accuracy is 81.3%, this figure conceals substantial performance variation driven by both test type and intuitiveness. One-sided tests yield near-ceiling accuracy (98.3%), yet the more challenging two-sided tests see aggregate accuracy fall to 73.1%. Critically, within two-sided tests, accuracy on counter-intuitive cases is only 68.8%, compared to 75.4% on obvious instances.
The performance hierarchy among models is pronounced. GPT-5.2 outperforms all peers consistently, maintaining 91.1% accuracy even on two-sided counter-intuitive cases. By contrast, GPT-4.1 attains only 43.3% in this challenging regime—barely above the random-choice baseline.
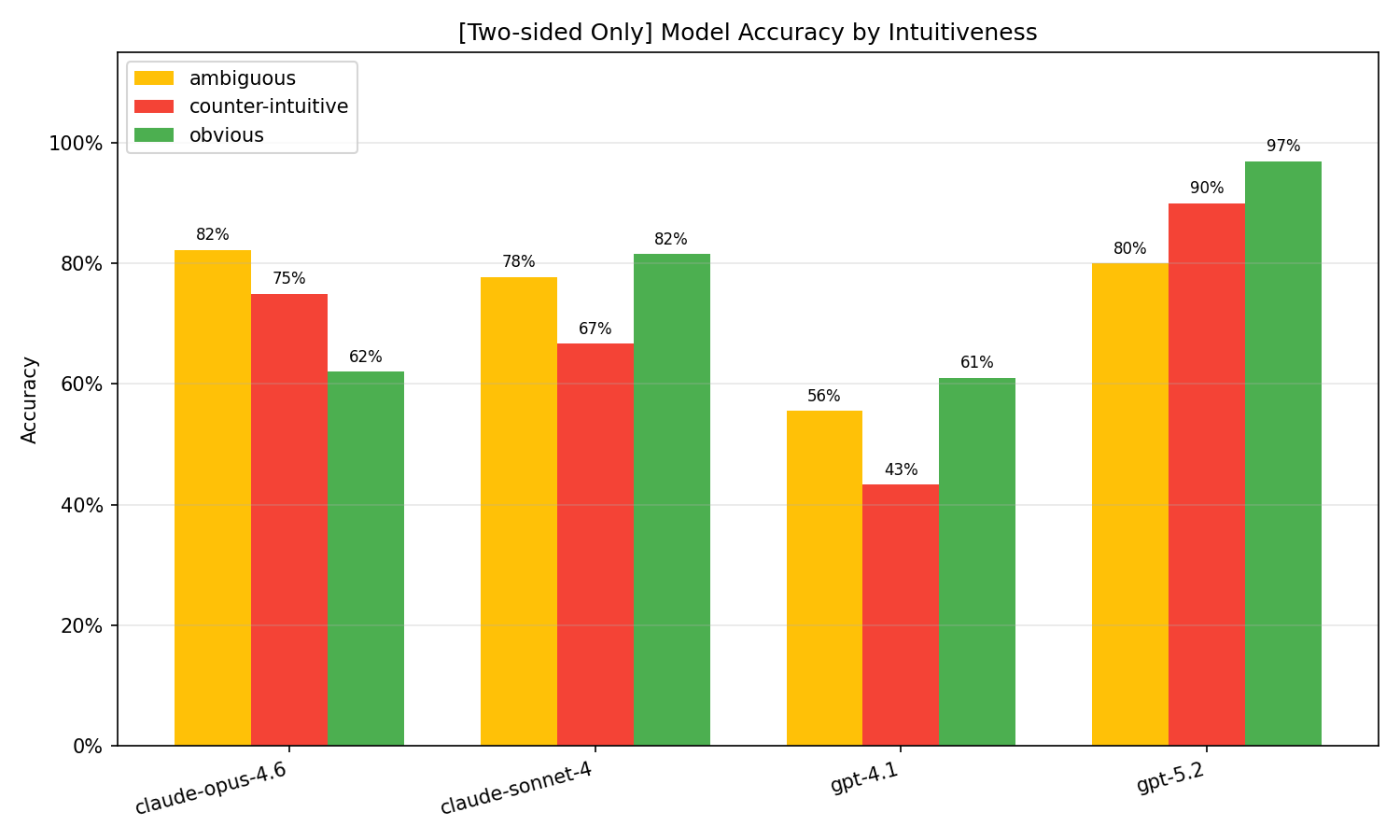
Figure 1: Accuracy on two-sided cases by model and intuitiveness, highlighting GPT-4.1’s especially poor results on counter-intuitive examples.
The Chain-of-Thought (CoT) Paradox
The most salient result is the identification of the Chain-of-Thought paradox. While CoT prompting yields substantial accuracy improvements on "obvious" cases (+17 percentage points), its benefit on counter-intuitive ones is minimal (+4 percentage points). Mixed-effects modeling confirms this with a dramatic CoT × counter-intuitiveness interaction effect (OR = 0.053, p<0.001).
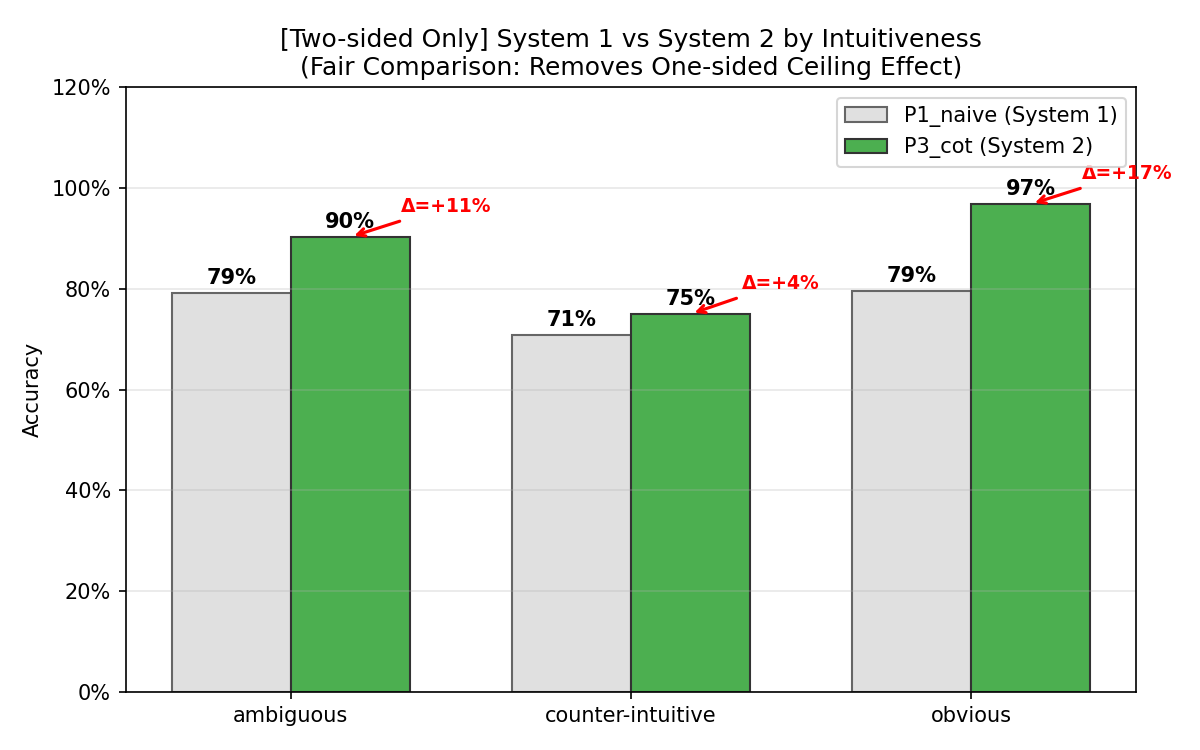
Figure 2: CoT-induced accuracy improvements are differential: robust gains for obvious cases, minimal for counter-intuitive, implicating reinforcement rather than override of intuitive priors.
This effect generalizes to other reasoning-heavy prompts; structured prompts show an even larger drop in efficacy on counter-intuitive queries (interaction OR = 0.034).
Intuitiveness as the Dominant Variance Source
Intraclass correlation analysis places case intuitiveness as the dominant factor explaining accuracy variance (ICC = 0.537), eclipsing both model identity and the effect of prompt engineering. These data strongly support the thesis that LLM counterfactual reasoning is fundamentally constrained by the congruence or incongruence of ground truth with intuitive priors.
Error Consistency and Failure Structure
Majority-vote "self-consistency" improves accuracy only marginally (from 81.3% to 82.4%), with systematic errors persisting—i.e., LLMs repeatedly applying the wrong causal model rather than fluctuating stochastically. On error-prone cases where the correct response is "INCREASE," 75% of errors are consistent directional reversals rather than uncertainty, confirming a failure to effectively inhibit intuitive causal beliefs.
Heatmap visualization confirms that certain cases—such as those involving daycare fines and right-to-carry laws—produce systematic, cross-model failures clustered among counter-intuitive cases.
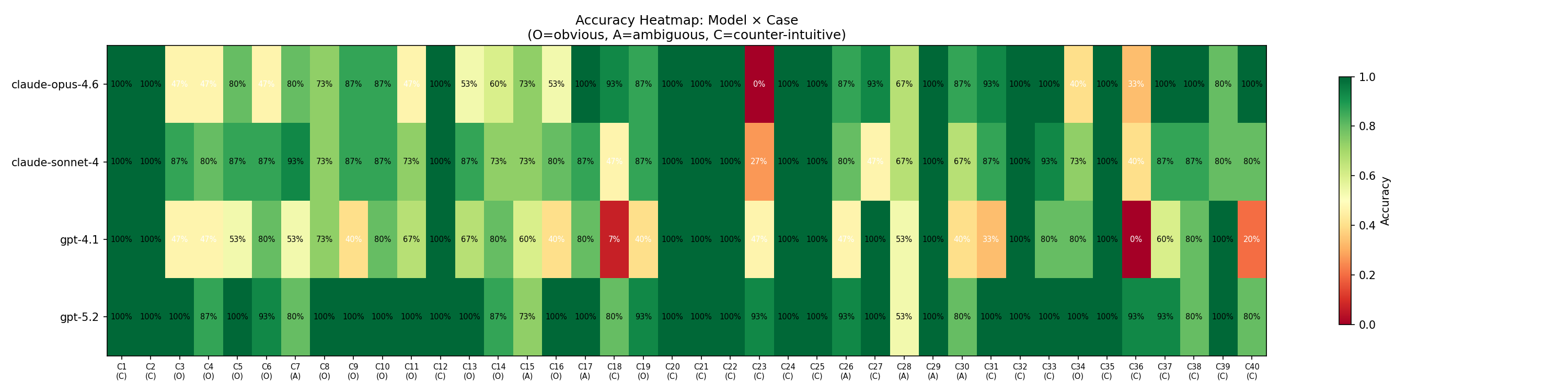
Figure 3: Heatmap of model and case accuracies identifies red clusters denoting systematic, intuition-driven failures on specific counter-intuitive cases.
Knowledge–Reasoning Dissociation
Unlike the "causal parrots" hypothesis, empirical findings indicate that accuracy does not correlate with the citation count of the underlying study (OR = 1.271, p=0.53). Even well-known, highly cited effects are systematically answered incorrectly, demonstrating that mere knowledge inclusion in pretraining is not sufficient for robust reasoning when knowledge must override intuitive priors.
Theoretical and Practical Implications
Dual-Process Model Inference
The empirical results parallel key findings in human cognition: LLMs default to "System 1"-like fast, intuitive reasoning, and "System 2" analogues triggered by CoT prompting often lack genuine inhibitory control. Such CoT chains frequently rationalize initial, intuition-based responses rather than override them, a result that generalizes and extends the CoT critique from [jacoviACL2024cot]. Dual-process theory therefore provides a useful lens for diagnosing architectural deficits in current LLMs regarding inhibitory and override capabilities.
Consequences for Policy Analysis Deployment
The inflation of aggregate accuracy by intuitive cases obscures a crucial risk in practical deployment: LLM systems provide confidently erroneous evaluations precisely in cases where careful, empirical reasoning is most needed. Reliance on even SOTA LLMs for evaluative guidance in real-world policy analysis entails substantial risk, especially in domains rife with counter-intuitive causal effects (e.g., behavioral economics, regulatory interventions).
Future Research Directions
The observed performance plateau on counter-intuitive cases motivates research towards novel architectural mechanisms or training paradigms aimed at enhancing LLM inhibitory control—potentially spanning model-level adaptations, learning objectives focused on override tasks, or new forms of reasoning supervision. There remains open space for benchmarks that more precisely isolate the tension between knowledge retrieval and the construction of counterfactual reasoning pathways that accurately override intuition.
Conclusion
This work establishes that intuitiveness modulates LLM reasoning accuracy in a manner that current prompting and model architectures fail to surmount. Chain-of-thought prompting, long promoted as a silver bullet for intricate reasoning, is shown to be largely ineffective when accuracy depends on the suppression of intuitive but incorrect causal priors. The disconnect between knowledge recall and correct application underscores that LLMs’ so-called "slow thinking" is often only syntactically deliberative, devoid of functional override capacity. True progress on counterfactual reasoning in LLMs will require innovations that implement genuine inhibitory control akin to human System 2 processes.