- The paper demonstrates that eliciting self-reported confidence significantly reduces calibration errors and Brier scores compared to self-consistency and token-based methods.
- It reveals that while larger models improve accuracy, calibration benefits depend on the dataset and method, with some cases showing degradation.
- It highlights the top-skewed nature of LLM confidence scores, suggesting that tailored thresholding is essential for effective selective automation in grading.
Calibration of Confidence for Automated LLM Assessment: A Comprehensive Analysis
Introduction
This work provides a systematic evaluation of confidence calibration for automated grading by LLMs. Rather than focusing on increasing absolute grading accuracy, the study addresses the orthogonal, practically crucial question: when can an LLM grader’s prediction be trusted? The authors empirically investigate three distinct methods for extracting confidence scores from LLM graders—self-reported confidence, self-consistency voting, and token-level probability estimates—across seven models (ranging from 4B to 120B parameters) and three educationally relevant, human-graded short and long answer datasets. The results are analyzed in terms of calibration error, confidence distributions, and implications for selective automation in grading pipelines.
Problem Definition and Methodological Framework
The automated grading task formalized here is binary: given a question, student response, and rubric, predict whether the response satisfies the rubric. LLMs are used as graders, but their outputs may diverge from human-provided ground-truth labels. A confidence estimator C(x) that outputs a calibrated probability interpretable as P(LLM correct on x) is the main focus.
Three estimation paradigms are benchmarked:
- Token Probability: Uses softmax probabilities over verdict tokens (yes/no);
- Self-Reported Confidence: Prompts the LLM to directly assign an integer confidence rating (normalized post-hoc);
- Self-Consistency: Draws multiple (n=5) outputs via stochastic sampling and uses the fraction of majority votes as the confidence.
Evaluation is carried out via multiple calibration and ranking metrics: Expected Calibration Error (ECE), Brier score, AUC-ROC, and coverage at risk-thresholds. Bootstrap-based statistical procedures underpin all inferential claims.
Main Results and Empirical Findings
1. Self-Reported Confidence Yields Superior Calibration
Across all datasets and model scales, self-reported confidence resulted in the lowest ECE and Brier scores. For small models, self-reported ECE averaged 0.197 versus 0.229 (self-consistency) and 0.235 (token-probability). Large models showed further drop to average ECE 0.142 with self-reported confidence, whereas alternatives mostly stagnated or degraded slightly with scale. The empirical margin (0.166 vs. 0.229) establishes the superiority of self-reported signals, confirmed by significance in pairwise model-level bootstrapping.
Self-consistency, a popular method for uncertainty quantification in LLM-based reasoning [Wang et al., 2023], underperformed by 38% (ECE) despite requiring 5x the inference cost—counter-indicating its utility for practical grading pipelines.
2. Model Scale Primarily Drives Accuracy, Not Calibration
Larger models consistently increased prediction accuracy. Calibration improvements, however, were heavily dataset- and method-dependent. For self-reported confidence, gains were moderate on short-answer datasets, with marginal improvements on longer answer tasks (RiceChem). Notably, there are scenarios where token-probability calibration degrades with scale (RiceChem and Beetle), highlighting that larger LLMs do not guarantee improved confidence calibration across all extraction methods.
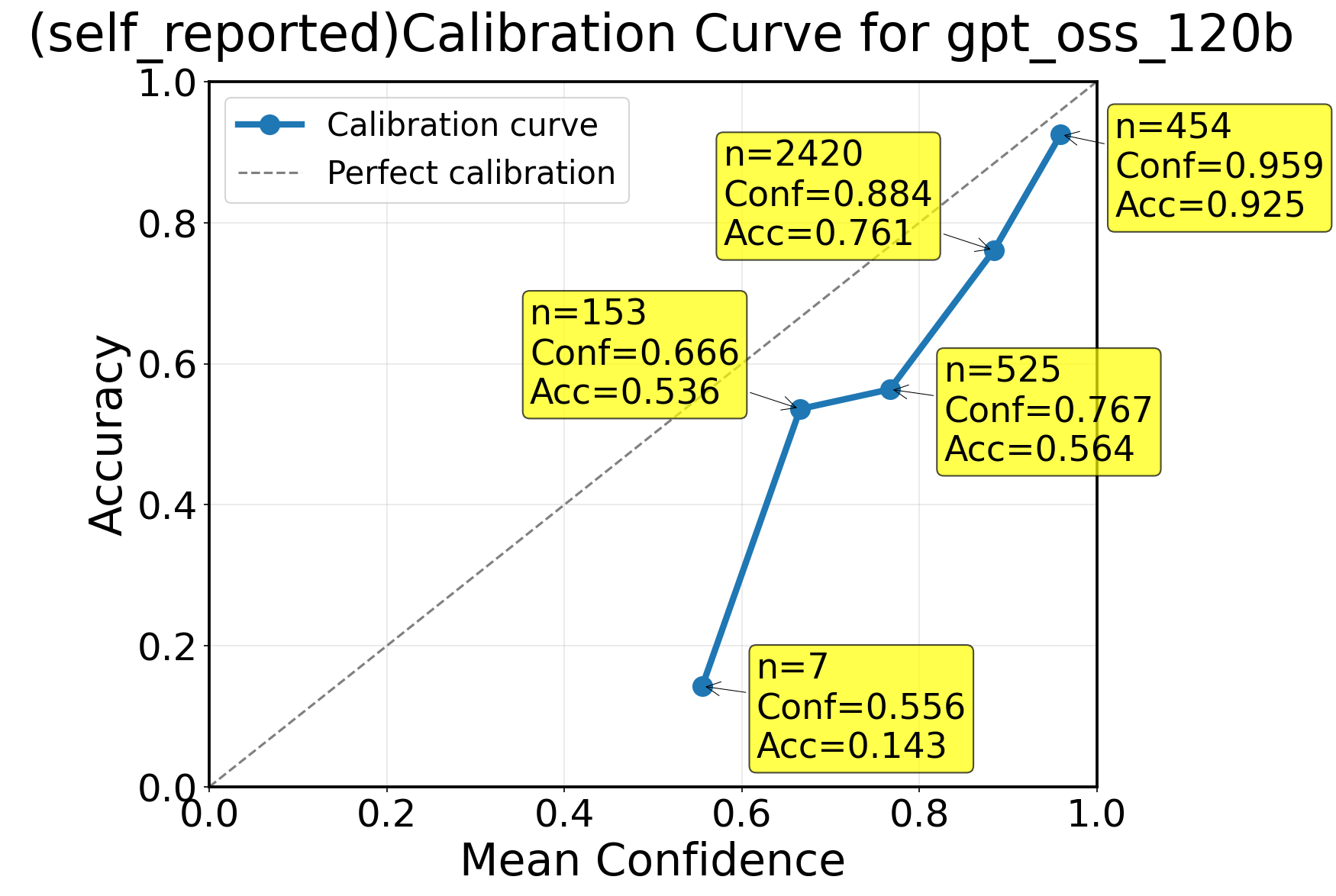
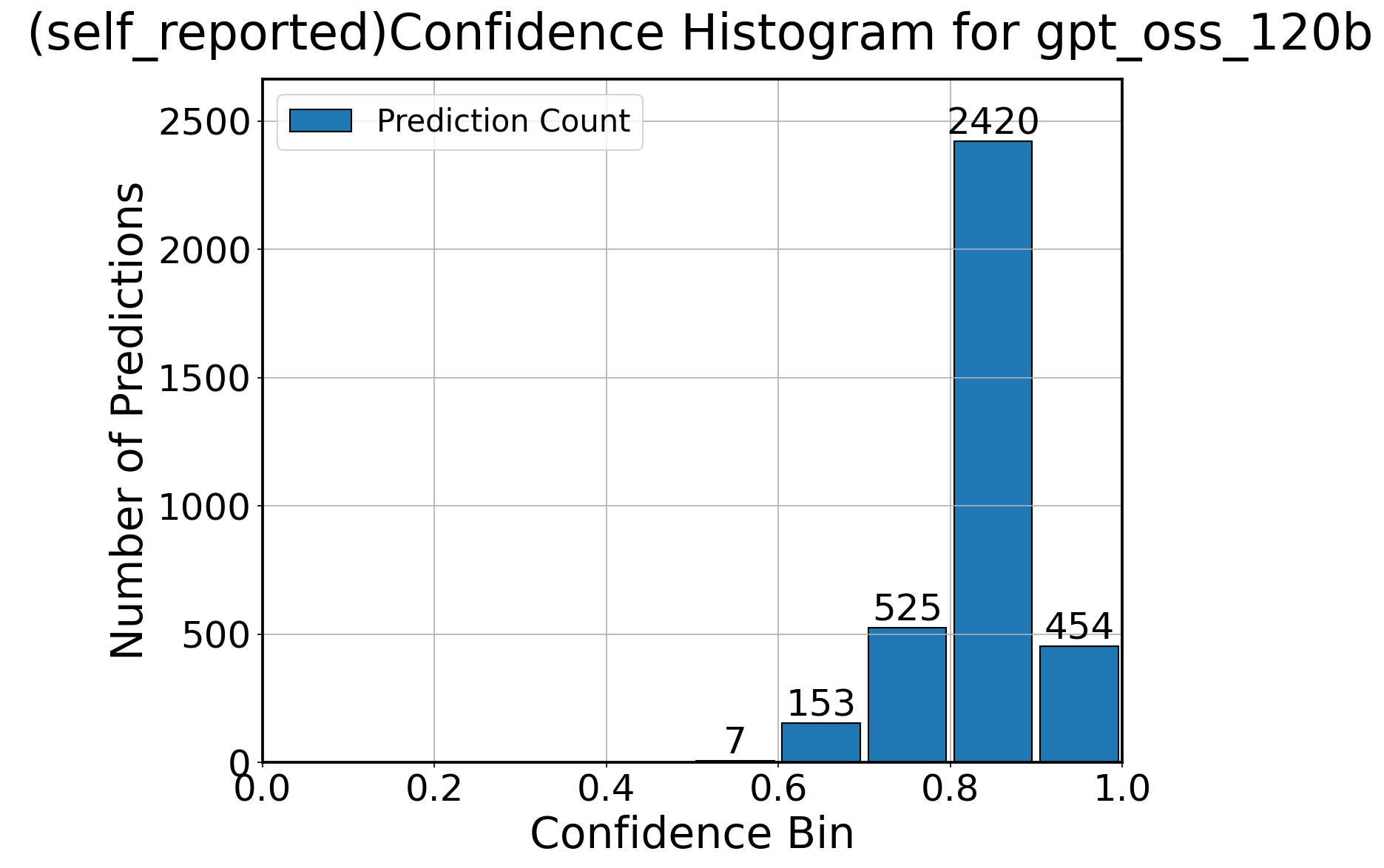
Figure 1: RiceChem: calibration curve for GPT-OSS-120B with self-reported confidence.
3. Confidence Distribution is Top-Skewed
Confidence outputs from all methods exhibit strong top-skew. For self-reported and token-based methods, over 85% of predictions are at or above 0.8 confidence, with almost none below 0.2. Self-consistency is inherently discrete—most outputs are perfect (5/5, or 1.0) or near-perfect. This skew induces a confidence floor: for deployment, thresholding should be adapted to each model’s empirical score distribution, not to intuitively chosen midpoints (e.g., 0.5).
4. Model-Specific Analysis
Among large models, GPT-OSS-120B consistently delivered the best calibration (avg ECE 0.100, Brier 0.180, AUC 0.668, per Table~4 in the text), and, unlike Qwen3-80B, its performance was stable across reasoning depth variations. Distinctions between "thinking" and "instruct" variants (Qwen3-80B) showed nontrivial tradeoffs: modes yielding higher accuracy could show weaker calibration depending on task, highlighting important architecture–prompt–task interactions.
Implications and Future Directions
Selective Automation and Practical Thresholding
Well-calibrated confidence enables selective automation: auto-grade only when the LLM is likely correct, otherwise defer to human review. With state-of-the-art (GPT-OSS-120B, self-reported) and a strict 5% risk target, only 11–20% of instances can be auto-graded—thus, reliable automation coverage is inherently limited by both calibration and the distribution of underlying difficulty. The top-skewed nature of LLM confidence further complicates static threshold selection.
The surprising strength of self-reported confidence, even surpassing computationally costly self-consistency, aligns with recent insights that LLMs are capable of "knowing what they know" ([Kadavath et al., 2022]; [Tian et al., 2023]; [Xu et al., 2024]). However, calibration is neither perfect nor monotonic with scale. In particular, calibration interacts with response, question, and rubric-level features—modeling these interactions (e.g., via mixed effects) may yield future improvements, especially in scenarios outside the evaluated domain/dataset space.
Limitations and Theoretical Extensions
The study is restricted to short- and long-answer grading tasks; investigation into multi-class, free-form, or higher-stakes academic assessments are logical next steps. Exploring synergistic or hybrid methods (ensemble of self-reported and token-probability, temperature-driven calibration, or perturbation-based techniques (Khanmohammadi et al., 27 May 2025)) may yield further gains, as could post-hoc recalibration methods from classical statistical literature (e.g., isotonic regression, Platt scaling).
From a theoretical perspective, the inherent top-skew of LLM confidence scores may reflect RLHF-induced reward shaping or training distribution artifacts. Deeper analysis, possibly leveraging advances in representation stability (Khanmohammadi et al., 27 May 2025), could provide a more fundamental understanding of when LLM metacognition aligns with ground truth.
Conclusion
This work delivers a comprehensive analysis of confidence calibration for LLM-based automated grading, revealing that explicitly elicited self-reported confidence provides the most reliable signal at minimal computational cost. Model size drives accuracy gains more robustly than calibration improvements, and all confidence metrics are highly top-skewed, constraining coverage in selective automation scenarios. These findings argue for the use of self-reported confidence as the primary automation gate in educational grading, with calibration statistics empirically validated via rigorous bootstrap and mixed-model analyses. Future research should explore extensions to broader tasks and develop mechanisms to further calibrate or interpret LLM metacognitive outputs.
References
- "When Can We Trust LLM Graders? Calibrating Confidence for Automated Assessment" (2603.29559)
- Kadavath et al., "LLMs (Mostly) Know What They Know" (Kadavath et al., 2022)
- Tian et al., "Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores..." [Tian2023EMNLP]
- Xiong et al., "Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs" [Xiong2024ICLR]
- Khanmohammadi et al., "Calibrating LLM Confidence by Probing Perturbed Representation Stability" (Khanmohammadi et al., 27 May 2025)