- The paper demonstrates that default verbal confidence elicitation leads to signal saturation, invalidating uncertainty estimates for 3–9B instruction-tuned models.
- It employs deterministic greedy decoding on 524 TriviaQA items to assess Type-2 discrimination, exposing severe degradation in categorical elicitation formats.
- Implications include significant risks for deploying these models in confidence-based systems until alternative, validated elicitation protocols are developed.
Verbal Confidence Saturation in 3–9B Instruction-Tuned LLMs: Empirical Validity and Deployment Implications
Introduction
The paper "Verbal Confidence Saturation in 3–9B Open-Weight Instruction-Tuned LLMs: A Pre-Registered Psychometric Validity Screen" (2604.22215) addresses the reliability of verbal confidence elicitation as an interface for extracting uncertainty from LLMs in the 3–9B parameter regime. The study applies a psychometric validity protocol to determine whether these models' confidence outputs—elicited verbally following question-answering—retain sufficient item-level Type-2 discriminatory power for downstream use, specifically under minimal numeric and categorical elicitation with greedy decoding. The investigation is motivated by the proliferation of studies assuming that LLM-generated confidence signals are both informative and well-calibrated, without direct verification of their actual validity.
Methodological Framework
Seven instruction-tuned open-weight LLMs from four families were assessed using a deterministic (greedy) inference regime on 524 TriviaQA validation items. Models provided explicit confidence estimates post-answering, under two elicitation paradigms: direct numeric (0–100) and 10-class categorical scales. Analyses were pre-registered, and the evaluation excluded any sampling stochasticity to focus on the models’ maximum-likelihood output for each prompt.
Validity was measured using a portable psychometric protocol adapted from clinical assessment, with a particular emphasis on degeneracy and item-level discrimination. The screening protocol classified model outputs as Valid, Indeterminate, or Invalid based on criteria such as binarised confidence response degeneracy, conditional error-detection rates, and directional indices (see Appendix A of the paper for the procedural details). Mean ceiling rates—the prevalence of maximal confidence responses—were scrutinized as a direct saturation indicator.
Empirical Findings
Saturation Prevalence and Validity Failure
All seven instruction-tuned LLMs failed to produce valid verbal confidence signals under numeric elicitation. The mean fraction of trials with confidence ≥95% was 91.7%, violating the minimal variability requirement for Type-2 discrimination (Figure 1). Five models exhibited degeneracy outright (>95% of binarised responses in a single category), with two models (M2, M7) outputting only high confidence values across all valid trials—a complete information collapse.
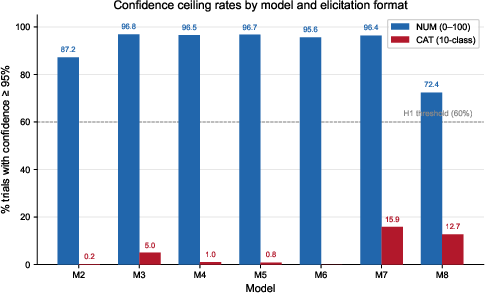
Figure 1: Confidence ceiling rates by model and elicitation format; all instruct models exceed 72% on numeric (NUM), with categorical (CAT) ceiling rates essentially zero.
Categorical Elicitation Interaction Failure
Attempts to “rescue” validity using a categorical elicitation format resulted in a distinct interaction failure: six out of seven models exhibited severe accuracy degradation (0.2–4.2%), with only M3 maintaining moderate accuracy. Thus, shifting from numeric to categorical confidence did not restore informative signal content and, instead, universally disrupted task performance under these prompt conditions.
Logprob–Confidence Relationship
Across models, token-level logprobabilities provided no usable predictive power for the verbalised confidence outputs; cross-validated R2 values were consistently below 0.20, confirming decoupling between direct model uncertainty metrics and explicit confidence responses as verbalized (H5 hypothesis, confirmed).
Type-2 Discrimination Metrics
Despite formal signal invalidity, the Type-2 AUROC2—a nonparametric index of confidence discrimination—was modestly above chance (0.527 to 0.683 across models, Figure 2). However, these values are artifactually inflated by a small subset (3–13%) of non-saturated trials, which does not rectify the overall collapse in signal informativeness.
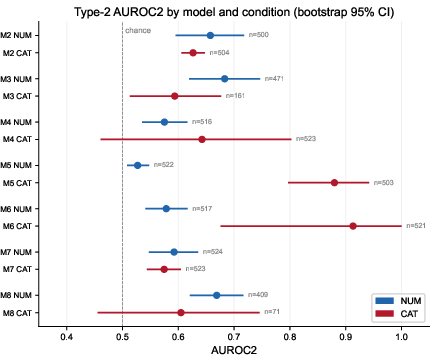
Figure 2: Type-2 AUROC2 analysis demonstrates modestly above-chance item discrimination, but is specified by a minority of non-ceiling responses.
Reasoning Contamination and Trace Length
For the reasoning-distilled model M8, the length of reasoning traces displayed a negative partial correlation with verbalised confidence (ρpartial=−0.36,p<.001), consistent with the “Reasoning Contamination Effect” observed in prior mechanistic probing (Miao et al., 26 Mar 2026) (Figure 3).
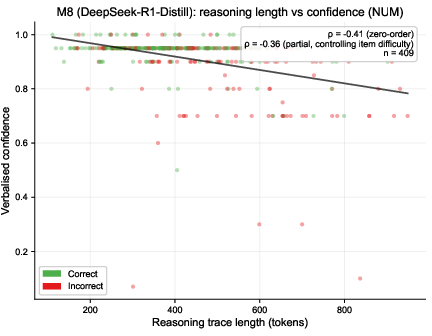
Figure 3: M8: Longer reasoning traces are associated with lower confidence, even after accounting for item difficulty.
Interpretation and Implications
Verbal Confidence as a Degenerate Readout
The saturation phenomenon—the collapse of confidence output to the ceiling across almost all items—signals a fundamental validity failure in the verbalized confidence interface for 3–9B instruction-tuned LLMs. This failure mode is not a matter of calibration error (misalignment between estimated and true probability), but a loss of variance prior to any possible calibration step, rendering the signal uninformative for selective prediction, abstention decisions, or uncertainty quantification.
Limitation to Specific Elicitation and Model Size
The observed failures are restricted to minimal prompts and greedy decoding in the considered model regime. They do not imply absence of internal uncertainty representations, as evidenced by moderate item-level correlations (e.g., ρ=.50 between underlying difficulty and mean confidence). Rather, the elicitation interface fails to transmit this signal in a usable form without more sophisticated probing or varied decoding strategies. Larger models (e.g., Gemma 27B) have shown more promising results (Kumaran et al., 18 Mar 2026).
Quantitative and Practical Relevance
The findings have immediate practical ramifications: any downstream system using such models for confidence-based abstention, output triage, or safety applications (e.g., human-AI collaboration, self-correction, dynamic prompt routing) should not assume that numeric or categorical verbal confidence elicited under default settings carries informative uncertainty content. Psychometric validity screening should be a standard prerequisite before any calibration or selective prediction workflows are pursued for model-generated confidence scores.
Future Research Directions
Further research should address whether alternative elicitation regimes (e.g., multi-step scaffolding, richer prompt design, temperature-based decoding) can reliably recover valid uncertainty signals from small- and mid-sized instruction-tuned models. Comparative behavioral and mechanistic work is also needed to chart model scaling trends and to characterise the probe–model–task interaction space in greater detail.
Conclusion
This study rigorously demonstrates that, for seven widely used 3–9B instruction-tuned open-weight LLMs, default verbal confidence elicitation produces universally invalid signals under psychometric scrutiny. Both numeric and categorical output formats failed to meet minimum requirements for item-level Type-2 discrimination, with confidence responses overwhelmingly saturated at the maximum value or associated with task performance collapse. Until robust elicitation protocols are established and validated, deployment systems relying on such confidence signals for uncertainty quantification are at significant methodological risk.