Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
Abstract: LLMs often lack meaningful confidence estimates for their outputs. While base LLMs are known to exhibit next-token calibration, it remains unclear whether they can assess confidence in the actual meaning of their responses beyond the token level. We find that, when using a certain sampling-based notion of semantic calibration, base LLMs are remarkably well-calibrated: they can meaningfully assess confidence in open-domain question-answering tasks, despite not being explicitly trained to do so. Our main theoretical contribution establishes a mechanism for why semantic calibration emerges as a byproduct of next-token prediction, leveraging a recent connection between calibration and local loss optimality. The theory relies on a general definition of "B-calibration," which is a notion of calibration parameterized by a choice of equivalence classes (semantic or otherwise). This theoretical mechanism leads to a testable prediction: base LLMs will be semantically calibrated when they can easily predict their own distribution over semantic answer classes before generating a response. We state three implications of this prediction, which we validate through experiments: (1) Base LLMs are semantically calibrated across question-answering tasks, (2) RL instruction-tuning systematically breaks this calibration, and (3) chain-of-thought reasoning breaks calibration. To our knowledge, our work provides the first principled explanation of when and why semantic calibration emerges in LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: Do LLMs “know what they don’t know” when answering open-ended questions? The authors study a kind of honest confidence called “semantic calibration.” That means checking if a model’s stated confidence matches how often its answers are actually right, not just at the level of the next word or token, but at the level of the answer’s meaning (the concept it expresses).
The main goals and questions
The paper has three easy-to-understand goals:
- Can we measure a model’s confidence about the meaning of its answer (not just the next word)?
- Are LLMs naturally well-calibrated in this semantic sense, even though they’re trained to predict tokens?
- When does semantic calibration show up, and when does it break?
In plain terms: If a model says it’s 70% sure about the kind of answer it’s giving (like “Paris” for “capital of France”), is it actually right about 70% of the time across many questions?
How they approached the problem (methods, explained simply)
Think of asking a friend a tricky question multiple times and seeing how often they pick the same answer. That’s the basic idea here:
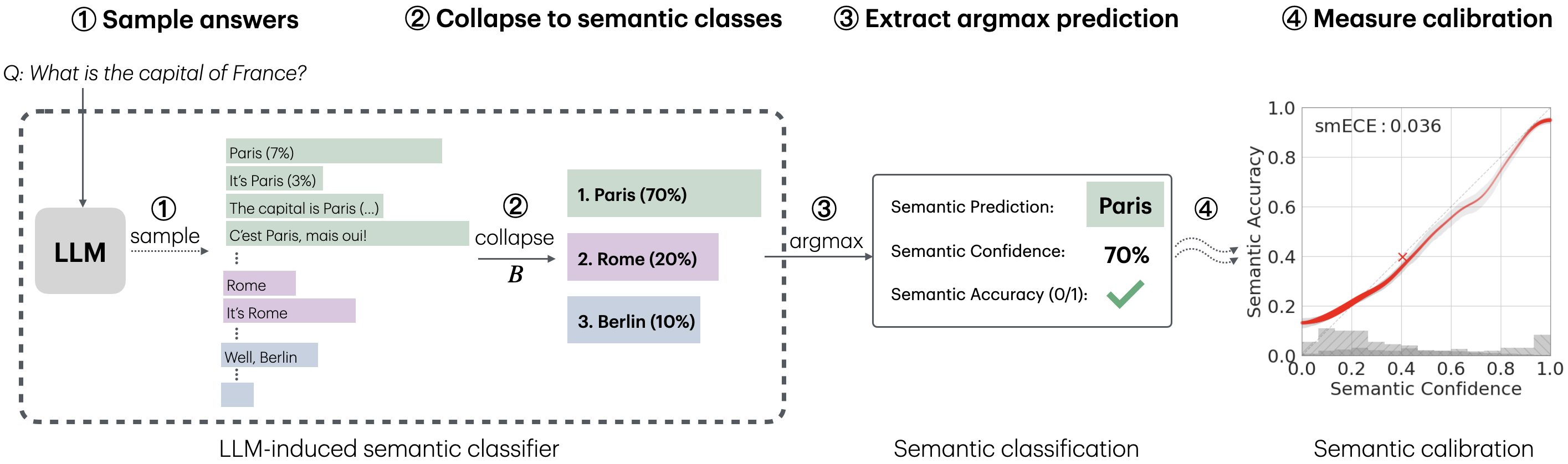
- Sampling: For each question, they let the LLM generate many answers (like 50), at a normal “temperature” (randomness level).
- Collapsing to concepts: They use a “collapsing function,” called B, to group different wordings that mean the same thing into one concept. For example, “Paris,” “It’s Paris,” and “The capital is Paris” all collapse to the concept “Paris.”
- Confidence from frequency: If 35 out of 50 generations collapse to “Paris,” the model’s semantic confidence in “Paris” is 70%.
- Calibration check: Across many questions, they compare the model’s confidence with how often those answers are actually correct. If “70% confidence” questions end up being correct around 70% of the time, that’s good calibration.
Behind the scenes, they also provide a theory for why this calibration can emerge “for free” from standard training:
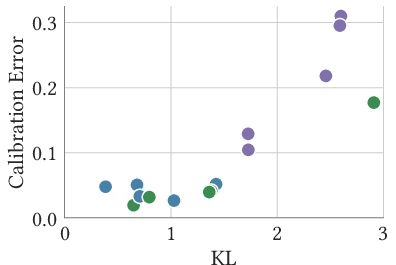
- LLMs are trained to minimize a “loss” that punishes wrong predictions. The authors show that if a model is miscalibrated in a certain way, there’s a simple tweak (a “perturbation”) that would make the loss better. Because training should already find these “easy improvements,” base LLMs (pretrained models) are expected to be calibrated—provided they can estimate how likely each concept is before they start writing out the full answer.
- They call this early estimate the model’s “intermediate B-confidence,” which is like the model knowing the chance it will end up answering “Paris” before it decides the exact wording.
Analogy: It’s like a weather forecaster who can estimate the chance of rain before writing the report. If they can do that well, and they’ve been trained to avoid easy mistakes, their stated probabilities should match reality over time.
What they found and why it matters
Here are the key findings, explained simply:
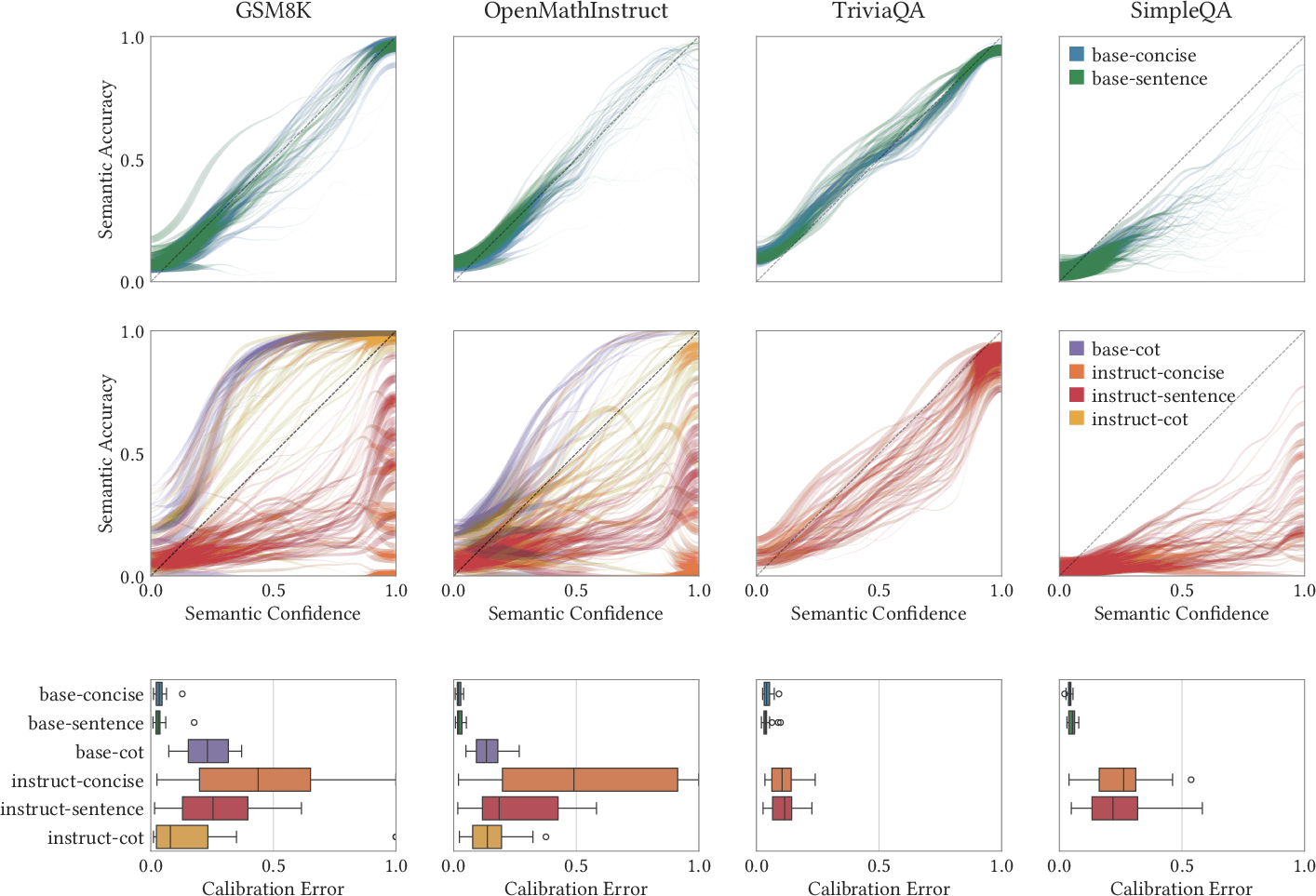
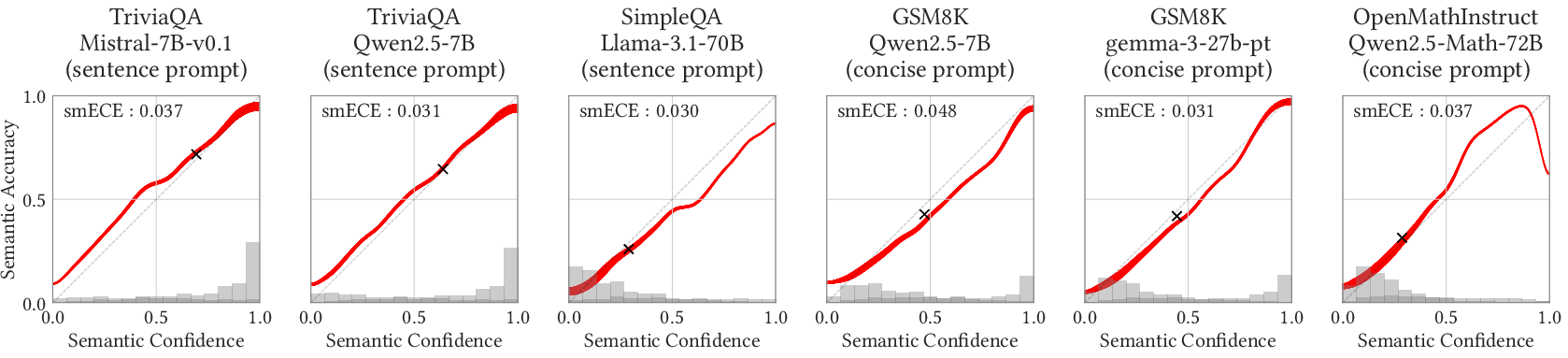
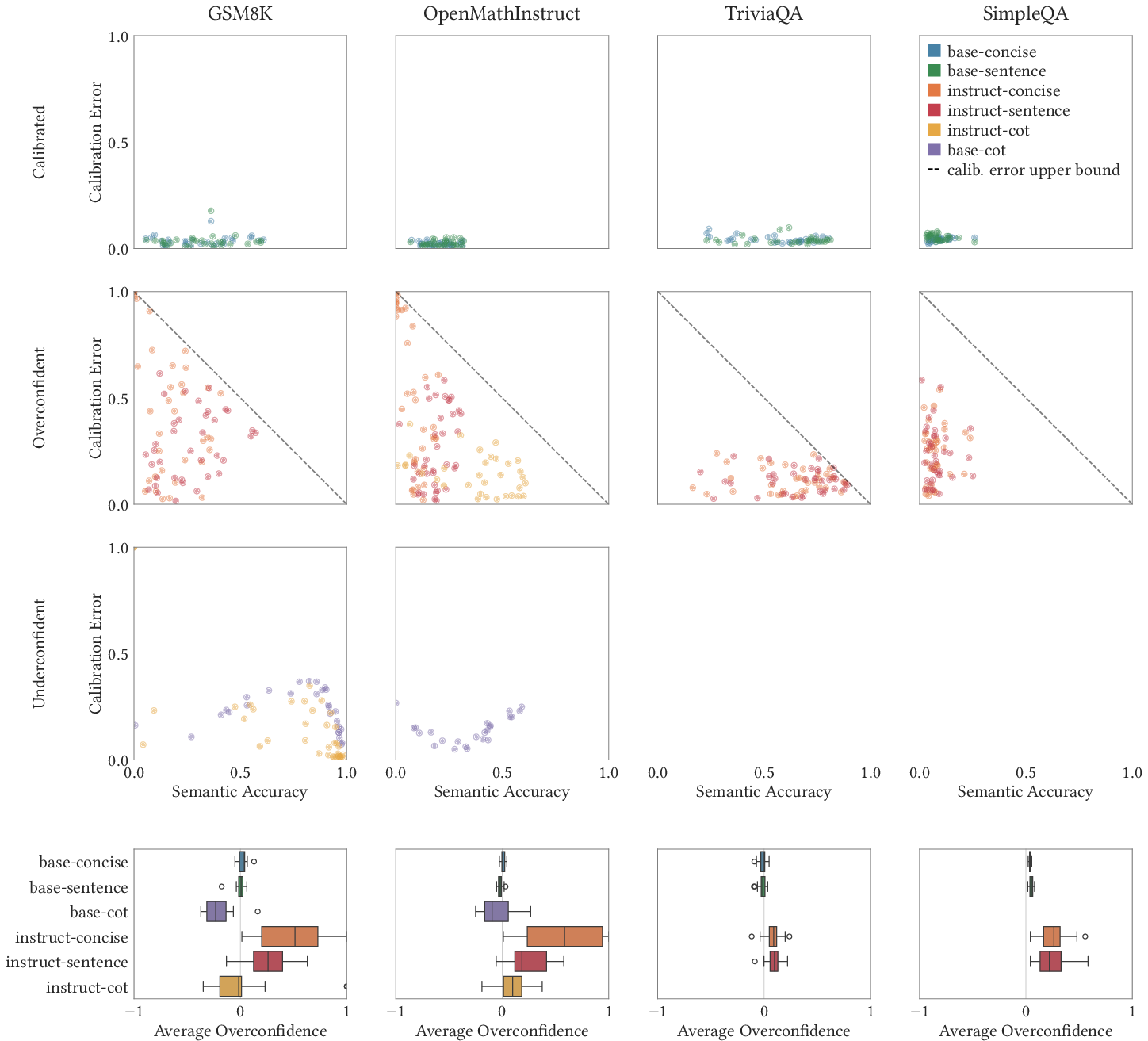
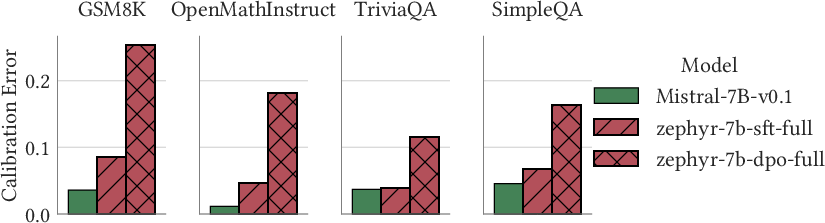
- Base LLMs (the raw models before extra instruction tuning) are often semantically well-calibrated on questions similar to their training data, especially when you ask for direct answers (a single word or a sentence).
- Chain-of-thought (CoT) often breaks calibration. CoT is when the model explains its reasoning step by step. This can help accuracy on hard problems, but it also means the model doesn’t “know” the final answer early on, so its confidence can be off.
- Instruction-tuned models (post-trained with methods like RLHF, DPO, or RLVR) are often less calibrated. These training methods change the model’s behavior at the sequence level in ways that don’t guarantee calibration.
- These patterns hold across many model families (Qwen, Gemini, Mistral, Llama) and sizes, and across several datasets (math problems and factual trivia).
Why this is important: If we can trust a model’s confidence to match its actual correctness rate, we can make better decisions about when to believe it, when to ask for more evidence, or when to escalate to a human. This makes LLMs safer and more useful.
What this could mean going forward (implications and impact)
- A practical way to measure uncertainty: Sampling multiple answers and collapsing them into concepts gives a principled, simple confidence measure you can trust—often without retraining the model.
- Better usage guidance:
- For calibrated confidence, prefer base models and ask for concise or sentence-style answers on questions similar to what the model was trained on.
- Be careful with chain-of-thought: it can improve accuracy on hard tasks but may make confidence less reliable.
- Post-training with certain methods (like RLHF/DPO/RLVR) can trade off calibration, so use with caution if trustworthy confidence is important.
- Design idea: If a model can quickly estimate “which concept it’s likely to answer” before generating text (and this estimate is easy for the model to learn), calibration will likely emerge naturally. Developers can add small adapters (like LoRA) to help the model make these estimates explicitly.
Key terms, briefly explained
- Semantic calibration: The model’s confidence about the meaning of its answer (not just the next word) matches how often it’s actually right.
- Collapsing function (B): A tool that turns different wordings into the same concept class (e.g., different ways to say “Paris” all count as “Paris”).
- Base LLM: A model trained only to predict the next token (word/subword), without extra instruction or preference tuning.
- Chain-of-thought (CoT): The model writes out its reasoning steps before the final answer. Helpful for accuracy on tough problems, but can hurt confidence honesty.
- In-distribution: Questions similar to what the model saw during training; the model is more likely to be calibrated there.
In short: The paper shows that even though LLMs are trained on tokens, they can end up calibrated on concepts—often “for free.” That makes a strong case for using sampling-based semantic confidence to understand and trust model answers, especially with base models and direct-answer prompts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Dependence on the collapsing function B
- How sensitive are calibration conclusions to the specific implementation of the semantic collapsing function B (e.g., auxiliary LLM prompt, extractor model, clustering heuristic, regex rules)?
- What is the error profile and inter-annotator agreement of B when implemented via an LLM vs. rule-based extractors vs. human adjudication?
- How do different choices of B that encode different semantic equivalence relations (synonyms, paraphrases, units, formatting) change calibration measurements?
- Estimation and sampling design
- What number of samples M is needed to reliably estimate the pushforward distribution B_x ∘ p_x and ECE within specified confidence bounds, as a function of K, task entropy, and model uncertainty?
- How do temperature, top-k/top-p, repetition penalty, and best-of-N decoding affect semantic calibration (both theoretically and empirically)? Is there a temperature-scaling analogue that calibrates semantics, not just token logits?
- Does deterministic decoding (e.g., T=0) produce meaningful semantic confidence signals under this framework, and if not, how can they be obtained?
- Scope and validity of the theoretical mechanism
- The central assumption that base LLMs are locally loss-optimal w.r.t. “easy” perturbations is not proven for autoregressive training; can we formalize learnability conditions that guarantee the assumed local optimality?
- The bridge from representational realizability (small circuits) to actual learnability with realistic optimizers (SGD/Adam) and parameterizations (Transformer + LoRA) remains unproven; can we give convergence guarantees or empirically validate with controlled interventions?
- The theory uses sequence-level cross-entropy and exponential tilting; how robust are the claims when training is strictly token-level next-token loss (without explicit sequence-level objectives)?
- Intermediate B-confidences vs. initial prediction
- The mechanism requires access to intermediate B-confidences g_i during generation, but experiments rely on a simplification to g_0 (pre-first-token). How much do calibration properties depend on the model’s ability to estimate g_i for i>0, especially in multi-step reasoning?
- Can we design probes that estimate g_i online during chain-of-thought and test whether calibration is restored when the model “knows” its final B-class mid-reasoning?
- Predictive testability via LoRA probes
- The paper suggests that if a small LoRA can learn to predict B_x ∘ p_x, calibration should hold, but does not report a systematic correlation study between LoRA-prediction quality and semantic calibration across tasks/models. Can this be quantified and validated as a practical diagnostic?
- Chain-of-thought (CoT) and restoring calibration
- While CoT is argued to break calibration, what interventions can restore it (e.g., training a head to predict B after T reasoning steps, multi-pass pipelines that estimate B_x ∘ p_x post-reasoning, or sequence-level proper losses aligned to final answers)?
- Is there a trade-off frontier between reasoning gains and semantic calibration, and can we characterize when calibration can be retained without sacrificing accuracy?
- Post-training effects and loss design
- The claim that RLHF/DPO/RLVR “often break calibration” is not fully quantified across algorithms, hyperparameters, and data; what specific post-training choices degrade vs. preserve calibration?
- Can sequence-level proper losses be practically implemented to enforce semantic calibration, and how do they compare (accuracy, compute, stability) to standard post-training methods?
- In-distribution vs. out-of-distribution
- The mechanism is expected to hold on “reasonably in-distribution” data; how does semantic calibration degrade under controlled domain shift (topic, style, language, temporal drift), and can we measure calibration as a function of distributional distance?
- Can we design OOD detectors or uncertainty-aware routing that leverage semantic confidence to maintain reliability under shift?
- Ground-truth and correctness definition
- For open-ended tasks, the ground-truth B_x(y) may be ambiguous or multi-valued; how do ambiguity, partial correctness, and equivalence-class granularity affect measured calibration?
- Can we extend the framework to graded correctness or ordinal/interval outcomes (e.g., numeric tolerance, units, equivalence under algebraic transformation)?
- Calibration granularity and metrics
- The empirical focus is confidence calibration (top-class) with SmoothECE; what about full-vector calibration, class-conditional calibration, adversarial/conditional calibration, or coverage–risk trade-offs under selective prediction?
- What is the metric sensitivity to binning/smoothing choices, and can we report confidence intervals or hypothesis tests for ECE differences?
- Few-shot context dependence
- Results use 5-shot prompts; how sensitive is semantic calibration to the number, order, and selection strategy of few-shot examples (including topic/difficulty matching)?
- Do system prompts, instruction style, and formatting (concise vs. sentence) causally affect calibration beyond stylistic changes to B?
- Model and data confounders
- The claim that base LLMs are “almost always calibrated” needs ablation over model architecture, tokenizer, context length, and pretraining corpus; can we disentangle model size from data/optimizer differences?
- How does data contamination/familiarity (seen vs. unseen questions) influence semantic calibration?
- Practical efficiency and deployment
- Sampling M=50 generations per query is expensive; what are cost–accuracy trade-offs, and can we derive principled stopping rules or adaptive sampling for stable confidence estimates?
- Can we approximate B_x ∘ p_x without sampling via amortized predictors, energy-based surrogates, or learned proposal distributions?
- Extensions to other settings
- Does semantic calibration emerge in multi-turn dialogue, tool use, code generation, multilingual tasks, and multimodal LLMs? How must B be adapted in these settings?
- Can the framework handle abstention/rejection classes, refusals, and safety-critical outputs where correctness is normative rather than factual?
- Edge cases and formal details
- The perturbation class W_B relies on argmax ties and non-differentiabilities; how are ties/smoothing handled theoretically and in practice?
- K can be large and instance-dependent; how does varying K across prompts affect both theory and estimation, and can we bound errors as K grows?
These gaps suggest concrete avenues: rigorous learnability analyses for the proposed mechanism; sensitivity and ablation studies over B, sampling, and prompts; interventions to restore calibration under CoT and post-training; and broadened evaluations across domains, decoding regimes, and distributions.
Practical Applications
Overview
This paper introduces and empirically validates a theoretically grounded mechanism by which semantic calibration (calibrated confidence about the semantic content of long-form LLM answers) can emerge “for free” from standard maximum-likelihood pretraining. The key operational recipe is to:
- Sample multiple generations at temperature ,
- Collapse each generation into a semantic class via a function (regex or an auxiliary LLM extractor),
- Treat the resulting empirical distribution over semantic classes as the model’s prediction,
- Use the argmax class and its probability as the semantic prediction and confidence,
- Evaluate and use these calibrated confidences in downstream decisions.
The theory predicts calibration primarily for base (pretrained-only) models, producing direct answers (not chain-of-thought), on reasonably in-distribution tasks. It also predicts that post-training methods that do not optimize a sequence-level proper loss (e.g., RLHF/DPO/RLVR) and chain-of-thought reasoning often break calibration.
Below are practical applications that leverage these findings.
Immediate Applications
The following applications can be deployed now using the paper’s methods (sampling-based semantic confidence via a collapsing function ), with minimal additional research or engineering.
- Semantic Confidence Wrapper for LLM APIs
- Description: A drop-in middleware that returns a calibrated confidence score alongside the LLM’s answer by sampling multiple generations (e.g., M=20–50), applying to collapse answers, and using the empirical distribution to compute confidence and majority-vote prediction.
- Sectors: software, customer support, search/Q&A, education, healthcare, finance, legal.
- Tools/Products/Workflows: “Semantic Confidence API,” majority-vote answer with confidence, reliability diagrams (SmoothECE), auxiliary LLM–based semantic collapser.
- Assumptions/Dependencies: base LLM; direct (concise/sentence) answers; in-distribution queries; temperature ; high-quality collapsing function ; sufficient sampling budget and latency tolerance.
- Calibration-Aware Decision Gating
- Description: Use semantic confidence thresholds to decide whether to auto-accept an answer, ask for clarification, switch to retrieval, or escalate to a human.
- Sectors: healthcare (clinical QA support), finance (compliance checks), legal (draft review), customer support (agent handoff), software (code generation acceptance).
- Tools/Products/Workflows: confidence-based routing rules; “Are you sure?” prompts; fallback pipelines; human-in-the-loop triage.
- Assumptions/Dependencies: calibrated semantic confidence (via sampling + ); clear thresholding policy aligned with risk; base LLM performance adequate on task; acceptance criteria defined by domain experts.
- Prompt/Model Selection to Preserve Calibration
- Description: Prefer concise/sentence-style prompts and base models when calibrated uncertainty is required. Avoid chain-of-thought and models post-trained with RLHF/DPO/RLVR for calibration-critical tasks.
- Sectors: enterprise AI procurement, platform engineering, ML Ops.
- Tools/Products/Workflows: prompt libraries tagged by “calibration-safe”; model governance policies; A/B testing with reliability diagrams.
- Assumptions/Dependencies: access to base model variants; evaluation on target task distribution; SmoothECE monitoring in CI.
- Reliability Diagnostics and Monitoring
- Description: Add SmoothECE-based reliability diagrams to evaluation dashboards; track calibration drift across datasets, prompts, and model versions.
- Sectors: ML Ops, QA benchmarking, compliance.
- Tools/Products/Workflows: “Calibration Monitor” dashboard; nightly runs on representative test suites; alerts on calibration regressions.
- Assumptions/Dependencies: curated evaluation sets; reproducible sampling; stable collapsing; storage/telemetry for confidence histograms.
- Hallucination and Risk Flagging via Low Confidence
- Description: Treat low semantic confidence as a strong signal for potential hallucination or weak generalization; degrade capabilities or require retrieval/citations.
- Sectors: search/Q&A, content moderation, safety.
- Tools/Products/Workflows: confidence-triggered retrieval; citation requirement; rate-limiting or refusal for low-confidence claims; guardrail integration.
- Assumptions/Dependencies: in-distribution tasks; calibrated confidence available; clear operational playbooks for low-confidence outputs.
- Active Learning and Data Curation
- Description: Select low-confidence examples for human labeling to improve future SFT/pretraining or to build new domain datasets.
- Sectors: ML data ops, enterprise domain adaptation.
- Tools/Products/Workflows: sampling-based confidence ranking; labeling queues; curriculum design from confidence strata.
- Assumptions/Dependencies: stable collapsing; budget for human annotation; alignment between target domain and base model’s training distribution.
- Accuracy Improvement with Majority Vote (Self-Consistency)
- Description: Use majority-vote over semantic classes to boost accuracy while retaining calibrated confidence.
- Sectors: math/factual QA, coding assistants, tutoring.
- Tools/Products/Workflows: batched sampling; semantic aggregation; accuracy-confidence trade-off controls.
- Assumptions/Dependencies: compute overhead acceptable; large enough (e.g., 20–50); reliably canonicalizes answers.
- Trustworthy UX for End Users
- Description: Display confidence bars and concise explanations about certainty; adapt UX to provide hints, alternative answers, or source links when confidence is low.
- Sectors: education (tutoring UIs), consumer assistants, enterprise productivity tools.
- Tools/Products/Workflows: confidence visualization; adaptive follow-ups; “check sources” button gated by confidence.
- Assumptions/Dependencies: user research for thresholds; calibrated confidence integrated; latency budget for sampling.
- Quick Feasibility Check with LoRA Probes
- Description: Train a small LoRA to predict (the model’s own semantic answer distribution) from the question alone to gauge whether a task will be semantically calibrated before full deployment.
- Sectors: ML research/engineering, platform teams.
- Tools/Products/Workflows: lightweight LoRA adapters; KL-loss probes; task triage by “model knows its own answer distribution” criterion.
- Assumptions/Dependencies: labeled -collapsed samples; LoRA training pipeline; proxy for target domain; compute for quick finetunes.
Long-Term Applications
These applications require further research, scaling, or development to become robust and broadly deployable.
- Calibration-Preserving Post-Training Methods
- Description: Design RLHF/DPO/RLVR variants or sequence-level proper-loss post-training that maintain -local loss optimality and semantic calibration.
- Sectors: foundation model training, enterprise model customization.
- Tools/Products/Workflows: new objective functions; calibration-aware reward models; validation suites that include SmoothECE.
- Assumptions/Dependencies: theoretical and empirical work on proper losses at sequence level; access to base models and training pipelines.
- Calibration-Compatible Chain-of-Thought (CoT)
- Description: Architectures or inference strategies that preserve calibration during reasoning (e.g., “fast confidence first” estimates, intermediate confidence tracking, or dual-pass reasoning).
- Sectors: math/logic assistants, scientific workflows, planning agents.
- Tools/Products/Workflows: early confidence heads; reasoning schedules that update confidence; selective “think then answer” with calibrated gates.
- Assumptions/Dependencies: new training signals for intermediate -confidences; model changes to expose/learn these signals; evaluation benchmarks tailored to CoT.
- Low-Cost Confidence Without Sampling
- Description: Train a dedicated head or small student model to predict -class distributions directly (approximate ), removing the need for many samples.
- Sectors: on-device AI, latency-constrained systems.
- Tools/Products/Workflows: distillation from sampling-based teacher; classification heads; calibration adjustment layers.
- Assumptions/Dependencies: robust teacher/student training; domain stability; careful calibration transfer without overconfidence.
- Robust, Domain-Specific Semantic Collapsers ( Functions)
- Description: Standardized, auditable functions that canonicalize answers across domains (e.g., healthcare codes, legal references, financial instruments).
- Sectors: healthcare, legal, finance, enterprise knowledge management.
- Tools/Products/Workflows: extractor libraries; schema/ontology alignment; validation sets for accuracy.
- Assumptions/Dependencies: high-quality domain ontologies; strong auxiliary models; governance for updates and drift.
- Regulatory Standards and Audits for Calibrated AI
- Description: Policies that mandate calibrated confidence reporting, reliability diagrams, and escalation thresholds in high-stakes deployments.
- Sectors: healthcare, finance, public policy, safety-critical industries.
- Tools/Products/Workflows: audit templates; compliance checklists; calibration SLAs.
- Assumptions/Dependencies: consensus on metrics (e.g., SmoothECE); accepted testing protocols; regulator and industry buy-in.
- Calibration-Aware Multi-Agent Orchestration
- Description: Route tasks among agents/models/prompts based on calibrated confidence to optimize cost, accuracy, and risk.
- Sectors: enterprise automation, customer support platforms, MOE-style systems.
- Tools/Products/Workflows: orchestration engines that consume confidence signals; mixture-of-prompts; fallback strategies.
- Assumptions/Dependencies: reliable confidence across components; consistent collapsing; monitoring for cross-agent calibration.
- Drift Detection and OOD Identification via Calibration Breaks
- Description: Use changes in calibration (e.g., rising ECE, confidence/accuracy mismatch) to detect dataset shift and trigger adaptation.
- Sectors: ML Ops, safety monitoring, production QA systems.
- Tools/Products/Workflows: drift dashboards; automatic retraining triggers; domain shift alarms.
- Assumptions/Dependencies: stable baselines; periodic evaluation; clear action plans on drift.
- Benchmarks and Libraries for Semantic Calibration
- Description: Open-source toolkits to compute semantic confidence, collapse long-form outputs, and produce reliability diagrams across varied tasks.
- Sectors: academia, open-source ML, industry evaluation teams.
- Tools/Products/Workflows: standardized implementations; sampling/evaluation harnesses; SmoothECE computation utilities.
- Assumptions/Dependencies: community governance; dataset licensing; shared protocols for prompts and temperatures.
- Safety Gating in Robotics and Autonomous Systems
- Description: For language-conditioned control, use calibrated confidence to gate autonomous actions or require human supervision.
- Sectors: robotics, industrial automation.
- Tools/Products/Workflows: action authorization thresholds; human override triggers; task decomposition with confidence-aware steps.
- Assumptions/Dependencies: reliable semantic collapsing for command domains; tight latency budgets; integration with control stacks.
- Pedagogical Design in AI Tutoring
- Description: Use calibrated confidence to tailor hints vs. direct answers, scaffold difficulty, and support metacognitive learning (“knowing what you don’t know”).
- Sectors: education technology.
- Tools/Products/Workflows: confidence-driven lesson plans; adaptive assessments; explanation modes tied to certainty.
- Assumptions/Dependencies: validated for educational domains; user studies on comprehension/trust; calibration maintained across curricula.
Notes on Feasibility and Dependencies
- The strongest guarantees apply to base LLMs trained with sequence-level proper loss (standard cross-entropy pretraining/SFT), using direct (concise/sentence) answers on reasonably in-distribution queries.
- Chain-of-thought reasoning and common post-training methods (RLHF, DPO, RLVR) often degrade calibration; deploying calibration-critical features in those settings will require additional research or mitigations.
- The semantic collapsing function is pivotal. Robustness depends on high-quality extraction, normalization, and clustering (regex for math; auxiliary LLM for open-ended tasks).
- Sampling introduces latency/cost; choose (e.g., 20–50) based on risk/throughput. Temperature is recommended by the paper’s experiments; deviations may affect calibration.
- LoRA probes to predict provide a practical test for whether a task is likely calibrated before investing in full rollouts.
Glossary
- arithmetic circuit: A computational model that uses arithmetic operations arranged in layers with bounded depth and width. "Specifically, an arithmetic circuit of constant depth and width."
- argmax: An operator that returns the index of the largest value in a set. "$k<sup>\star</sup> \gets \argmax_{k \in [K]}c_k ."</li> <li><strong>autoregressive LLM</strong>: A model that generates tokens sequentially, each conditioned on the previous context. "let $p_\theta(z \mid x)D$ with cross-entropy loss."</li> <li><strong>base LLM</strong>: A LLM that is only pre-trained (without instruction tuning or RL-based post-training). "base LLMs, which are only pre-trained with the maximum likelihood loss, are typically next-token-calibrated"</li> <li><strong>B-confidence-calibration</strong>: Calibration of predicted confidences after collapsing outputs via a function $B$. "The model $p_\thetaBD$"</li> <li><strong>chain-of-thought (CoT)</strong>: A prompting technique that elicits step-by-step reasoning before producing an answer. "Chain-of-thought reasoning typically breaks calibration."</li> <li><strong>collapsing function</strong>: A post-processing function that maps generated text to a finite set of classes. "The core of our approach is a collapsing function $B$"
- confidence calibration: The property that predicted confidence equals empirical accuracy for the predicted class. "We will focus primarily on confidence calibration"
- convex duality: A mathematical framework relating optimization and loss functions, used to select appropriate perturbations. "depends on the loss function via convex duality"
- cross-entropy loss: A standard log-loss objective for training probabilistic models, here at the sequence level. "We consider the sequence-level cross-entropy loss"
- DPO: Direct Preference Optimization, an RL-style post-training method that can affect calibration. "post-trained with RLHF, DPO, or RLVR"
- Empirical Semantic Confidence: A sampling-based confidence measure over semantic answers. "This definition coincides with \citet{lamb2025semantic}'s definition of ``Empirical Semantic Confidence''"
- ERM: Empirical Risk Minimization; training by minimizing average loss over data. "then ERM over a family of slightly larger models yields local loss optimality"
- exponential tilting: A method of perturbing a distribution by adjusting log-probabilities before re-normalization. "known as exponential tilting"
- KL loss: The Kullback–Leibler divergence used as a training objective or probe. "estimated as a standard KL loss"
- LLM-induced semantic classifier: A classifier formed by collapsing generated outputs into semantic classes. "LLM-induced semantic classifier (dashed box)"
- LoRA: Low-Rank Adaptation; an efficient fine-tuning technique to teach new behaviors or probes. "for example, the model could be LoRA-adapted to perform it."
- local loss optimality: A condition where no simple post-processing perturbation can reduce the model’s loss. "connects the statistical property of calibration to the optimization property of local loss optimality."
- maximum likelihood loss: The training objective that maximizes the probability of observed data. "only pre-trained with the maximum likelihood loss"
- perturbation function: A function that specifies how to adjust a model’s output distribution given the prompt and current distribution. "and a perturbation function "
- perturbation operator: An operator that constructs a perturbed distribution from a base distribution and a measure. "Perturbation operator"
- probability simplex: The set of all categorical distributions over a finite number of classes. "we use the shorthand for the probability simplex over the classes."
- proper loss: A loss function that encourages truthful probability estimates and supports calibration. "Models trained with anything but a sequence-level proper loss are unlikely to be calibrated."
- push-forward distribution: The distribution over classes obtained by mapping outputs through a function. "pushing-forward the LLM's output distribution via the function ."
- reliability diagram: A plot that compares predicted confidence to empirical accuracy across bins. "Reliability diagrams demonstrating semantic confidence-calibration"
- RLHF: Reinforcement Learning from Human Feedback; a post-training method that can alter calibration. "post-trained with RLHF, DPO, or RLVR"
- RLVR: A reinforcement learning method (e.g., with verifiable rewards) used in post-training. "post-trained with RLHF, DPO, or RLVR"
- self-consistency: A technique that samples multiple generations and aggregates (e.g., by majority vote) to improve accuracy. "Taking majority vote is identical to the ``self-consistency'' method proposed by \citet{wang2023selfconsistency}"
- semantic calibration: Calibration of confidences for predictions over semantic classes derived from outputs. "Semantic calibration refers to calibration of an LLM-induced semantic classifier"
- semantic collapsing function: A function that groups different strings into the same semantic class. "Of particular interest are semantic collapsing functions"
- semantic confidence: The probability assigned to the most likely semantic class after collapsing. "semantic confidence as the probability of the most-likely semantic class"
- semantic entropy: An entropy-based measure of uncertainty over semantic answers. "semantic entropy of \citet{farquhar2024detecting}"
- signed measure: A measure that can take positive or negative values, used in defining perturbations. "a signed measure "
- SmoothECE: A smoothed expected calibration error metric for assessing calibration quality. "Calibration error measured with SmoothECE (smECE)"
- softmax: A normalization function that converts logits into probabilities. ""
- weighted calibration: A generalized calibration notion that incorporates weights or conditions. "based on the language of weighted calibration developed in \citet{gopalan2024computationally}"
Collections
Sign up for free to add this paper to one or more collections.