Future Is Unevenly Distributed: Forecasting Ability of LLMs Depends on What We're Asking
Abstract: LLMs demonstrate partial forecasting competence across social, political, and economic events. Yet, their predictive ability varies sharply with domain structure and prompt framing. We investigate how forecasting performance varies with different model families on real-world questions about events that happened beyond the model cutoff date. We analyze how context, question type, and external knowledge affect accuracy and calibration, and how adding factual news context modifies belief formation and failure modes. Our results show that forecasting ability is highly variable as it depends on what, and how, we ask.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how good AI chatbots (called LLMs, or LLMs) are at predicting real-world events, like election results, sports games, or stock market moves. The big idea is that their forecasting ability is uneven: it changes a lot depending on the type of question, how the question is asked, and whether you give the model recent news to read first.
What were the researchers trying to find out?
The researchers wanted to understand:
- Which kinds of real-world questions LLMs predict well, and which ones they struggle with.
- Whether adding news articles (written before the question was asked) helps or hurts the models’ predictions.
- How confident the models are, and whether their confidence matches reality.
- The common ways these models go wrong when making predictions.
How did they do the study?
They started by collecting about 10,000 yes/no prediction questions from online “prediction markets.” These are websites where people bet on the chances of future events, like Polymarket or Metaculus. They filtered out the silly or personal questions and ended up with 392 solid, checkable questions across six categories: Politics, Entertainment, Sports, Technology, Finance, and Geopolitics.
Then they picked a balanced set of 150 questions (same number from each category) and tested four well-known AI models: GPT-5, GPT-4.1, DeepSeek-R1, and Claude 3.7 Sonnet. For each question, every model had to answer “YES” or “NO” and give a confidence number between 0 and 1 (like 0.75 means 75% sure). The models did not use the internet or tools, except in a second test where the researchers added up to ten short news snippets published before the question date.
To judge performance, they used three simple ideas:
What is “accuracy”?
Think of accuracy like a score in a quiz: how many questions did the model get right? If it said “YES” and the event happened, that’s correct.
What is “Brier score”?
Imagine you’re guessing the chance of rain and you say 0.90 (90%). If it doesn’t rain, you were confidently wrong, and you get a bigger penalty. The Brier score is a number that punishes being confidently wrong and rewards being confidently right. Lower is better.
What is “Expected Calibration Error (ECE)”?
Calibration asks: “When you say you’re 80% sure, are you actually right about 8 out of 10 times?” ECE measures how well confidence matches reality. Lower ECE means the model’s confidence is realistic.
What did they find?
Overall, the models can sometimes predict well, but their success depends heavily on the topic and the way the question is framed.
- In structured areas like Geopolitics and Politics (where rules, history, and processes matter), GPT-5 and Claude 3.7 were well-calibrated and often accurate.
- In noisier, fast-changing areas like Entertainment and Technology, models were less well-calibrated, and some were overconfident.
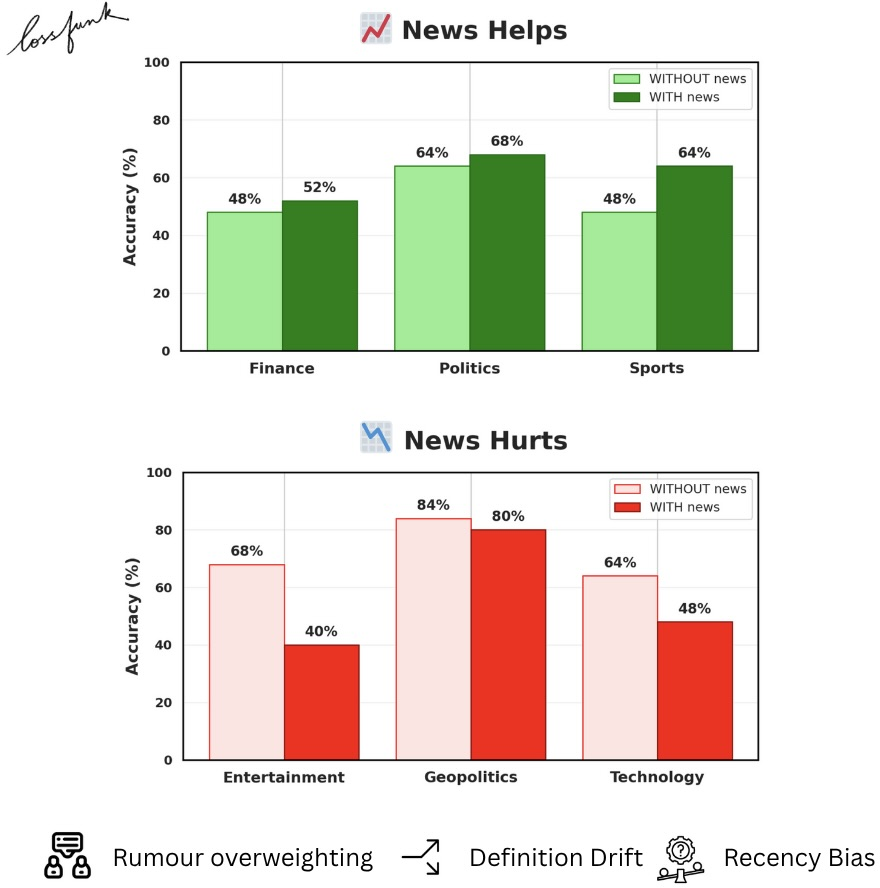
- Adding news helped in some categories (Finance and Sports) but made things worse in others (Entertainment and Technology). In short: more information doesn’t always mean better predictions.
When did news help or hurt?
- Helped: Finance and Sports often benefited from timely context (e.g., recent earnings hints or player injuries).
- Hurt: Entertainment and Technology sometimes got worse because the models latched onto hype or rumors, or misunderstood what the question really meant.
Common ways models went wrong
Here are three failure patterns the researchers saw often when news was included:
- Recency bias: The model got overly swayed by the latest headlines, ignoring steady long-term patterns. It might turn a cautious, probably-correct answer into an overconfident wrong one just because the last few articles sounded exciting.
- Rumor overweighting: The model treated speculation in news as if it were already true. For example, “Tariffs likely to rise” is not the same as “Tariffs have risen,” but the model sometimes acted as if it was decided.
- Definition drift: The model misunderstood what the question’s key term meant after reading the news. For instance, if “MATS” is an academic program, but the news mostly talks about a trucking show with the same acronym, the model might switch meanings and answer the wrong problem.
They also noticed one model (DeepSeek-R1) didn’t explain its reasoning even when asked, making it harder to diagnose mistakes.
Why is this important?
If AI is going to help people make decisions—about money, policy, or safety—it needs to be:
- Good at predicting future outcomes, and
- Honest about how sure it is.
This paper shows that today’s models are not consistently strong forecasters. They can be decent in some areas, but they’re sensitive to how questions are written and to the type of information they’re given. Sometimes, adding news makes them worse because they chase hype, misunderstand definitions, or get fooled by rumors.
What does this mean for the future?
- Better benchmarks are needed: We should test models in ways that separate “remembering facts” from “reasoning about the future.”
- Careful prompt design matters: How you ask the question can change the prediction. Clear definitions and timeframes help.
- Smarter use of context: Not all news helps. Designers should make systems that filter noisy or speculative sources and keep definitions consistent.
- Human-AI teamwork: Combining model suggestions with human judgment (especially experts who can spot hype or ambiguity) could lead to stronger forecasts.
Bottom line: AI can help forecast the future, but not evenly. What you ask—and how you ask it—changes the outcome a lot.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Benchmark representativeness and power: The evaluation uses only 150 questions (25 per category) from a 392-item corpus; expand to the full set and provide per-subcategory analyses to improve statistical power and generalizability.
- Absence of human and market baselines: No comparison to contemporaneous crowd forecasts (e.g., market prices at creation time), expert forecasters, or simple baselines; add these to contextualize LLM performance.
- No statistical significance or uncertainty reporting: Provide confidence intervals, bootstrap resampling, and hypothesis tests for accuracy, Brier, and ECE differences (with and without news). Include reliability diagrams and variance estimates.
- ECE specification incomplete: The number and edges of calibration bins (M) are unspecified; define binning choices, test sensitivity to binning, and report reliability curves per model and category.
- Ambiguity and resolution criteria missing from prompts: Models received only the question string and creation date, not the market’s full description or resolution rules; include these to reduce definition drift and measure its impact quantitatively.
- LLM-as-judge filtering/classification bias: Category assignment and relevance filtering by Gemini 2.5 Flash may introduce selection bias; validate with human annotation (e.g., dual-annotator agreement, Cohen’s kappa) and release guidelines for reproducibility.
- Time horizon effects unexplored: The relationship between lead time (creation-to-resolution gap) and model performance is not analyzed; stratify by horizon to test whether short-term questions benefit more from news context.
- Domain structure granularity: Results are at coarse category level; perform subcategory-level and region-level analyses (e.g., geopolitics by region) to identify finer-grained performance patterns.
- Prompt framing ablations absent: Only a single multi-step “superforecaster” prompt was used at temperature 0.0; test variations in framing, reasoning steps, compact vs verbose prompts, and visible vs hidden chain-of-thought to quantify framing sensitivity.
- Model version and cutoff verification: The dataset was chosen to be “post-cutoff,” but per-model training cutoffs are not verified; document model versions/cutoffs and test for potential contamination (e.g., by asking for sources or using post-cutoff probe questions).
- News retrieval quality and leakage controls: Exa-based retrieval may include rumor/speculation and subtle leakage; quantify source credibility, deduplicate snippets, audit leakage systematically, and measure the impact of snippet count and retrieval ranking.
- Causal attribution of news effects: The “news helps/hurts” claim is observational; run controlled interventions (e.g., add/remove specific snippets, swap rumor with confirmed reports) to isolate recency bias, rumor overweighting, and noise amplification.
- Failure mode quantification: Rumor overweighting, recency bias, and definition drift are presented via case studies; create labeled datasets to estimate their prevalence and correlate them with performance changes across domains.
- Market resolution integrity: Prediction markets sometimes have non-standard or contentious resolutions; audit resolution quality and exclude or tag problematic markets to avoid training on inconsistent ground truth.
- Metric coverage limited: Beyond accuracy, Brier, and ECE, include proper scoring rules (log score), Brier decomposition (reliability, resolution, uncertainty), and sharpness analyses; consider post-hoc calibration (isotonic/Platt scaling).
- Ensemble methods unexplored: Test whether ensembles (across models or prompts) improve accuracy and calibration versus single-model forecasts.
- Tool-augmented settings excluded: Evaluate retrieval-augmented or tool-using agents (e.g., fact-checkers, rumor detectors, summarizers) to test whether structured pipelines mitigate failure modes without overwhelming context.
- Token budget and prompt length effects: Analyze whether adding many snippets causes token saturation or distractor effects; compare raw snippets vs summarized context and measure trade-offs.
- Disambiguation pre-steps: Investigate whether an explicit entity/acronym disambiguation stage (using market descriptions) reduces definition drift and improves accuracy.
- Selective context inclusion: Build a predictive model of “context utility” (which questions benefit from news) and test gating policies that add context only when expected to help.
- Rumor detection integration: Incorporate veracity scoring or source reliability signals in prompts or retrieval (e.g., deprioritize speculative headlines) and measure its impact on flipping correct to incorrect answers.
- Calibration training and post-processing: Explore calibration techniques (temperature scaling, isotonic regression, RLHF variants focused on probability estimation) and report improvements in ECE across domains.
- Continuous/numeric forecasting: Extend beyond binary yes/no to numeric targets (e.g., index levels, macro prints) and evaluate proper continuous scoring rules and calibration for regression tasks.
- Chain-of-thought visibility effects: DeepSeek-R1 suppressed reasoning traces despite prompting; study how visible vs hidden reasoning and reasoning style affect forecast quality and calibration.
- Difficulty-controlled evaluation: Distinguish domain differences from dataset difficulty by creating matched, difficulty-controlled subsets or semi-synthetic questions to test whether structure vs prior knowledge drives performance.
- Priors vs likelihoods (Bayesian prompting): Test prompts that explicitly separate prior beliefs (historical base rates) from likelihood updates (news) to mitigate recency bias and quantify how priors should be weighted.
- Reproducibility artifacts: Release code, prompts, retrieval queries, model identifiers, seeds, and the curated dataset (with metadata) to enable replication and extensions by other researchers.
- Source bias and fairness: Audit whether forecasts vary by region, outlet type, or topic due to retrieval/source biases; add diverse, high-quality sources and measure fairness across geopolitical and socio-economic contexts.
- Temporal generalization: Track performance longitudinally with streaming updates, evaluating whether models maintain calibration and accuracy over time rather than single-shot snapshots.
Practical Applications
Practical Applications Derived from the Paper’s Findings
Below are actionable, real-world applications that leverage the paper’s insights into LLM forecasting performance, failure modes, and evaluation methodology. Applications are grouped by deployment timeline and annotated with sectors, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These use cases can be deployed with current models and infrastructure, using the paper’s prompts, evaluation metrics, and retrieval hygiene practices.
- Domain-aware model routing and guardrails for forecasting
- Sectors: finance, geopolitics/policy, enterprise analytics
- What: Route questions by category to the model families that exhibited better calibration; prefer GPT-5/Claude in structured domains (Geopolitics, Politics), add caution in Entertainment/Technology when augmenting with news.
- Tools/workflows: model router, domain-specific prompt presets, calibration dashboards
- Assumptions/Dependencies: Access to multiple LLM APIs; observed performance generalizes across adjacent tasks and time periods.
- Context hygiene pipeline for retrieval-augmented forecasting
- Sectors: software, media, finance, research
- What: Enforce strict time-bounded retrieval (e.g., via Exa), strip post-cutoff leakage, de-duplicate snippets, and tag sources by credibility to reduce rumour overweighting.
- Tools/workflows:
Context Hygienemicroservice, publication-date validators, credibility scorer - Assumptions/Dependencies: Reliable timestamp metadata; robust retrieval APIs; organizational agreement on credibility heuristics.
- Two-pass forecaster workflow (no-news vs news-augmented) with divergence flags
- Sectors: finance trading, policy analysis, enterprise risk
- What: Run both the base forecasting prompt and the news-augmented version; flag large deltas in answer/confidence as potential recency bias or rumour-driven shifts; escalate for human review.
- Tools/workflows:
Delta Monitorto compare probabilities and explanations; human-in-the-loop escalation - Assumptions/Dependencies: Ability to run multiple inference passes; staff or automated triage for flagged items; latency/cost budgets.
- Calibration monitoring (Brier, ECE) and model evaluation by category
- Sectors: quant funds, enterprise decision-support, platform governance
- What: Track accuracy, Brier score, and ECE by domain over time; gate decisions or capital deployment based on calibration thresholds.
- Tools/workflows:
Calibration Monitordashboards; alerts on ECE drift; weekly scorecards - Assumptions/Dependencies: Reliable ground-truth resolution data; systematic logging of predictions and outcomes.
- Acronym/entity disambiguation pre-check to prevent definition drift
- Sectors: education, enterprise analytics, research support
- What: Run a lightweight NER/acronym resolver and category classifier prior to forecasting; confirm intended entity/program and adjust retrieval terms.
- Tools/workflows:
Definition Sentinel(NER + acronym resolver), category classifier (LLM-as-a-Judge) from the paper’s prompts - Assumptions/Dependencies: Good coverage of domain lexicons; integration into prompt-building workflow.
- Rumour detection and citation scoring on retrieved news
- Sectors: media validation, policy analysis, corporate communications
- What: Score snippets for verification status (e.g., official announcements vs speculative headlines), down-weight unverified claims during aggregation.
- Tools/workflows:
Rumor Shieldclassifier; source-type weighting; aggregation rules in prompt scaffolding - Assumptions/Dependencies: Labeled datasets or heuristics for rumor classification; editorial standards for weighting.
- Prompt framing toolkit modeled on superforecaster steps
- Sectors: forecasting platforms, analyst teams, education
- What: Adopt the paper’s core forecasting prompt that structures reasoning (rephrase > yes/no reasons > considerations > probability > calibration > final ans/conf).
- Tools/workflows:
Prompt Librarywith domain variants; template governance - Assumptions/Dependencies: Stable behavior across model updates; token budget and low-temperature sampling feasible.
- Model audit: enforce reasoning trace capture and logging
- Sectors: AI governance, compliance, software engineering
- What: Detect models that skip rationales (e.g., DeepSeek-R1 in this study); require minimal explanation fields for auditability and post-hoc error analysis.
- Tools/workflows:
Reasoning Trace Auditor; logging/telemetry hooks; compliance checks - Assumptions/Dependencies: Vendor support for structured outputs; organizational policies requiring audit trails.
- Question filtering for prediction platforms using LLM-as-a-Judge
- Sectors: forecasting markets, enterprise decision forums
- What: Use the paper’s relevance and category judge prompts to exclude hyper-localized or non-event questions and curate forecastable items.
- Tools/workflows:
Forecast Question Filter; volume/liquidity heuristics - Assumptions/Dependencies: Tolerance for automated moderation; category taxonomy alignment with platform needs.
- Domain-specific context toggles based on observed news effects
- Sectors: prediction products, analyst tools
- What: Configure retrieval augmentation by domain (e.g., enable news for Finance/Sports; caution or stricter filters for Entertainment/Technology).
- Tools/workflows:
Domain Context Policyengine; per-category retrieval profiles - Assumptions/Dependencies: Effects replicate beyond the evaluation set; dynamic policies can be updated as monitoring indicates.
Long-Term Applications
These use cases need additional research, scaling, or productization to reach production-grade reliability.
- Specialized forecasting LLMs trained for temporal reasoning and retrieval alignment
- Sectors: AI research, forecasting platforms
- What: Fine-tune models on curated temporal datasets, integrate retrieval-aware training to mitigate recency bias, rumour overweighting, and definition drift.
- Tools/workflows: temporal RLHF/RLAIF pipelines; retrieval-in-the-loop training
- Assumptions/Dependencies: Access to high-quality, time-stamped corpora; evaluation benchmarks; compute budgets.
- Hybrid human–AI forecaster teams with calibrated aggregation
- Sectors: finance, public policy, national security
- What: Combine calibrated LLM forecasts with expert forecasters; aggregate via weighting schemes informed by Brier/ECE and domain performance.
- Tools/workflows: ensemble aggregator; expert feedback loops; performance-based weights
- Assumptions/Dependencies: Organizational buy-in; clear governance and accountability; data privacy/security.
- Regulatory and procurement standards for AI forecasting in high-stakes decisions
- Sectors: government, regulated industries (finance, healthcare)
- What: Require reporting of calibration metrics (ECE/Brier), documented failure-mode mitigations, and two-pass context checks before policy or capital allocation.
- Tools/workflows: audit templates; compliance attestations; certification processes
- Assumptions/Dependencies: Multi-stakeholder consensus; enforcement mechanisms; alignment with existing risk frameworks.
- Autonomous market-participation agents with context hygiene and failure-mode detectors
- Sectors: trading, supply chain risk, energy markets
- What: Build agents that trade or hedge based on forecasts, guarded by
Rumor Shield,Definition Sentinel, andDelta Monitor, and shut off or de-risk on divergence. - Tools/workflows: strategy gates; kill-switches; live calibration monitors
- Assumptions/Dependencies: Market access permissions; robust backtesting; regulatory compliance.
- Dynamic model routing and adaptive context weighting based on live calibration
- Sectors: enterprise decision platforms, analytics SaaS
- What: Automatically adjust which model and how much news context to use per domain based on rolling ECE/Brier; learn policies to minimize failure modes.
- Tools/workflows:
Context Policy Learner; online evaluation infrastructure - Assumptions/Dependencies: Sufficient volume of resolved events; safe online learning protocols.
- Standardized forecasting benchmarks and datasets with temporal purity
- Sectors: academia, standards bodies, open-source community
- What: Open, time-bounded corpora with leakage-controlled retrieval; category-balanced sets; failure-mode annotations.
- Tools/workflows: dataset curation pipelines; reproducible leaderboards
- Assumptions/Dependencies: Licensing and publisher cooperation; ongoing maintenance.
- Education and training programs on prompt framing and bias mitigation
- Sectors: education, corporate L&D
- What: Train analysts and students to structure questions, recognize domain-specific pitfalls, and operate two-pass and calibration-aware workflows.
- Tools/workflows: curriculum; sandbox platforms; case libraries (recency bias, rumour, definition drift)
- Assumptions/Dependencies: Institutional adoption; pedagogical resources.
- Meta-models for failure-mode prediction and explanation
- Sectors: AI safety, tooling, research
- What: Train discriminators to predict when adding news will help/hurt, flag likely acronym drift, and quantify rumour susceptibility, guiding retrieval and weighting.
- Tools/workflows: failure-mode classifiers; explanation generators; confidence gating
- Assumptions/Dependencies: Labeled failure-mode data; generalization across domains and models.
- Enterprise “Forecaster Copilot” products with certification
- Sectors: software, consulting, risk management
- What: Package routing, hygiene, calibration, and audit features into a product; offer certification for compliant deployment in decision workflows.
- Tools/workflows: copilot app; certification rubric; integration SDKs
- Assumptions/Dependencies: Market demand; alignment with regulatory standards; vendor partnerships.
- Horizon scanning centers using calibrated LLM ensembles
- Sectors: national security, corporate strategy, public health
- What: Maintain multi-model ensembles with domain-aware retrieval policies to monitor emerging events and produce calibrated early warnings.
- Tools/workflows: ensemble orchestration; alerting systems; analyst review pipelines
- Assumptions/Dependencies: Secure data access; sustained funding; analyst capacity.
Notes on Cross-Cutting Assumptions and Dependencies
- Results depend on model versions, categories, and time periods; performance may shift with updates and domain drift.
- Reliable ground truth and event resolution data are essential for calibration and continuous improvement.
- Retrieval quality and metadata integrity (publication dates, source credibility) directly affect feasibility and accuracy.
- Cost, latency, and compliance (especially in finance and government) can constrain multi-pass workflows and ensemble approaches.
- Selection bias in prediction-market questions and differences in domain structure impact generalization beyond the studied corpus.
Glossary
- Aggregate human forecasters: The combined predictions of many human participants, often used as a benchmark. "underperformed relative to aggregate human forecasters"
- Anti-dumping/countervailing duties: Trade remedies imposing extra tariffs to offset unfair pricing or subsidies. "anti-dumping/countervailing duty cases can yield provisional rates well above 150\%"
- Autocast: A dataset evaluating forecasting on future world events under evolving context. "ForecastQA \cite{jin2021forecastqa}, Autocast \cite{zou2022forecastingfutureworldevents}, ExpTime \cite{yuan2024exptime}, FOReCAst \cite{yuan2025forecastfutureoutcomereasoning}, and FutureX \cite{zeng2025futurexadvancedlivebenchmark} each evaluate long-horizon prediction and confidence estimation under streaming updates."
- Brier Score: A proper scoring rule measuring the squared error of probabilistic predictions. "Brier Score. Quantifies probabilistic calibration by penalizing confidence errors and is formally defined as:"
- Calibration: The alignment between predicted probabilities and actual outcomes. "emphasizing calibration and model uncertainty"
- Data contamination: Evaluation leakage where test information is present in training, biasing performance. "data contamination due to excessive reliance on model training cutoffs"
- Definition drift: A change in a term’s meaning across contexts that leads to misinterpretation. "Models sometimes misinterpret acronyms or context when additional news shifts their semantic grounding, leading to incorrect predictions."
- Deterministic sampling: Generating repeatable outputs by using zero randomness (e.g., temperature 0). "as well as for deterministic sampling with 0.0 temperature."
- Dynamic market participation: Continuous involvement of agents in evolving market-style systems. "spanning HumanâAI comparison, contextual robustness, and dynamic market participation."
- Expected Calibration Error (ECE): A metric quantifying the difference between predicted confidence and empirical accuracy across bins. "Expected Calibration Error (ECE). Measures the discrepancy between predicted confidence and empirical accuracy across probability bins."
- Failure mode taxonomy: A structured categorization of recurrent error patterns in model behavior. "Failure mode taxonomy: We identify and categorize recurrent failure modes that emerge during forecasting, particularly when contextual information is introduced, highlighting where reasoning and calibration diverge."
- ForecastQA: A dataset for question-answering that targets forecasting and temporal reasoning. "ForecastQA \cite{jin2021forecastqa}, Autocast \cite{zou2022forecastingfutureworldevents}, ExpTime \cite{yuan2024exptime}, FOReCAst \cite{yuan2025forecastfutureoutcomereasoning}, and FutureX \cite{zeng2025futurexadvancedlivebenchmark} each evaluate long-horizon prediction and confidence estimation under streaming updates."
- Hyper-localized: Extremely specific to a narrow locale or context, often reducing general relevance. "their context was hyper-localized"
- Human–AI comparison: Comparative evaluation of human and AI performance on the same tasks. "spanning HumanâAI comparison, contextual robustness, and dynamic market participation."
- LLM-as-a-Judge: Using a LLM to classify or evaluate items according to a rubric. "as an LLM-as-a-Judge"
- Logical leakage: Unintended pathways by which information revealing the answer slips into evaluation. "including logical leakage, unreliable news retrieval, and data contamination due to excessive reliance on model training cutoffs"
- Low-liquidity markets: Markets with limited trading activity, often noisier and less informative for forecasting. "we applied volume filtering to remove low-liquidity markets"
- News-augmented forecasting: Forecasting that incorporates external, time-bounded news context. "News-Augmented Forecasting"
- Polymarket: A real-money prediction market platform used for evaluating forecasts. "prediction markets such as Polymarket, Metaculus, and Manifold Markets"
- Probabilistic calibration: How well predicted probabilities reflect true frequencies of outcomes. "Quantifies probabilistic calibration by penalizing confidence errors"
- Probabilistic inference: Reasoning aimed at deriving probabilities from evidence and priors. "disentangle knowledge recall from probabilistic inference"
- Prompt framing: The specific wording and structure of prompts that influence model behavior and outputs. "predictive ability varies sharply with domain structure and prompt framing"
- Recency bias: Overweighting of recent information at the expense of longer-term trends. "rumour overweighting, definition drift, and recency bias."
- Retrieval alignment: Aligning models to effectively use retrieved information to improve reasoning. "iterative improvements in reasoning and retrieval alignment yield measurable forecasting gains."
- Rumour anchoring: Reliance on unverified or speculative information that skews predictions. "because of definition drift, rumour anchoring and recency bias etc."
- Rumour overweighting: Assigning excessive importance to rumor-driven signals in predictions. "Rumour Overweighting."
- Superforecaster: An expert forecaster known for consistently accurate probabilistic predictions. "Think like a superforecaster (e.g. Nate Silver)."
- Temporal purity: Ensuring inputs respect time cutoffs without leaking future information. "to ensure temporal purity in all model inputs."
- Temporal reasoning tasks: Tasks requiring reasoning about time, sequences, and deadlines. "reinforcement learning on temporal reasoning tasks"
- Time-bounded news snippets: News excerpts restricted to a specific publication window tied to the question’s creation date. "up to ten time-bounded news snippets"
- Volume filtering: Removing items based on low trading volume to improve dataset relevance. "applied volume filtering to remove low-liquidity markets"
Collections
Sign up for free to add this paper to one or more collections.

