- The paper demonstrates that VLMs perform robustly on familiar, semantic-rich domains but exhibit marked failures in geometric transformation tasks, especially rotation.
- The evaluation employs controlled image pair tests across varied domains—ranging from real photos to symbolic scripts—to reveal degradation in performance with increasing transformation magnitudes.
- The findings imply that current VLMs rely on dataset bias and semantic cues rather than genuine geometric reasoning, highlighting a need for improved architecture and training strategies.
Assessing the Fragility of Visual Invariance in Vision-LLMs
Motivation and Problem Statement
Despite substantial progress in Vision-LLMs (VLMs) such as Gemini and GPT-5.2, their ability to generalize spatial relations and geometric transformations remains underexplored. This paper addresses whether state-of-the-art VLMs possess robust geometric and transformation reasoning abilities, or whether their apparent invariance arises merely from semantic familiarity and dataset bias. The authors present an extensive evaluation that probes VLMs on recognition tasks involving rotation, scale, and identity transformations, crossing a spectrum of semantic richness from real photographs to abstract and symbolic domains.
Experimental Framework
VLMs are evaluated using a precisely controlled protocol involving pairs of images subjected to defined transformations: rotation, scaling, and identity. The datasets span (1) Omniglot (handwritten characters in 50 scripts, both familiar and rare), (2) Handwritten English, (3) Times New Roman (standardized printed characters), and (4) PACS (objects in multiple visual styles including Photo, Art, Cartoon, and Sketch). Both open (Qwen2.5-VL, Qwen3-VL variants) and closed (Gemini-2.5-Pro, GPT-5.2) multimodal LLMs are benchmarked.
The primary tasks require models to decide whether two images contain the same object/character under given transformations. For example, does image I′ represent the same object as I when I′ is a rotated or scaled version of I, or just a different object entirely? The main quantitative metrics are accuracy, true positive rate (TPR), and true negative rate (TNR), aggregated over a range of transformation magnitudes.
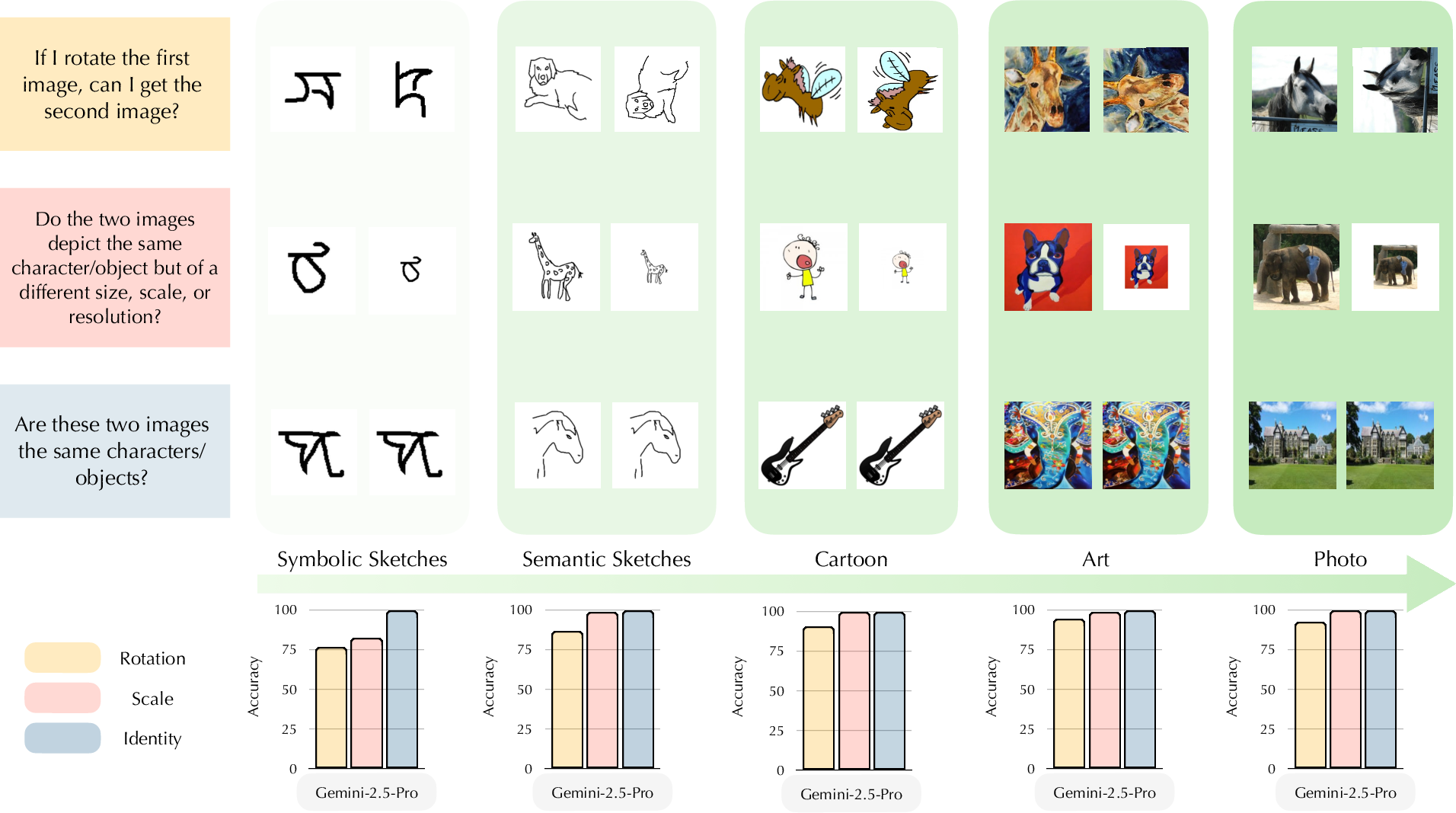
Figure 1: Failure of visual transformation reasoning across visual domains for Gemini-2.5-Pro; accuracy remains high on semantic-rich "Art" and "Photo" but degrades sharply in symbolic/sketch domains, especially for rotation.

Figure 3: Datasets used in evaluation, covering a gradient from natural images to symbolic scripts, facilitate control over semantic content and visual complexity.
Feature-Space Invariance: Vision Encoder Analysis
The paper first assesses rotational invariance at the visual encoder level by measuring cosine similarities between representation vectors from CLIP, DINOv2, SigLIP, and Qwen2.5-VL-7B encoders, for image pairs under increasing rotation. While these encoders exhibit high similarity for small rotations, similarity decreases monotonically with angle, especially for DINOv2. Notably, the similarity decay is less drastic for SigLIP and Qwen2.5-VL-7B, suggesting some degree of low-level feature stability to rotation in the representation space.
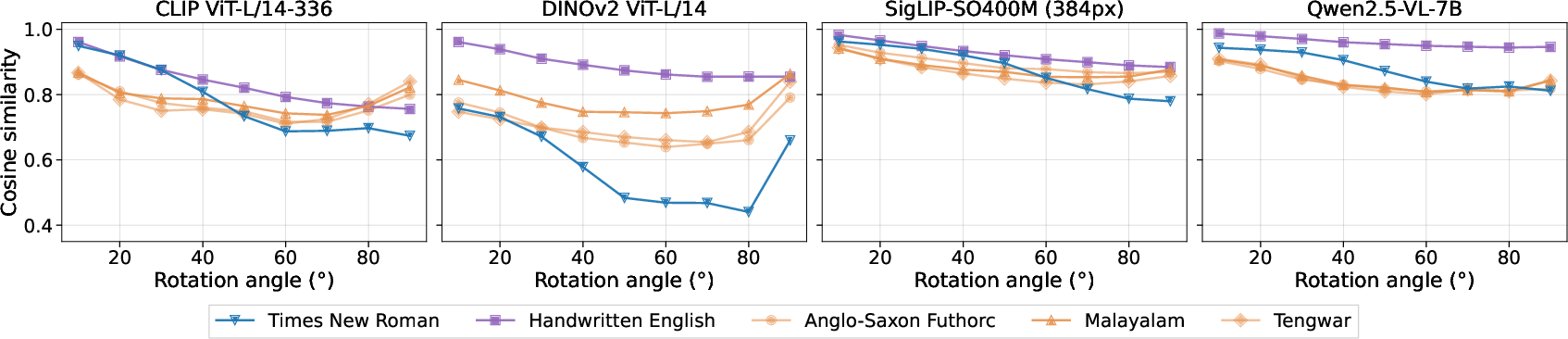
Figure 4: Cosine similarity between visual encoder features across rotation angles; even without the language head attached, representations diverge with rotation, suggesting limited feature-level invariance, especially in symbolic domains.
Despite some invariance at the feature level, all VLMs—including the highest capacity closed-source models—exhibit substantial failures in reasoning about geometric transformations, especially in semantically impoverished domains (<80% accuracy with TPR sharply reduced).
Scale Invariance Analysis
Scaling invariance is less problematic on familiar scripts but still substantially degrades for Omniglot. All models remain highly accurate on Times New Roman and Handwritten English (>95% accuracy) but accuracy on Omniglot is 75-83%, with pronounced variance across scripts depending on their prevalence in pretraining data, revealing a strong correlation with semantic familiarity.
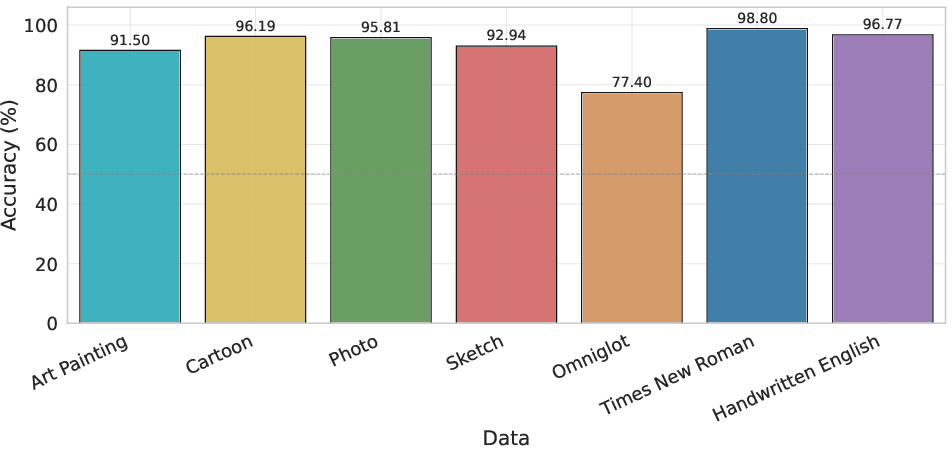
Figure 2: Scale invariance accuracy across domains for Qwen2.5-VL. High accuracy is maintained for natural and familiar domains, but Omniglot accuracy is markedly lower.
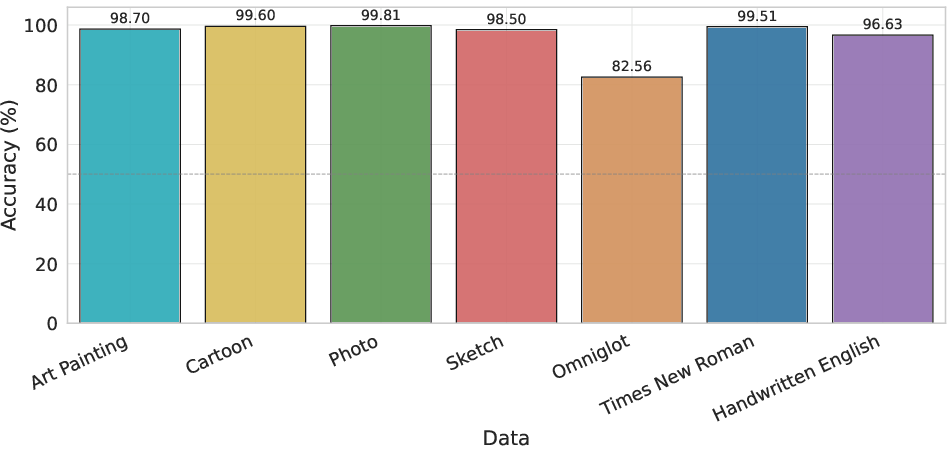
Figure 8: Scale invariance for Gemini-2.5-Pro. Again, performance remains robust except for the least familiar Omniglot scripts.
Prompt Sensitivity & In-Context Learning
ICL and structured visual prompting marginally improve transformation invariance (primarily TPR), but the improvement often comes at a cost of reduced specificity, indicating an over-correction toward "same" predictions. Model failures persist across different prompt templates and example setups, confirming that the deficiency relates to underlying representation and reasoning inadequacy, not merely language interface.

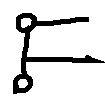

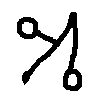
Figure 10: ICL prompting setup; labeled positive and negative examples for rotation reasoning marginally improve results but fail to robustly endow geometric invariance.
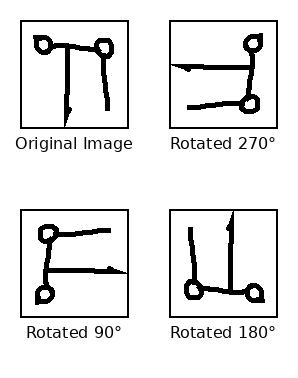
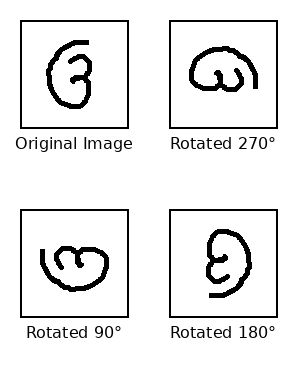
Figure 12: Rotational grid prompting supplies visual anchors for the concept of rotation, but even with strong in-context guidance, generalization is limited to semantically familiar scripts.
Theoretical and Practical Implications
The findings challenge assumptions about emergent invariances in VLMs: robust semantic performance does not translate to spatial-geometric reasoning or equivariance under transformation. This casts doubt on using VLMs in settings that require true geometric consistency and out-of-distribution generalization, such as robotic control, complex physical reasoning, and visual analogy tasks. Since failures persist even with high model scale, architectural modifications and explicit data augmentation for transformation invariance may be necessary.
Conclusion
The paper demonstrates a systematic gap between object-centric semantic understanding and geometric reasoning in current VLMs. Robustness to spatial transformation is not an intrinsic property of today's models but mostly a byproduct of semantic and contextual familiarity. These results highlight the urgent need for representation learning approaches that enforce or learn geometric equivariance and for benchmark design that isolates semantic knowledge from geometric structure. Future multimodal model development must explicitly address these deficiencies for reliable deployment in safety-critical domains and reasoning-intensive applications.
References
For all empirical claims and dataset/model details, see "Semantic Richness or Geometric Reasoning? The Fragility of VLM's Visual Invariance" (2604.01848).
