- The paper introduces a novel sequential decision process that adapts context compression based on real-time available budget.
- It employs a commit-block aggregation policy that dynamically chooses between null, selective, or full compression to balance resource constraints and task relevance.
- Optimized with curriculum-based reinforcement learning, the framework achieves over 1.6× performance gains even under severe context window shrinkage.
Budget-Aware Context Management for Long-Horizon Search Agents
Problem Statement and Conceptual Framework
The standard operational context for long-horizon LLM-based agents confronts a strict bottleneck in the form of finite context-window budgets, leveraging copious memory resources but under deployment constraints governed by inference costs and latency. The linear growth of in-context histories—from both input observations and intermediate reasoning traces—demands robust strategies to manage the accumulation of long-term dependencies without exceeding these resource ceilings. Existing approaches employ static context compression or fixed heuristics, largely disregarding the current, actionable context budget—a design choice that leads either to undue information loss (via premature or excessive compression) or truncated processing and output overflow.
The "ContextBudget" framework reframes context management as a sequential budget-constrained decision process. The agent, at each step, is explicitly conditioned on the available context headroom before loading future observations and must adaptively arbitrate compression intensity and timing to retain task-intrinsic evidence while deferring unnecessary summarization. This policy is operationalized through a commit-block aggregation architecture where compression actions range from null (preserving full history), to selective (summarizing dedicated segments), to full (collapsing all context blocks). The compression policy is then optimized via multi-turn, curriculum-based reinforcement learning (RL), specifically adapting Group Relative Policy Optimization (GRPO), to directly tie compression behavior to downstream task performance and hard-constraint adherence.
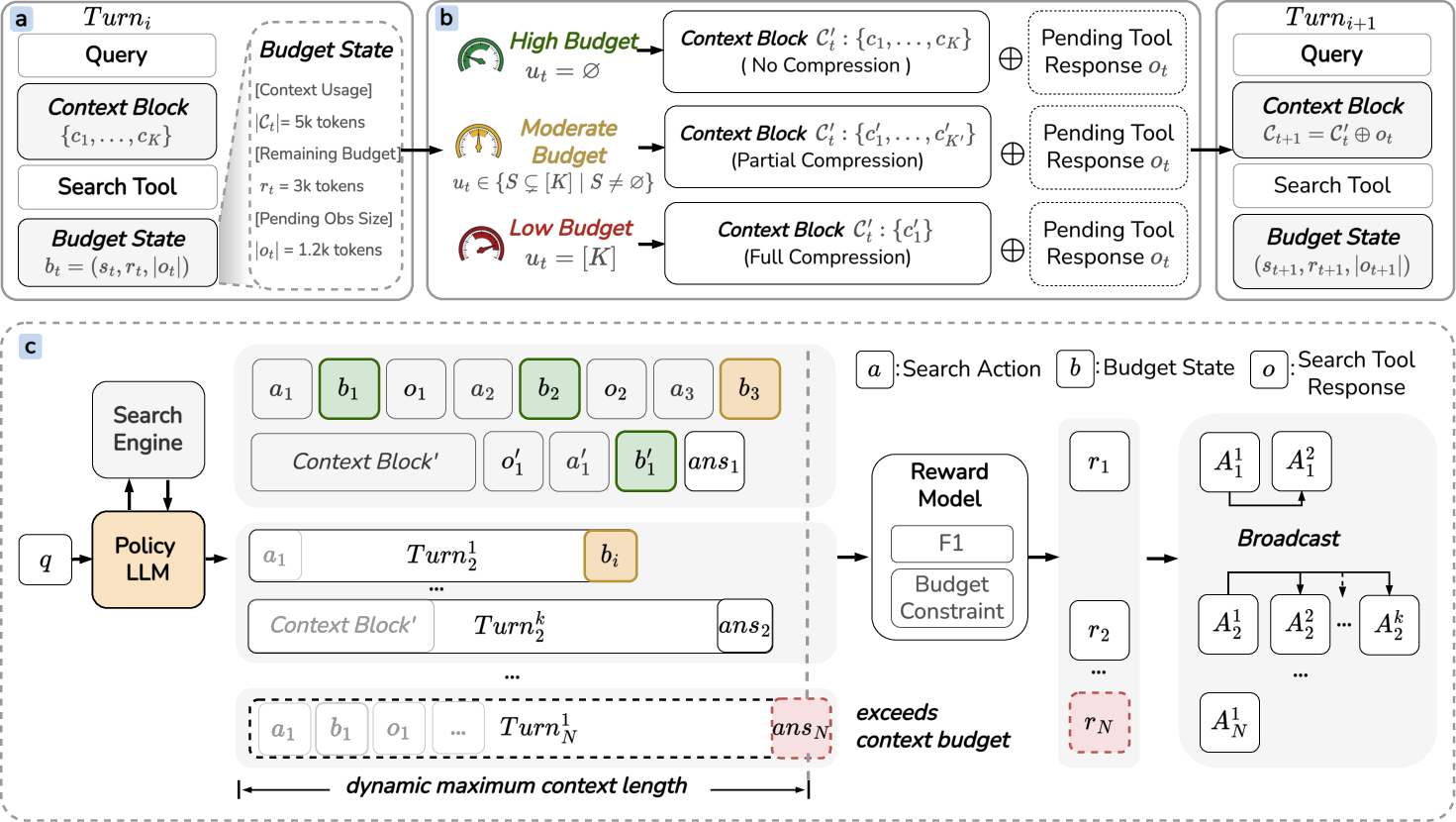
Figure 1: Overview of the ContextBudget framework, depicting budget-aware state conditioning, commit-block aggregation, and curriculum-based GRPO optimization.
Methodological Innovations
Budget-Conditioned State with Deferred Observation Loading
Unlike prior approaches that append observations before managing compression, the agent in ContextBudget observes the available context budget, rt=B−∣Ct∣, and token size of the impending observation ∣ot∣ prior to updating its context. The sequential decision is defined as bt=(st,rt,∣ot∣), which conditions the policy πθ on both current context occupancy and required capacity for the next observation. The agent selects an action that determines which, if any, context segments are compressed via commit-block aggregation prior to loading ot. This mechanism guarantees budget-conformant operation.
Commit-Block Aggregation Policy
Compression occurs at the granularity of semantically contiguous context segments. The policy selects from three aggregation intensities: (i) Null—preserve all segments (sufficient budget); (ii) Partial—aggregate a non-empty subset, tuning the degree of history retention based on anticipated budget stress; (iii) Full—collapse the entire history under severe constraint. The structured action space enables continuous adaptation to the environment's context pressure spectrum.
Curriculum-Based GRPO: Progressive Constraints
Optimization is performed via multi-turn GRPO applied across a curriculum of monotonically shrinking context-window budgets. The curriculum stabilizes RL signal sparsity and exposes the model to escalating pressure, incentivizing policies that generalize to increasingly resource-scarce scenarios. Only rollouts strictly conforming to the current budget are rewarded, reinforcing precise compliance. Trajectory-relative normalization of rewards (group-relative advantages) attenuates gradient instability common in sparse-reward RL.
Empirical Evaluation: Results and Analysis
Experiments span multi-objective compositional QA (using programmatically aggregated variants of NQ, HotpotQA, TriviaQA, etc.) and long-horizon web browsing (BrowseComp-Plus), with evaluation metrics including summed per-objective F1 and LLM-as-judge answer accuracy.
Across backbone model scales (Qwen2.5-7B, Qwen3-30B), ContextBudget delivers over 1.6× performance gains relative to MEM1 and Search-R1 in high-complexity (16 and 32-objective) settings. Its robustness persists under severe context shrinkage: while static or delayed compression baselines (e.g., Summary Agent, MEM1) suffer marked degradation as window size is reduced from 16k to 4k tokens, ContextBudget maintains nearly invariant performance, evidencing the effectiveness of dynamic budget-aware adaptation.
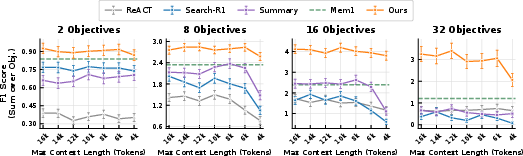
Figure 2: Summed F1 performance across context budgets and objective cardinality, demonstrating ContextBudget's invariance to context shrinkage and superiority to baseline methods.
Compression efficiency analysis affirms that the improved performance is not attributable to indiscriminate summarization. Under light workloads, the model achieves higher F1 with fewer compression actions than MEM1; under heavy workloads, it judiciously increases summarization frequency, deliberately aligning compression acts with objective and context complexity.
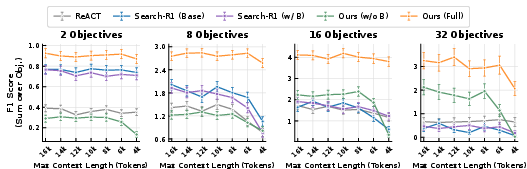
Figure 3: Ablation study isolating the effect of budget metadata and compression policy. Full model outperforms all ablations, including reactive (baseline) budget conditioning.
Ablation and Behavioural Analysis
The inclusion of budget metadata into the policy’s conditioning state is critical: ablation reveals a sharp drop in robustness and F1 when budget signals are removed. Simply appending budget metadata to a non-compression agent (Search-R1 w/B) yields negligible gains; only policies that explicitly couple compression decisions with real-time budget metrics realize the empirically observed stability.
Deferred loading is also essential: agents aware of upcoming observation size prior to appending outperform those using pre-append strategies, especially as objective complexity increases.
Further, a progressive budget curriculum substantially outperforms both static and randomly fluctuating budget schedules. Randomization disrupts credit assignment and convergence in RL, while static schedules lead to overfitting to ample contexts and poor scalability.
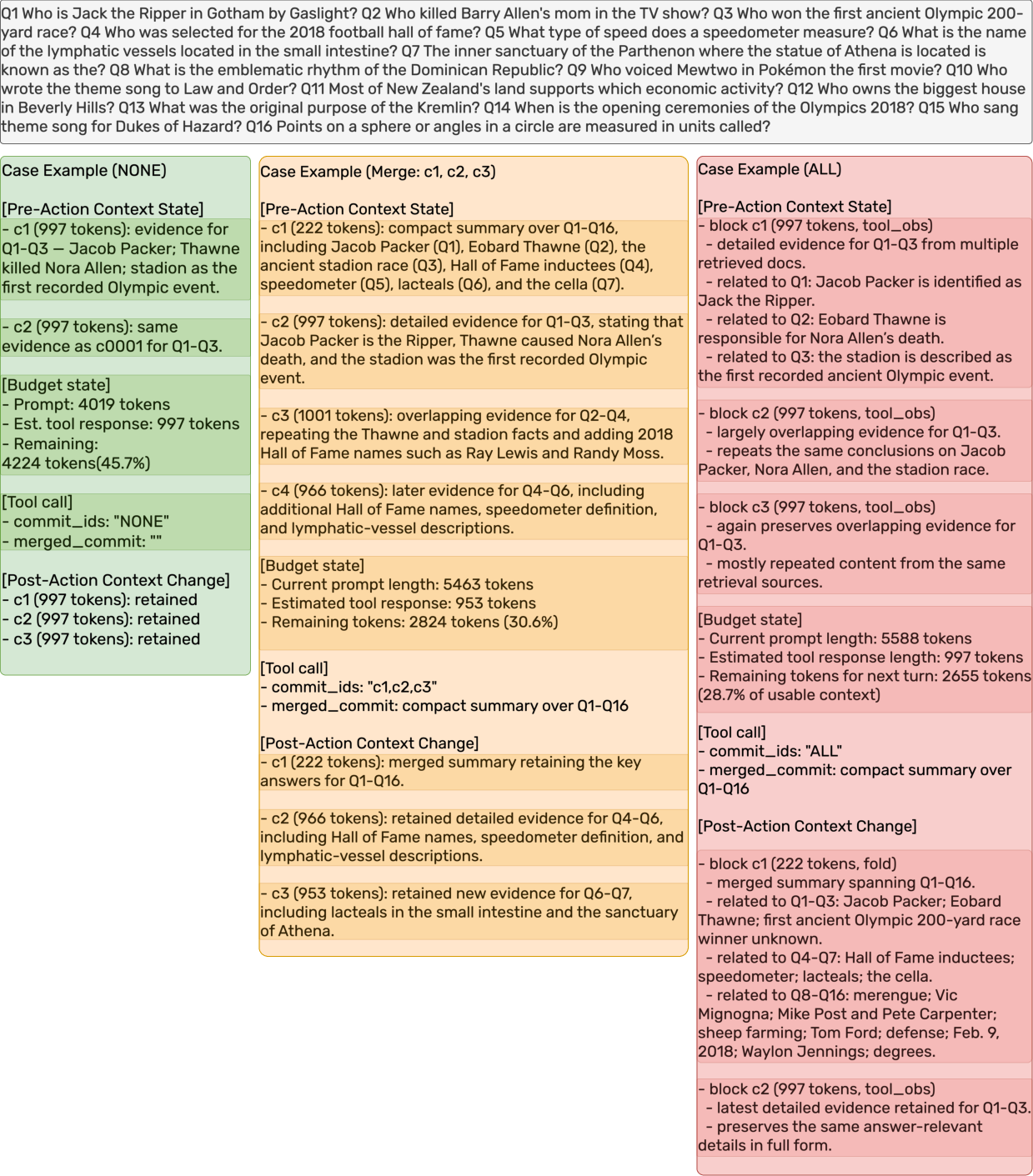
Figure 4: Case study illustrating adaptive selection among [NONE], [Selective], and [ALL] compression strategies as context headroom diminishes.
Practical and Theoretical Implications
From a deployment perspective, ContextBudget offers a principled solution for agent platform designers where inference cost, latency, and compute are fundamentally capped. By reframing context compression as a sequential, budget-aware policy rather than a reactive or periodic side-effect, the method guarantees improved information retention within hard context limits and precludes failures due to abrupt overflow.
Theoretically, this work provides an RL-based template for resource-constrained policy optimization in sequential LLM agent decision processes. Unlike static heuristics or externally regulated resource controllers, this framework tightly integrates memory management with downstream reasoning quality, balancing local retention against global task utility.
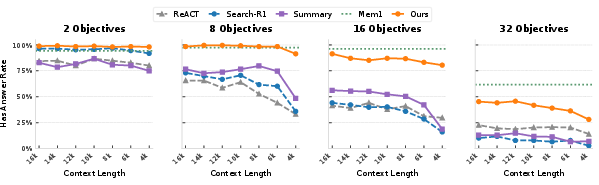
Figure 5: Answer rate comparison across objectives and context windows, where ContextBudget (Ours) maintains competitive or superior answer rates especially as context tightens.
Future Directions
Open questions remain regarding (i) credit assignment granularity in RL (currently trajectory-level), (ii) the extension of segmentation granularity from segments to token- or span-level saliency for critical information preservation, and (iii) generalizability to tool-use, multimodal, or human-in-the-loop settings. Scalability of the RL signal and transferability of the learned policy to novel, unencountered domains will also require further empirical investigation.
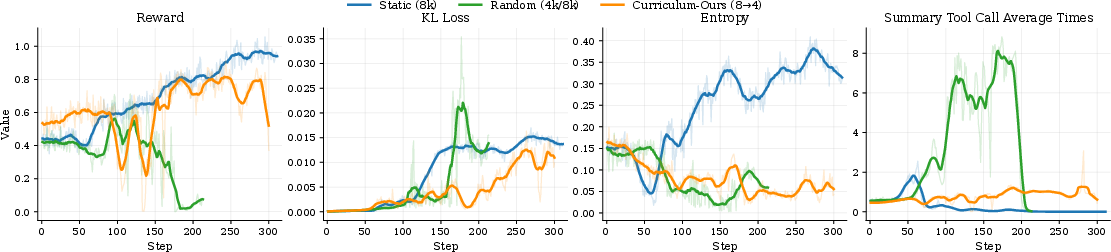
Figure 6: Comparative training dynamics showing reward stability and adaptive summarization under curriculum-based context budget tightening.
Conclusion
Budget-aware context management, as operationalized by ContextBudget, constitutes a substantial advance in robust, long-horizon agent design under finite context windows. Through explicit, adaptive compression policies tightly coupled to available context budgets and optimized by curriculum-based RL, agents achieve superior and stable task performance, particularly as the regime shifts toward high-complexity, resource-scarce horizons. The framework is broadly applicable across memory-constrained LLM deployments and lays a theoretical foundation for future work in RL-based agentic memory management.
Reference: "ContextBudget: Budget-Aware Context Management for Long-Horizon Search Agents" (2604.01664)

