- The paper presents a novel Focus architecture that autonomously compresses and manages context, achieving a 22.7% token reduction while maintaining 60% accuracy.
- It uses an active focus loop to consolidate interaction history, mitigating context bloat and reducing computational costs and latency.
- Aggressive prompting and a biologically-inspired strategy enable LLM agents to efficiently prune redundant data and maintain optimal performance.
Active Context Compression: Autonomous Memory Management in LLM Agents
Introduction
The paper "Active Context Compression: Autonomous Memory Management in LLM Agents" (2601.07190) tackles the issue of "Context Bloat" in LLM agents, a significant challenge in long-horizon tasks, particularly in software engineering. Context Bloat arises as the interaction history lengthens, leading to escalating computational costs, increased latency, and deteriorating reasoning capabilities due to distractions from irrelevant past information. The authors propose a novel agent-centric architecture called Focus, inspired by the exploration strategies of Physarum polycephalum (slime mold), to autonomously manage memory and context effectively.
Problems and Challenges
The paper identifies three major challenges related to context window usage in autonomous AI agents:
- Cost: Re-evaluating and processing a growing historical context during iterative loops leads to quadratic growth in computational costs.
- Latency: The time-to-first-token increases linearly with context length, resulting in sluggish performance of interactive agents.
- Context Poisoning: Long contexts filled with redundant exploration data can confuse the model, inducing the "Lost in the Middle" phenomenon.
The authors acknowledge existing solutions like MemGPT and Voyager that utilize external memory hierarchies or skill libraries to address context limitations. Moreover, approaches like Reflexion, LLMLingua, and StreamingLLM focus on reflection and prompt compression. The distinguishing feature of Focus lies in its ability to perform intra-trajectory compression actively, allowing the agent to self-regulate its context without relying heavily on external memory systems.
Focus Architecture and Methodology
The Focus architecture operates through the "Focus Loop," introducing two critical processes: start_focus and complete_focus. This loop enables agents to autonomously decide when to consolidate and compress their interaction history:
- Start Focus: Agents declare their current investigative task.
- Explore: Conducts necessary operations and interactions.
- Consolidate: Upon completing a task, agents synthesize a summary of significant learnings.
- Withdraw: The summary is stored in a persistent Knowledge block, and the intervening messages are deleted, converting the context into a "Sawtooth" pattern of growth and compression.
The architecture is designed to enforce effective context management, drawing parallels to biological systems like slime mold that efficiently explore environments while retracting from dead ends. This analogy is pivotal in demonstrating how agents can effectively prune irrelevant data and maintain an optimal context.
Experimental Evaluation
The performance of Focus was evaluated using SWE-bench Lite, a benchmark for software engineering agents. Experiments were conducted with the Claude Haiku 4.5 model on five context-intensive instances. Focus demonstrated a significant 22.7% token reduction from 14.9 million to 11.5 million tokens while maintaining identical accuracy levels (60%) as baseline agents.
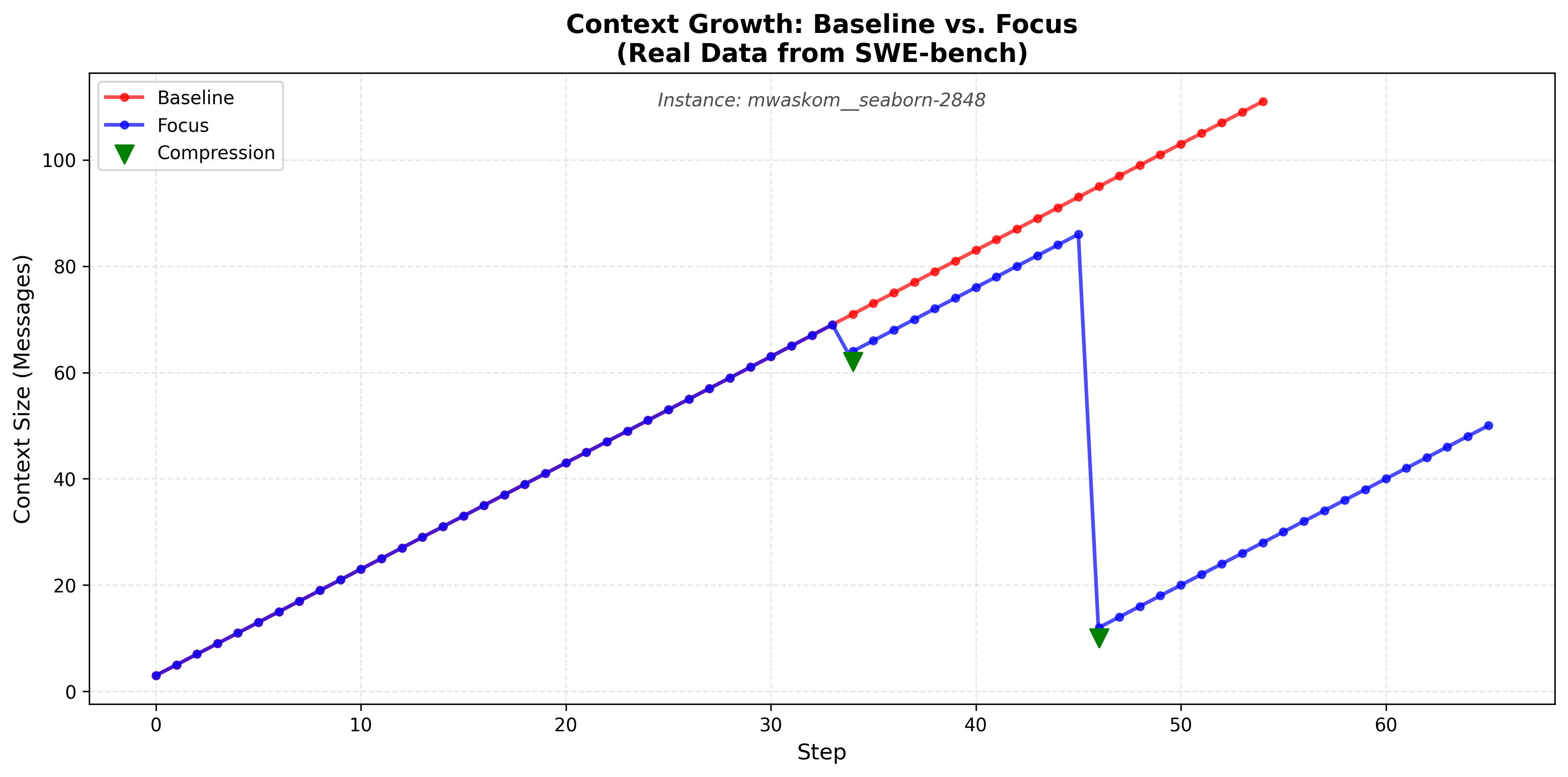
Figure 1: Conceptual sawtooth pattern of context growth. Focus (blue) exhibits periodic compressions (drops) while Baseline (red) grows monotonically. With aggressive prompting, Focus compresses every 10-15 tool calls, preventing context bloat while preserving learnings in a persistent Knowledge block.
Key Findings and Implications
- Token Efficiency Without Accuracy Loss: Focus achieved notable reductions in token usage while maintaining performance. This efficiency challenges the assumed trade-off between context compression and task accuracy.
- Aggressive Prompting: Implementing directive prompts that enforce frequent compression cycles significantly enhanced the system's effectiveness, suggesting that LLMs require guided prompting to optimize context accumulation and pruning.
- Task-Specific Benefits: Focus displayed the greatest efficiency improvements in exploration-heavy tasks, indicating its utility in scenarios requiring extensive data navigation and analysis.
Conclusion
The research illustrates that aggressive, autonomous context compression can lead to efficient memory management without compromising accuracy in LLM agents. The proposed Focus architecture provides a framework for enhancing the capabilities of cost-aware agentic systems. Future directions include expanding validation across more extensive datasets, exploring fine-tuning methods for compression heuristics, and examining the architecture's applicability across diverse models and tasks. As LLMs continue to evolve, the ability to self-regulate context and manage memory dynamically will be critical in handling complex, long-duration tasks efficiently.