AgentFold: Long-Horizon Web Agents with Proactive Context Management
Abstract: LLM-based web agents show immense promise for information seeking, yet their effectiveness on long-horizon tasks is hindered by a fundamental trade-off in context management. Prevailing ReAct-based agents suffer from context saturation as they accumulate noisy, raw histories, while methods that fixedly summarize the full history at each step risk the irreversible loss of critical details. Addressing these, we introduce AgentFold, a novel agent paradigm centered on proactive context management, inspired by the human cognitive process of retrospective consolidation. AgentFold treats its context as a dynamic cognitive workspace to be actively sculpted, rather than a passive log to be filled. At each step, it learns to execute a `folding' operation, which manages its historical trajectory at multiple scales: it can perform granular condensations to preserve vital, fine-grained details, or deep consolidations to abstract away entire multi-step sub-tasks. The results on prominent benchmarks are striking: with simple supervised fine-tuning (without continual pre-training or RL), our AgentFold-30B-A3B agent achieves 36.2% on BrowseComp and 47.3% on BrowseComp-ZH. Notably, this performance not only surpasses or matches open-source models of a dramatically larger scale, such as the DeepSeek-V3.1-671B-A37B, but also surpasses leading proprietary agents like OpenAI's o4-mini.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “AgentFold: Long-Horizon Web Agents with Proactive Context Management”
What is this paper about?
This paper introduces AgentFold, a computer program (an “AI web agent”) that browses the internet to answer complex questions. The big idea is to help the agent manage its “memory” better during long tasks, so it doesn’t get overwhelmed by too much information or lose important details by summarizing too aggressively.
Think of it like doing a long school project online: if you copy every single thing you see, your notes become a mess. But if you summarize too early, you might throw away something important. AgentFold learns to keep its notes clean and useful by “folding” its memory—saving key details and merging finished parts into neat summaries at the right times.
What questions did the researchers want to answer?
The paper focuses on a few simple questions:
- Can an AI agent manage its own memory while browsing, so it neither drowns in details nor forgets crucial facts?
- Can this help the agent solve long, multi-step tasks (called “long-horizon” tasks) more accurately?
- Can a smarter memory strategy let a smaller model beat bigger, more expensive ones?
How does AgentFold work? (Methods in plain language)
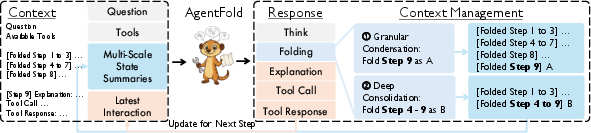
AgentFold treats its memory like a tidy workspace with two kinds of notes:
- Multi-Scale State Summaries: short, organized notes about what’s already been done (like clean summaries in your notebook).
- Latest Interaction: a full, detailed record of the most recent step (like a fresh sticky note with all the details you just found).
At each step, the agent does three things:
- Decides how to “fold” its memory:
- Granular Condensation: turns the latest detailed step into a short, precise summary (like condensing a paragraph into one line).
- Deep Consolidation: merges several related steps into one higher-level summary once a mini-task is finished (like wrapping up a whole chapter with one takeaway).
- Explains briefly why it’s taking the next step.
- Takes an action, like searching the web or opening a page.
After acting, the result gets added as the new “Latest Interaction,” and the cycle repeats.
How they trained it:
- The team built a special data pipeline called “Fold-Generator” to create good examples of how to browse and fold memory properly.
- They filtered out bad examples using rejection sampling (if a step was messy or didn’t follow the rules, they threw it away).
- They then taught the model with supervised fine-tuning (SFT)—basically showing it many good examples until it learned the pattern—using an open-source base model called Qwen3-30B-A3B.
Key terms explained:
- Long-horizon task: a problem that needs many steps to solve (dozens or even hundreds).
- Context: the “memory” the AI uses—past actions, observations, and summaries.
- Folding: the agent’s way of cleaning up and organizing memory at the right moments, either by condensing a step or merging many steps.
What did they find, and why does it matter?
AgentFold did very well on tough web-browsing tests:
- BrowseComp: 36.2%
- BrowseComp-ZH (Chinese): 47.3%
- WideSearch: 62.1%
- GAIA (general tasks, text-only subset): 67.0%
Why this is impressive:
- It beat or matched much larger open-source models (some over 20 times bigger), like DeepSeek-V3.1-671B.
- It also outperformed a leading proprietary agent (OpenAI’s o4-mini) on some benchmarks.
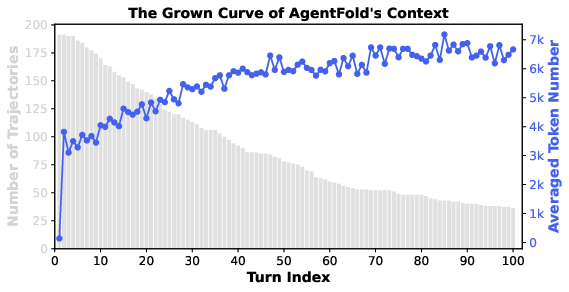
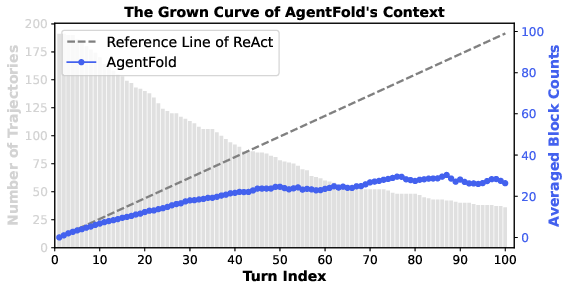
- Its memory stayed compact even in long tasks: after 100 steps, the context stayed around “7k tokens” (think: a manageable notebook), not exploding in size like typical agents.
- It can keep working well for hundreds of steps (tested up to 500 turns), which is great for deep research tasks.
In short: managing memory proactively helped the agent stay focused, use fewer resources, and solve longer, harder problems more reliably.
Why is this important for the future?
If AI agents can organize their own memory on the fly, they can:
- Do serious, multi-hour research without getting “lost.”
- Work efficiently, using less compute and memory.
- Scale to very long tasks—bigger projects, better accuracy, and more stable results.
The authors suggest the next step is to combine this with reinforcement learning (RL), so the agent can discover even smarter folding strategies by directly practicing and optimizing for success.
The big takeaway
AgentFold shows that how an AI manages its memory can matter as much as how big the AI is. By “folding” its notes like a careful student—saving important details and wrapping up finished parts—AgentFold stays sharp over long tasks and can outperform much larger models.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme to guide follow-up research.
Method and Design Limitations
- No mechanism to “unfold” or retrieve pruned details after a deep consolidation; unclear how the agent recovers if critical information is lost or mis-summarized.
- Lack of principled criteria for selecting the folding range k and the aggressiveness of folding; no learned utility model or confidence-aware policy for deciding granular vs deep consolidation.
- Latest Interaction only retains the immediately preceding step; unexplored whether a short rolling window (last K full steps) or adaptive windowing would reduce near-term information loss.
- No ablation isolating the contributions of Granular Condensation vs Deep Consolidation vs both; unclear which operation drives gains on which task regimes.
- No analysis of the effect of the “thinking/explanation” components on folding quality and downstream performance (e.g., with/without visible CoT, distilled rationales).
- Absent theoretical guarantees or bounds on context growth (e.g., expected token/block complexity over horizon H under different folding policies).
- Folding directives depend on strict structured output and parsing; robustness to minor format deviations or parser failures is not studied.
Data and Training Pipeline Gaps
- Fold-Generator data quality, diversity, and bias are under-specified; no diagnostics on coverage of task types, failure modes, or linguistic/style diversity of summaries.
- Rejection sampling ensures format compliance but may bias trajectories toward “clean” paths; impact on generalization to noisy or atypical web interactions is unknown.
- Potential overfitting to generator model style: no experiments with cross-generator training or style-randomization to test robustness.
- No ablation on dataset size/composition vs performance (how many steps/trajectories are needed; which folds are most learnable).
- The generated trajectories lack ground-truth labels for “fold correctness”; no human or automated verification that summaries preserve key facts.
- Unclear whether the training data or evaluation benchmarks are contaminated by overlaps with generator outputs or web content used in data creation.
Evaluation and Experimental Limitations
- Limited metrics: beyond final task score and token/block counts, no measures of summary fidelity, factual preservation, or error propagation due to folding.
- No significance testing, confidence intervals, or variance analysis across runs for large benchmarks; robustness of reported gains is unclear.
- In scaling-to-500 turns, success rates and accuracy are not reported—only context length dynamics—leaving the utility of very long horizons unquantified.
- Comparisons may be confounded by heterogeneous toolchains/environments across baselines; the browser/tool setup is insufficiently specified for fair reproducibility.
- No cost/latency profiling (e.g., tokens processed, wall-clock time, memory) per turn and per horizon; the compute benefits of folding remain anecdotal.
- No head-to-head ablations against stronger, learned memory baselines (e.g., episodic memory stores, retrieval-augmented memories, memory graphs) under identical conditions.
- Lack of cross-domain testing (e.g., code search, academic literature, multi-hop QA with structured sources); generality beyond web browsing benchmarks is unproven.
- No human evaluation of readability, auditability, or traceability of state summaries for debugging and oversight.
Robustness, Safety, and Reliability Gaps
- No evaluation under adversarial web settings: prompt injection, malicious scripts, content hijacking, cloaked pages, or misleading metadata.
- No study of robustness to dynamic/non-stationary environments (content changes between steps, rate-limits, intermittent tool failures).
- No mechanisms to detect and correct erroneous or contradictory folds; absence of self-verification or rollback strategies after mis-consolidations.
- Hallucination control and misinformation propagation are not assessed; folding could compress and lock in fabricated or biased content.
- Privacy/compliance and data retention concerns are unaddressed, especially given persistent multi-scale summaries that may store sensitive content.
Scalability and Generalization Questions
- Portability to other base LLMs (smaller or larger, different architectures) is untested; sensitivity to instruction-following and reasoning strength is unknown.
- Interaction with multimodal inputs (images, PDFs, tables, embedded maps) is unexplored; can folding handle heterogeneous content effectively?
- Interoperability with external knowledge bases or vector stores (combining intra-task folding with external memory retrieval) is untested.
- Team/interactive settings (multi-agent collaboration, task handoff, shared memory) are not considered; how folding integrates in collaborative workflows is open.
- Persistence across sessions (inter-task memory) and lifelong adaptation are not addressed; folding is scoped to within-task context only.
Policy Learning and Control Open Questions
- The paper proposes RL as future work; currently no evidence on whether RL or bandit-style feedback improves folding policies over SFT, nor on safe reward design.
- No uncertainty-aware or risk-sensitive folding policy; how to tie folding decisions to calibrated confidence or downstream utility remains open.
- No exploration of adaptive budgets (token/time/turn) that trade off folding aggressiveness and action depth dynamically per task.
Reproducibility and Transparency
- Exact tool configurations, browsing stack, and environment setup (e.g., rendering engine, JavaScript handling, anti-bot measures) are insufficiently documented for replication.
- Availability of the Fold-Generator code, trained datasets, and full logs is unclear; without them, independent verification of folding behaviors is difficult.
- Criteria for forced termination and its effect on reported performance (especially for tasks nearing the turn limit) are not disentangled from agent competence.
These gaps suggest concrete next steps: design reversible or uncertainty-aware folding; build ground-truthed fold-fidelity datasets; ablate folding modes and training data properties; add rigorous robustness/safety evaluations; report cost-performance curves; test across models, domains, modalities, and memory baselines; and introduce RL or utility-driven policies for when and how to fold.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now using the paper’s AgentFold paradigm and tooling.
- Enterprise competitive intelligence and market landscape analysis (finance, software, manufacturing)
- What: Long-horizon web research across hundreds of sources; AgentFold’s deep consolidation reduces noise while granular condensation preserves critical facts, producing Multi-Scale State Summaries as a navigable briefing.
- Product/workflow: “AgentFold CI Analyst” with a fold-aware research brief UI; headless browser + search APIs + exportable summary blocks.
- Assumptions/dependencies: Open-web access, anti-bot compliance (CAPTCHAs, rate limits), paywall constraints, human-in-the-loop validation for high-stakes decisions.
- Academic literature reviews and meta-analyses (academia, healthcare)
- What: Tiered summaries of papers and sub-topics; failed leads folded into concise conclusions; key methods/results preserved at fine-grain.
- Tools/workflows: PubMed/arXiv APIs; “Folded Literature Map” with per-subtopic blocks; citation capture and deduplication.
- Assumptions/dependencies: Access to licensed content; reproducibility checks; domain expert oversight for clinical or statistical claims.
- Legal due diligence and e-discovery triage (policy/legal)
- What: Multi-source review (case law, filings, regulatory guidance) with explicit folding directives to compress repetitive or unproductive trails and retain pivotal precedents.
- Product/workflow: “Folded Case Digest” with block-level audit trail; export to matter management systems.
- Assumptions/dependencies: Legal accuracy and confidentiality; paywall/licensing; human attorney review; document quality/OCR fidelity.
- Investigative journalism and OSINT (media, policy)
- What: Cross-source verification over extended browsing; timeline synthesis via multi-scale summaries; explicit reasoning trails support editorial review.
- Product/workflow: “AgentFold OSINT Desk” with provenance tracking for each folded block.
- Assumptions/dependencies: Misinformation risk; need for independent fact-checking; source reliability scoring.
- Customer support knowledge base curation (software/SaaS)
- What: Mine tickets/forums/docs; consolidate recurring issues into KB articles while preserving edge-case details in granular blocks.
- Tools/workflows: Helpdesk integrations; “Context Folding KB Builder” that turns long threads into structured resolutions.
- Assumptions/dependencies: Access to internal data, privacy/compliance, PII redaction.
- Cyber threat intelligence scanning (cybersecurity)
- What: Continuous monitoring of indicators across forums, repos, and advisories; deep consolidation suppresses noise while retaining confirmed IoCs and TTPs.
- Product/workflow: “Folded CTI Watch” dashboards with block-level provenance.
- Assumptions/dependencies: Secure browsing sandbox; rate limits; integration with SIEM/SOAR; analyst validation.
- SEO/content audit and competitive site reviews (marketing)
- What: Crawl and compare hundreds of pages; consolidate redundant patterns (e.g., thin content) and preserve exemplar pages in high-fidelity blocks.
- Tools/workflows: Headless crawler + SERP APIs; exportable content gap summary.
- Assumptions/dependencies: Robots.txt compliance; site permissions; accurate parsing/rendering.
- Procurement/vendor evaluation dossiers (manufacturing, energy, public sector)
- What: Compile specs, certifications, financials; fold dead-end checks; retain critical compliance details as fine-grained blocks.
- Product/workflow: “AgentFold Vendor Dossier” with multi-scale evidence trails.
- Assumptions/dependencies: Source reliability; up-to-date certifications; human review for awards and risk.
- Personal research assistant for complex decisions (daily life)
- What: Multi-step product comparisons and travel planning; long-horizon exploration with compact context and clear trade-off summaries.
- Tools/workflows: Browser plug-in; integrations to booking or shopping sites.
- Assumptions/dependencies: API integrations; authentication/paywall handling; user privacy.
- Cost-efficient agent orchestration and LLM app tuning (software/ML ops)
- What: Integrate AgentFold’s proactive folding into existing agent stacks (e.g., LangChain/LlamaIndex) to cut context size and inference cost at long horizons.
- Tools/workflows: “Context Folding SDK” and middlewares that parse/apply folding directives (JSON).
- Assumptions/dependencies: Long-context model availability; tool execution reliability; telemetry for fold efficacy.
Long-Term Applications
The following applications are viable but need further research, scaling, RL-based policy learning, stronger integrations, or governance.
- Autonomous scientific discovery assistants and living reviews (academia, healthcare)
- What: Closed-loop hypothesis formation across literature, data, and lab notebooks; multi-scale memory of experiments, negative results, and evolving rationale.
- Tools/products: “AgentFold Science Pod” with ELN/LIMS integration; RL to learn non-obvious folding policies.
- Dependencies: Lab safety, experimental APIs, rigorous validation; regulatory approvals for medical domains.
- Regulatory surveillance and compliance copilots (policy/finance/healthcare)
- What: Continuous, multi-jurisdiction monitoring of evolving rules; retain authoritative clauses at granular level and fold minor updates.
- Product/workflow: “AgentFold Compliance Radar” with audit-ready folding logs and explainable summaries.
- Dependencies: Timely access to official sources; legal review; governance for auditability and accountability.
- Enterprise-grade RPA for semi-structured web workflows (operations/software)
- What: Months-long tasks spanning procurement, onboarding, licensing checks; folding maintains tractable memory and allows course corrections after dead ends.
- Tools/products: Integration with ERP/CRM; reliability enhancements (retry policies, CAPTCHA solving).
- Dependencies: Robustness to site changes; safety/guardrails; task-level RL.
- Clinical evidence synthesizers and living guidelines (healthcare)
- What: Continually updated systematic reviews; preserve pivotal trial details while folding incremental updates.
- Tools/products: Guideline authoring platforms; traceable fold logs for medical boards.
- Dependencies: Content licensing; bias control; expert oversight; patient safety considerations.
- Crisis response OSINT fusion centers (public safety/policy)
- What: 24/7 multilingual monitoring of social, news, and official channels; deep consolidation for evolving situational summaries.
- Tools/products: “AgentFold Situational Awareness” with geotagging and credibility scoring.
- Dependencies: Robust misinformation handling; secure infrastructure; cross-agency workflows.
- Autonomous product design and trend research (industry/design)
- What: Long-horizon scanning of patents, forums, catalogs; multi-scale memory of design patterns and constraints.
- Tools/products: CAD/PLM integrations; IP risk tracking in folded blocks.
- Dependencies: IP compliance; expert validation; domain-specific toolchains.
- Personal long-term memory managers (daily life/education)
- What: Lifelong assistants that fold digital traces (emails, notes, browsing) into multi-scale summaries for reflection, learning, and planning.
- Tools/products: Privacy-preserving local agents; fold-aware personal knowledge graphs.
- Dependencies: PII protection, consent; on-device inference or secure cloud; user control over folding policies.
- High-level task memory for embodied agents (robotics)
- What: Apply proactive context folding to task-level plans and failures over hundreds of steps (e.g., household tasks, inspections).
- Tools/products: “Folded Task Memory” modules attached to planners.
- Dependencies: Sensor/action integration; mapping to spatial/temporal representations; safety and verification.
- Energy market and grid operations analysis (energy/finance)
- What: Long-horizon monitoring of markets, weather, outages; retain critical events; fold routine fluctuations.
- Tools/products: “AgentFold Grid Intel” with data feeds and operator consoles.
- Dependencies: Real-time data licenses; model calibration; operator oversight.
- Fold-aware governance and audit suites for AI agents (software/policy)
- What: Standardized folding directive logs (JSON) for compliance, reproducibility, and post-hoc review across agent ecosystems.
- Tools/products: “AgentFold Governance Suite” with policy engines; cross-agent “Folding API” standard.
- Dependencies: Industry standards; regulatory alignment; secure logging and provenance.
Cross-cutting assumptions and dependencies
- Model capability and context: Performance depends on a strong base LLM with sufficient context window; folding reduces token pressure but still requires long-context models.
- Tooling: Reliable headless browsing, search APIs, data parsing, and rate-limit handling; robust error recovery aligned with the folding policy.
- Data access and licensing: Paywalls, authentication, and content rights may constrain deployment; multilingual performance requires strong translation.
- Accuracy and oversight: Human-in-the-loop validation for high-stakes domains (legal, healthcare, policy); fact-checking and bias control are essential.
- Governance and safety: Auditability via structured folding directives; PII handling and privacy; alignment and guardrails for autonomous long-horizon behavior.
- Scaling: RL and domain-specific fine-tuning can improve folding decisions; industrialization requires MLOps, monitoring, and reliability engineering.
Glossary
- AgentFold: A web agent paradigm that proactively manages its context via learned folding to handle long-horizon tasks efficiently. "we introduce AgentFold, a novel agent paradigm centered on proactive context management, inspired by the human cognitive process of retrospective consolidation."
- append-only context: A logging strategy that accumulates all past interactions without pruning, often causing bloated, noisy context. "However, the append-only context inherent to the ReAct paradigm leads to context saturation on long-horizon tasks, impairing reasoning as critical signals become buried in noise."
- cognitive workspace: The agent’s structured internal context, actively curated to support reasoning and action. "AgentFold treats its context as a dynamic cognitive workspace to be actively sculpted, rather than a passive log to be filled."
- context saturation: The degradation of agent performance due to excessive, noisy context accumulation. "Prevailing ReAct-based agents suffer from context saturation as they accumulate noisy, raw histories,"
- deep consolidation: A folding operation that merges multiple prior steps and the latest interaction into a single coarse summary. "or as a deep consolidation, it fuses the Latest Interaction with a chain of prior summaries, retracting these specific entries and replacing them with a single abstraction at a coarser strategic scale."
- dynamic 'look-back' mechanism: A retrospective process where the agent revisits past steps to distill insights and discard irrelevancies. "This involves a dynamic `look-back' mechanism: after several actions, irrelevant steps are discarded, intermediate findings are distilled, and key insights are abstracted."
- Fold-Generator: A specialized data collection pipeline that produces trajectories demonstrating structured folding for training. "To this end, we develop Fold-Generator, a specialized LLM-oriented data collection pipeline that can automatically generate trajectories for training."
- folding directive: A structured command specifying how to update state summaries (range and replacement summary) at each step. "This folding directive has a dual (two-scale) character:"
- folding operation: The learned action of compressing or consolidating context segments during task execution. "it learns to execute a `folding' operation, which manages its historical trajectory at multiple scales"
- GAIA: A benchmark for evaluating general AI assistant capabilities. "and 67.0% on general benchmark GAIA"
- granular condensation: A folding operation that compresses only the latest step into a fine-grained summary while preserving key details. "it can perform granular condensations to preserve vital, fine-grained details"
- Intra-Task Context Curation: Managing and refining the context generated within the current task to maintain relevance over long horizons. "Our work, in contrast, pursues Intra-Task Context Curation, which focuses on managing the context generated within the task itself to maintain relevance and efficiency over long horizons."
- Item-F1: A task-specific evaluation metric (F1 score at the item level) used in WideSearch. "WideSearch-en (the most detailed metric: Item-F1)"
- JSON object: The data format used to encode the folding directive’s range and summary. "It takes the form of a JSON object:"
- Latest Interaction: The complete record of the most recent step (explanation, action, observation) serving as working memory. "and the \textcolor{red!70}{Latest Interaction}, which is the complete record of the most recent action and observation."
- long-horizon tasks: Tasks requiring many steps and sustained reasoning, where context management is crucial. "LLM-based web agents show immense promise for information seeking, yet their effectiveness on long-horizon tasks is hindered by a fundamental trade-off in context management."
- long-term memory: The agent’s curated, abstracted summaries of past steps used for coherent long-range reasoning. "The \textcolor{blue!70}{Multi-Scale State Summaries} function as the agent's curated long-term memory."
- Multi-Scale State Summaries: A sequence of condensed summaries at varying granularities capturing the historical trajectory. "AgentFold's workspace (i.e., context) is explicitly partitioned into the invariant user question, the curated \textcolor{blue!70}{Multi-Scale State Summaries} representing long-term memory, and the high-fidelity \textcolor{red!70}{Latest Interaction} serving as the immediate working memory."
- rejection sampling: A filtering mechanism that discards generated steps or trajectories that violate format or contain errors. "we leverage a rejection sampling mechanism, discarding any generated step that fails to strictly adhere required formats, or any trajectory that contains too many environmental errors."
- retrospective consolidation: A cognitive process of integrating and abstracting past information to support sustained reasoning. "inspired by the human cognitive process of retrospective consolidation."
- ReAct: A paradigm where agents iterate in a reasoning–action–observation loop, typically with append-only history. "Prevailing ReAct-based agents suffer from context saturation as they accumulate noisy, raw histories"
- Supervised Fine-Tuning (SFT): A training method that fine-tunes models on curated trajectory pairs to internalize structured responses. "This curated dataset is then used for conducting conventional Supervised Fine-Tuning (SFT) on open-source LLMs."
- tool call: An external action invoking a specified tool with arguments to obtain an observation for the next step. "Simultaneously, the resulting observation from the executed tool call then, combined with the action, constitutes the new Latest Interaction for the subsequent cycle."
- trajectory: The ordered sequence of agent steps (reasoning, actions, observations) that defines progress on a task. "It operates not on a monolithic log, but on a dynamic trajectory composed of \textcolor{blue!70}{Multi-Scale State Summaries}—several distilled records of past events—and the \textcolor{red!70}{Latest Interaction}"
- uniform full-history summarization: A policy that summarizes the entire history at every step, risking the loss of crucial details. "AgentFold's design offers a novel approach to context management, resolving the trade-off between the append-only history of ReAct, which leads to context saturation, and uniform full-history summarization, which risks irreversible information loss."
- working memory: The immediate, high-fidelity memory of the latest interaction used for short-term decision-making. "The \textcolor{red!70}{Latest Interaction} acts as a high-fidelity working memory."
Collections
Sign up for free to add this paper to one or more collections.

