Test-Time Scaling Makes Overtraining Compute-Optimal
Abstract: Modern LLMs scale at test-time, e.g. via repeated sampling, where inference cost grows with model size and the number of samples. This creates a trade-off that pretraining scaling laws, such as Chinchilla, do not address. We present Train-to-Test ($T2$) scaling laws that jointly optimize model size, training tokens, and number of inference samples under fixed end-to-end budgets. $T2$ modernizes pretraining scaling laws with pass@$k$ modeling used for test-time scaling, then jointly optimizes pretraining and test-time decisions. Forecasts from $T2$ are robust over distinct modeling approaches: measuring joint scaling effect on the task loss and modeling impact on task accuracy. Across eight downstream tasks, we find that when accounting for inference cost, optimal pretraining decisions shift radically into the overtraining regime, well-outside of the range of standard pretraining scaling suites. We validate our results by pretraining heavily overtrained models in the optimal region that $T2$ scaling forecasts, confirming their substantially stronger performance compared to pretraining scaling alone. Finally, as frontier LLMs are post-trained, we show that our findings survive the post-training stage, making $T2$ scaling meaningful in modern deployments.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine you’re practicing for a quiz. You can spend time studying (training), and later you’ll take the quiz (testing). You could also allow yourself multiple tries per question at test time—like guessing a few times and keeping the best answer. This paper asks: if we know we’ll let the model try multiple times when answering, how should we train it in the first place?
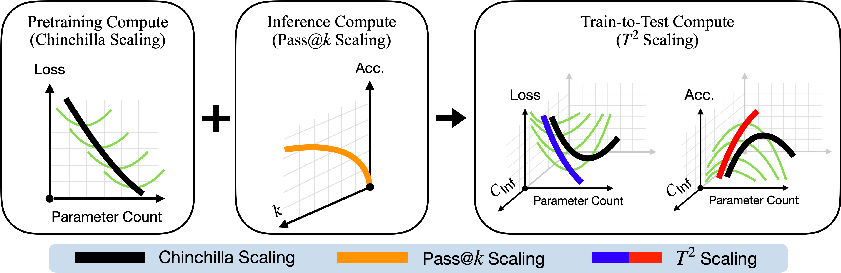
The authors introduce Train-to-Test (T²) scaling laws. These are simple rules of thumb that tell you how big your model should be, how long to train it, and how many attempts to make per question at test time—so you get the best results for a fixed amount of “compute budget” (the total computer power you’re willing to spend). Their surprise: when you plan to try multiple samples at test time, it’s better to train a smaller model for longer than the usual advice suggests. That’s called “overtraining” relative to older rules, and the paper shows why it’s a good idea in modern deployments.
What the researchers wanted to find out
- If you know you’ll use repeated attempts at test time (often called “test-time scaling”), should you change how you train your model?
- Can we build a single recipe that chooses:
- model size (how many parameters),
- how many training tokens (how long to train),
- and how many test-time attempts (how many tries per question),
- all under one overall compute budget?
- Do these recommendations still work when the model gets “post-trained” (fine-tuned) for specific tasks?
How they approached it (in everyday terms)
Think of compute as your allowance:
- Training allowance: how much you spend making the model smart (longer training and/or bigger model).
- Testing allowance: how much you spend when the model answers questions later (more tries cost more).
Two key ideas make this work:
- Test-time scaling with repeated attempts
- “pass@k” is the chance you get at least one correct answer if you try k times.
- Small models are cheaper per try, so you can afford more tries; big models are better per try but more expensive, so you can afford fewer tries. There’s a trade-off.
- A joint plan (T²): Optimize training and testing together
- Instead of choosing training settings in isolation (like older “Chinchilla” rules that balance model size and data), T² also plans how many attempts you’ll use at test time.
- The team created two complementary prediction models:
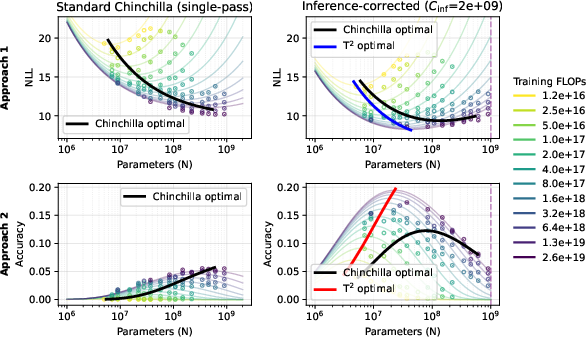
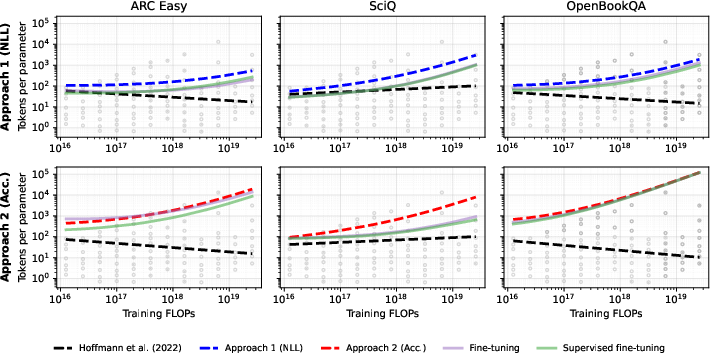
- Approach 1: Model “mistakes” (loss) directly and add how multiple tries reduce mistakes.
- Approach 2: Model “accuracy” (how often you’re right) directly, using a simple statistical model of question difficulty. Then compute pass@k from that.
- Both approaches aim to pick the best combination of model size, training length, and number of test-time tries given fixed training and testing budgets.
What they tested
- They trained and evaluated over 100 small models (under 1B parameters) across a wide range of training lengths.
- They checked performance on 8 tasks (some real, some synthetic) that measure knowledge and reasoning.
- They also tried post-training (fine-tuning) to see if recommendations still hold.
What they discovered and why it matters
Here are the main findings:
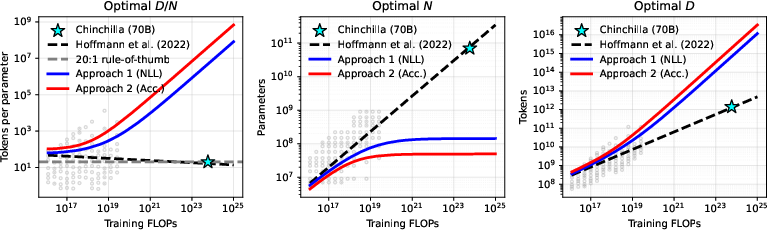
- Overtraining is optimal when you plan to use multiple test-time attempts Instead of the older rule-of-thumb (balance model size and data in a certain ratio), T² says: train a smaller model for longer and plan to use more attempts at test time. This gives better results for the same overall compute budget.
- Smaller, cheaper models with more tries can beat larger models Because each try on a small model costs less, you can afford many tries. Those extra attempts dramatically raise the chance that at least one answer is correct.
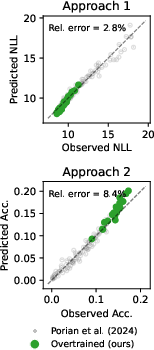
- The forecasts work in practice They trained “overtrained” models exactly where T² said they’d be best—and those models outperformed the standard Chinchilla-style models under the same total budget.
- The effect survives post-training Even after fine-tuning for specific tasks, smaller overtrained models with more test-time attempts still came out ahead.
Why this matters: This connects how you train a model with how you plan to use it. If you know you’ll rely on multiple attempts (which many modern systems do for tough problems), you shouldn’t follow the old “one-try” training recipe. Instead, you should:
- build a smaller model,
- train it longer (more data, more steps),
- and use more tries per question at test time.
This can save money at deployment while improving accuracy.
Simple takeaway and impact
- If your model will answer tough questions and you can afford multiple attempts per query, the best overall strategy is to train a smaller model for longer and use those extra tries at test time.
- T² gives a blueprint to pick the right model size, training length, and number of test-time attempts under fixed budgets.
- This helps teams release “families” of models that are cheaper to run but still strong when used with test-time scaling—useful for research assistants, coding helpers, or any system where multiple samples are acceptable.
- In short: plan training and testing together, not separately. Doing so makes “overtraining” the smart, compute-efficient choice in many real-world deployments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow‑up work:
- Dependence assumptions in repeated sampling: The analysis assumes i.i.d. samples for pass@ gains; real decoding often produces correlated samples (e.g., with nucleus/temperature settings), which can materially reduce pass@ returns. Quantifying and modeling correlation effects and diversity-inducing decoding policies is left open.
- Verification and selection costs omitted: The framework counts only sampling cost (2Nk) and not the compute to detect a “correct” sample (e.g., unit tests for code, math verifiers, reward models, rerankers). Incorporating verifier cost, accuracy, and failure modes into the end‑to‑end budget could shift optima.
- Continuous k vs. discrete deployment: The optimization treats k via k = C_inf/(2N) and uses it continuously; practical deployments require integer k, early-stopping upon first success, and adaptive halting. Modeling the expected “time to first success” and integer/early-stopping effects is not addressed.
- Cost model oversimplification: Training and inference costs are fixed at 6ND and 2N FLOPs per token, respectively. These abstractions ignore sequence length, prefill vs. decode phases, KV‑cache costs, memory bandwidth/latency, batching, quantization, sparsity/MoE, and hardware effects. A more realistic, transformer‑aware cost model (noted as future work) remains to be developed and validated.
- Sequence length and output length not modeled: Inference costs scale with context and generated length; pass@ typically lengthens outputs (e.g., chain‑of‑thought). The current analysis normalizes per-token but does not couple compute to variable sequence lengths across tasks and strategies.
- Data quality and mixture effects excluded: All training uses RefinedWeb; the framework does not model the impact of curation, deduplication, contamination, domain mix, or curriculum on scaling exponents and overtraining benefits. Extending to data quality/mixture variables is open.
- Generalization beyond small models: All experiments are <1B parameters; whether the strong overtraining recommendations persist at 10B–>100B scales (where scaling exponents can shift) is untested.
- Limited task coverage and evaluation form: The eight tasks (four real, four synthetic) are short‑answer QA/cloze style. Generalization to long‑form generation, code, math, reasoning with verifiers, tool use, and multi-step pipelines is not evaluated.
- Mapping from loss to accuracy is task‑specific: The loss→accuracy link relies on a fitted sigmoid and Beta regression. Stability of this mapping across diverse tasks, distributions, and larger models—and under domain shift—remains uncertain.
- Beta distribution assumption for per‑item accuracies: The accuracy‑based approach assumes per‑question success probabilities follow a Beta family. Assessing robustness to mis‑specification (e.g., multimodal or heavy‑tailed difficulty distributions) is left open.
- Independence of pretraining and test-time mechanisms: The framework optimizes N, D, k, but not decoding strategies (e.g., temperature, top‑p, self‑consistency variants) that interact with k. Jointly optimizing k and decoding policy is unaddressed.
- Adaptive per‑instance allocation not modeled: The analysis fixes a global k per model size; it does not consider dynamic allocation of k across inputs based on estimated difficulty or early signals—an avenue likely to improve compute efficiency.
- Post‑training scope is narrow: Only FT and SFT are studied; modern deployments use instruction tuning, DPO, RLHF/RLAIF, and verifier‑augmented training. How these alter optima and overtraining recommendations is an open question.
- Overtraining side effects unmeasured: Heavily overtraining on limited data may increase memorization, privacy leakage, calibration drift, and brittleness. The paper does not quantify such risks or their trade‑offs with pass@ gains.
- Budget integration across stages: Post‑training compute is not included in the joint budget. A complete budgeted framework that includes pretraining, post‑training, and inference (with verifiers) is missing.
- Deployment constraints beyond FLOPs: Latency SLAs, memory footprint, batching efficiency, and throughput targets are not modeled. Translating FLOP‑optimal recommendations to real system‑optimal choices remains open.
- Rounding and granularity of optimal N and D: The optimization yields continuous solutions; constraints such as tensor‑parallel sizes, memory tiers, or data availability (epochs over finite corpora) may force discrete choices. Sensitivity to such constraints is not analyzed.
- Robustness and uncertainty quantification: The fits report point estimates; confidence intervals over forecasts, sensitivity to seed variance, and model misspecification diagnostics are not provided.
- Interaction with chain‑of‑thought and longer reasoning traces: Repeated sampling often coincides with CoT/self‑consistency, which changes both per‑sample success probabilities and per‑sample compute. Joint modeling of trace length, correctness, and cost is left for future work.
- Retrieval and tool use left out: Test‑time strategies like RAG, external tools, and program execution alter cost and accuracy scaling. Extending to include retrieval/tool costs and benefits is unexplored.
- Safety and alignment outcomes: The effect of overtraining and heavy sampling on toxicity, hallucination control, and alignment after post‑training is not studied.
- Cross‑family/model‑arch generality: Results are based on a single architecture family; applicability to MoE, state‑space models, speculative decoding, and other accelerations is untested.
- Heterogeneous workload mixtures: The paper macro‑averages tasks; real deployments serve mixed workloads with different k, latency, and verifier availability. Optimizing under workload distributions remains open.
- Economic and operational costs: FLOP budgets ignore energy, cloud pricing, GPU memory rentals, and engineering overhead (e.g., verifier development). Incorporating economic cost models into is future work.
- Fairness and bias considerations: How overtraining and repeated sampling affect subgroup performance and bias is unexamined.
- Data reuse vs. fresh data: Overtraining implies multiple epochs over the same data; the trade‑off between more epochs and acquiring more (or better) data is not modeled.
- Rounding errors in pass@ estimation and metric choice: pass@ may be sensitive to small changes in p; alternative utility‑based metrics (e.g., expected maximum reward with verifiers) could shift recommendations. Exploring metric choice is open.
Practical Applications
Overview
This paper introduces Train-to-Test (T²) scaling laws that jointly optimize model size (N), training tokens (D), and test-time sampling (k) under end-to-end compute constraints. The key practical insight is that, when deployment will use repeated sampling (pass@k), the compute-optimal strategy is to train smaller, more overtrained models and allocate more inference samples to them. The authors provide two robust formulations (loss-based and accuracy-based) and validate them across tasks, overtrained checkpoints, and post-training. Below are actionable applications and their feasibility considerations.
Immediate Applications
The following can be piloted or deployed now using existing LLMs, infrastructure, and workflows.
- Training/inference budget planner (“T² calculator”) for model developers
- Sectors: software/AI, cloud, MLOps, finance (FP&A for AI projects)
- Tools/products/workflows: a dashboard or Python library that, given target tasks, training compute C_train and per-query inference budget C_inf, outputs compute-optimal tuples (N, D, k); integrates with experiment trackers (e.g., Weights & Biases), and cloud cost estimators
- Dependencies/assumptions: needs task-specific fits for the T² parameters; uses FLOP models (≈6ND for training, ≈2Nk for inference); assumes sampling temperature/prompting are fixed during optimization; requires representative validation data to fit pass@k curves
- Model family design with overtrained small variants for sampling-heavy workloads
- Sectors: AI labs, model vendors, open source model maintainers
- Tools/products/workflows: release “overtrained-small” checkpoints alongside standard sizes; publish recommended pass@k curves and k-to-latency tables; provide recipes (tokens-per-parameter, learning rate schedules) for overtraining
- Dependencies/assumptions: longer training runs and data pipelines; may need modified post-training hyperparameters because overtrained bases are harder to fine-tune; benefits largest when customers will use repeated sampling
- Inference orchestrator that enforces per-query compute budgets by adapting k = C_inf/(2N)
- Sectors: inference platforms, MLOps, dev tooling
- Tools/products/workflows: middleware that reads model N and sets k automatically per request; configurable latency/quality SLAs; integrates with speculative decoding, batching, and sample-parallel decoding
- Dependencies/assumptions: independent (or low-correlation) samples; stable sampler settings; latency/UX tolerance for higher k on smaller models
- Code generation with sample-and-verify under fixed compute
- Sectors: software engineering, CI/CD, enterprise developer tools
- Tools/products/workflows: IDE plugins/CI jobs that draw many samples from a small overtrained model, run tests/linters/fuzzers, and select the first passing solution; cost-equivalent alternatives to using a single large model
- Dependencies/assumptions: availability of verifiers/tests; pass@k gains hold for the code domain; sample diversity (controlled via temperature/top-p) is maintained
- Evidence-based content and safety review via multi-sample routing
- Sectors: trust & safety, legal, healthcare documentation, finance compliance
- Tools/products/workflows: multiple generations with verifiers (retrievers, citation checkers, rule-based filters); choose best-supported output; log C_inf allocation for audits
- Dependencies/assumptions: reliable verifiers; clear escalation policies when samples disagree; regulatory constraints on automated decision support
- Post-training practice updates for overtrained bases
- Sectors: LLM providers, applied ML teams
- Tools/products/workflows: adjust SFT/FT schedules (learning rates, patience, batch sizes) for overtrained bases; monitor calibration and overfitting; fine-tune fewer steps but to convergence
- Dependencies/assumptions: overtrained models are somewhat harder to fine-tune; requires task-specific monitoring and early-stopping criteria
- A/B testing protocols that compare (N, D, k) triads under equalized end-to-end compute
- Sectors: product analytics, applied research
- Tools/products/workflows: experiment templates ensuring equal C_train and C_inf across arms; report pass@k and latency; evaluate cost-per-solved-instance
- Dependencies/assumptions: consistent datasets/prompts; identical decoding settings except for k; compute accounting rigor
- Cost and capacity planning that rebalances training vs serving spend
- Sectors: finance/procurement, cloud customers, cloud providers
- Tools/products/workflows: spreadsheets or tooling to choose spend fractions on training longer small models vs serving with more samples; COGS modeling for SKU/pricing teams
- Dependencies/assumptions: stable unit costs per FLOP; realistic utilization and latency targets; expected query volume and difficulty distribution
- Edge and on-device assistants using overtrained small models plus repeated sampling
- Sectors: mobile, embedded, offline productivity tools
- Tools/products/workflows: local assistants that run k>1 samples per query within battery/latency limits; use verifiers or preference scoring to select outputs
- Dependencies/assumptions: device energy/thermal budgets; fast decoding kernels; small models fine-tuned for target tasks; user accepts slightly higher latency for higher reliability
- Reporting practices for benchmarks to include pass@k and inference budgets
- Sectors: academia, evaluation platforms, open-source leaderboards
- Tools/products/workflows: standardize reports with pass@k curves vs C_inf, not only single-pass accuracy; provide fitted T² parameters per task
- Dependencies/assumptions: access to raw per-problem success probabilities or sufficient samples; community buy-in on metrics
Long-Term Applications
These require further research, scaling, or development (e.g., new hardware/software, standards, or larger-scale validations).
- AutoML for compute-aware co-design of N, D, and k per task and per user segment
- Sectors: AI platforms, enterprise ML
- Tools/products/workflows: end-to-end search that chooses base model size, train tokens, and adaptive test-time sampling policies given SLAs (latency, cost, accuracy)
- Dependencies/assumptions: reliable task-specific T² fits; automated difficulty estimation; budgeted hyperparameter optimization
- Dynamic k controllers that adapt per-query using uncertainty/difficulty signals
- Sectors: inference platforms, search/assistants, code tools
- Tools/products/workflows: controllers that allocate higher k when confidence is low (e.g., entropy, verifier disagreement), and save compute on easy queries
- Dependencies/assumptions: calibrated uncertainty estimates; fast online difficulty predictors; policy constraints to avoid latency spikes
- Hardware–software co-design optimized for high-k sampling regimes
- Sectors: GPU/ASIC vendors, cloud providers, inference engines
- Tools/products/workflows: sample-parallel decoding kernels, KV-cache reuse across samples, scheduler support for many short generations; memory layouts to maximize throughput
- Dependencies/assumptions: architectural support for concurrent sampling; batching strategies that preserve sample independence/diversity
- Pricing and SLAs based on per-query compute budgets (C_inf) and pass@k tiers
- Sectors: cloud/SaaS, API providers
- Tools/products/workflows: plans that guarantee pass@k performance targets for a given C_inf; customers choose quality/latency/cost bundles
- Dependencies/assumptions: stable mapping from C_inf to pass@k for target workloads; transparent compute accounting
- Regulatory and sustainability standards that include test-time compute
- Sectors: policy, sustainability, ESG reporting
- Tools/products/workflows: disclosure of C_train and C_inf, model families’ pass@k profiles, emissions per solved instance; guidelines for public sector procurement
- Dependencies/assumptions: accepted FLOP-to-emissions conversion; standardized reporting formats; third-party audits
- Education: AI tutors that sample multiple explanations and self-grade
- Sectors: edtech
- Tools/products/workflows: generate k explanations/solutions, score with task rubrics/graders, return best; allocate more samples for hard problems
- Dependencies/assumptions: robust graders; guardrails for pedagogy and bias; latency tolerance in interactive settings
- Healthcare/clinical decision support using sample-and-verify
- Sectors: healthcare, life sciences
- Tools/products/workflows: produce multiple differential diagnoses or care plans, cross-check against guidelines/knowledge bases, escalate uncertainty
- Dependencies/assumptions: stringent verification; prospective clinical validation; adherence to regulation (HIPAA, MDR); human oversight; high-stakes risk management
- Robotics and planning with proposal sampling
- Sectors: robotics, logistics, autonomy
- Tools/products/workflows: small overtrained policy/planning models that sample k candidate action sequences; safety and feasibility filters select outputs
- Dependencies/assumptions: real-time constraints; reliable validators/simulators; robust sampling diversity
- Data strategy for the overtraining regime (tokens-per-parameter >> 20)
- Sectors: data platforms, web-scale curation, synthetic data providers
- Tools/products/workflows: pipelines to supply many more high-quality tokens per parameter; synthetic data generation and filtering tuned for overtraining
- Dependencies/assumptions: data quality scaling remains beneficial at high tokens-per-parameter; deduplication and contamination control
- Cross-modal T² extensions (vision, multimodal assistants, AV perception)
- Sectors: multimodal AI, automotive, retail
- Tools/products/workflows: pass@k-aware training and deployment for image/video/vision-LLMs; sampling multiple captions/plans/detections and verifying
- Dependencies/assumptions: task-appropriate pass@k analogs and verifiers; domain-specific FLOP models for inference cost
- Carbon-aware scheduling that jointly optimizes C_train and C_inf over time
- Sectors: data centers, sustainability operations
- Tools/products/workflows: schedulers that shift high-k workloads to low-carbon windows; dashboards showing emissions per solved task
- Dependencies/assumptions: accurate energy telemetry; flexible SLAs to shift compute; integration with power market signals
- Public benchmarks and leaderboards for T² optimization
- Sectors: academia, evaluation ecosystems
- Tools/products/workflows: standardized task suites reporting compute-optimal (N, D, k), plus efficiency metrics like cost-per-solved
- Dependencies/assumptions: broad community adoption; reproducible compute accounting; open access to fitted parameters
Notes on Assumptions and Dependencies
- Statistical modeling: Accuracy-based T² assumes per-item success probabilities are well-approximated by a Beta distribution; both approaches assume power-law relationships similar to Chinchilla.
- Compute accounting: Uses simplified FLOP models (≈6ND for training; ≈2Nk per token for inference); real systems may have overheads (KV cache, attention, context length, memory bandwidth).
- Sampling independence and diversity: Pass@k benefits depend on reasonably independent/diverse samples (temperature/top-p tuning, anti-collapse measures).
- Task and domain variability: Fitted parameters are task-dependent; gains are strongest where pass@k curves improve sharply with k.
- Post-training: Overtrained bases can be harder to fine-tune; careful FT/SFT hyperparameters and monitoring help.
- Latency/UX: High k increases latency; some applications need dynamic k controllers or parallelization to meet SLAs.
- Verification availability: Sample-and-verify pipelines rely on domain-appropriate verifiers (tests, retrieval, graders, formal checks).
Glossary
- Beta distribution: A continuous probability distribution on [0,1] often used to model variability in success probabilities across items or tasks. "the task difficulty distribution can be modeled by a Beta distribution"
- Beta function: A special function related to the Gamma function, used to compute expectations with Beta-distributed variables. "is the Beta function, where is the Gamma function."
- Beta regression: A regression framework for modeling variables in (0,1) using parameterized mean and precision (sample size) with link functions. "which we model as a Beta regression problem."
- Chinchilla scaling law: An empirical law prescribing compute-optimal trade-offs between model size and training tokens for minimizing language modeling loss. "The Chinchilla scaling law~\citep{hoffmann2022training} models the pretraining loss as a function of finite model capacity and dataset size "
- compute-optimal: Achieving the best performance for a fixed amount of compute by allocating resources (parameters, tokens) optimally. "compute-optimal training recipes"
- fine-tuning (FT): Post-training adaptation of a pretrained model on a task-specific dataset by continuing gradient-based training. "We explore two canonical post-training techniques: standard fine-tuning (FT) and supervised fine-tuning (SFT)"
- FLOPs: Floating point operations, a standard unit to measure computational cost for training or inference. "measured as the inference FLOPs per-token served."
- forward pass: The computation of model outputs from inputs without parameter updates; its FLOPs scale roughly with parameter count. "approximately $2N$ FLOPs for a forward pass"
- frontier LLMs: The most advanced LLMs at the leading edge of capability. "as frontier LLMs are post-trained"
- hero run: A flagship or best-effort training run used as a prominent reference point in scaling analyses. "the 70B Chinchilla hero run model"
- inference budget: The compute allocated per query or per token at deployment time for sampling or reasoning. "we can choose an inference budget $C_{\text{inf}$"
- inference-corrected: Accounting for inference-time compute (e.g., repeated sampling cost) when comparing or optimizing models. "When inference-corrected, we see that the Chinchilla optimal frontier exhibits non-monotonic improvement"
- irreducible loss: The asymptotic loss floor that cannot be reduced by increasing model size, data, or samples. "approaches the `irreducible loss' term ."
- isoFLOP: A curve or set of configurations that share the same total compute (FLOPs), used to compare trade-offs of N, D, and k. "Each of the 12 isoFLOP curves traces out a fixed pretraining budget "
- Jensen's inequality: A mathematical inequality used here to justify an upper-bounding surrogate objective for negative log pass@k. "By Jensen's inequality, our NLL-style objective acts as an upper-bounding surrogate"
- link function: A transformation mapping predictors to distribution parameters in generalized regression (e.g., logit or log). "using standard link functions from Beta regression"
- logit link: The logistic transform used as a link function to model means constrained to (0,1). "a logit link for the mean (which we rescale with an additional parameter), and a log link for the sample size."
- negative log-likelihood (NLL): A loss measuring how well the model predicts data; lower NLL indicates better fit. "the loss is assumed to be the negative log-likelihood (NLL) over the data distribution"
- overtraining: Training with many more tokens per parameter than standard compute-optimal recommendations (e.g., Chinchilla), often to reduce inference cost via test-time scaling. "into the overtraining regime"
- pass@: The probability of obtaining at least one correct output when sampling k independent outputs. "pass@---the probability of producing at least one correct answer in independent attempts."
- pass@ estimator: A modeling component that predicts pass@k by composing single-pass accuracy with the k-sample success computation. "by composing Chinchilla scaling with a pass@ estimator."
- post-training: Additional training stages after pretraining (e.g., FT or SFT) to adapt the base model to specific tasks or behaviors. "we show that our findings survive the post-training stage"
- power law scaling: A relationship where performance or loss changes proportionally to a parameter raised to a power, common in scaling laws. "yields power law scaling"
- pretraining scaling laws: Empirical laws describing how performance or loss scales with model size and data during pretraining. "Pretraining scaling laws tell us how to optimally train LLMs"
- repeated sampling: Drawing multiple independent outputs from a model at test time to boost the chance of a correct answer. "via repeated sampling"
- supervised fine-tuning (SFT): Fine-tuning using labeled input–output pairs, often focusing on targets only. "supervised fine-tuning (SFT)"
- test-time scaling: Allocating additional computation during inference (e.g., multiple samples or longer reasoning) to improve results. "Test-time scaling laws tell us how to optimally allocate compute at deployment"
- tokens per parameter: A ratio indicating data exposure relative to model size; higher values imply longer training per parameter. "the 20 tokens per parameter rule of thumb used by practitioners"
- Train-to-Test () scaling laws: A framework jointly optimizing model size, training tokens, and number of inference samples under training and inference budgets. "We propose Train-to-Test () scaling laws"
- upper-bounding surrogate: An objective function that upper-bounds the true objective, used for tractable optimization or analysis. "acts as an upper-bounding surrogate"
Collections
Sign up for free to add this paper to one or more collections.