Revisiting the Scaling Properties of Downstream Metrics in Large Language Model Training
Abstract: While scaling laws for LLMs traditionally focus on proxy metrics like pretraining loss, predicting downstream task performance has been considered unreliable. This paper challenges that view by proposing a direct framework to model the scaling of benchmark performance from the training budget. We find that for a fixed token-to-parameter ratio, a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks. Our results show that the direct approach extrapolates better than the previously proposed two-stage procedure, which is prone to compounding errors. Furthermore, we introduce functional forms that predict accuracy across token-to-parameter ratios and account for inference compute under repeated sampling. We validate our findings on models with up to 17B parameters trained on up to 350B tokens across two dataset mixtures. To support reproducibility and encourage future research, we release the complete set of pretraining losses and downstream evaluation results.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: If you spend more training “fuel” (compute) on a LLM, how much better will it get on real tests like math problems, general knowledge quizzes, and coding tasks? The authors show that you can predict a model’s test scores directly from how much training compute you give it, using a very simple rule. They also show this direct method predicts better than older, more complicated methods.
What were the researchers trying to find out?
They focused on five plain-language goals:
- Can we predict a model’s accuracy on popular benchmarks straight from the training budget (how much compute it used)?
- Is there a simple, reliable pattern (a “scaling law”) that connects compute to accuracy?
- Does this pattern still hold when we change how much data the model reads per parameter (the token-to-parameter ratio)?
- Can we also predict coding “pass@k” scores, where the model is allowed multiple attempts?
- Is this “direct” prediction better than the older “two-stage” approach that first predicts a proxy (like loss) and then turns that into accuracy?
How did they study it?
The team ran a lot of careful experiments and then fit simple curves to the results.
Here are the key ideas explained in everyday terms:
- Compute (training FLOPs): Think of this like the total number of calculator steps the model uses while learning. More FLOPs = more practice.
- Tokens and parameters: Tokens are chunks of text the model reads; parameters are like the model’s “brain cells.” The token-to-parameter ratio (TPR) is “how much reading per unit of brain.” They tested several TPRs.
- Benchmarks: These are tests like multiple-choice science questions, story completion, math word problems, and coding challenges. Examples include ARC, HellaSwag, LAMBADA, GSM8K, and HumanEval.
- Direct vs two-stage prediction:
- Two-stage (old way): First predict a proxy (like loss or negative log-likelihood), then convert that to accuracy. This can stack errors from each step.
- Direct (this paper’s way): Skip the detour. Fit a simple curve that maps training compute directly to accuracy.
What they actually fit:
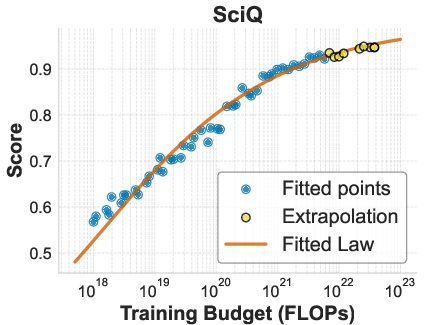
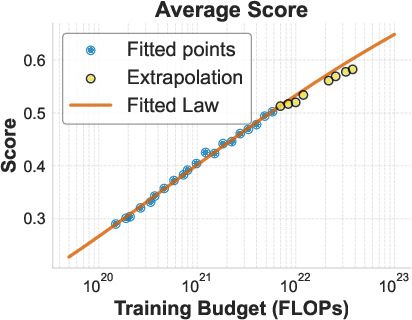
- For fixed TPR, they found a simple pattern: as compute increases, “how far you are from perfect” shrinks smoothly. In math-speak, the negative log of accuracy follows a power law with compute. You don’t need to understand the formula; the point is the curve is simple and predictable.
- Across different TPRs, they extended the same idea: “how far from perfect” depends on both model size (parameters) and data size (tokens) in a similarly simple way.
- For coding pass@k (letting the model try k different solutions), they modeled how success improves when you allow more attempts and how that interacts with training compute.
They validated these ideas on:
- Up to 130+ runs,
- Models up to 17 billion parameters,
- Up to 350 billion training tokens,
- Two different pretraining datasets (one modern mixture including web, math, and code; and C4).
What did they discover, and why is it important?
Main findings:
- A simple law predicts accuracy directly from training compute. When the token-to-parameter ratio is fixed, accuracy follows a smooth, simple pattern as you scale compute. No fancy tricks required.
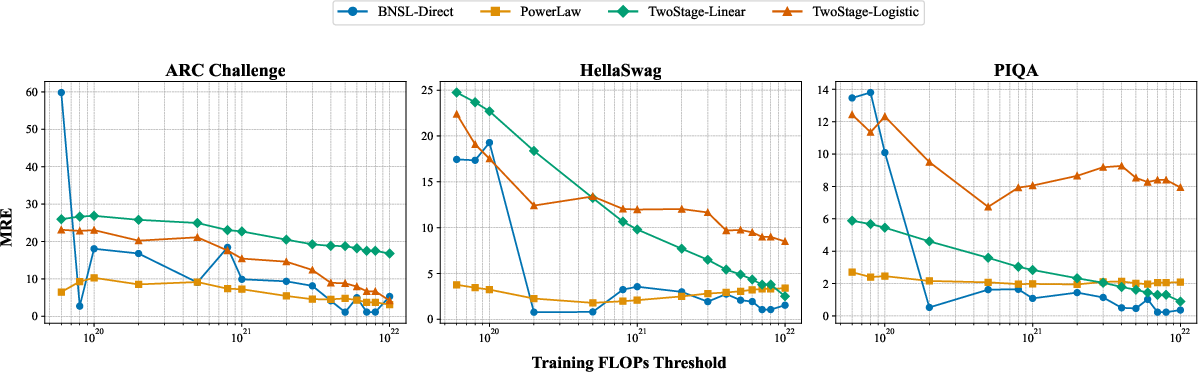
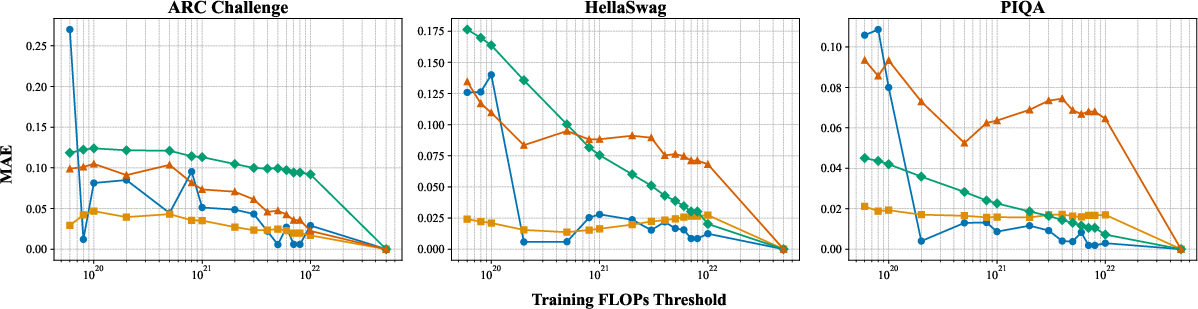
- This direct approach predicts better than the two-stage approach. The older method compounds errors because it takes two steps (compute → proxy → accuracy). The direct path is simpler and more accurate when extrapolating to bigger models.
- The law generalizes across token-to-parameter ratios. They provide a formula that works when you vary model size and data size.
- For coding tasks, pass@k (more tries) follows a predictable pattern too. The model shows how training compute and the number of tries trade off.
- Data matters. When they trained only on C4 (which lacks much code and math), scaling stayed predictable for general language tasks but code and math scores fell toward chance. In other words, scaling patterns hold, but the ceiling you can reach depends on what you train on.
Why this matters:
- Planning: Teams can estimate how much compute they need to reach a target accuracy before spending a lot of money.
- Simplicity: You don’t need complex, two-step predictions. A single, well-fit curve often does better.
- Broader coverage: The method works not just for multiple-choice but also for exact-match, reasoning with chain-of-thought, and coding pass rates.
What could this change or enable?
- Smarter budgeting: Organizations can plan training runs more confidently, aiming for desired scores without over- or under-spending.
- Better trade-offs: For coding, you can weigh training compute (make the model better) versus inference compute (let it try more times) to hit a pass-rate goal.
- Faster iteration: Because the curves are simple, smaller experiments can guide bigger ones.
- Clearer reporting: The paper offers a direct, repeatable recipe for predicting accuracy from compute, plus public results to help others build on it.
Limits and what’s next
The authors are careful about where their findings apply:
- Metric quirks: Some benchmarks have thresholds or noisy labels, which can create bumps in the curves. They provide ways to handle random-guess floors and discuss imperfect labels.
- Data mixture: Results depend on the kind of pretraining data. If you don’t train on code, don’t expect strong code results—even if compute scales nicely.
- Scale thresholds: Very small models can be too noisy; predictions become reliable after a size/compute “threshold.”
- Training recipe and beyond: They tested standard decoder-only Transformers with a modern setup. Different model types (like mixture-of-experts or retrieval-augmented) might need re-checking. Also, later steps like instruction tuning or preference optimization can change scores.
The takeaway
Bigger models trained with more compute don’t just get better—they get better in a predictable way that you can describe with a simple curve. Predicting real test accuracy directly from training compute works well, often better than older two-step methods. That makes training LLMs more like careful engineering and less like guesswork.
Knowledge Gaps
Below is a single, action-oriented list of the paper’s unresolved knowledge gaps, limitations, and open questions.
- Mechanistic basis: The paper lacks a theoretical account of why negative log accuracy should follow a simple power law in training compute; connecting aggregate trends to per-item difficulty distributions (e.g., via item response theory or error-decay models) remains open.
- Ceiling effects: The main scaling forms omit irreducible error terms; a systematic estimation of benchmark-specific accuracy ceilings (label noise, ambiguity) and incorporation into the primary fits is not provided.
- Interaction of parameters and data: The additive form −log Q = A/Nα + B/Dβ assumes no interactions; testing multiplicative or cross terms (e.g., N–D coupling) and assessing whether the additive decomposition holds universally is unresolved.
- Frontier scales: Generalization beyond the studied regime (≤17B parameters, ≤350B tokens, ≤6.7× extrapolation) to frontier models (e.g., 70B–400B, >1T tokens) is unverified.
- Architecture and training recipe scope: Results are limited to decoder-only Transformers with a fixed optimizer/schedule; scaling behavior for MoE, retrieval-augmented, multimodal models, different activations/positional embeddings, optimizers, and schedules is unknown.
- Data-mixture dependence: While C4 vs. mixture was contrasted, a systematic study mapping mixture composition (and filtering choices) to scaling exponents across domain-specific tasks (math/code/general QA) is missing.
- Contamination assessment: The paper does not quantify training–evaluation overlap; the impact of benchmark contamination on scaling fits and extrapolations is unexplored.
- Prompting and evaluation sensitivity: The robustness of exponents to prompt templates, shot counts, chain-of-thought vs. direct prompting, context length, and decoding hyperparameters (temperature, top-p) has not been measured.
- Seed variance and uncertainty: Fits are presented without replicate runs or calibrated prediction intervals; quantifying across-seed variance, checkpoint variance, and providing confidence bands for extrapolations is an open need.
- Early-scale thresholds: A principled method to detect and report task-specific FLOPs thresholds at which fits become reliable (and the probability of success vs. threshold) is not provided.
- Random baseline estimation: For multiple-choice tasks, random accuracy is estimated from small models rather than task structure; robustness of normalization to this choice and to class imbalance or varying option counts is not assessed.
- Saturation behavior: As accuracy approaches 1, the proposed forms may misbehave; testing saturating variants and identifying when simple power laws break near the ceiling is left open.
- Per-item heterogeneity: Aggregate smoothness can mask item-level non-monotonicities; modeling example-level scaling slopes, clustering items by difficulty, and explaining benchmark-dependent S-shapes is not attempted.
- Pass@k independence and diversity: The pass@k model assumes effective independence of samples and uses a C–k interaction term; the role of sample correlation/duplication and diversity-promoting decoding on pass@k scaling is not analyzed.
- Inference vs. training compute trade-offs: A formal Pareto analysis quantifying optimal allocations between training FLOPs and inference sampling (k, decoding settings) for code tasks is not provided.
- Cross-lingual and non-English tasks: Applicability of the scaling laws to multilingual pretraining/evaluation and to non-English benchmarks is untested.
- Shot count scaling: Beyond WebQS 1-shot, how accuracy scales with shots (0-shot vs. k-shot) across tasks and whether exponents shift with shot count remains unexamined.
- Context length effects: The impact of longer context windows (beyond 4k) on scaling exponents and downstream accuracy (e.g., long-form QA, code) is not studied.
- Tokenizer and vocabulary: The tokenizer (150k vocab) is fixed; sensitivity of scaling exponents to tokenization choices (vocab size, byte-level vs. subword) is unknown.
- Error propagation analysis: While two-stage methods are empirically weaker, a formal treatment of error compounding (FLOPs→proxy→accuracy) and potential corrections or hybrid direct–proxy approaches is not developed.
- Compute accounting: The definition and measurement of training FLOPs (e.g., optimizer overheads, activation recompute, hardware differences) and their effect on fitted exponents are not audited.
- Post-pretraining effects: The influence of continued pretraining, instruction tuning, preference optimization/RLHF, or domain-specific finetuning on downstream scaling laws is not characterized.
Practical Applications
Below are practical, real-world applications that follow directly from the paper’s findings and methods. Each item describes the use case, relevant sectors, potential tools/workflows/products, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Predictive capability planning from small “ladder” runs
- What: Fit the proposed direct scaling law on a handful of small training runs to forecast downstream accuracy at target compute budgets.
- Sectors: software, finance, healthcare, education, robotics, energy (anywhere LLMs are trained/fine-tuned at scale)
- Tools/products/workflows: “Scaling Forecaster” dashboard (plugin for MLflow/Weights & Biases); internal MLOps template that automates Huber/L-BFGS-B fitting on checkpoints; budget-to-capability calculators for PMs
- Assumptions/dependencies: Decoder-only Transformer recipe and evaluation setup comparable to paper; fixed or known token-to-parameter ratio (or use the N–D extension); measurements taken beyond FLOPs thresholds where predictability stabilizes; benchmark prompts and harness consistent over time
- Token-to-parameter (TPR) planning and trade-off optimization
- What: Use the N–D scaling extension (-log Q = A/Nα + B/Dβ) to choose parameter count vs. token count that meets an accuracy target at minimal cost.
- Sectors: software, energy, finance (cost/carbon-aware training), cloud platforms
- Tools/products/workflows: “TPR Optimizer” that recommends N, D given compute, cost, or emissions constraints; early-stopping criteria when further tokens yield diminishing returns
- Assumptions/dependencies: The fitted exponents are recipe- and data-mixture-dependent; changes to optimizer/schedule or architectural shifts (e.g., MoE, retrieval) may require re-fitting
- Inference compute policy for code generation (pass@k planner)
- What: Use the pass@k scaling form to set task-specific sampling budgets (k) that minimize inference cost while preserving pass rates.
- Sectors: software engineering, developer tooling, DevOps
- Tools/products/workflows: “Pass@k Planner” that selects k per repository/file/difficulty tier; CI/CD policy that raises k only when estimated train-side capability is insufficient; dynamic sampling budget tied to predicted failure probability
- Assumptions/dependencies: Pass@k scaling fit must be calibrated per code benchmark and model family; interaction term δ (compute × k) can vary by domain/task; reliable unit tests are needed to validate gains
- Budgeting, ROI, and capability roadmapping
- What: Translate target benchmark accuracy (e.g., GSM8K, HellaSwag, HumanEval) into required FLOPs and cost; justify investment stages and product timelines using predicted accuracy deltas per x× compute.
- Sectors: finance, enterprise software, startups, cloud providers
- Tools/products/workflows: “Compute-to-Capability” ROI calculators; investment gates that trigger larger runs only after ladder-run fits cross pre-defined confidence thresholds
- Assumptions/dependencies: Cost/revenue models are outside the scaling law; forecast uncertainty should be reported (e.g., bootstrap intervals)
- Data mixture gating and risk control
- What: Run small-scale experiments across candidate pretraining mixtures and fit the direct law to quickly identify mixtures that will win at larger scales (especially for specific benchmarks/skills).
- Sectors: data vendors, software, applied research labs
- Tools/products/workflows: Lightweight “mixture sweep” protocol; early-stop rules when mixture scaling curves underperform; mixture-aware capability dashboards
- Assumptions/dependencies: Mixture effects are strong; extrapolation beyond tested mixtures can degrade; evaluation must reflect intended downstream domains
- Benchmark normalization and metric audits for fair comparisons
- What: Apply random-baseline normalization and (where needed) an irreducible-accuracy ceiling to avoid misleading scaling fits on multiple-choice or noisy/ambiguous datasets.
- Sectors: academia, model evaluation platforms, standardization bodies, industry eval teams
- Tools/products/workflows: “Benchmark Audit” scripts that estimate Q_random from small runs; label-noise audits; standardized reporting of normalized accuracy
- Assumptions/dependencies: Stable prompts and harness; labeling noise estimation may require additional annotation or statistical modeling
- Training governance protocols and reporting standards
- What: Adopt the paper’s diagnostics (FLOPs thresholds, hold-out validation, error metrics) in model cards and internal reviews to improve reproducibility and risk management.
- Sectors: policy, compliance, industry labs, standards bodies
- Tools/products/workflows: Internal SOPs mandating FLOPs-threshold reporting; capability forecasts vs. compute in governance reviews; “success probability vs. threshold” charts accompanying launches
- Assumptions/dependencies: Organizational buy-in; harmonized FLOPs accounting; acceptance of forecast uncertainty bounds
- Energy and carbon-aware training decisions
- What: Use capability forecasts to select the lowest-emissions plan that attains a capability target (e.g., prefer tuning D vs. N depending on exponents; avoid overtraining under weak mixture).
- Sectors: energy, sustainability, cloud providers
- Tools/products/workflows: “Carbon-Aware Planner” that couples scaling fits with grid carbon intensity forecasts; Pareto front of train compute vs. inference sampling compute (pass@k)
- Assumptions/dependencies: Reliable emissions accounting; access to location/time-based carbon intensity; validated fits for the intended tasks
- Academic experiment design and reproducibility teaching
- What: Teach students and teams to run compute-efficient ladders, fit direct laws, and report FLOPs thresholds; reproduce the paper’s results using the released runs.
- Sectors: academia, education
- Tools/products/workflows: Open-source notebooks for fitting and diagnostics; course modules on scaling law practice; replication assignments using the authors’ released data
- Assumptions/dependencies: Availability of modest compute for the ladder; consistent evaluation harness
Long-Term Applications
- End-to-end AutoScale agents for training/program planning
- What: Fully automated systems that allocate N, D, data mixture, and schedule; monitor checkpoints; update scaling fits; and decide train-vs-inference compute trade-offs (including pass@k) to meet product SLOs at minimal cost/carbon.
- Sectors: cloud platforms, MLOps vendors, large AI labs
- Tools/products/workflows: “LLM Training Autopilot”; integration with cluster schedulers, cost/carbon meters, and eval farms
- Assumptions/dependencies: Robust generalization of exponents across recipes (MoE, retrieval, multimodal); strong uncertainty modeling; reliable, scalable eval infrastructure
- Domain-specific capability forecasting in safety-critical settings
- What: Predict target clinical/financial/legal task performance from small domain-pretraining runs, including irreducible-error modeling and dataset shift detection.
- Sectors: healthcare, finance, law, government
- Tools/products/workflows: “Regulated-Domain Forecaster” with conservative prediction intervals and domain-shift alarms; pre-deployment capability attestations
- Assumptions/dependencies: High-quality domain corpora; alignment/tuning steps may change exponents; stringent validation and governance requirements
- Standards and regulation integrating compute-to-capability forecasting
- What: Incorporate scaling-based capability forecasts into compliance regimes (model cards, AI Act–style disclosures), procurement guidelines, and public compute funding decisions.
- Sectors: policy, regulators, public research funders
- Tools/products/workflows: Reference protocols for FLOPs accounting, FLOPs-threshold reporting, and uncertainty intervals; third-party auditing playbooks
- Assumptions/dependencies: Legal consensus on reporting schemas; auditors able to reproduce fits; guardrails against gaming through benchmark overfitting
- Metric- and item-level difficulty modeling for more general laws
- What: Extend beyond aggregate benchmarks to item-difficulty distributions that explain S-shaped curves mechanistically and improve transfer to composite or thresholded tasks.
- Sectors: academia, benchmark providers, evaluation platforms
- Tools/products/workflows: “Metric Audit 2.0” that clusters items by difficulty/ambiguity and fits mixture-aware scaling; benchmark re-weighting tools
- Assumptions/dependencies: Item-level metadata and sufficient sample sizes; agreement on standardized taxonomy of difficulty and noise
- Unified scaling across pretraining, instruction tuning, and preference optimization
- What: Extend direct laws to include finetuning/aligning stages and new covariates (e.g., RLHF steps, preference data volume/quality).
- Sectors: software, education, assistants, safety
- Tools/products/workflows: Multi-stage scaling planners that forecast post-alignment capabilities and cost; “alignment budget” optimizers
- Assumptions/dependencies: Additional datasets and recipes shift exponents; need for careful normalization and hold-out validation
- Marketplace SLAs and capability certification
- What: Standardize “capability SLAs” that tie advertised benchmark accuracy to documented training/inference budgets, with third-party verification using direct scaling fits.
- Sectors: AI model platforms, cloud marketplaces, procurement
- Tools/products/workflows: Capability certification services; signed forecasts with uncertainty bounds; penalties for deviations beyond tolerance
- Assumptions/dependencies: Trusted auditors; robust, tamper-resistant reporting of compute and evaluation
- Consumer/developer tools that adapt sampling and energy on-device
- What: Smart IDEs/agents that set k, temperature, and retries based on task difficulty and learned pass@k curves, balancing latency, battery, and accuracy.
- Sectors: software tooling, mobile/edge, consumer apps
- Tools/products/workflows: “Adaptive Sampler” in IDEs; mobile agents that throttle retries based on predicted marginal gain
- Assumptions/dependencies: Compact local models or hybrid on-device/off-cloud routing; accurate difficulty estimation; user-acceptable latency/energy trade-offs
Key cross-cutting assumptions and dependencies
- Model family and recipe scope: Results validated on decoder-only Transformers with a modern training recipe; MoE, retrieval-augmented, and multimodal models may need new fits.
- Data mixture sensitivity: Exponents and ceilings depend on pretraining mixture; practitioners should fit on the intended data pipeline and domain.
- Scale thresholds: Predictability improves past task-specific FLOPs thresholds; below them, fits can be brittle.
- Benchmark noise and design: Ambiguity or label noise requires normalization and/or irreducible terms; composite/thresholded metrics can induce nonmonotonic behavior.
- Post-pretraining stages: Instruction tuning, preference optimization, and domain finetuning can shift scaling behavior; incorporate additional covariates when present.
- Evaluation consistency: Stable prompts/harnesses and reproducible FLOPs accounting are necessary for reliable fits and comparisons.
Glossary
- Asymptote: A limiting value that a function approaches as the input grows large or small. "Note that \Cref{eq:scaling_law_basic} indicates that Q takes values from a fixed range, with the lower and upper asymptotes set to zero and one, respectively."
- Broken Neural Scaling Law (BNSL): A smooth, piecewise model of performance vs. scale that captures regime changes (“breaks”) in log-log space. "\cite{caballero2023brokenneuralscalinglaws} propose to model a broad set of evaluation metrics from various modalities by a smooth approximation of a piecewise linear function in log-log space, referred to as the Broken Neural Scaling Law (BNSL)."
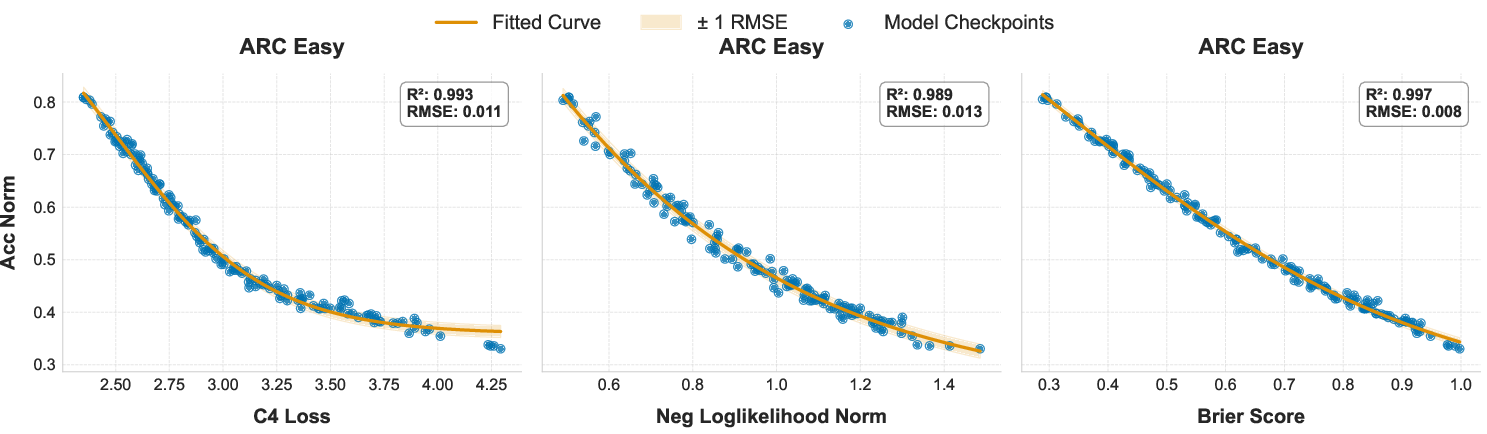
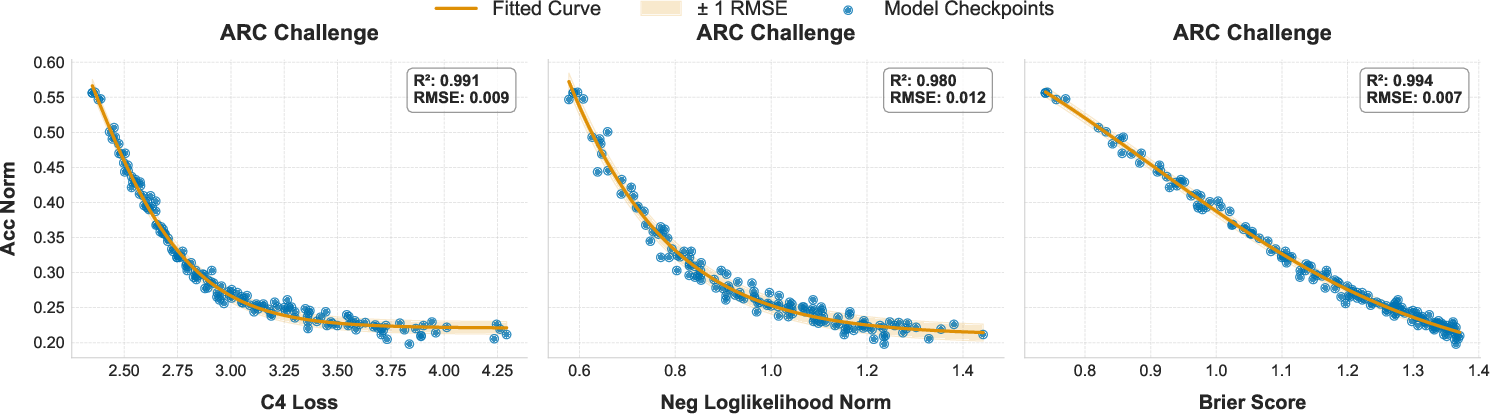
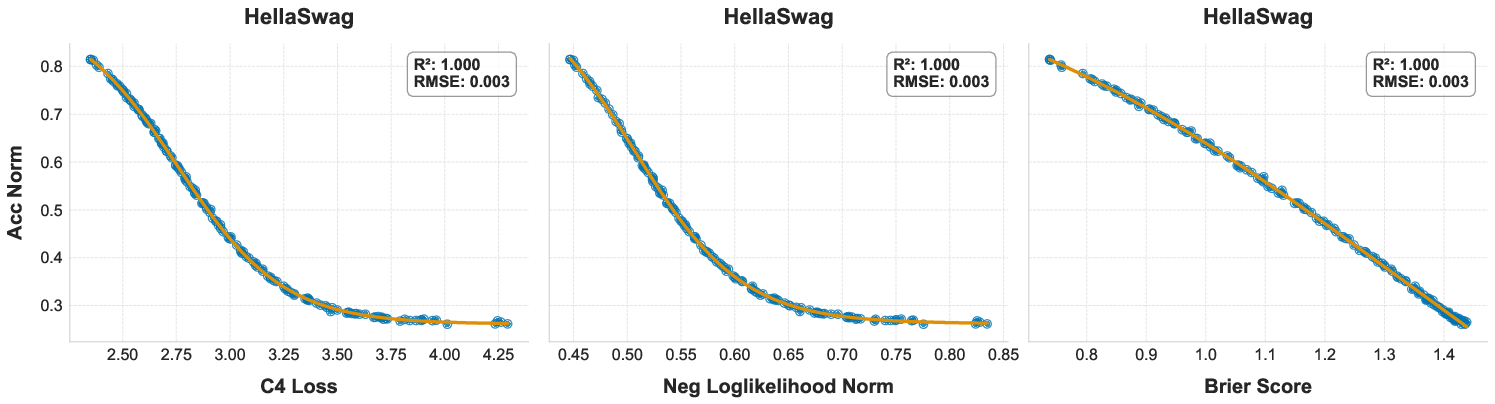
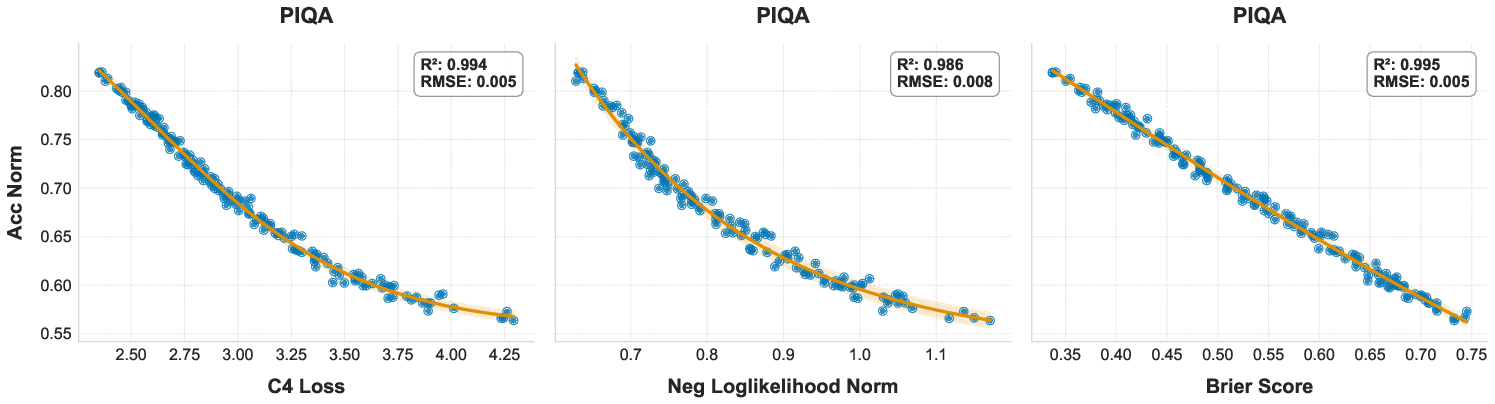
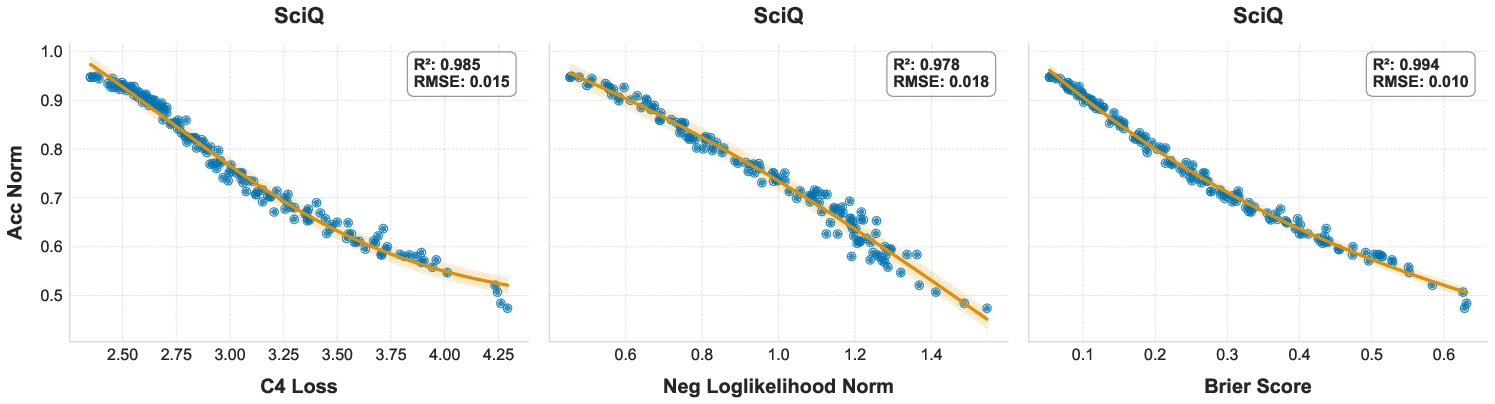
- Brier Score: A proper scoring rule for probabilistic predictions measuring the mean squared difference between predicted probabilities and outcomes. "we analyze the correlation between downstream task accuracy and several candidate proxy metrics including log-probability, evaluation loss, and the Brier Score."
- Chain-of-thought: A prompting or evaluation style where models produce intermediate reasoning steps before final answers. "we analyze predictability across metric families (ranked classification, exact-match generation, chain-of-thought math, and code pass rates)"
- Chinchilla scaling laws: Empirical laws suggesting compute-optimal training with a specific token-to-parameter ratio. "We first analyze models trained at a fixed TPR of 20, which approximates the compute-optimal point suggested by the Chinchilla scaling laws"
- Coefficient of determination (): A statistic that quantifies how well a model explains variance in the observed data. "We evaluate fit quality using Root Mean Squared Error (RMSE) and the coefficient of determination ()."
- Compute-efficient model ladders: A methodology that fits scaling trends from a small, structured set (“ladder”) of model sizes to forecast performance at larger scales. "Compute-efficient ladders \citep{DBLP:journals/corr/abs-2412-04403} advocate measuring task scaling on a small âladderâ of models to infer the trend for a target scale"
- Data mixture: The composition of datasets used for pretraining, which can strongly influence downstream capabilities. "The composition of the pretraining data significantly affects scaling behavior."
- DataDecide: A methodology that selects pretraining data mixtures via small-scale experiments and extrapolation. "DataDecide \citep{DBLP:journals/corr/abs-2504-11393} addresses a complementary question: choosing pretraining data by running small experiments and extrapolating which data mixture will win at larger scales"
- Decoder-only Transformer: A Transformer architecture that uses only the decoder stack, typical for autoregressive language modeling. "We use a standard modern pre-norm decoder-only Transformer architecture."
- Exact-match generation: A metric family where predicted strings must exactly match the reference answer. "we analyze predictability across metric families (ranked classification, exact-match generation, chain-of-thought math, and code pass rates)"
- Evaluation harness: A framework or pipeline to run benchmarks on models without requiring internal training signals. "we stress model-agnostic procedures that require no access to internal losses beyond what the evaluation harness already."
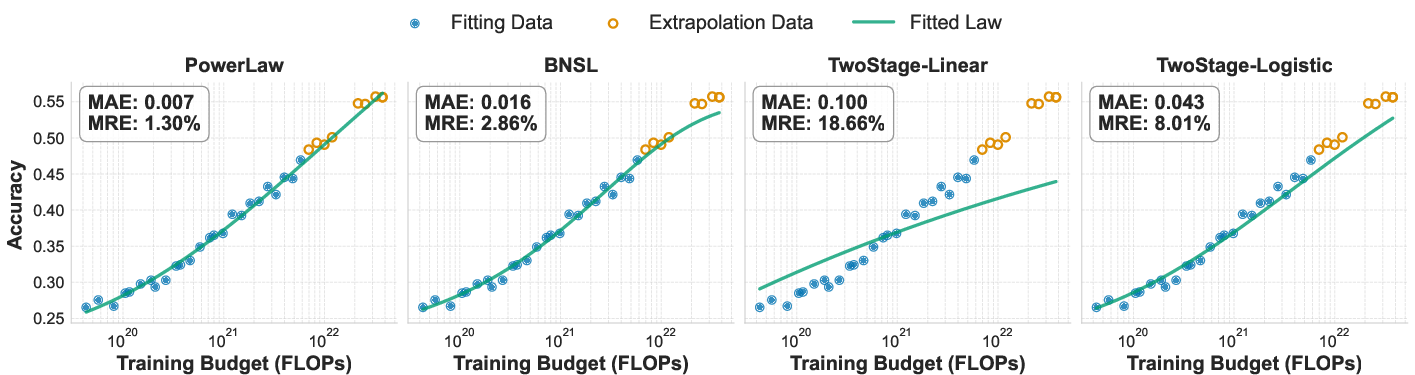
- Hold-out validation set: A subset of experiments reserved for evaluating predictive performance after fitting on separate training data. "To evaluate the model's predictive power, we established a hold-out validation set comprising of all runs with either a training budget over FLOPs or trained with the largest token-to-parameter ratio (TPR) in our experiments (160)."
- Huber loss: A robust regression loss that is quadratic near zero and linear for large errors, controlled by a parameter delta. "We fit the coefficients of \Cref{eq:scaling_law_basic_ND} by minimizing the Huber loss () with the L-BFGS-B algorithm."
- Inference compute: The computational resources consumed during model evaluation or sampling (as opposed to training). "account for inference compute under repeated sampling."
- Instruction tuning: Post-training that aligns a model to follow instructions using curated instruction-response pairs. "continued pretraining, instruction tuning, and preference optimization can reshape downstream accuracy"
- Irreducible term: A performance floor in scaling laws (e.g., due to data entropy) that cannot be improved by more compute. "A key distinction is the absence of an irreducible term in our model."
- L-BFGS-B algorithm: A quasi-Newton optimization method that handles bound constraints, often used for fitting models. "We fit the coefficients of \Cref{eq:scaling_law_basic_ND} by minimizing the Huber loss () with the L-BFGS-B algorithm."
- Logistic function: A sigmoidal mapping often used to relate proxy metrics to accuracy. "we fit logistic functions of the form "
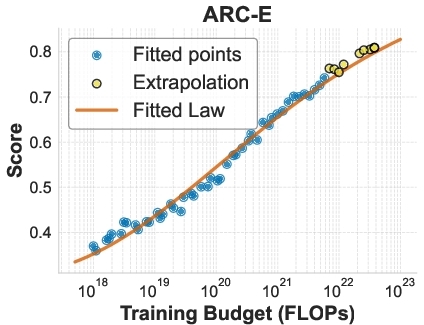
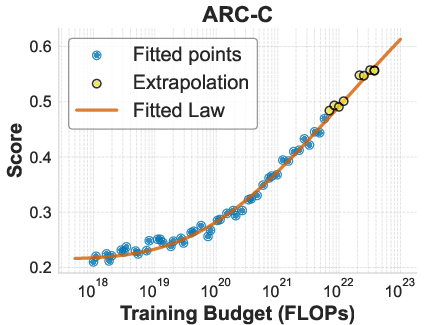
- Log accuracy: The natural logarithm of accuracy, used to obtain smoother scaling behavior and S-shaped trends. "we demonstrate that when holding the token-to-parameter ratio fixed, the scaling of downstream log accuracy is accurately captured by a simple power law."
- Log-log scale: A plotting or modeling regime where both axes are logarithmic, often revealing linear trends in power laws. "we also noticed an approximately linear relationship between log accuracy and training FLOPs on a log-log scale."
- Loss-to-loss prediction: A framework showing that losses across datasets can forecast each other, serving as a surrogate for downstream ability. "\cite{DBLP:journals/corr/abs-2411-12925} show that losses across datasets can be predicted from each other (loss-to-loss), offering a unifying surrogate for downstream ability."
- Mean Absolute Error (MAE): The average magnitude of prediction errors without considering their direction. "To evaluate predictive performance, we use Mean Relative Error (MRE) and Mean Absolute Error (MAE)."
- Mean log pass rate: The average of the logarithm of pass rates across items, used to smooth variability in code benchmarks. "GPT-4 documents predictable scaling on evaluation tasks by fitting a power law to smaller-run models and extrapolating mean log pass rate on HumanEval"
- Mean Relative Error (MRE): The average prediction error normalized by true values, expressed as a percentage. "To evaluate predictive performance, we use Mean Relative Error (MRE) and Mean Absolute Error (MAE)."
- Negative log-likelihood (NLL): A loss measuring how improbable the correct outputs are under a model, often used as a proxy for performance. "we evaluate two-stage scaling laws that use negative log-likelihood (NLL) as a proxy metric to predict downstream task performance."
- Non-monotonicities: Instances where performance on individual items does not consistently improve with scale, despite smooth aggregate trends. "they also note that individual items can display non-monotonicities even when aggregate trends are smooth"
- Pass rate: The fraction of tasks or test cases a model solves or passes, particularly in code generation benchmarks. "predict accuracy across token-to-parameter ratios and account for inference compute under repeated sampling."
- Pass@k: The probability that at least one of k sampled generations solves a task; a standard code-generation metric. "We also study the effect of increasing the number of samples in pass@k for coding benchmarks across different training budgets."
- Pareto analyses: Trade-off analyses that map optimal fronts between competing objectives, such as training vs. inference compute. "For code, train vs. inference compute (pass@k) tradeâoffs deserve explicit Pareto analyses."
- Perplexity: An exponentiated average negative log-likelihood used to assess LLM uncertainty; lower is better. "Our model for log accuracy scaling (\Cref{eq:scaling_law_basic}) parallels the standard power laws used for log perplexity"
- Power law: A functional relation where one quantity varies as a power of another, commonly used in scaling analyses. "a simple power law can accurately describe the scaling behavior of log accuracy on multiple popular downstream tasks."
- Pre-norm: A Transformer variant where layer normalization is applied before attention and feed-forward sublayers for training stability. "We use a standard modern pre-norm decoder-only Transformer architecture."
- Preference optimization: Post-training techniques (e.g., RLHF) that optimize models to align with human preferences. "continued pretraining, instruction tuning, and preference optimization can reshape downstream accuracy"
- Pretraining checkpoints: Saved model states during pretraining, used for evaluation or further fine-tuning. "We fit laws on pretraining checkpoints; continued pretraining, instruction tuning, and preference optimization can reshape downstream accuracy"
- Pretraining loss: The objective minimized during pretraining (e.g., language modeling loss), often used as a proxy metric. "scaling laws for LLMs traditionally focus on proxy metrics like pretraining loss"
- Proxy metric: An intermediate signal (e.g., loss) used to predict downstream performance when direct metrics are expensive or noisy. "we analyze the correlation between downstream task accuracy and several candidate proxy metrics including log-probability, evaluation loss, and the Brier Score."
- Ranked classification: A setting where a model scores multiple choices and selects the highest, enabling log-probability-based evaluation. "showing strong fits on ranked classification benchmarks where each item is scored by a modelâs log-probability over choices."
- RoPE positional embedding: Rotary positional encodings that incorporate relative position via complex rotations, improving extrapolation. "We employ the RoPE positional embedding \citep{su2023roformerenhancedtransformerrotary}"
- Scaling law: An empirical formula that predicts performance as a function of scale (compute, parameters, tokens). "We propose a new, direct scaling law for downstream performance."
- Sigmoidal link: A nonlinear mapping (often logistic) from a proxy (e.g., NLL) to accuracy. "using a sigmoidal link from NLL to accuracy to forecast final scores for ranked multiple-choice tasks."
- SwiGLU activation: A gated activation function variant that can improve Transformer performance. "and SwiGLU activation \citep{shazeer2020gluvariantsimprovetransformer}."
- Token-to-parameter ratio (TPR): The number of pretraining tokens per model parameter, a key variable in compute-optimal training. "Our experimental setup spans 48 distinct training budgets and five token-to-parameter ratios (TPRs), allowing us to systematically map the scaling landscape."
- Training FLOPs: The floating-point operations consumed during training; a standard measure of compute budget. "Benchmark accuracy can be described using a direct scaling law based on training FLOPs."
- Training budget: The total compute (or tokens) allocated for training a model. "We characterize the relationship between training budget and downstream performance by pre-training a comprehensive grid of models."
- Transition point: A regime-change location in a broken scaling curve where the slope changes. "that is a BNSL with one transition point."
- Validation loss: The loss measured on held-out data used to tune or assess models during training. "report that aggregate downstream error is nearâlinear when plotting logâerror vs. validation loss"
- μ‑parametrization: A parameterization technique that transfers learning rate and optimization settings across scales. "derived by tuning a proxy model and later transferring with -parametrization \citep{yang2022tensorprogramsvtuning} in its simplified form"
Collections
Sign up for free to add this paper to one or more collections.

