Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
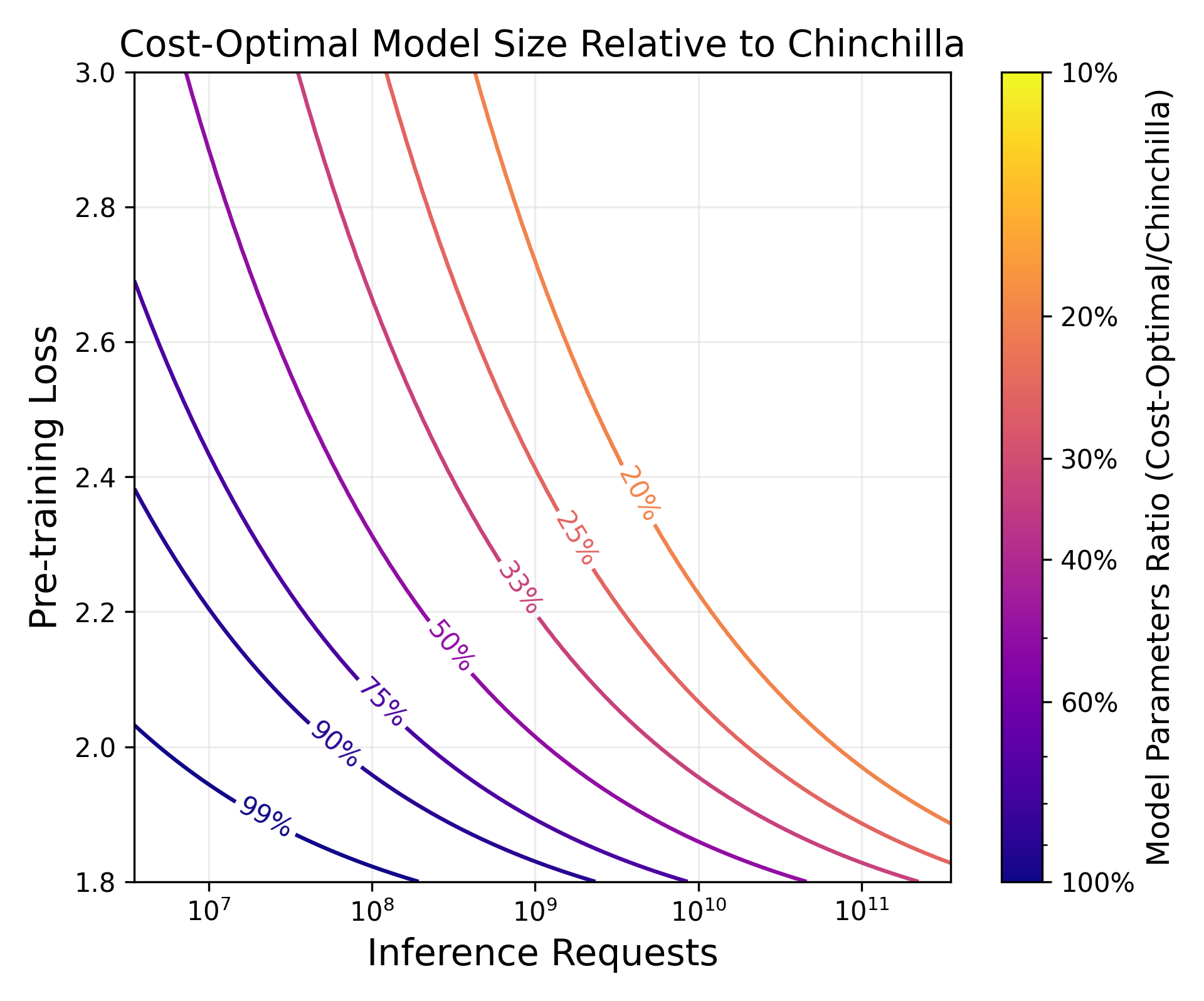
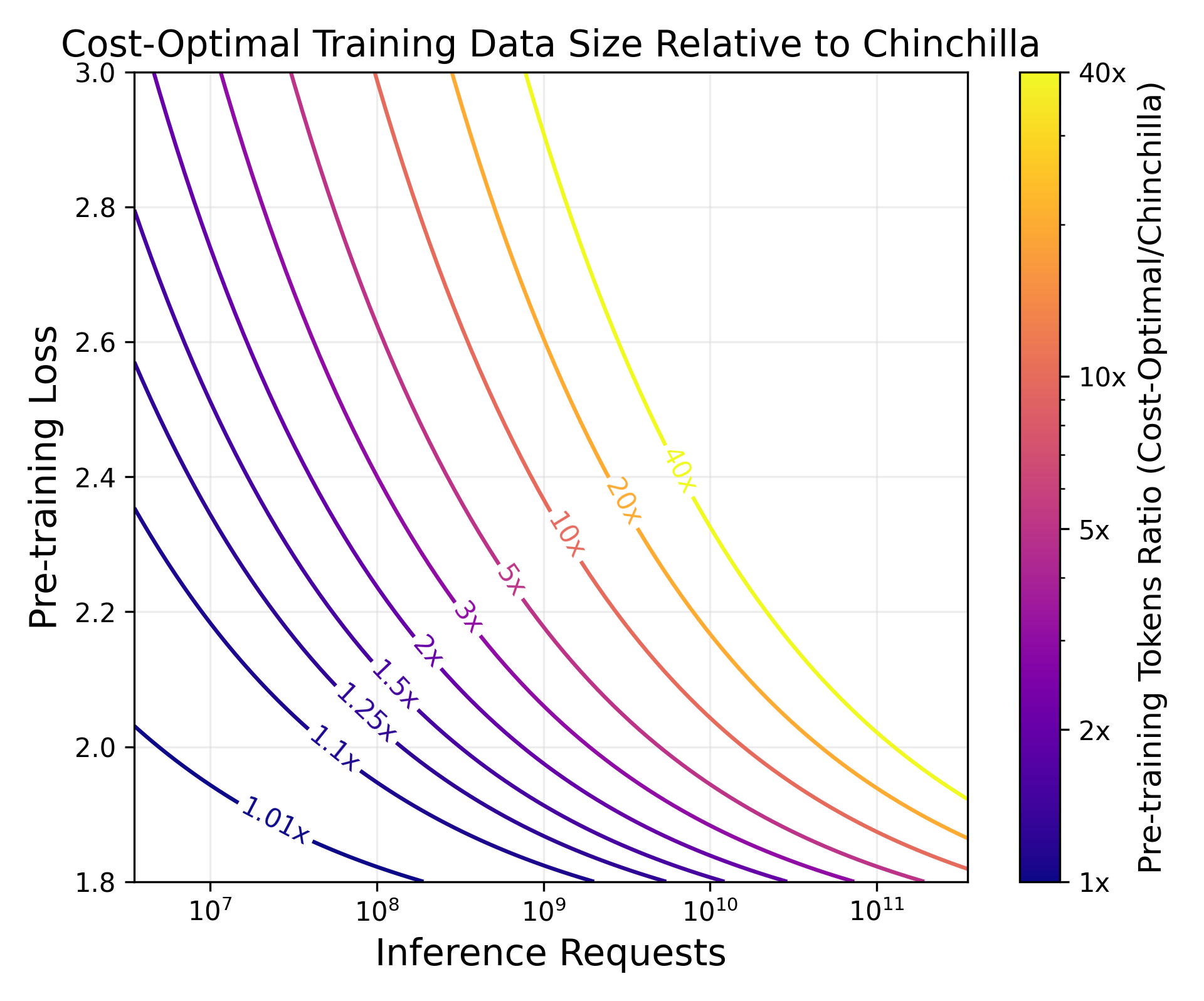
Abstract: LLM scaling laws are empirical formulas that estimate changes in model quality as a result of increasing parameter count and training data. However, these formulas, including the popular Deepmind Chinchilla scaling laws, neglect to include the cost of inference. We modify the Chinchilla scaling laws to calculate the optimal LLM parameter count and pre-training data size to train and deploy a model of a given quality and inference demand. We conduct our analysis both in terms of a compute budget and real-world costs and find that LLM researchers expecting reasonably large inference demand (~1B requests) should train models smaller and longer than Chinchilla-optimal. Furthermore, we train 47 models of varying sizes and parameter counts to validate our formula and find that model quality continues to improve as we scale tokens per parameter to extreme ranges (up to 10,000). Finally, we ablate the procedure used to fit the Chinchilla scaling law coefficients and find that developing scaling laws only from data collected at typical token/parameter ratios overestimates the impact of additional tokens at these extreme ranges.
- H. De Vries. Go smol or go home, 2023. URL https://www.harmdevries.com/post/model-size-vs-compute-overhead/.
- Cerebras-gpt: Open compute-optimal language models trained on the cerebras wafer-scale cluster, 2023.
- Gptq: Accurate post-training quantization for generative pre-trained transformers, 2023.
- Training compute-optimal large language models, 2022.
- Scaling laws for neural language models, 2020.
- W. Knight. Openai’s ceo says the age of giant ai models is already over. Wired, 2023. ISSN 1059-1028. URL https://www.wired.com/story/openai-ceo-sam-altman-the-age-of-giant-ai-models-is-already-over/.
- Reducing activation recomputation in large transformer models, 2022.
- L. Labs. Gpu cloud - vms for deep learning. https://lambdalabs.com/service/gpu-cloud, 2023. Accessed 2023-10-02.
- Scaling data-constrained language models, 2023.
- NVIDIA. Nvidia a100 datasheet, 2021. URL https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf.
- OpenAI and A. Pilipiszyn. Gpt-3 powers the next generation of apps, Mar 2021. URL https://openai.com/blog/gpt-3-apps.
- Efficiently scaling transformer inference, 2022.
- Scaling language models: Methods, analysis & insights from training gopher, 2022.
- Exploring the limits of transfer learning with a unified text-to-text transformer, 2023.
- N. Shazeer and D. d. Freitas. Introducing character, Dec 2022. URL https://blog.character.ai/introducing-character/.
- Llama: Open and efficient foundation language models, 2023a.
- Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Technical report for stablelm-3b-4e1t. https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo, 2023. Accessed 02-10-2023.
- P. Villalobos and D. Atkinson. Trading off compute in training and inference, 2023. URL https://epochai.org/blog/trading-off-compute-in-training-and-inference. Accessed: 2023-9-26.
- Smoothquant: Accurate and efficient post-training quantization for large language models, 2023.
- Lmsys-chat-1m: A large-scale real-world llm conversation dataset, 2023.
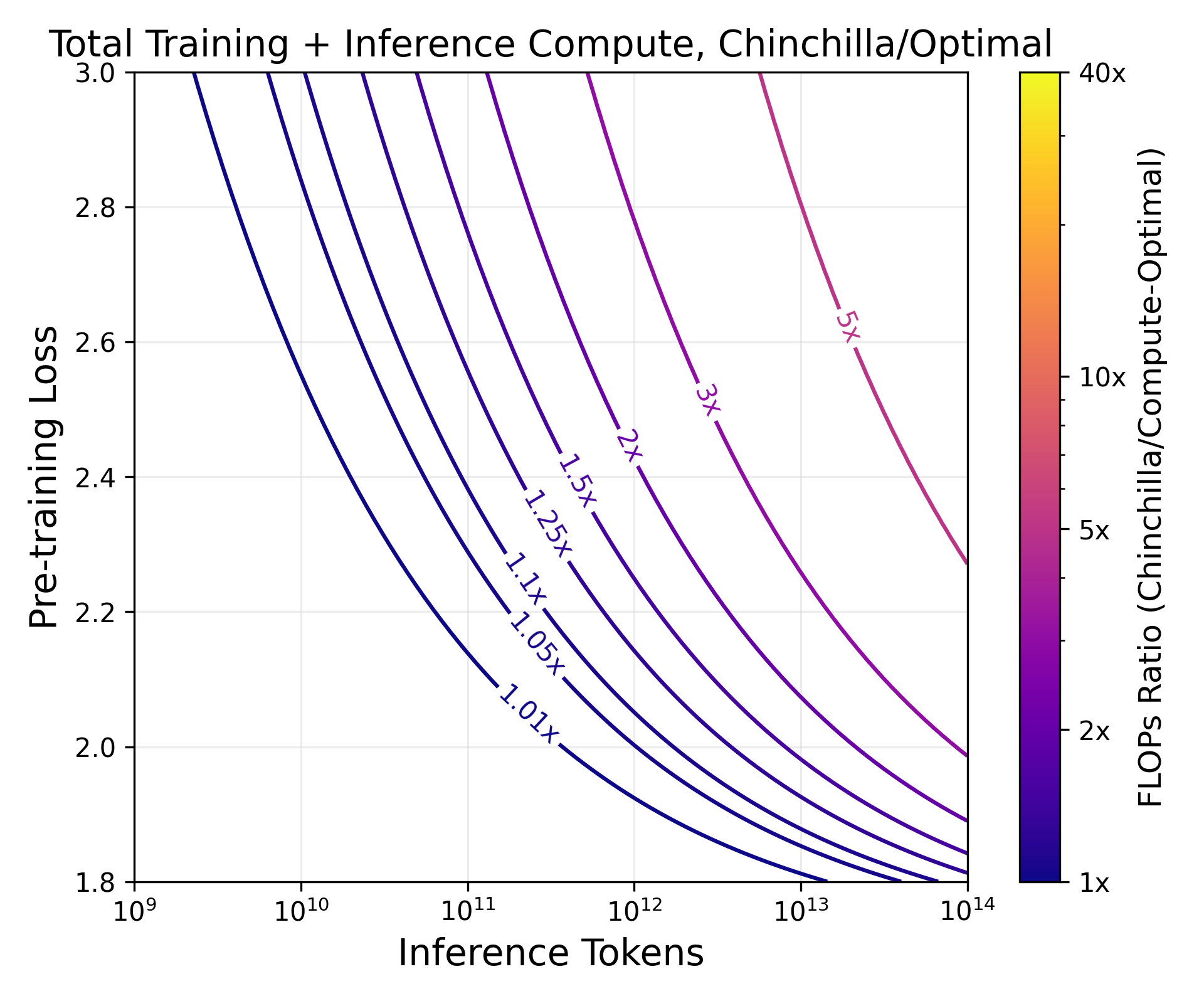
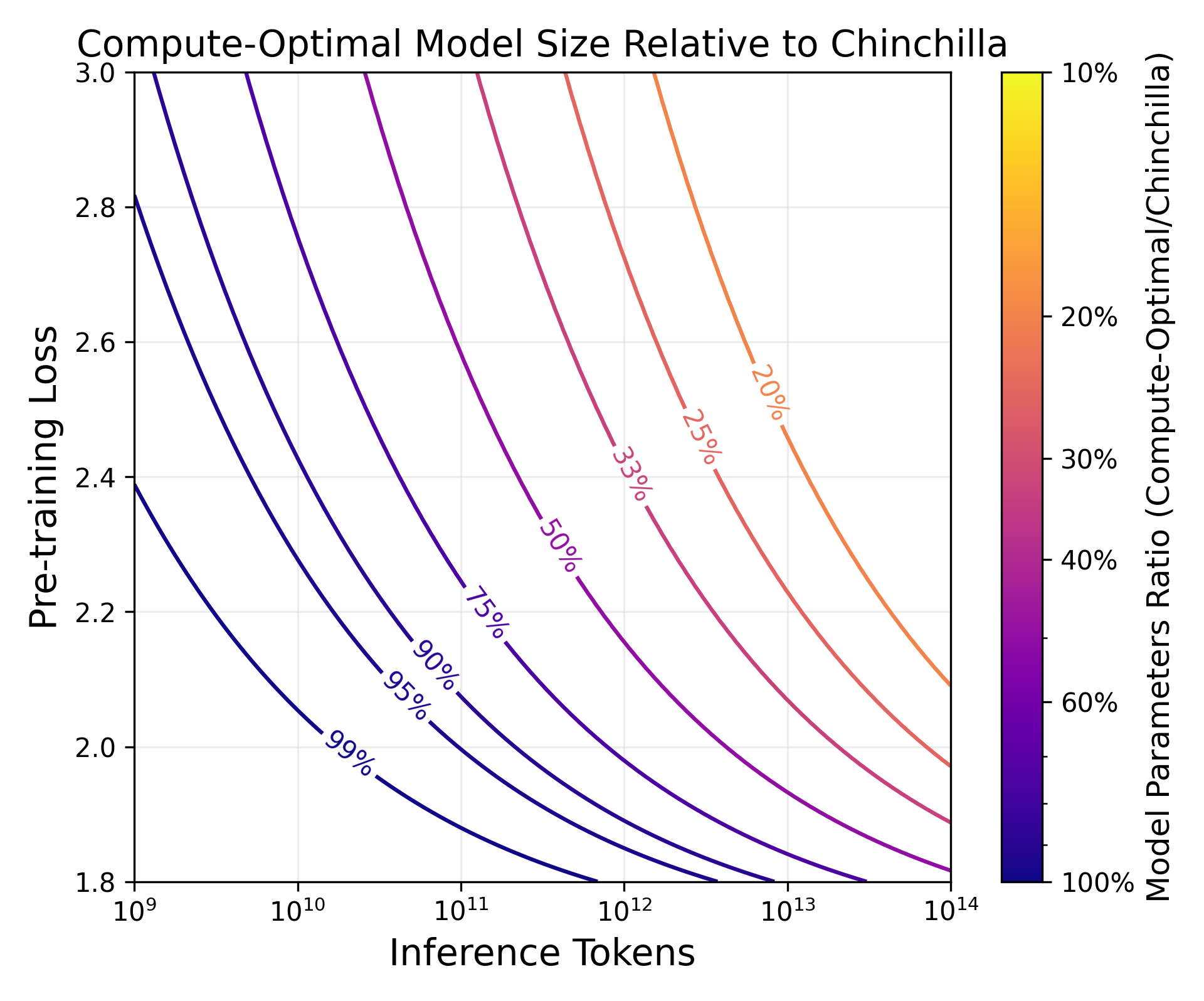
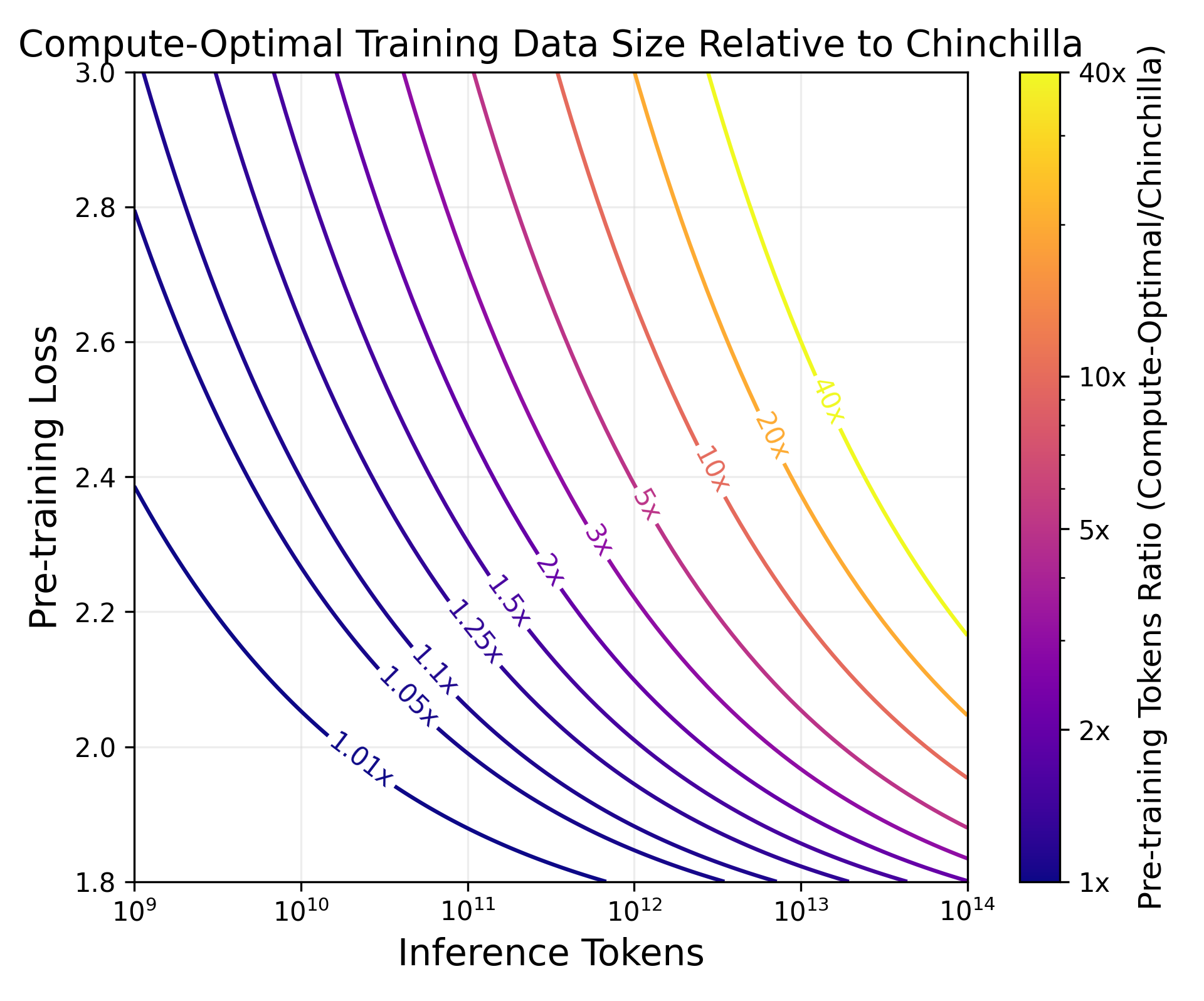
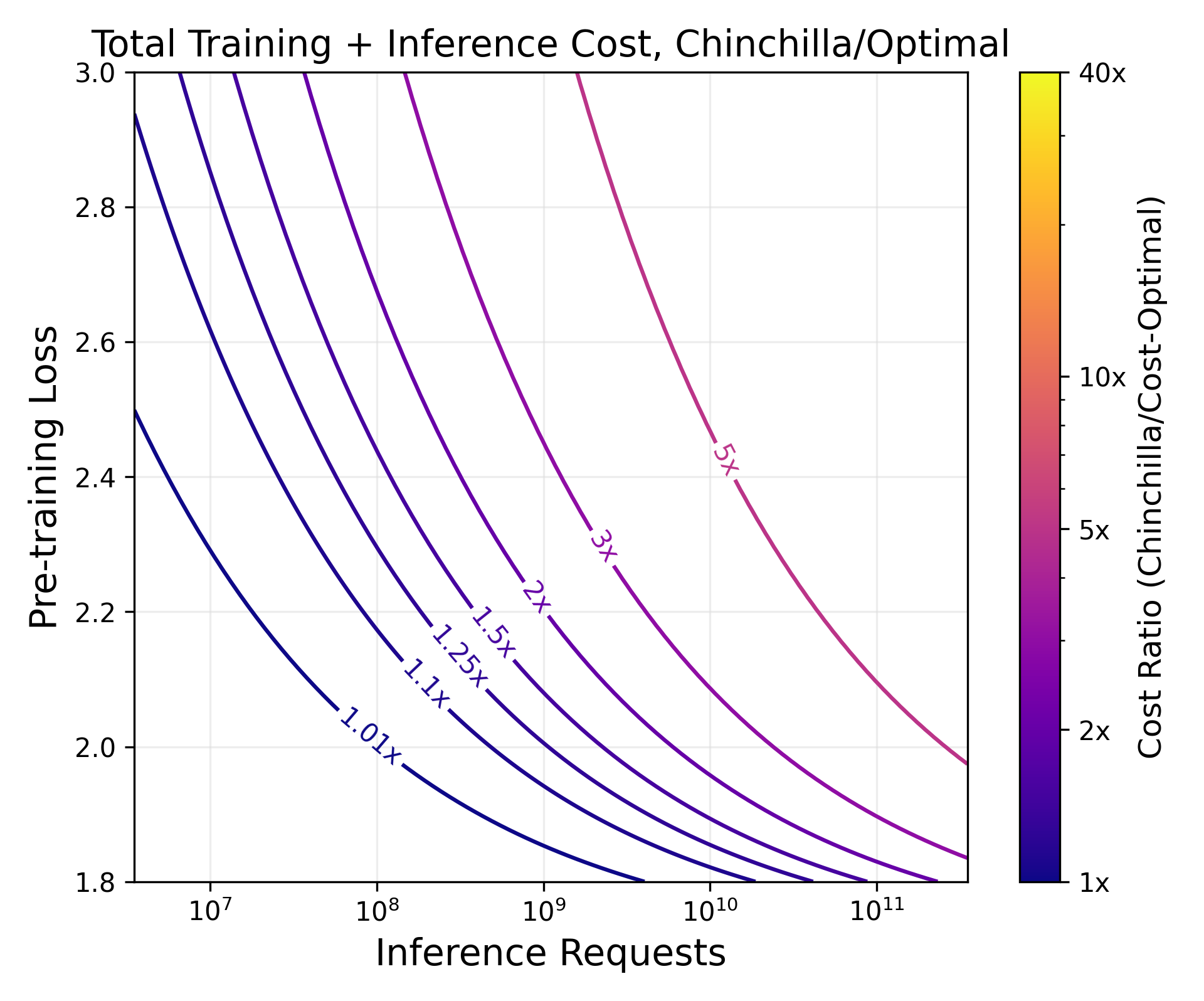
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

