- The paper introduces deep-thinking tokens and the DTR metric, which correlate positively with LLM accuracy compared to traditional length measures.
- It employs Jensen–Shannon divergence to assess token stabilization across layers, offering a more reliable measure of reasoning effort.
- It demonstrates a test-time compute scaling approach, Think@n, that reduces inference cost while maintaining or improving performance.
Measuring Deep Reasoning Effort in LLMs via Deep-Thinking Tokens
Introduction
The assessment of reasoning effort during inference in LLMs is typically confounded by imprecise proxies, the most common being output token length. "Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens" (2602.13517) systematically dissects this paradigm, arguing through empirical and mechanistic analysis that output length is, at best, a weak and unreliable indicator of actual reasoning, sometimes exhibiting negative correlation with accuracy. To address the limitations of length and surface-level token statistics, the authors introduce the "deep-thinking ratio" (DTR): a metric that quantifies the proportion of output tokens requiring continued revision across deeper layers prior to prediction distribution stabilization. DTR is then operationalized to inform a test-time aggregation approach, Think@n, which leverages this internal signal to enable more compute-efficient majority voting with no sacrifice (and sometimes improvement) in task accuracy.
Deep-Thinking Ratio: Methodology
The core technical contribution is the definition and computation of deep-thinking tokens. The key insight is that, in autoregressive generation, tokens for which the internal prediction distributions remain unsettled until deep in the model (i.e., late layers) can be interpreted as requiring more “thought,” whereas tokens that stabilize predictions in shallower layers are trivial with respect to computational effort.
Formally, for each output token, the method projects the hidden state of every layer to the vocabulary space via the unembedding matrix and computes the Jensen–Shannon divergence (JSD) between each intermediate-layer output and the final-layer output. The layer at which the divergence drops below a threshold g is denoted as the “settling depth” for that token. If this stabilization occurs after a certain fraction ρ of the total depth (e.g., ρ=0.85), the token is flagged as a deep-thinking token.
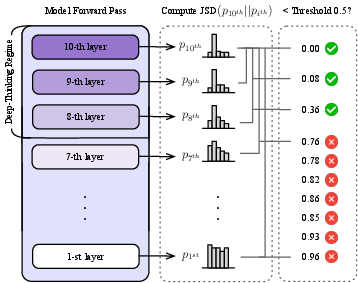
Figure 1: Deep-thinking token identification: a token is classified as deep-thinking if its stabilization (JSD with the final-layer distribution below g) first occurs in the late regime of the network.
The deep-thinking ratio (DTR) for an output sequence is simply the fraction of its tokens classified as deep-thinking.
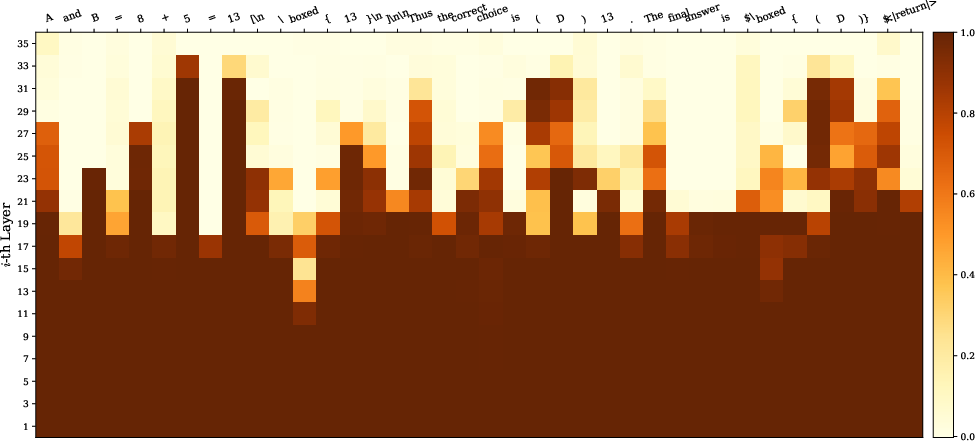
Figure 2: Heatmap of Jensen–Shannon divergence (JSD) across layers for an example sequence: functional tokens stabilize quickly, while answer-critical tokens undergo distributional shifts until late layers.
Empirical Correlation with Reasoning Accuracy
A major empirical finding is that output length correlates negatively with accuracy, reaffirming prior reports of “overthinking,” where models that generate overly long reasoning traces can actually degrade performance on complex tasks. In contrast, DTR exhibits a robust positive correlation with accuracy, stable across datasets, model architectures, and benchmarks.
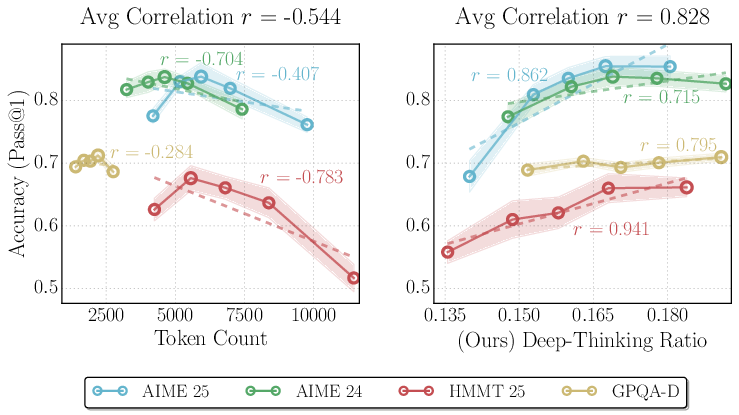
Figure 3: Output token count is weakly (and often negatively) correlated with accuracy, while deep-thinking ratio (DTR) demonstrates strong, positive correlation with accuracy across datasets and model checkpoints.
DTR consistently outperforms not only token count but also log-probability, negative perplexity, negative entropy, and self-certainty metrics. Across 32 model–benchmark combinations, DTR is positive in nearly all (30/32), with average correlation r=0.683 (compared to length’s r=−0.594 and confidence-based metrics in the $0.2$–$0.6$ range).
Sensitivity to Hyperparameters and Model Configuration
DTR’s correlation to accuracy is robust across reasonable hyperparameter choices for the settling threshold g and depth fraction ρ. Using stricter thresholds (higher g, lower ρ) decreases the absolute DTR but maintains the trend. g=0.5 and ρ=0.85 provide the best trade-off between selectivity and robustness.
Further, DTR values encode information not just about individual responses but about system-level configuration: for instance, models prompted with “higher reasoning level” system instructions tend to produce lower DTRs but achieve higher accuracy, reflecting a redistribution of compute from per-token depth to sequence length.
Test-Time Compute Scaling with Think@n
The DTR metric is used to implement Think@n, a test-time voting scheme where, instead of majority voting across all (or randomly selected) sampled responses, one selects those candidate generations with top DTR score as the voting pool, often using only short prefixes (e.g., first 50 tokens) for early rejection. This enables substantial inference compute savings by not fully decoding low-quality candidates.
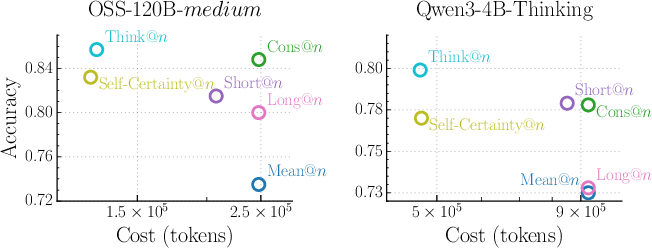
Figure 4: Think@n achieves Pareto-optimal trade-off, matching or exceeding majority voting accuracy at approximately half the inference cost.
Across various datasets, Think@n matches or surpasses standard self-consistency with roughly 50% reduction in compute, outperforming both token-length and confidence-based selection methods. Cost reduction is achieved by early halting (based on DTR computed from a prefix), with no negative impact on accuracy. Ablation studies confirm this efficiency: a prefix of only 50 tokens suffices to achieve near-oracle performance.
Architectural Analysis and Interpretability
The layer-wise heatmap analysis (Figure 2) reveals that functional and template tokens converge quickly, whereas semantico-critical tokens (e.g., operation results, logic steps, answer statements) show late stabilization. Furthermore, this mechanism is agnostic of specific architectures and applies without modification to multiple families (GPT-OSS, DeepSeek-R1, Qwen3), and tasks (AIME, HMMT, GPQA).
Implications and Future Directions
The evidence provided here undermines the validity of surface-level proxies for computational effort in autoregressive LLMs and instead advances internal depth-wise evolution as a rigorous, mechanistic, and actionable signal. Practically, this discredits decode-time heuristics which equate output verbosity with depth of reasoning or infer that high-confidence output is always indicative of effective computation. Theoretically, DTR suggests directions for model development and evaluation that focus on maximizing efficient use of intermediate computation resources, and for weighting or pruning in ensemble/test-time selection.
The findings prompt several avenues for future work:
- Cross-model and cross-task normalization: Since DTR may not be directly inter-comparable across fundamentally distinct models or system instructions, deeper analysis of how different prompts and architectures redistribute depth and token usage is warranted.
- Fine-grained interpretability: Deeper analysis into specific categories of tokens, reasoning steps, or compositional subroutines that consistently show late stabilization could shed light on internal LLM decomposition of complex tasks.
- Adaptive training signals: Future work may consider incorporating DTR directly into training or reinforcement learning objectives to maximize effective rather than superficial thinking effort.
- Extension to multimodal or mixed-architecture models: The DTR framework is not inherently tied to text-only LLMs and may generalize to vision-language or code-generation models for assessing compositional effort.
Conclusion
"Think Deep, Not Just Long" provides a rigorous and empirically validated methodology for measuring and leveraging inference-time reasoning effort in LLMs, superseding traditional surface-level heuristics. By tracking the evolution of token prediction stabilization across model depth, deep-thinking ratio enables mechanism-driven test-time compute scaling, consistently yielding superior and more efficient performance aggregation in high-stakes reasoning benchmarks. The results motivate a reorientation of both evaluation and model optimization toward internal computation mechanisms rather than superficial generative measures.

