- The paper introduces a novel RL framework that trains LLMs to employ parallel thinking through a progressive curriculum and dual-stage rewards.
- The methodology integrates cold-start SFT on simple math problems with RL on challenging benchmarks, achieving an 83.7% success rate in parallel-thinking traces and notable accuracy improvements.
- The study demonstrates that alternating reward strategies guide LLMs from exploratory multi-threading to verified reasoning, yielding up to 42.9% accuracy gains over baselines.
Reinforcement Learning for Parallel Thinking in LLMs: The Parallel-R1 Framework
Introduction
Parallel thinking, the ability to concurrently explore multiple reasoning paths, has recently been recognized as a critical capability for advanced mathematical reasoning in LLMs. The Parallel-R1 framework introduces a reinforcement learning (RL) approach to instill parallel thinking in LLMs, moving beyond the limitations of supervised fine-tuning (SFT) on synthetic data. The framework leverages a progressive curriculum and novel reward designs to address the cold-start problem and optimize both reasoning accuracy and parallel thinking behaviors.
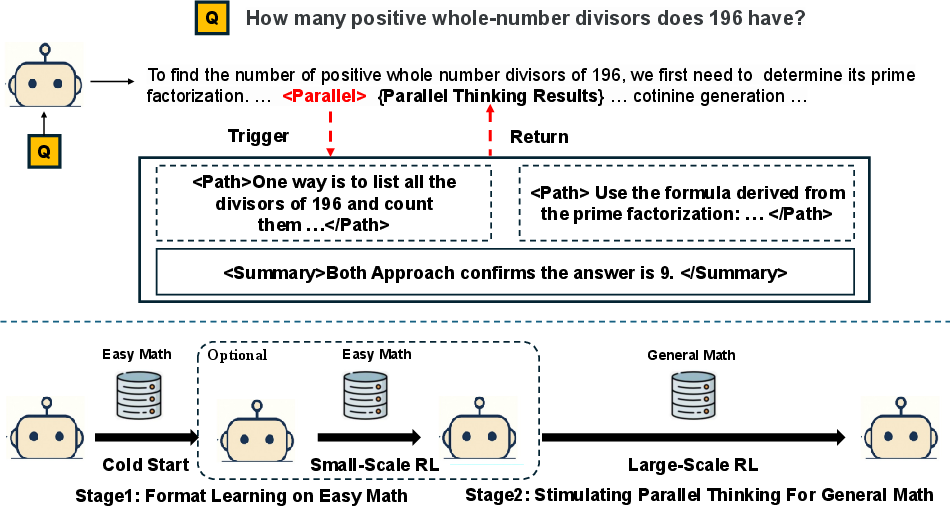
Figure 1: Overview of the Parallel-R1 framework, illustrating the inference workflow and progressive multi-stage training for parallel thinking.
Parallel thinking in LLMs is operationalized via two stages: (1) exploration, where the model detects critical steps and launches multiple independent reasoning threads, and (2) summary, where the model aggregates and synthesizes insights from these threads before resuming the main reasoning chain. This is implemented using control tags: <Parallel>, <Path>, and <Summary>, which structure the generation process and enable adaptive invocation of parallel reasoning.
During inference, the model generates responses auto-regressively until a <Parallel> tag is emitted, at which point multiple threads are spawned. Each thread explores a distinct solution path, and their outputs are summarized and merged back into the main context. This cycle can repeat as needed, allowing the model to flexibly balance exploration and verification.
Data Pipeline and Cold-Start Strategy
A key challenge in training parallel thinking is the scarcity of high-quality parallel reasoning traces in natural text, especially for complex problems. The framework addresses this by generating cold-start data on simple math problems (GSM8K) using detailed prompting, achieving an 83.7% success rate in valid parallel-thinking traces. This data is used to teach the model the format and basic behavior of parallel thinking before transitioning to RL on more difficult tasks.
A format-check algorithm ensures strict adherence to the parallel thinking structure, which is essential for structured model variants that rely on architectural modifications (e.g., path-window attention masks and multiverse position encodings).
Reinforcement Learning Algorithms and Training Recipes
The RL phase employs Group Relative Policy Optimization (GRPO), which optimizes the policy using group-wise advantage estimation and KL regularization. The training recipe consists of three stages:
- Cold-Start SFT: Fine-tuning on Parallel-GSM8K to learn the parallel thinking format.
- RL on Easy Math: Reinforcement learning on GSM8K with a binary reward that requires both correct answers and the use of parallel thinking.
- RL on General Math: RL on challenging datasets (DAPO, AIME, AMC, MATH) with accuracy-based rewards to generalize parallel thinking to complex problems.
For structured models, architectural modifications enforce strict isolation between reasoning paths, and reward schedules are alternated between accuracy and parallel thinking incentives to avoid overfitting to superficial patterns.
Empirical Results and Ablation Studies
Parallel-R1 achieves substantial improvements over baselines. On AIME25, the causal variant (Parallel-R1-Seen) reaches 19.2% mean@16 accuracy, compared to 14.8% for the GRPO baseline. The framework yields an average accuracy improvement of 8.4% over sequential RL models and up to 42.9% improvement on AIME25 when using parallel thinking as a mid-training exploration scaffold.
Ablation studies reveal:
- Stage-wise RL: Cold-start SFT followed by RL on easy math is essential for causal models, while structured models require direct RL on hard tasks to avoid overfitting.
- Reward Design: Direct accuracy rewards fail to stimulate parallel thinking, while direct parallel rewards harm performance. Alternating rewards achieve a balance, increasing parallel ratio without sacrificing accuracy.
- Prompting: Detailed parallel thinking prompts improve model understanding and generalization.
Evolution of Parallel Thinking Behavior
Analysis of training dynamics shows a strategic shift in the use of parallel thinking. Early in RL training, the model employs parallel paths for computational exploration, increasing the likelihood of discovering correct solutions. As training progresses, the model transitions to using parallel thinking for late-stage multi-perspective verification, minimizing risk and maximizing reward.
(Figure 2)
Figure 2: Dynamics of the relative position of the <Parallel> block during RL training, indicating a shift from early exploration to late verification.
Parallel Thinking as a Mid-Training Exploration Scaffold
Parallel thinking serves as an effective structured exploration mechanism during RL training. By enforcing parallel reasoning in the early stages, the model explores a broader policy space, avoiding local optima. Transitioning to accuracy-only rewards in later stages allows the model to exploit the most effective strategies discovered during exploration, resulting in higher final performance.
(Figure 3)
Figure 3: Two-stage training with parallel reasoning as a mid-training exploration scaffold, showing accuracy and parallel ratio trends.
Case Studies
Qualitative analysis demonstrates the model's ability to adaptively invoke parallel thinking for both exploration and verification. Early-stage models use parallel blocks to explore distinct algebraic methods, while late-stage models employ parallel thinking for verification after a primary solution is found.
Implications and Future Directions
The Parallel-R1 framework provides a scalable and effective approach to instilling parallel thinking in LLMs, with strong empirical gains in mathematical reasoning. The strategic evolution of parallel thinking behaviors and the utility of mid-training exploration scaffolds have broad implications for RL-based reasoning in LLMs. Future work may extend these techniques to other domains, investigate more adaptive reward schedules, and explore architectural innovations for more efficient parallel reasoning.
Conclusion
Parallel-R1 demonstrates that reinforcement learning, combined with a progressive curriculum and carefully designed rewards, can successfully teach LLMs to perform parallel thinking on complex reasoning tasks. The framework achieves consistent improvements over sequential baselines, reveals nuanced learning dynamics, and validates parallel thinking as a powerful exploration strategy in RL training. These findings advance the state of the art in reasoning with LLMs and open new avenues for research in adaptive, multi-path reasoning.