- The paper presents a novel Parallel-Distill-Refine (PDR) approach that generates multiple drafts, distills them into summaries, and iteratively refines outputs.
- The methodology outperforms traditional chain-of-thought reasoning, achieving up to 11% accuracy gains on AIME benchmarks while reducing token costs.
- Experimental results validate efficient distillation techniques and highlight the potential of LLMs as self-improving operators for various complex tasks.
Rethinking Thinking Tokens: LLMs as Improvement Operators
Abstract and Motivation
The paper "Rethinking Thinking Tokens: LLMs as Improvement Operators" explores alternatives to the long chain-of-thought (CoT) reasoning in LLMs, which typically increases token usage and computational costs. Instead, it proposes viewing LLMs as improvement operators on their own outputs, by iteratively refining reasoning over multiple rounds. The primary focus is on a novel Parallel-Distill-Refine (PDR) approach which generates diverse drafts, distills them into concise summaries, and refines outputs iteratively to maintain bounded context sizes, thus optimizing computational efficiency.
Proposed Methods
Parallel-Distill-Refine (PDR)
PDR operates through several key steps:
- Parallel Draft Generation: Multiple drafts are generated in parallel, offering a variety of perspectives on solving the task at hand.
- Distillation: These drafts are distilled into a compact, textual workspace or summary using methods such as top-k extraction, global summarization, or random sampling. This step emphasizes compressing key information, filtering out noise, and retaining useful insights for further refinement.
- Refinement: The workspace feeds into subsequent rounds to stimulate improvement on the initial results, thus enabling the model to incrementally refine outputs over successive iterations.
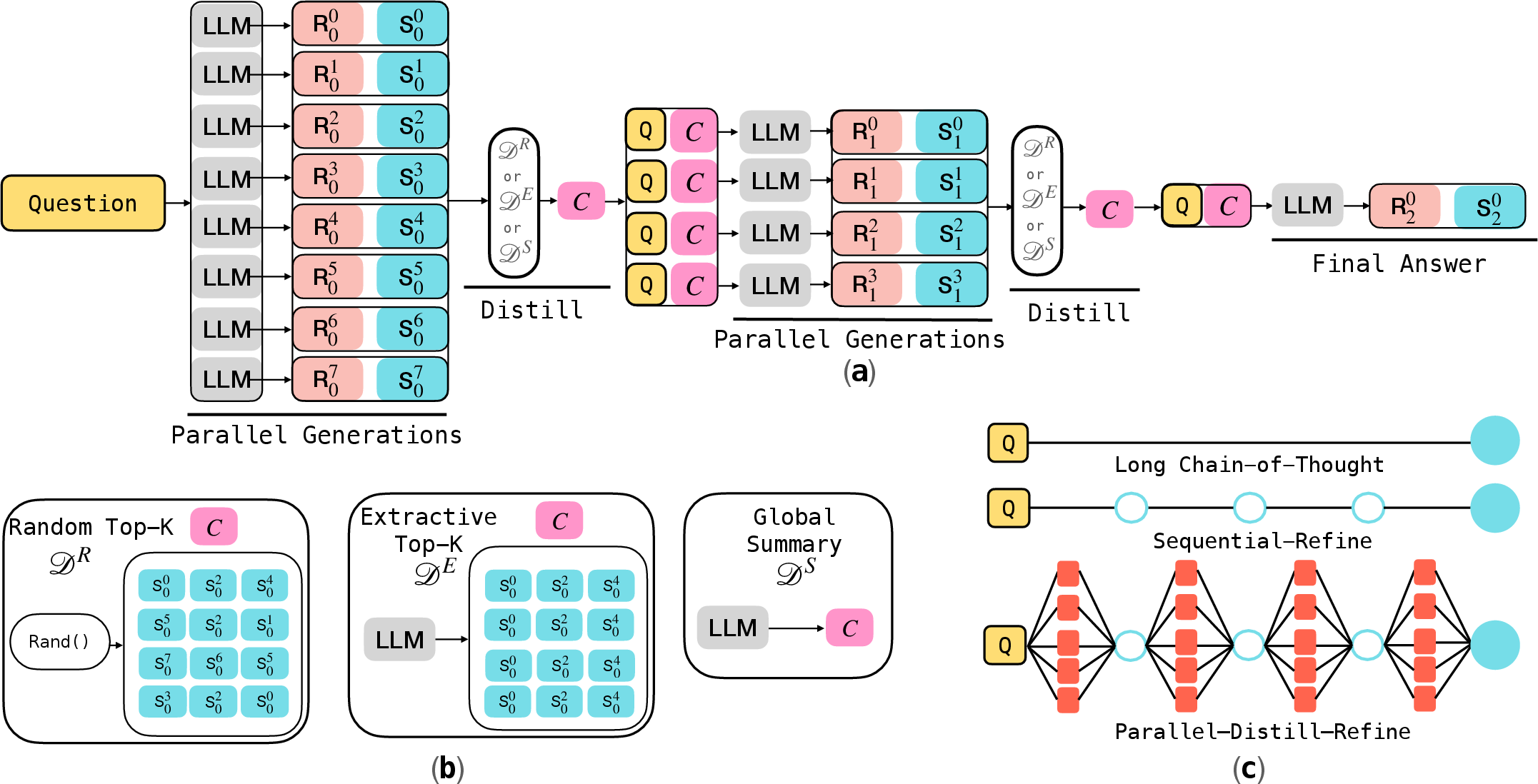
Figure 1: Overview of the Parallel-Distill-Refine (PDR) framework, showing the cycle of parallel draft generation, distillation into a summary, and iterative refinement in subsequent rounds.
Sequential Refinement (SR)
The paper also details an alternative, Sequential Refinement (SR) setup wherein a single solution draft is iteratively refined over multiple steps. This approach simplifies the processing pipeline by focusing on a single candidate but emphasizes the role of error analysis between iterations.
Practical Implementation Details
Inference Budget and Optimization
The performance evaluation of both PDR and SR methods involves sophisticated budget constraints:
- Bseq: A latency proxy counting only tokens along the accepted iteration path.
- Btotal: The total computational proxy considering all inferences, including unused drafts.
The inference setup is evaluated against the Advanced International Mathematics Examination (AIME) datasets for rigorous validation of numerical reasoning capabilities.
Experimental Results
Both PDR and SR consistently surpass traditional long-CoT methods in terms of accuracy under matched computational budgets. Significant improvements were observed:
- PDR improved accuracy by up to 11% on AIME 2024 and 9% on AIME 2025 when compared to long-coT baselines, showcasing its ability to mitigate cognitive and computational inefficiencies.
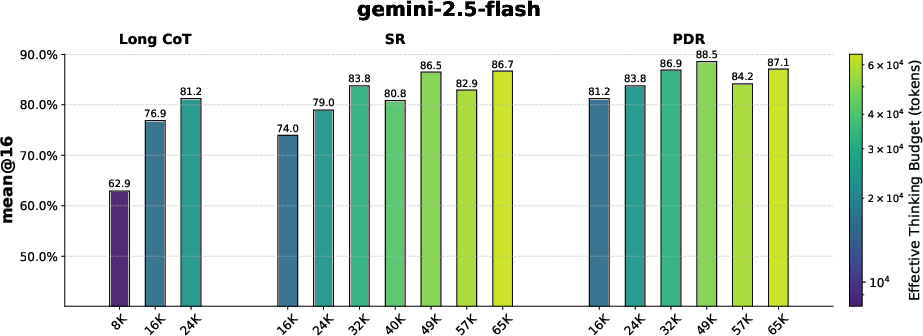
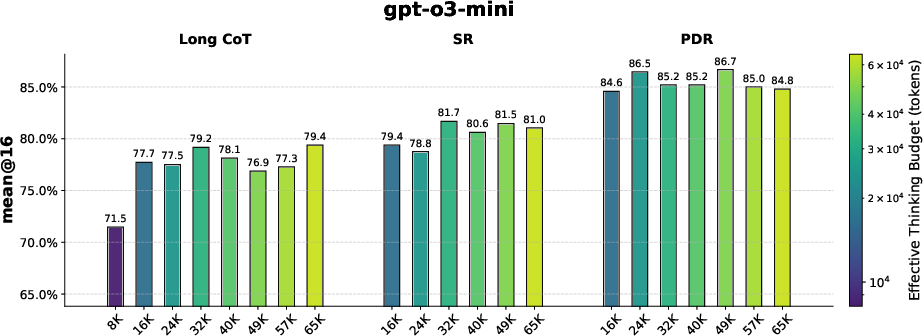
Figure 2: Comparative performance metrics from the AIME 2024 benchmark demonstrating the superior performance of PDR under fixed token budgets.
Distillation Effectiveness
The paper highlights the crucial role of distillation strategies. Methods such as per-sample top-k or globally aggregated summaries proved effective, with global summarization often yielding the best results due to its comprehensive nature (Refer to Table).
Implications of Self-Verification
Experiments testing oracle-guided distillation also expose the variance in self-verification capabilities among LLMs, underscoring areas for further refinement: ensuring the fine-tuning process embraces more robust self-correction mechanisms to maximize iterative gains.
Conclusion and Future Directions
The paper showcases the effectiveness of paradigms like PDR and SR in optimizing LLM reasoning under computational constraints while maintaining or exceeding accuracy levels of traditional long-CoT methods. The findings promote a shift from tokens as mere computation units to potent operators of self-improvement.
Future advancements entail developing adaptive distillation techniques, exploring operator-consistent training frameworks, and scaling these methodologies to broader domains such as code generation and complex decision-making tasks. These advancements aim to leverage LLMs’ latent potential as self-improving entities capable of efficiently navigating extensive reasoning landscapes.